
从架构到部署,全面了解K3s
作者简介

Kubernetes无处不在——开发者的笔记本、树莓派、云、数据中心、混合云甚至多云上都有Kubernetes。它已然成为现代基础设施的基础,抽象了底层的计算、存储和网络服务。Kubernetes隐藏了各种基础设施环境之间的差异,它将多云变成了现实。
Kubernetes也成为了编排的通用控制平面,不仅仅是容器编排,还包括虚拟机、数据库,甚至SAP Hana实例等各种资源。
尽管Kubernetes发展迅猛,但还是给开发者和运营商抛出了许多挑战。其中一个关键挑战是在边缘运行Kubernetes。与云或数据中心相比,边缘是非常不同的。它运行在一个高度受限环境中的远程位置。与运行在数据中心的同类设备相比,边缘设备的计算、存储和网络资源只有一小部分。边缘设备与云的连接是断断续续的,而且它们主要在离线环境中运行。这些因素使得很难在边缘部署和管理Kubernetes集群。
基于此,业界应用最为广泛的K8S管理平台创建者Rancher Labs发布了K3s,这是一个Kubernetes的发行版,它针对边缘进行了高度优化。虽然K3s是Kubernetes的简化版、迷你版,但API的一致性和功能并没有受到影响。从kubectl到Helm再到Kubernetes,几乎所有的云原生生态系统的工具都能与K3s无缝对接。实际上,K3s是一个经过CNCF认证的、符合要求的Kubernetes发行版,可以在生产环境中部署。几乎所有运行完整的Kubernetes集群的工作负载都能保证在K3s集群上工作。
Kubernetes这个10个字母的单词,在社区里被称为K8S。由于K3s正好是Kubernetes内存的一半,Rancher为新的发行版找到了一个5个字母的单词,并将其简称为K3s。
深入了解K3s架构
K3s的魅力在于它的简单性。作为一个单一的二进制文件(约100MB)进行打包和部署,你只需几秒钟就可以得到一个完全成熟的Kubernetes集群。安装体验就像在集群的每个节点上运行一个脚本一样简单。
K3s二进制文件是一个自给自足的封装实体,它几乎运行了Kubernetes集群的所有组件,包括API server、scheduler和controller。默认情况下,每个K3s的安装都包括控制平面、kubelet和containerd运行时,这些已经足以运行Kubernetes工作负载。当然,也可以添加只运行kubelet agent和containerd运行时的专用worker节点,来调度和管理pod生命周期。
