点蓝色字关注 “机器学习算法工程师 ”
设为 星标 ,干货直达!
本文 作者:杨军
原文: https://zhuanlan.zhihu.com/p/463629676
每一代NV GPU的发布都会给业界带来新的想象空间。作为AI系统(这里主要代指深度学习系统)方向的从业者,最关心的自然是每一代GPU能够为AI系统领域带来哪些新的变量。 从之前NV GPU的甲方消费者,转变为现在的乙方提供者,视角变化让自己可以从不同角度来看待这个问题。这里会以深度学习系统的发展踪迹为应用载体,来回顾NV GPU架构的历史变迁。 整个回顾会从最早应用于深度学习计算加速的GTX 580开始,直到最新的Ampere架构。对每一代GPU的回顾会从以下几个方面展开: 单设备硬件架构
跨设备硬件架构
AI workload及应用场景的演进
AI软件栈的演进
生态发展
首先来看Fermi,这也是第一款应用于代表性深度学习加速场景(AlexNet)的GPU架构。 1
Fermi
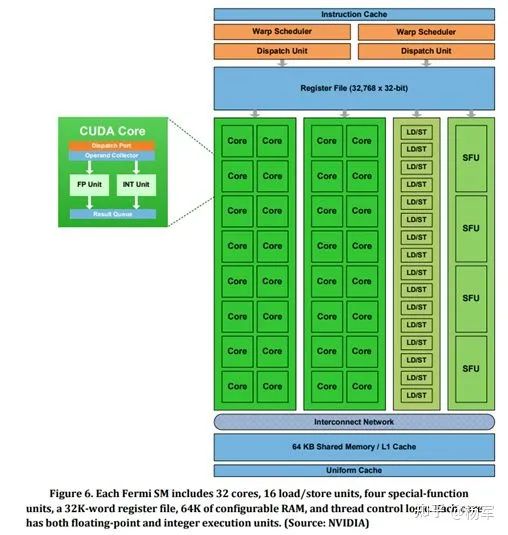
Fermi是支持CUDA的第三代GPU架构,第一代是2006年推出的G80架构(公开材料没有查询到G80的whitepaper,相对详细一些的分析可以参见anandtech的文章: https://www.anandtech.com/show/2116/5 ),第二代是2008年推出的GT200架构(类似G80,在NV官网上已经找不到类似Fermi的whitepaper,倒是在一些分析网站上有一些关联内容,比如beyond3d的文章 https://www.beyond3d.com/content/reviews/51/8 和anandtech的文章 https://www.anandtech.com/show/2549 )。 从Fermi时代开始,Tesla产品线的每一代GPU的whitepaper都提供了公开下载的链接,里面提到了大量的架构技术细节。这篇回顾文章正是以这些whitepaper为基础展开。在Fermi的这篇whitepaper里提到了这样一段话,读来让人感慨颇深: When designing each new generation GPU, it has always been the philosophy at NVIDIA to improve both existing application performance and GPU programmability ; while faster application performance brings immediate benefits, it is the GPU’s relentless advancement in programmability that has allowed it to evolve into the most versatile parallel processor of our time . It was with this mindset that we set out to develop the successor to the GT200 architecture.(来源: https://www.nvidia.com/content/PDF/fermi_white_papers/NVIDIA_Fermi_Compute_Architecture_Whitepaper.pdf ) 以hindsight式的视角来看,将可编程性放在和性能相齐的位置是一个重要的决策。因为可编程性的改善对于提升NV GPU的网络效应和用户切换成本,至关重要。 在俞军的《产品方法论》里提到了用户价值=新体验-旧体验-切换成本 。这个公式也适用于GPGPU这种To B性质的产品。以NV当前代际GPU代指新体验,上一代GPU代指旧体验,性能提升相当于在强化新体验,可编程性相当于在减少切换成本。以NV GPU代指旧体验,竞品代指新体验,这个公式同样成立,只不过可编程性相当于增加竞品的切换成本,性能提升相当于减少竞品提供的增益价值。 在接下来的历代GPU架构回顾过程中,我们可以看到NV一以贯之地坚持践行这个理念,不断通过性能和可编程性(包括用于提升AI开发者生产效率的努力也归结为广义的可编程性)的提升来强化自己产品相较于上代产品和竞品的用户增益价值。 任何事物都有其两面性。所以,对可编程性的重视也存在风险,可能成为制约NV发展的阿喀琉斯之踵。从Google在2016年推出TPU开始(从开创AI DSA硬件先河的角度,引爆这一拨AI硬件技术演进大趋势的寒武纪也成立于2016年),行业里涌现出大量的AI芯片Start-up。 仅从硬件层面AI绝对算力来说,这些公司里已经出现了和NV当前主流产品性能on-par的产品,如果从performance per watt的角度来看,也已经出现了超过NV的若干竞品。其核心原因也跟NV需要关注可编程性和历史用户习惯的包袱有关,而新兴公司没有积累也同样没有包袱,所以可以在架构设计的空间里以适当牺牲通用可编程性为代价来寻找更适合于挖掘AI计算效率的设计权衡点。 相关原理在《创新者的窘境》里也有提到,这也是考验某个领域里头部企业的地方。 回归正题。Fermi相较前两代架构,引入了比较大的架构变化: 对流处理器(SM)进行了重新设计,包括: 每个SM包含32个CUDA cores(这里需要提一下,CUDA core在概念上和通用计算的CPU core的性质其实是有差异的,不过并不影响从AI计算角度的讨论,所以在此先不展开)。每个SM里包括32浮点单元 ( FPU ) 和32个整数计算单元 ( INT Unit ) ,16个Load/Store单元。4个特殊函数单元(SFU)。习惯上,我们会把FP32 ALU称为一个CUDA core,早期NV GPU因为INT 和 FP32 共享datapath,不能做ILP,所以那时候的CUDA core可以被认为包含一个INT和一个FP32 ALU。
对双精度算力进行了大幅提升。考虑到深度学习场景很少用到双精度计算,所以对这个细节不再展开。
引入了L1 cache,并增加了shared memory的容量。L1和shared memory的可配置总量是64KB,支持两种配置(48KB shared memory + 16KB L1或48KB L1 + 16KB L1)。shared memory从上一代的16KB增加到最多可达48KB。实际上,从Fermi开始,每一代GPU都会对shared memory,Register File,L1进行调整,支撑这些调整决策的是硬件推出后,通过和客户交互迭代所增加的对应用负载的理解,以及工艺进步带来了更多可供腾挪的片上硬件资源。
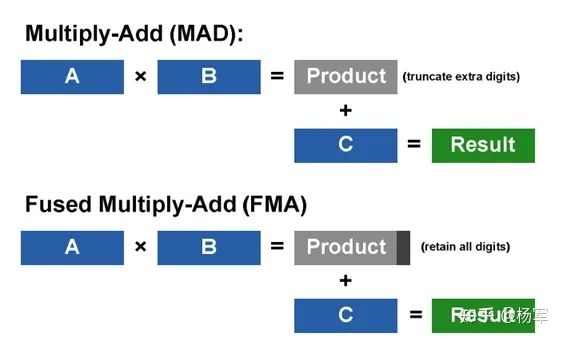
