
AI技术课堂 | 深度解读词嵌入技术的基础原理

引言
词嵌入是生成式人工智能中的一项关键技术,是一种将词语或短语从词汇表(可能包含数千或数百万个词语)映射到向量的实数空间的技术。这些嵌入捕获了词语之间的相似性,因此相似的词语会被映射到相近的点。词嵌入可以分为两类:基于计数的方法和预测方法。基于计数的方法计算某词语与其邻近词语在大型文本语料库中共同出现的频率及其他统计量,然后将这些统计量映射到一个小的、密集的向量。预测方法则试图直接从某词语的邻近词语预测该词语,预测模型的参数即为词嵌入。
词嵌入在自然语言处理(NLP)中有许多具体的应用,包括但不限于以下几个方面:
1. 情感分析:词嵌入可以帮助机器理解文本的情感,例如判断用户评论是正面的还是负面的。
2. 文本分类:词嵌入可以用于新闻分类、垃圾邮件检测等任务,帮助机器理解文本的主题并进行分类。
3. 命名实体识别:通过词嵌入,机器可以识别出文本中的特定实体,如人名、地名、组织名等。
4. 机器翻译:词嵌入在机器翻译中也起着关键作用,帮助机器理解源语言,并将其准确地翻译成目标语言。
5. 语义搜索:词嵌入可以用于搜索引擎,提高搜索结果的相关性,使搜索结果更符合用户的查询意图。
6. 问答系统:词嵌入可以帮助问答系统理解用户的问题,并提供准确的答案。
7. 语音识别:词嵌入可以帮助语音识别系统理解用户的语音指令,并执行相应的操作。
8. 聊天机器人:词嵌入可以帮助聊天机器人理解用户的输入,并生成自然、相关的回复。
总的来说,词嵌入是许多自然语言处理任务的基础,它使机器能够理解和处理人类语言,从而实现更高级的功能。
词嵌入技术的发展历史
以下是关于词嵌入(Word Embedding)发展历史的时间线图表:
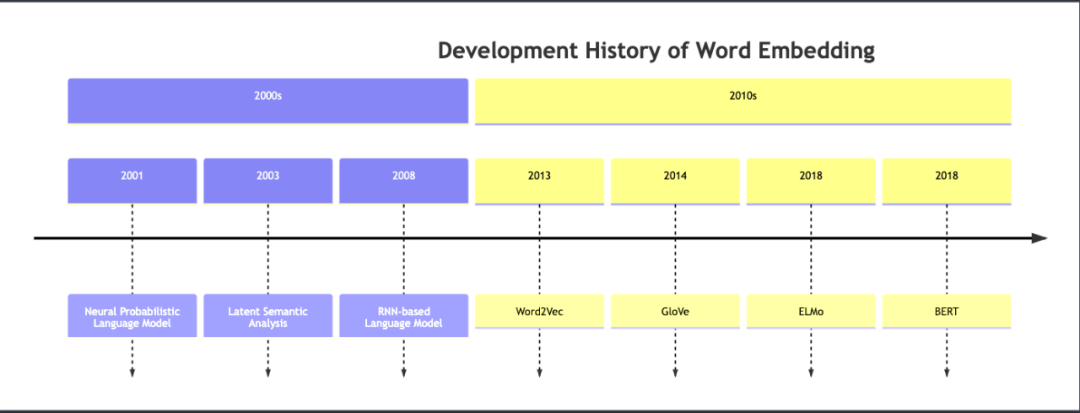
这个图表以时间线的形式展示了 Word Embedding 的发展历程。从2000年代开始,我们看到了如下的一些关键发展:
-2001年:神经概率语言模型(Neural Probabilistic Language Model)
-2003年:潜在语义分析(Latent Semantic Analysis)
-2008年:基于 RNN 的语言模型(RNN-based Language Model)
进入2010年代,Word Embedding 的发展进一步加速:
-2013年:Word2Vec
-2014年:GloVe
-2018年:ELMo 和 BERT
以上就是词嵌入技术的主要发展历程。
词嵌入的技术生态图
下图对词嵌入的技术生态进行的归纳。

上图展示了词嵌入的各种分类,包括类型(基于计数方法还是预测方法)、预测方法的具体实现(如Word2Vec和FastText)、考虑上下文的模型(如ELMo和Transformers)、评估方法(内在和外在)以及它的应用(NLP任务)。
词嵌入的质量可以通过两种主要的方式进行评估:内在评估和外在评估。内在评估通过直接测量嵌入的质量,例如通过词语相似性任务或词语类比任务。外在评估则通过测量在某个下游任务(如文本分类或命名实体识别)上的性能来间接评估嵌入的质量。
如图所示,能够实现词嵌入的技术方案较多,本系列文章主要关注如下几种。
· Word2Vec:是一种预测模型,用于学习词嵌入。它有两种变体:连续词袋模型(CBOW)和Skip-Gram模型。CBOW模型预测目标词语(如“猫”)给定其上下文(如“黑色的”和“跳上了桌子”)。Skip-Gram模型则反过来,预测上下文给定目标词语。