与传统的Kubernetes集群相比,K3s中的master节点和worker节点没有明显的区别。可以在任何节点上调度和管理Pod,不管它们扮演的是什么角色。所以,master节点和worker节点的命名方式不适用于k3s集群。
在k3s集群中,将运行控制平面组件与kubelet的节点称为server,而只运行kubelet的节点称为agent。server和agent都有容器运行时和一个kubeproxy,管理整个集群的tunnel和网络流量。
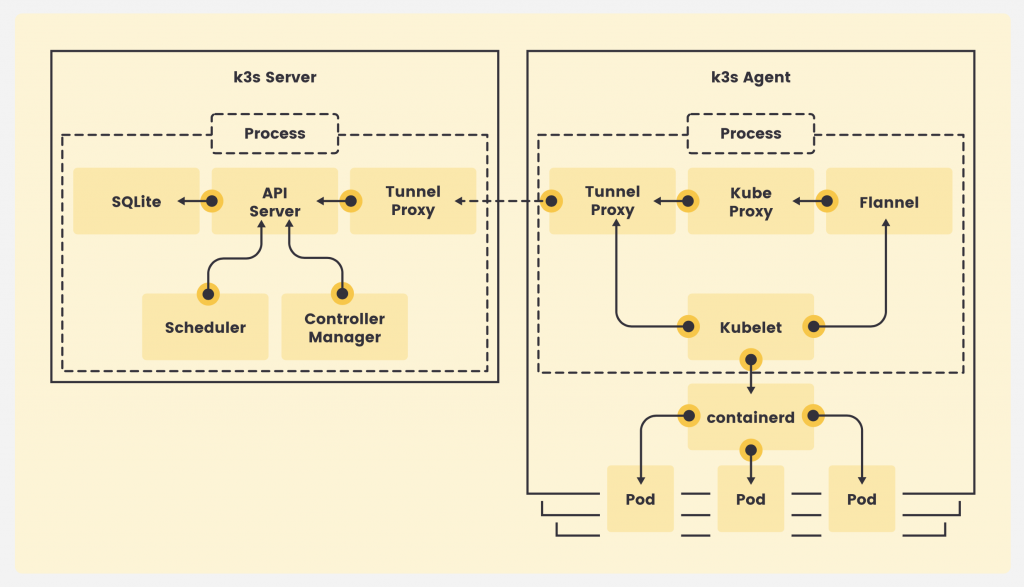
在典型的k3s环境中,你运行一个server和多个agent。在安装过程中,如果你传递了server的URL,节点就会变成一个agent;否则,你最终会运行另一个独立的k3s集群,有自己的控制平面。
那么,Rancher是如何降低k3s的内存呢?首先,他们去除了Kubernetes的很多可选组件,这些组件对于运行一个最低限度的集群来说并不重要。然后,它增加了一些必要的元素,包括containerd、Flannel、CoreDNS、CNI、Traefik ingress controller、本地存储程序、一个嵌入式服务负载均衡器和一个集成的网络策略controller。所有这些组件都被打包成一个二进制文件,并在同一个进程中运行。除了这些,该发行版还支持开箱即用的Helm chart。
上游的Kubernetes发行版是臃肿的,有很多代码可以删除。例如,存储volume插件和云提供商API,这些会极大增加发行版的内存。K3s省略了所有这些,以最大限度地减少二进制的大小。
另一个关键的区别是集群状态的管理方式。Kubernetes依靠分布式键值数据库etcd来存储整个集群的状态。K3s用名为SQLite的轻量级数据库取代了etcd,SQLite是一个成熟的嵌入式场景数据库。很多移动应用都会捆绑SQLite来存储状态。
通过在至少三个节点上运行etcd,Kubernetes控制平面变得高度可用。另一方面,SQLite并不是分布式数据库,它成为为了实现控制平面的高可用,K3s server可以指向外部数据库端点。支持的数据库包括etcd、MySQL和PostgreSQL。通过有效地将状态委托给外部数据库,K3s支持多个控制平面实例,使得集群具有高可用性。
Rancher正在试验一种名为DQLite的分布式版本的SQLite,它最终可能会成为K3s的默认数据存储。