加入了对单精度浮点计算FMA的支持(Fermi之前的架构,支持双精度的FMA,对于单精度只支持MAD,FMA的精度更有保障,可参见这里的描述: https://en.wikipedia.org/wiki/Multiply%E2%80%93accumulate_operation ),精度有了更高保障。 引入了768KB的L2 cache。在Fermi之前,NV GPU是没有L2 cache的,从Fermi这一代开始,引入了L2 cache,并且随着代际演化,不断增加L2的尺寸。L2的引入,将之前需要由软件开发人员take的数据搬运优化的部分工作让渡给了硬件,从而部分减少了软件开发人员的心智负担。
对访存系统加入了ECC支持。对于ECC,我目前仍然怀疑其对于AI计算场景的必要性。因为我的认识是,AI计算过程本身可以通过系统层面的设计(比如阶段性的Checkpoint)来对冲ECC所针对修复检测的内存bits错误异常的影响,所以引入ECC这种会消耗访存带宽及存储资源的手段有些浪费。这也是我理解大量不包含ECC功能的桌面显卡能够应用在生产训练和推理集群的原因。
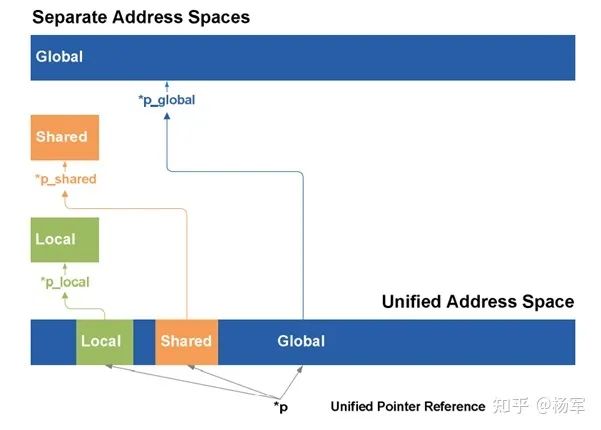
load/store地址位宽由32-bit提升到64-bit,为统一地址访问提供了基础条件。比如local memory,shared memory,global memory进行统一编址(参见下面的一张示意图)。
从AI系统的角度,NV在Fermi这一代并没有为AI计算场景进行任何针对性的设计,包括硬件和软件。其被应用在AlexNet上也更像是一个机缘巧合:Alex这样的算法科学家因为实际算法需求,在为钉子找锤子的过程中,发现GPU相较CPU更适合解决相关问题从而将其作为锤子引入进来。整个过程中NV的作用是相对passive的 。这和当前NV在AI计算领域的主动和激进存在着巨大差异。 而在当时那个年代,为什么是NV GPU被选中作为锤子,而不是Intel CPU或AMD GPU? 在2006年的这篇文章( https://hal.inria.fr/inria-00112631/document )里,我们能够看到基于论文里的实验对比,Intel CPU上打开BLAS库,和NV GPU上的性能在on-par的水准,当时这个工作里并没有使用到CUDA,因为当年正是CUDA的元年。 有趣的是在,这篇文章的脚注里提到了除了在NVIDIA GeForce 7800 Ultra( https://www.techpowerup.com/gpu-specs/geforce-7800-gtx.c127 ),Intel Pentium 4( https://en.wikipedia.org/wiki/Pentium_4 )上的性能实验之外,也准备加入ATI Radeon X1900( https://www.techpowerup.com/gpu-specs/radeon-x1900-xt.c454 )上的实验结果。在2005年更早的一篇文章( https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=1575717 )里,能够看到在CPU, ATI GPU, NV GPU上同时进行MLP加速实验对比的一些数据,看起来当时还互有千秋。 而在2011年的这篇文章( https://people.idsia.ch/~juergen/ijcai2011.pdf )里,基于CUDA实现的卷积操作,性能最多已经达到了Intel CPU上的60倍。当时使用的硬件是Intel Core i7-920(2.66GHZ)以及基于Fermi架构的GTX480/GTX580显卡。年代久远,实测评估已经不太现实,不过,从多个途径的数据cross check的结果( https://gadgetversus.com/processor/intel-core-i7-920-specs/, https://fiehnlab.ucdavis.edu/staff/kind/collector/benchmark/core-i7-vs-opteron, 还有https://www.overclock.net/threads/intel-and-amd-gflops-data-thread-looking-for-sandybridge-too.869018/ )来看,i7-920 2.66GHZ的峰值算力大体在在24~100GFlops 之间。关于i7-920的理论峰值算力, @李少侠 给出了一个比较专业的预估,我直接援引如下: nehalem cpu 只有 port0 的 sse 支持 FP32 乘法,port1 的 sse 只支持 FP32 加法,所以对于深度学习里典型的乘法加法 1:1 的场景,i7-920 理论算力是 4-way*4core*2(FP add + mul ILP)*sse_freq,sse_freq 取 2.66G,那么算力约85Gflops,不过官方并没有公布sse密集情况下的多核频率,应该和这个数接近。 这个数字和( https://progforperf.github.io/nehalem.pdf )的一个推算基本是相当的。所以从客观公平性角度,不妨将i7-920的峰值算力按85Gflops 来设定。而GTX580的峰值算力是1.5TFlops ,大体是1个数量级的差异。再加上CUDA提供的可编程性,以及Fermi引入的提升软件开发人员效率的一些硬件feature(比如L2的引入),在2011年,NV GPU相较Intel CPU已经在神经网络加速场景 取得了比较明显的优势。结合文章里的这一段话,对于Fermi加入L2,并且在后续代际持续提升L2的容量的动作,就更容易有共鸣了。 The latest generation of NVIDIA GPUs, the 400 and 500 series (we use GTX 480 & GTX 580), has many advantages over older GPUs, most notably the presence of a R/W L2 global cache for device memory. This permits faster programs and simplifies writing the code. In fact, the corresponding transfer of complexity into hardware alleviates many software and optimization problems. Our experiments show that the CNN program becomes 2-3 times faster just by switching from GTX 285 to GTX 480. Manual optimization of CUDA code is very time-consuming and error prone. We optimize for the new architecture, relying on the L2 cache for