· GloVe:是一种基于计数的模型,它结合了上述两种方法的优点。GloVe首先构造一个大型的共现矩阵,然后对这个矩阵进行分解,得到词嵌入。
· FastText:是一种预测模型,它与Word2Vec类似,但是FastText预测的是包含字符n-gram的词语。这使得FastText能够理解词根、词缀等词语内部的结构,因此对于形态丰富的语言(如土耳其语)特别有用。
· ELMo:是一种预测模型,它考虑了词语的上下文。与Word2Vec和GloVe不同,ELMo为每个词语生成不同的嵌入,这取决于词语的上下文。例如,"bank"在"he deposited money in the bank"和"he sat on the bank of the river"中的含义是不同的,因此它的嵌入也应该不同。
· Transformer(变换器)模型:如BERT和GPT-2/3/4,使用了自注意力机制,可以捕获词语之间的复杂关系。这些模型在许多NLP任务中都取得了最先进的效果。
围绕word2vec的词嵌入技术演变
以下是以围绕word2Vec词嵌入技术的演变图:
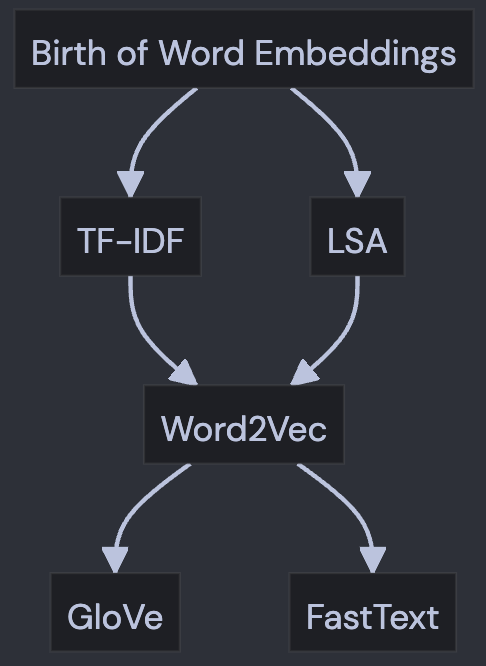
上图解释如下:
· "Birth of Word Embeddings" 是词嵌入技术的起源。
· 从那里,我们看到了两种早期的词嵌入技术的发展,即 "TF-IDF" 和 "LSA"。
· 这两种技术都为 "Word2Vec" 的出现铺平了道路,Word2Vec 是一种更先进的词嵌入模型。
· 最后,我们看到 "Word2Vec" 为 "GloVe" 和 "FastText" 的开发提供了基础,这两种技术都是当前最先进的词嵌入模型。
TF-IDF 例解
TF-IDF (Term Frequency-Inverse Document Frequency) 是一种用于信息检索和文本挖掘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF-IDF由两部分组成:TF和IDF。
· TF (Term Frequency),词频,即某个词在文章中出现的频率。计算公式为:某个词在文章中出现的次数 / 文章的总词数。
· IDF (Inverse Document Frequency),逆文档频率。如果包含词条的文档越少,IDF越大,则说明词条具有很好的类别区分能力。计算公式为:log(语料库的文档总数 / 包含某个词的文档数+1)。
最后,将TF和IDF相乘,就得到了一个词在文章中的重要程度。值得注意的是,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语料库中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取前N个就可以了。
01
通过例子来理解 TF-IDF 的机制
假设我们有三篇只包含一句话的文章:
1. 文章A: "The cat sat on the mat."
2. 文章B: "The dog sat on the log."
3. 文章C: "Cats and dogs are mortal enemies."