K3s最大的优点是它的 “包含电池但可替换 "的方式。例如,我们可以用Docker CE运行时替换containerd运行时,用Calico替换Flannel,用Longhorn替换本地存储等等。
关于K3s架构的详细讨论,我强烈推荐你观看K3s的架构师Darren Shepherd在北美KubeCon 2019上的演讲:
https://youtu.be/-HchRyqNtkU
K3s部署场景和拓扑结构
K3s发行版支持多种架构,包括AMD64、ARM64和ARMv7。凭借一致的安装体验,K3s可以在Raspberry Pi Zero、NVIDIA Jetson Nano、Intel NUC或Amazon EC2 a1.4xlarge实例上运行。
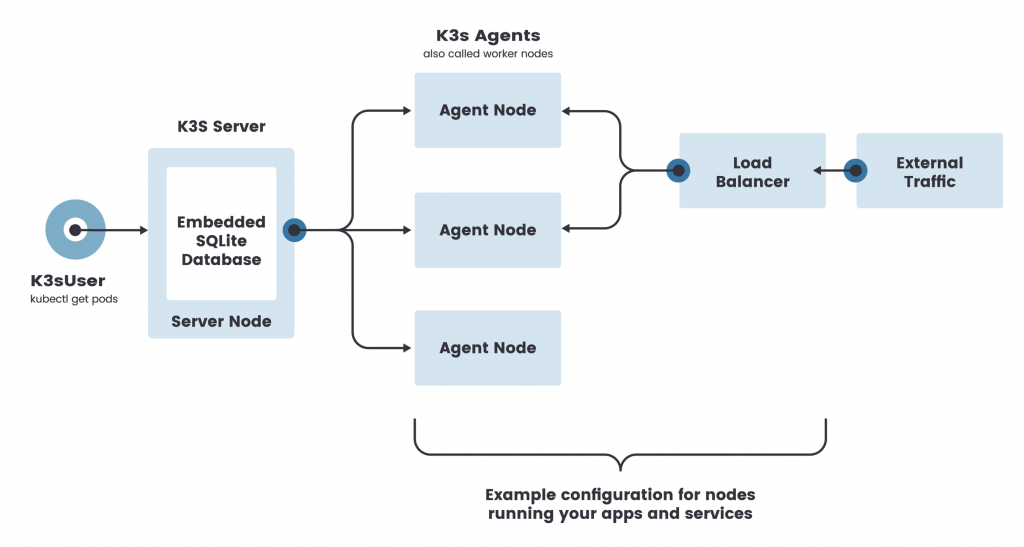
在你需要一个单节点Kubernetes集群来维护部署manifest的相同工作流程的环境中,请在服务器或边缘设备上安装K3s。这使你可以灵活地使用你现有的CI/CD流水线和容器镜像以及Helm chart或YAML文件。
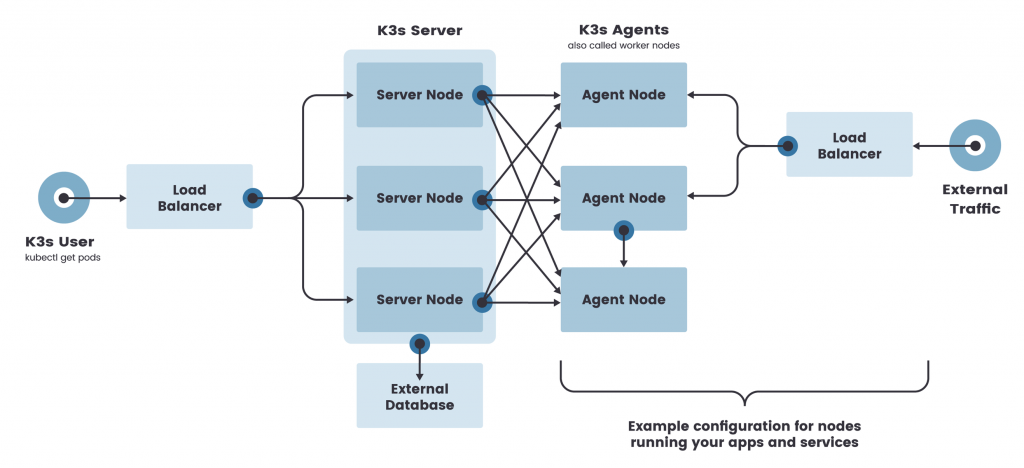
如果你需要一个在AMD64或ARM64架构上运行的高可用集群,安装一个3节点的etcd集群,然后是3个K3s server和一个或多个agent。这样就可以为你提供一个生产级的环境,并为控制平面提供HA。
当在云中运行K3s集群时,将server指向一个托管数据库,如Amazon RDS或Google Cloud SQL,以运行一个具有多个agent的高可用控制平面。每个K3s server可以运行在不同的可用性区域,以获得最大的正常运行时间。
如果你在具有可靠的、始终在线连接的边缘计算环境中运行K3s,则在云中运行server,在边缘运行agent。这使你可以灵活地在云中运行一个高可用和可管理的控制平面,同时在远程环境中运行agent。
最后,你可以将K3s HA控制平面部署在5G边缘位置,如AWS Wavelength和Azure Edge Zones环境中,agent在设备中运行。这种拓扑结构呼应了智能建筑、智能工厂和智能医疗场景。
在此系列的下一篇文章中,我将介绍在边缘环境中部署HA集群的步骤,保持关注!
原文链接:
https://thenewstack.io/how-rancher-labs-k3s-makes-it-easy-to-run-kubernetes-at-the-edge/
推荐阅读
扫码添加k3s中文社区助手
加入官方中文技术社区
官网:https://k3s.io