many of the device memory accesses, instead of manually writing code that uses textures and shared memory. Code obtained by this pragmatic strategy is fast enough. We use the following types of optimization: pre-computed expressions, unrolled loops within template kernels, strided matrices to obtain coalesced memory accesses and registers wherever possible. Additional manual optimizations are possible in case future image classification problems will require even more computing power. 需要指出的是,上面的对比,并没有做到完全基于第一性原理的公平性,比如Intel Core i7-920的工艺是45nm ,而GTX580是40nm ,集成的晶体管数量也存在明显的差异(30B v.s. 0.731B )。不过考虑到i7-920的架构设计中,只有不到20%的芯片面积用于实际计算,(参见下图: https://www.nvidia.com/content/PDF/fermi_white_papers/P.Glaskowsky_NVIDIA%27s_Fermi-The_First_Complete_GPU_Architecture.pdf ),已经可以认为,论文里的性能差异是由GPU和CPU在架构设计权衡的定性差异所带来的,所以我们不再花费精力进行更精细的定量对比。 总的来说,在Fermi这一代,NV GPU虽然没有为AI计算场景进行特殊的定制,但因为其相异于CPU的设计理念使得其更适配于神经网络的并行计算特性,再加上CUDA和硬件层面改善可编程性的一系列努力,使得其“误打误撞”地契合了AlexNet的建模需求,在深度学习的第一个killer application上取得了不错的开局。 2 Kepler Kepler架构在2012推出。这一代并没有引入多少AI计算相关的架构创新,更多是一些偏通用性质的架构改进,包括 : 1. 针对performance per watt进行了比较多的改进。 每个SM里的CUDA cores数量由前代的32个提升为192个(单精度计算)。
SM里的warp scheduler由Fermi的2个增加到4个,来适配CUDA core的数量增加。
将warp scheduler里硬件实现的调度依赖处理逻辑上推到软件编译器层(得益于NV GPU的计算流水线的确定延迟特性),节省了部分硬件资源消耗。
引入了warp shuffle指令,使得warp范围内的归约操作不需要经过shared memory中转,直接通过register的数据交互即可完成。而这类指令恰好为深度学习场景下特定尺寸workload的归约操作提供了相较于shared memory更高效的实现可能。
3. 引入了dynamic parallelism, hyper-Q, Grid Management Unit等一系列特性。基于我个人的经验,这些特性对于提升单个AI作业本身性能帮助很有限,其中hyper-Q和Grid Management Unit对于集群层面的资源优化倒是会有帮助。 4. 引入了GPUDirect技术。虽然在Kepler代际引入GPUDirect并不是为AI计算场景考虑,但这个特性对于未来分布式AI训练的性能提升还是有着重要的价值。 5. 对每个thread的可用寄存器数量,L1/Shared memory以及L2 cache的尺寸进行了调整。我的理解是,这些调整一方面源于NV对客户工作负载反馈的响应,另一方面也得益于工艺提升带来的腾挪空间。 关于Kepler时代的架构变化细节,可以参见这篇whitepaper( https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/tesla-product-literature/NVIDIA-Kepler-GK110-GK210-Architecture-Whitepaper.pdf )以及GTX680的whitepaper( https://www.nvidia.com/content/PDF/product-specifications/GeForce_GTX_680_Whitepaper_FINAL.pdf ),在此不再做信息搬运。 Kepler时代,NV在软件层面引入了针对AI计算场景的一个大动作——cuDNN v1.0在2014年的发布,并集成进了Caffe等深度学习框架中。考虑到硬件迭代的成本,其发展通常会滞后于软件发展,所以2014年cuDNN的发布标志着深度学习已经进入了NV的视野,通过软件库的迭代加深对深度学习计算负载的理解,为后续硬件架构的演进提供信息反馈,大体可以推测是这个思路。而2016年Pascal架构的发布,也基本上佐证了这点。 在Kepler时代,生态方面有几个有代表性的事件: Google在2013年基于三台单机装配四块GTX680显卡的服务器,替换掉了之前使用的1000台CPU服务器,完成了猫脸识别任务。这对于NV GPU后续在深度学习计算场景的更多被采用,提供了非常好的背书。
虽然从第一性原理出发,我仍然认为NV GPU和Intel CPU不应该存在100X的性能差异,但很多时候,商业上的演化并不仅仅是基于第一性原理的技术论道(实际上从一些公开工作可以看得出来,至少Intel内部的技术团队对于NV GPU和自家硬件的优劣对比是有着清晰认知判断的,但似乎出于别的一些原因,这些技术认知未能最终转化成有效的公司决策操作)所能完整覆盖的,商业宣传布道、市场公关再加上不同企业面临相同场景因为自身组织特点和公司现状对客户反馈的反应不一,使得这种认知在相当长一段时间内深入建模人员的mindset中,这就为NV GPU扩大其在深度学习计算领域的覆盖率打下了很好的基础。
Google的GNMT模型在96块K80 GPU上完成其训练过程。在GNMT模型推出之后,工业界有若干头部公司先后参考其理念,将深度学习应用于机器翻译场景,并大抵都选择了GPU作为训练硬件。
2013年深度学习开源框架Caffe的发布。在Caffe发布之前,2002年Torch其实就已经发布,2007年Theano也已经发布,并且都提供了深度学习建模能力的支持。但是在深度学习领域,其接纳度远不如当时的后起之秀Caffe。Caffe推出之后,很快就收到了NV的关注,包括给Caffe开发团队免费提供GPU,以及推进cuDNN的集成,都是NV当时响应动作的部分。为什么是Caffe而不是先推出的Torch/Theano取得这样的成就呢?
我想,这里面的核心还是在于Caffe面对CV建模场景提供了更好的易用性(基于Caffe描述模型结构,以及定制Caffe的便利性)以及预训练好的模型checkpoint,使得CV建模人员可以把精力更多花在add-on的建模创新本身,而不是去折腾基础设施或是在复现其他SOTA结果上花费太多时间。
值得注意的是,如果我们回顾历史,会有这样一种感觉,Caffe开发过程中,关注的核心点首先是功能、易用性以及用户生态的建设,性能从一开始就不是其关注的第一优先级,性能方面,Caffe通过和硬件厂商的close合作来解决,而不是自己投入大量研发精力去解决 。
一言以蔽,Caffe当时满足了更多DL建模人员的需求(当时的建模需求以CV为主),达到了第一代深度学习框架和使用用户之间更好的一个契合度。稍微形而上一些,从历史唯物主义的角度,在一个领域代表了大多数人利益的事物往往会得到更多的支持和认可,在2013年显然因为种种因素Caffe在CV建模领域达到了这个状态,于是Caffe得到了快速的推广。而NV则借着Caffe的推广普及,其GPU硬件更加深入深度学习建模人群了。
阿里巴巴初具规模采购NV GPU,也是从Kepler时代开始的。腾讯使用GPU进行语音识别加速,也始于Kepler时代。百度使用GPU的历史则更为悠久一些,我不确定是不是在Kepler之前就开始在使用GPU了,有熟悉这段历史的朋友欢迎提供线索。 3 Maxwell Maxwell架构在2014年被推出。和上一代Kepler架构相同,采用的也是28nm工艺。相同工艺通常意味着可供腾挪的硬件晶体管资源数量不会有显著增加,留给架构师的设计空间相对有限。不过在Maxwell时代,因为28nm工艺成熟度的改进,加上从前代产品迭代中学习到的经验,Maxwell仍然引入了一些比较出彩的变化:
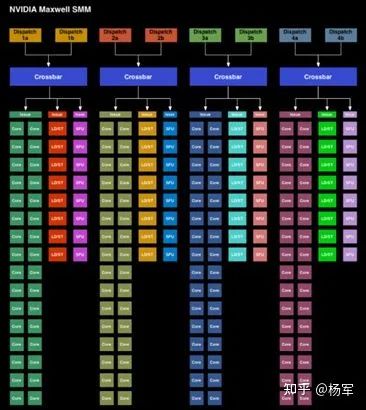
将L1 cache和shared memory进行分离,而不是合成一段可灵活配置的连续存储资源资源。关于这一点,我们会注意到,Volta时代又将L1和shared memory进行了合并。架构设计的反复也体现了架构设计层面的螺旋式上升。
对L2尺寸进行了大幅调整,从512KB扩大到2MB。我的理解是,这种程度的调整 往往是基于真实的workload反馈,数据驱动做出的架构决策。
增加了每个SM上active的thread blocks数量,从16增加到32,改善occupancy( https://docs.nvidia.com/gameworks/content/developertools/desktop/analysis/report/cudaexperiments/kernellevel/achievedoccupancy.htm )。我的理解是,这个调整也是为了配合下面的warp scheduler的改进所引入的协同动作,以确保有足够多的warp可够调度,来弥补去除全局warp scheduler损失掉的灵活性。
对warp scheduler的设计进行了调整( https://www.anandtech.com/show/7764/the-nvidia-geforce-gtx-750-ti-and-gtx-750-review-maxwell/3 ),每个warp scheduler只能看到SM内部四分之一的计算执行资源,牺牲了一定的灵活度,但节省了全局warp scheduling所需的SM范围内全局crossbar的功耗开销。
Kepler架构warp scheduling示意图。
在这里( https://www.microway.com/download/whitepaper/NVIDIA_Maxwell_GM204_Architecture_Whitepaper.pdf )可以了解到更多Maxwell的架构细节。 Maxwell这一代在架构上也和Kepler和Fermi一样,并没有引入针对AI计算场景的特别考虑。 软件层面,在14年cuDNN V1.0推出以后,进行了持续的迭代,2015年3月发布了v2,2015年9月发布了v3,2016年2月发布了cuDNN v4,2016年3月伴随P100发布了cuDNN v5(cuDNN的发展过程中值得一提的是Scott Gray,这位兄台人不在NV,但通过逆向工程手写了Maxwell架构上的SASS assembler( https://github.com/NervanaSystems/maxas ),并首次基于winograd实现了快速conv算法,最终这个作法被cuDNN团队吸纳入正式产品中),同时在v5版本也加入了对RNN/LSTM结构的优化支持,虽然现在RNN/LSTM结构的使用已经显得势微。 但在当时,对于机器翻译,语言模型等NLP场景(以及涉及序列建模的OCR及语音识别场景),RNN/LSTM实际上是当时的SOTA了,如果我们结合一些领域工作发表的时间做一下关联,会发现NV对RNN/LSTM的支持跟这些工作发表的时间距离非常之近,这从侧面体现出NV对于AI计算workload演化趋势跟进之紧密。 同时,这段时间涌现了一些具备killer application属性的深度学习模型,比如微软在2015年推出的ResNet。我没能在公开文献中检索到ResNet论文发表时所使用的具体GPU型号,不过按时间推算,应该使用的是Kepler或Maxwell架构的GPU。 Maxwell时代,行业生态层面有几件重要的事情发生: 1. AlphaGo在2016年3月胜出李世石,极大程度上提振了整个行业对深度学习的信心和热情,也间接促使了一些公司采购了更多的NV GPU,因为当时的NV GPU已经几乎是训练深度学习模型的的标配硬件了。 2. Google在2015年底发布了TensorFlow 0.5版本,虽然当时发布的还只是一个单机版本,但对于整个深度学习领域来说,仍然有着划时代的意义。原因在于: 用户想加入新的模型结构(比如LSTM),相较第一代的Caffe,生产力有了显著的提升。曾经在Caffe里加入过RNN/LSTM支持的同学应该对这个是比较有体感的。在TensorFlow时代,如果只关注建模功能,对性能要求不picky的话,在Python层面就可以基于TF提供的原子operator完成LSTM结构的建模了。
从设计理念上,TF为不同的分布式执行策略提供了更好的基础。将计算图描述和运行期执行进行显式区分,对于后端优化,其实引入了更干净的抽象边界。
配套的TF Serving的引入。为深度学习提供了端到端的支撑能力,而不仅仅是训练环节。
3. Chainer在2015年6月的发布。由于不像TensorFlow背后有Google的豪华团队支持,Chainer受到的关注度并不算大。但这个框架在一些geek味的深度学习建模人员那里得到了非常好的评价。我还记得2017年参加现场GTC时,SaleForce的两个小哥分享他们基于Chainer做的一个RNN的优化工作,映象中是当时现场参加人数最多的一个session。更重要的是,Chainer实际上为后续遵循define-by-run执行模式的深度学习框架提供了一个生动的示例。这也是体现技术创新的脉络延续性的例子。 回头审视,站在2016年Pascal推出的前夜,会有一种“山雨欲来风满楼”的感觉,于是就有了Pascal架构的发布。 4 Pascal Pascal架构在2016年3月被推出,采用16nm和14nm的工艺,说其是NV面向AI计算场景发布的第一版架构当不为过。在Pascal架构里引入了面向AI场景很重要的一些特性: 1. FP16。从实用性角度来看,Pascal时代的FP16其实蛮鸡肋的,理论算力相较FP32提升只有2X,但是中间累加结果只支持FP16的格式,使得对于训练场景很容易影响精度。所以在我了解到的范围内,Pascal的FP16应用于训练场景的案例非常有限。 但这个特性的引入,为Volta加入FP16 TensorCore提供了有效的实验反馈,并且这是NV在硬件架构层面第一次结合深度学习作业特点进行的软硬协同设计,其架构设计层面的影响是蛮深远的。 技术脉络的演进,总是草蛇灰线、伏脉千里,透过某个技术出现的单点时刻,回溯其源起和演进路径,可以更有效地指导后续的技术决策,而不是寄希望于灵光一现式的运气。 2. NVLink。在我的认知里,NVLink是一个典型的点状头部业务驱动技术架构升级,技术架构升级进一步影响更多业务接受的技术特性。NVLink背后的含义是单机多卡,并且只有卡多到一定程度以后,NVLink的价值才更容易显现。所以在Pascal的whitepaper( https://images.nvidia.com/content/pdf/tesla/whitepaper/pascal-architecture-whitepaper.pdf )里给出的参考架构至少也是单机四卡的规模,标配是单机八卡。而单机四卡/八卡被生产环境接纳,并不像现在感觉这么显然。原因主要是几点: 和CPU/内存资源配比的问题
机房运维新增复杂性的问题
对集群调度系统提出了更高要求
阿里大约是在2018年上线了具备NVLink的生产集群,而要到2019年才有比较多生产作业启用NVLink进行单机多卡加速,距离NVLink架构特性的推出大约有近三年的时间差,可以参见这里的一些分析描述。 NVLink的技术细节简要来说可以分为NVHS, Sub-link, Link, Gang四个层次。一条NVHS的link提供单向20Gb/s的传输带宽带宽,8根NVHS构成一个Sub-link,两条Sub-links组成一条用于双向连接的Link,P100架构下的单机八卡配置,不同GPU之间会由四个Link组成一条Gang,所以Gang的双向汇总带宽是20Gb * 8 * 2 * 4 = 160GB/s ,单向汇总带宽80GB/s,是PCIe提供带宽的5x 。更形象一些的示意图如下: HBM。Pascal架构的一个突破性特性是首次将HBM技术引入到NV的硬件中(行业里最早将HBM引入到产品中的是AMD在2015年将其应用在Fji GPU产品中,第一块HBM内存芯片则是在2013年由SK hynix推出),提供相较上一代Maxwell架构最高3倍的访存带宽提升。HBM的引入为高访存压力的训练作业提供了更有力的硬件支持。
INT8。从Pascal时代开始,NV GPU首次引入了对INT8格式的支持(INT8首次引入是在基于GP102架构的P40 GPU,而不是基于GP100架构的P100 GPU)。INT8对于推理场景的必要性现在已经不需要过多说明,但是在16年的硬件里加入INT8支持,还是一件蛮激进的事情。Google TPU的消息也是在16年才对外正式expose,即便NV能够有渠道更早嗅到相关技术趋势,能够做到这么快将INT8加入量产GPU里,也是非常迅速的一个执行动作了。这也反映出NV的敏捷性和执行力。
在SM架构层面,Pascal引入的变化不算多。在我的理解中,更多是工艺提升带来更多可用晶体管资源以后,可以把更多料堆起来反映到SM的数量提升,属于增量式的变化。从这一点也体现出NVIDIA从Fermi时代起结合CUDA所选择的计算架构的优越性——几乎每一代新架构(特别是SM相关)都能够以相对增量的方式将工艺提升带来的新增晶体管资源利用起来,而不是动辄引入大的架构调整。 在Pascal whitepaper里提及的将CPU和GPU进行统一内存访问的特性,我自己的经验是并没有感觉到这个特性对于AI计算领域提供了多少实际收益。记得在刚刚拿到P100以后,我们评测过其page migration engine的表现( https://developer.nvidia.com/blog/beyond-gpu-memory-limits-unified-memory-pascal/ ),当时的结论非常negative。 我们当时的判断是想使用CPU内存来作为GPU显存的backup,并且保证性能下滑不要太明显,还是需要在AI框架层结合应用作业的特点来进行处理,而不是直接交给page migration engine来在后台自动完成。 另外值得一提的是,在P ascal时代 能够看到NV在从芯片向整机系统迈进,在其whitepaper里提到了单机8卡的DGX-1 server,这也是从Fermi时代开始,第一次在whitepaper里出现单GPU之上整机的方案。考虑到DGX-1的成本,在大量生产环境布署的其实是参考DGX-1代工生产的类似GPU服务器机型。 软件层面,Pascal这一代针对AI场景也引入了更多变化,首先是面向推理加速场景的TensorRT的发布,然后是NCCL在2016年的发布。 说到这里,我一直很好奇NCCL以开源形式存在至今(多机部分初始是以闭源形式提供,后来在框架自行提供多机通信库的压力下推动了NCCL多机通信版本的开源),而TensorRT则一直保持闭源形态,是什么导致这两个产品存在这样的差异?在NV的官方blog上提到NCCL最早是一个research project,而TensorRT的源起则并不是一个research project,所以可能在对外开放度上NCCL尺度会更大。 不过从生态建设的角度,hindsight地来看,如果TensorRT在起步的时候,就考虑按一个开源项目的方式来运作,不确定会不会带来更快的迭代速度(如果迭代速度是一项重要的商业度量)?这也是自己有时候会思考的问题之一——如果有一款全新硬件,需要为其规划AI软件栈的技术路线的话,NV的哪些做法是应该借鉴的,哪些是应该改良的? 2016年5月,MxNet 0.7版本的发布。其实很长一段时间,MxNet在业内都有着不错的认可度。包括我知道国内的一些AI公司在早期都是更倾向于基于MxNet进行扩展定制,而不是TensorFlow。以及NV在新款GPU上进行深度学习模型性能优化时,往往会先在MxNet上开展,比如MLPerf。
但一个发人深思的事实是,时至今日,基于MxNet发表的论文已经廖廖(参考Paperswithcode的一个趋势统计)。相近的项目启动时间,为什么最后出现这样的结果?我想,至少有一个信息是我们可以解读出来的,对于深度学习框架这个场景来说,性能可能并不是决定胜负的因素,因为至少在NV GPU上,MxNet的综合性能是最好的,但最后胜出的不是MxNet。PyTorch核心团队的一篇分享内容( https://soumith.ch/posts/2021/02/growing-opensource/ ),也许能部分回答这个问题。
2016年9月,PyTorch 0.1.1版本的发布,时至今日,PyTorch在研究领域,已经一骑绝尘,把其他深度学习框架远远甩在了后面,包括TensorFlow。与此同时,随着计算硬件的发展,PyTorch也开始暴露出一些局限性,最大的局限性也和其最大的优势有关——过于强调易用性使得用户建模代码里很容易充斥大量Pythonic的代码,导致引入大量host和加速器的数据以及控制依赖,在加速器不断push性能边界的大背景下,这个影响可能会吃掉易用性的红利。
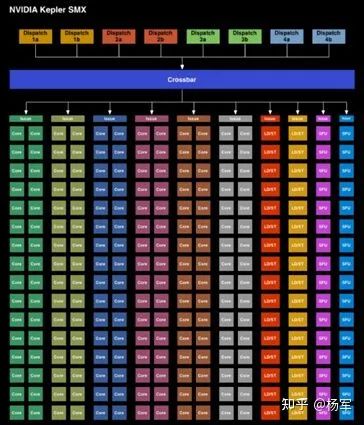
5 Volta 在距离Pascal架构推出仅过去一年之后,2017年5月的GTC keynote( https://www.anandtech.com/show/11360/the-nvidia-gpu-tech-conference-2017-keynote-live-blog ),NV宣布了下一代Volta架构的发布。 考虑到Pascal代际引入了较大的架构升级,间隔这么短又发布了下一代的Volta架构,这并不是一个常规行为,实际上是源于Google TPU当时给NV带来的压力。 在Volta之前,面向AI计算场景,NV GPU相较TPU其实是存在技术上的代际差异的,这就严重威胁到了NV在AI计算领域的地位。如果技术上不能及时拉平代际差异,仅靠CUDA生态建立的用户切换成本来进行对抗,很可能会出现《创新者的窘境》里的状况——被颠覆性的技术拉下马来。这个技术代际差异在Volta架构通过引入第一代Tensor Core在训练场景进行了拉平,随后Turing架构的第二代Tensor Core在推理场景上进行了拉平,直到Ampere时代,NV才算再次巩固了自己在AI计算领域的龙头地位。 时隔四年,回顾这一段行业历史,还是感觉精彩之至。比如,为什么选择了先支持FP16,而不是Google提及的BF16?为什么考虑选择了4x4尺寸的Tensor Core,而不是更大的尺寸?如何figure out出来和FP16配套的Loss scaling的训练策略?Tensor Core的编程API如何对外暴露来尽量避免和现有CUDA体系形成撕裂?怎样让NV之外的开发者也具备在Tensor Core上开发程序的能力?这里涉及到了大量技术、非技术因素的综合权衡。 一些结论决策,当时看是合理的,但现在来看,已经被推翻或迭代更新了。比如从最早支持FP16,到支持BF16,及至引入TF32。从4x4尺寸,到更大的8x8。CUDA层面暴露的API粒度也在发生演进变化。如此等等。这里重要的不是结论,而是探讨这些结论产生的过程。因为这些过程,是可以迁移到下一拨workload,下一拨架构创新机会上,具体的结论则很可能未必。 硬件层面,Volta时代的Tensor Core提供了单cycle完成4x4x4=64条半精度FMA计算操作的的能力,在计算能力提升的同时,因为原先由64条FP32指令完成的操作现在由一条TensorCore指令完成,也省掉了大量用于保存中间计算结果的寄存器资源消耗,提升了数据复用性。 Volta的每个SM内部除了跟Pascal时代一样的64个FP32/32个FP64/64个INT CUDA core以外,还提供了8个Tensor Cores。FP32 CUDA core和Tensor Core数量差距如此之大,再加上Tensor Core对数据存取的需求和FP32 CUDA core存在明显的差异,如何将Tensor Core计算能力对CUDA软件开发人员暴露成为一个蛮考究的问题。 从Volta架构开始,PTX指令中引入了Warp level的矩阵计算及存取指令,并不断扩展其灵活性,从只能使用wmma.load/wmma.store/wmma.mma按ISA约束的数据组织方式来进行存取,到使用mma指令由软件开发人员根据需要进行显式的数据组织排布(灵活性提升的同时也意味着编程复杂性的增加),以及为了简化NV之外CUDA开发人员使用Tensor Core的负担所推出的CUTLASS软件库。Tensor Core编程复杂性的根源在于: 从原先相对符合朴素直觉的SIMT过渡到了Warp-level的编程范式,同一个warp内的32个thread需要按照Tensor Core的数量分成8个分组(grouping),每个group内的四个thread需要协同完成shared memory到寄存器的数据加载,group与group之间也需要考虑协同。不同处理任务之间的依赖关系,增加了思考的复杂度度。
考虑到性能,shared memory里的数据组织方式需要注意规避bank conflict,这就引入了另一个反朴素直觉的维度。
Tensor Core的粗计算粒度,使得程序员需要显式地将计算过程进行细致的拆解。有兴趣的同学可以参考这里( https://arxiv.org/pdf/1804.06826.pdf )和这里( https://arxiv.org/pdf/1811.08309.pdf )的两份材料,可以看到CUDA层面为16x16x16规模矩阵计算暴露的wmma::mma_sync API映射为64(FP32累加)或32条HMMA指令(FP16累加)的细节拆解过程。如果想直接使用PTX的mma指令进行编程来获得更好的灵活性,就需要自行完成相应的拆解。
总的来说,Volta时代的Tensor Core在技术原理上帮助NV拉平了和Google在AI计算领域的技术代差,但是现在回头来看仍然存在比较多的局限性,包括 : 只支持FP16。虽然NV的技术团队设计了精巧的loss scaling策略( https://arxiv.org/abs/1710.03740 ),并通过自动混合精度插件化的手段完成了和主流深度学习框架的集成,但是对模型训练精度仍然存在一定影响,导致其在实际业务中被启用的比例并不算高。
可编程性相较SIMT时代的CUDA差了很多。CUDA层面暴露的WMMA API的粒度很粗,灵活性较差。即便使用PTX层面的WMMA指令,也只能提供相似灵活度。使用HMMA SASS指令虽然足够灵活,但又会影响到程序的可移植性,并且过于hacky。不过从PTX 6.4 版本开始(对应于CUDA 10.1 ),在PTX层面对外暴露了MMA指令( https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#warp-level-matrix-instructions-for-mma ), 该指令的粒度和HMMA SASS指令已经一一对应,这就使得NV之外的工程师也拥有了更精细的Tensor Core编程API了。不过总体来说,Tensor Core编程本身的复杂性,导致NV之外能够基于Tensor Core开发CUDA程序的工程师数量显著下降。
NVLink带宽的增加。Volta时代的NVLink 2.0,单条link提供的单向带宽由Pascal时代的NVLink 1.0的20GB/s提升到25GB/s,双向向带宽由40GB/s提升提升到50GB/s,GPU之间的Link数量也由4条扩展为6条,加总在一起,GPU之间的双向互联带宽达到了300GB/s,相较NVLink 1.0带来了80%的带宽提升。
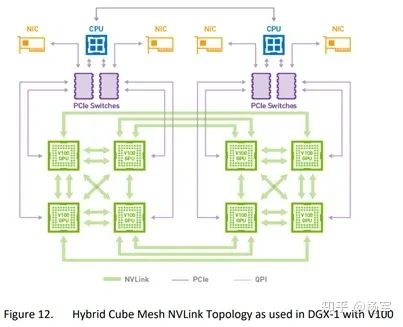
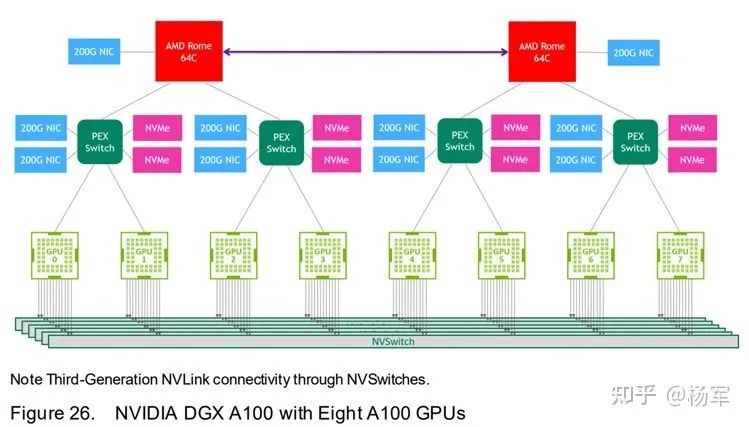
NVSwitch。在NVLink的基础上,2018年NV基于NVSwitch推出了DGX-2机型。NVSwitch的出现使得单机内部卡间通信带宽呈现出了均匀性。单机八卡机型,每块GPU通过6根links连接到NVSwitch上,再通过NVSwitch和其他GPU进行互联。所以理论上,任意两块GPU之间,都可以达到最高达300GB/s的双向带宽。这就为reduce-to-one乃至all2all这种通信模式提供了极大便利性。
HBM带宽的增加。经过Pascal时代引入HBM的试水,在Volta时代,NV对HBM的带宽进行了扩展,16GB显存配置的卡型,显存带宽由732GB/s提升到900GB/s,并且对HBM的实际访存效率进行了改善。
为SM的整数计算加入了单独的data path,使得整数计算指令(在AI场景通常对应于地址计算逻辑)不会阻塞浮点计算或Tensor Core指令的发射。引入这个特性是对Tensor Core毫无疑问是有benefit的,因为随着计算能力的提升,增加了其他操作成为瓶颈的可能,所以期望把地址计算操作所需的整数计算放在单独的data path里,从而缓解瓶颈。同时INT data path的引入也可以使其他非Tensor Core计算,但存在浮点和整数指令混合的场景受益,Volta 上不使用 Tensor Core 的 SGEMM优化难度相比 Pascal 更低就有这方面原因(感谢 @李少侠 同学指出这一点 )。
在Volta时代,深度学习模型层面也出现了一些新的变化,这些变化主要集中在自然语言处理领域。首先是2017年Transformer模型结构在机器翻译场景取得的效果突破,使得其开始替换之前SOTA的RNN/LSTM结构,被大量采用。然后是2018年BERT的出现,在展现其出色的预训练模型效果的同时,也给使用NV GPU预训练BERT带来了比较大的挑战和压力。 NV对此的应对是迅速推出了32G显存的V100卡型,并在设计针对训练场景的下一代GPU架构时对显存容量给予了更高权重。 另一个标志性的事件是2020年OpenAI对外公布其在微软提供的V100集群上完成了包含175B参数的GPT-3模型的训练过程。一个有意思但无从考证的坊间传言是,BERT的核心开发者之前在微软工作,在加入Google后,借助Google提供的软硬结合的AI算力,在比较短的时间内推出了BERT,微软的高层决策者收到这个反馈之后,投入了一大笔钱购买了DGX的服务器:)。 软件层面,NV在2017年底发布了CUTLASS,为NV之外的开发者开发Tensor Core程序提供了一个比较好的参考基础。2018年Q3以开源代码的形式发布了跨结点的NCCL通信库(这里的一个背景是,NCCL 1.X 一直是开源的,2.0 加入了多机分布式支持之后一度闭源了一年左右,后续框架开始自行支持 AllReduce on RDMA的压力倒推NV最终将NCCL 2.0开源,最终成为多卡通信的事实标准),并在当年发布了TensorRT Inference Server(之后被更名为Triton Inference Server)。 2018年NV为TensorFlow加入了TF-TRT的支持(还记得在NV推出这个工作之前,当时我还在阿里,我的同事易凡同学因为支持业务的需要,正好也完成了一个类似工作的原型,看到NV发布了撞车的tf-trt以后,感觉也是比较微妙),显著提升了基于TensorFlow使用TRT布署能力的易用性。单设备优化之外,继续向AI系统全链路渗透。 另外值得一提的是在V100时代,大模型训练的需求变得更加旺盛。在V100之前的时代,大模型训练场景主要包括三类:一类是大规模人脸分类,因为其会有一个巨大的全连接分类层需要进行模型并行;一类是ResNet101这种极深类型的模型,需要引入类似pipeline并行的作法;还有一种就是大规模稀疏搜推广模型,通过将大规模embedding table分片存放解决。 从V100之后,我们会发现大模型训练所需要的技术核心点其实并没有变化,只不过场景更多以NLP为主。其推手当属BERT和GPT-3这两大killer application性质的模型。 2019年,NV对外发布了支持Megatron-LM的工作,这也是Megatron-LM的第一次对外亮相,当时的工作基于32GB V100 GPU来完成,并且只支持Tensor Parallelism,不支持Pipeline Parallelism。 与此同时,也已经能够看到业界有更多围绕大模型训练相关的工作,比较有代表性的当属微软DeepSpeed团队的工作,这支团队通过引入精细的显存优化技术从另一条技术路径对大模型训练进行探索,这个工作也是以V100 GPU为主要硬件平台来完成的。其他相关工作包括微软的PipeDream(在NV GPU上完成),Google的GPipe(同时使用了NV GPU和TPU作为硬件平台)等。 这篇回顾文章的重点不是讨论分布式训练技术,所以不再展开更多相关细节,这里的关键是,这些大模型训练工作背后的支撑硬件,几乎清一色以NV GPU为主,以及若干Google发起的工作基于TPU来完成。 另一个值得一提的是,MLPerf training 0.5在2018年12月份结果的发布,从此MLPerf training先后历经0.5、0.6、0.7、1.0、1.1五个版本的迭代(MLPerf inference历经0.5、0.7、1.0、1.1四个版本迭代)。迭代过程中,因为有了清晰的优化标的,NV得以资源聚集,整套软硬技术全栈也经历了巨大的变化飞跃。虽然MLPerf里的不少优化结果并不能直接迁移到生产环境里(参考这里的一些讨论: https://images.nvidia.com/aem-dam/en-zz/Solutions/data-center/nvidia-ampere-architecture-whitepaper.pdf ),但其对于行业技术进步的促进作用还是毋庸置疑的。 在V100时代,随着Tensor Core对Conv/GEMM这类计算密集算子带来显著加速,访存密集算子以及kernel launch开销对端到端性能的影响变得也越来越大,也是从V100时代开始,自动算子融合技术开始受到更多关注。 在这方面,Google XLA应该是最早进行相关探索的团队。Google在为TPU设计XLA编译器的过程中,发现里面的一些技术对于GPU和CPU也同样能够带来收益,于是将XLA也使能到了GPU上(XLA CPU的投入一直乏善可陈,在此不提)。时至今日,无论是NV GPU还是新兴的AI芯片公司,算子融合技术已经是必备的了。 6 Turing Turing架构在2018年9月的SIGGRAPH正式发布。和Volta相同,Turing也基于TSMC 12nm工艺完成生产。从AI计算的角度,Turing主要面向推理场景,相较Volta其架构上的变化主要有: 加入了INT8/INT4/INT1的Tensor Core支持。
使用GDDR6替换掉HBM,面向推理场景,提供更好的性价比,推理场景因为不涉及反向传播计算,并且推理过程可以更激进的启用算子融合技术,所以访存压力显著小于训练场景。
大幅去除用于FP64的计算资源(从Volta时代的1:2 的FP64:FP32比例下降到Turing的1:32 ),因为DL推理场景并不需要使用FP64,所以大幅提升了能效比。
7 Ampere Ampere架构在2020年5月发布。这一代架构引入了比较多的变化: 采用7nm工艺,GPU die的尺寸相较V100略增(826mm^2 v.s. 815mm^2 ),片上晶体管数量从21B 激增到54B ,这就为更激进的架构创新提供了更多腾挪空间。
引入了BF16和TF32的Tensor Core,后者对于AI训练场景,具备更大的潜力成为开箱即用的精度格式。TF32的引入也得益于NV从Pascal时代对低精度训练的持续投入迭代,通过多轮实际系统的交付以及客户互动,获得了宝贵的反馈输入,最终催生了TF32的数据格式。看到TF32格式的引入,还是会对NV这家公司充满了敬意,因为这是一家在不断push自身边界的公司,期望未来能够保持这种态势。
对Tensor Core的尺寸进行了增加,由Volta/Turing代际的4x4x4增大到8x8x4,每个cycle可以完成128~256 个FMA操作,进一步改善数据复用,提升了计算密度(GA100是256 ,GA10x是128 )。
第三代NVLink(NVSwitch)。Ampere架构的NVSwitch和上一代的区别是将带宽提升了一倍,理论上,任意两块GPU之间,都可以达到最高达600GB/s的双向带宽。
引入了MIG。用于提供硬件层面的单GPU多任务安全隔离。不过坦率说,我听到这个特性的使用案例似乎并不多。
结构化稀疏。这个特性从刚引入的很受关注,到现在渐渐有些期望回调。究其原因,涉及到侵入用户训练过程的优化手段,如果不是非常显著的收益,接受起来往往会有一定门坎。
HBM显存增加到40GB/80GB的配置,适配大模型训练的显存压力。带宽相较V100代际也有1.7X的提升,达到1.5TB/s。
大幅提升片上L2容量,从V100的6MB激增到40MB,这往往意味着基于工作负载反馈拿到了重要的架构决策所需的数据输入才可能支撑这么激进的的架构决策。L2访问带宽相较V100提升2.3X。Ampere架构里,L2到SM的crossbar不再是全连接,而是分拆成两个L2 sub-partition,每个sub-partition只服务于直接和其相连的SM。L2尺寸的增加和L2 sub-partition的引入其实是整个架构决策的一体两面(减少L2和SM互联的crossbar的开销),互为补充。
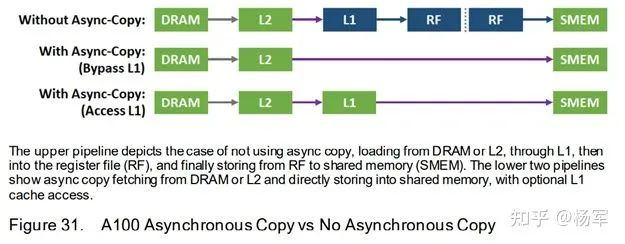
引入了用于异步数据copy的LDGSTS指令,可以bypass寄存器的中转,直接从global memory里将数据加载到shared memory,减少了寄存器的压力和不必要的数据中转,进一步节省了功耗。并且因为这条指令的异步性,可以作为背景操作和前台的计算指令overlap执行,进一步提升整体计算效率。
CUDA Graph在2018年被引入,用于优化小kernel的launch开销。在Ampere代际,为其加入了专门的硬件支持。时至今日,CUDA Graph已经是AI性能优化的重要依赖特性了,比如MLPerf里的诸多刷榜优化,以及Facebook也在2021年将CUDA Graph正式集成进PyTorch中。
加入了专用于JPEG格式解码的硬件decoder NVJPG,用于对数据预处理环节加速。以及大幅增加了用于视频解码的NVDEC的硬件资源,同理,也是为了对数据预处理环节加速。
更多细节可以参考这里的whitepaper( https://images.nvidia.com/aem-dam/en-zz/Solutions/data-center/nvidia-ampere-architecture-whitepaper.pdf )。 在Ampere时代,NV在整机之外,进一步推出集群解决方案SuperPOD,以及基于SuperPOD搭建的超算集群Selene,SuperPOD和Selene支持了Megatron-LM以及MLPerf training的大量性能优化工作,也作为解决方案,成功交付给了若干客户。这也是一个蛮有意思的行业信号。 软件方面,Ampere时代一个比较重要的工作是TensorRT和PyTorch的集成Torch-TensorRT,不过这个工作仍然面临一个大的挑战。那就是PyTorch的模型写法过于灵活,存在不少无法成功导出TorchScript的模型写法(比如NLP场景中decoding部分的循环生成结构),对于这部分如何进行高效自动推理加速,目前仍然是一个开放问题。 另一个NV GPU上软件相关有代表性的工作是对dynamic shape的支持,关于有效处理dynamic shape,大约从三年前业界就有过过呼声。TensorRT目前仍然是通过padding的策略来解决dynamic shape的问题。阿里在两个月前开源的BladeDISC是一个基于MLIR针对dynamic shape提供的E2E的AI编译解决方案,不过完备性还有待完善。Amazon的Nimble工作则基于TVM技术栈探索了另一条解决dynamic shape的技术方案。 无论是Torch-TensorRT,还是对dynamic shape的支持,都反映出对AI开箱即用性能优化的重视,这在一定程度上,也和AI当前更多进入到行业应用落地期的阶段有关。 模型方面,Ampere自2020年推出以后,直到现在,能够看到AI领域主要的关注焦点集中在大模型训练上。除了GPT-3,BERT类模型以外,MoE模型也受到了一定关注,相应地也催生了一系列工作,包括Google TPU之上的Gshard系列工作,GPU上的DeepSpeed-MoE工作等。但是大模型到底能够为业务层面带来多少实际收益,其收益是否足以justify新增的算力投入,是否需要更高效环保的模型设计方法以及AI算力提供方案,目前仍然是一个open的问题。 以上结合AI系统演进的视角,回顾了从Fermi到Ampere共7代架构,期望随着未来Ampere-Next以及Ampere-Next-Next的发布,我们可以再添加相关的内容,一起经历见证AI系统领域和NV GPU架构的共同演进发展。 这篇回顾涉及到了比较长的时间跨度,比较宽的技术区域,整个回顾内容,有些是我亲身经历的,有些是我基于获取到的一手或二手信息提炼的,还有一些则是根据网络上的资讯进行交叉校验后汇总出来的,难免会有疏漏或不够准确之处,也欢迎同行朋友的批评指正。 今日口令红包秘语:2022我们在一起
推荐阅读
深入理解生成模型VAE
SOTA模型Swin Transformer是如何炼成的!
快来解锁PyTorch新技能:torch.fix
集成YYDS!让你的模型更快更准!
辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了!
SimMIM:一种更简单的MIM方法
SSD的torchvision版本实现详解
机器学习算法工程师
一个用心的公众号

 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”