首先,我们创建一个包含所有单词的词汇表:{the, cat, sat, on, mat, dog, log, cats, and, dogs, are, mortal, enemies}。
然后,我们计算每篇文章中每个词的TF-IDF值。TF-IDF是一个衡量词在文档中重要性的统计方法,由词频(TF)和逆文档频率(IDF)两部分组成。
以文章A中的"cat"为例:
· 词频(TF):文章A中"cat"出现一次,文章总词数为6,所以TF = 1/6 = 0.167。
· 逆文档频率(IDF):"cat"出现在文章A和C中,总共有3篇文章,所以IDF = log(3/2) = 0.176。
· 因此,"cat"在文章A中的TF-IDF值为TF * IDF = 0.167 * 0.176 = 0.029。
我们可以对文章A、B、C中的每个词重复这个过程,得到每个词在每篇文章中的TF-IDF值,这些值可以用作词嵌入,表示每个词的重要性。
注:TF-IDF的归一化处理
量化过程中存在一个问题,例如,当某个词如"the"IDF值为0,导致TF-IDF值为0。但在向量化过程中,文档中未出现的词(如某篇文章未出现的词如"tiger")也会被赋值为0。为了避免混淆,我们通常会对TF-IDF值进行平滑处理,最常见的方法是将值加1。根据需要,这些值可以进行归一化处理。
对于上述三篇文章的例子,我们可以计算出每个词的 TF、IDF、TF-IDF、和最终的词向量。以下是计算结果(注意,这里的计算是基于这三篇文章的,实际应用中,TF-IDF的计算通常是基于一个大规模的语料库):
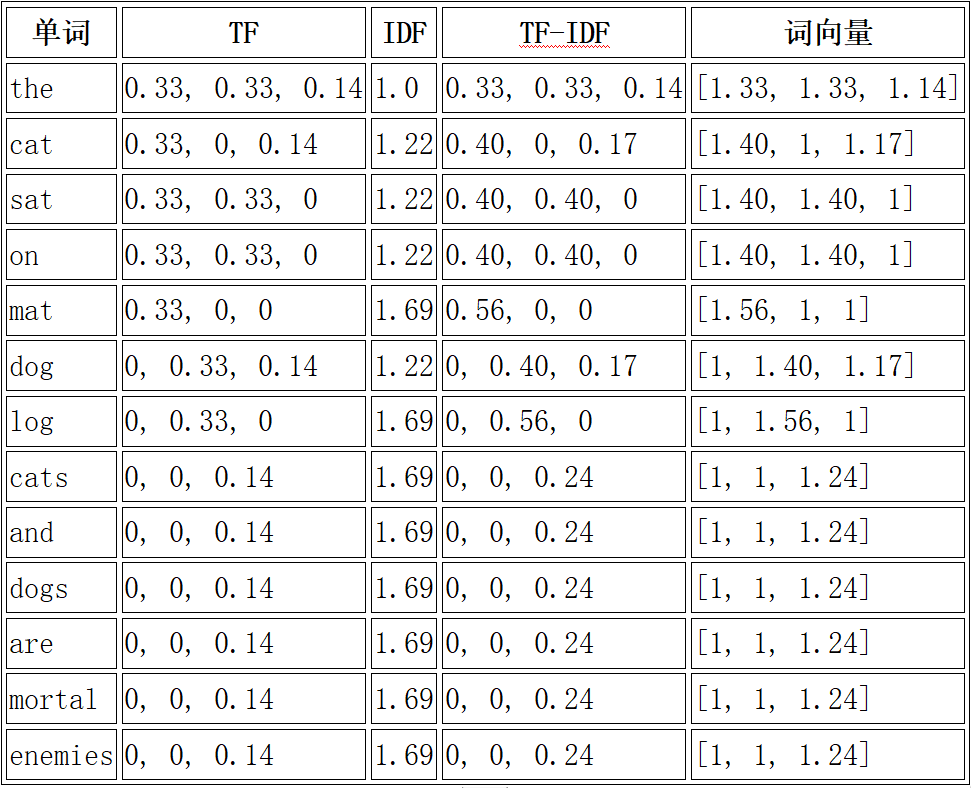
在这个例子中,我们对 TF-IDF 值进行了平滑处理,即将所有的 TF-IDF 值加1,以避免混淆。
对于上述三篇文章的例子,我们可以为每篇文章创建一个向量。向量的长度为所有文档中的唯一单词的数量,即13。向量中的每个元素值是该单词在本文档中的 TF-IDF 值。如果某个词没有在文章中出现,其对应的向量位置的值设为 0。以下是计算结果:
· 文章A的向量:[1.33, 1.40, 1.40, 1.40, 1.56, 0, 0, 0, 0, 0, 0, 0, 0]
· 文章B的向量:[1.33, 0, 1.40, 1.40, 0, 1.40, 1.56, 0, 0, 0, 0, 0, 0]
· 文章C的向量:[0, 1.17, 0, 0, 0, 1.17, 0, 1.24, 1.24, 1.24, 1.24, 1.24, 1.24]
这些向量更准确地表示了每篇文章的词汇分布。对于没有在文章中出现的词,其对应的向量位置的值为 0,这样可以更好地区分文章的内容。
02
TF-IDF的优缺点分析
TF-IDF是一种常用的文本分析方法,它通过计算词频(TF)和逆文档频率(IDF)来衡量一个词在文本中的重要性。
TF-IDF的一个主要优点是它能够区分出对文档意义影响较大的单词。这是因为TF-IDF不仅考虑了单词在文档中出现的频率(TF),还考虑了单词在整个文档集合中的分布情况(IDF)。
例如,考虑两个单词:"the"和"rocket"。在一篇关于太空探索的文章中,"the"可能出现的频率非常高,但是它几乎在所有的英文文章中都会出现,因此它对于文章的意义贡献不大。相反,"rocket"可能出现的频率较低,但是它只在少数一些关于太空或科技的文章中出现,因此它对于文章的意义贡献较大。TF-IDF就能够通过降低"the"的权重,提高"rocket"的权重,从而更好地反映出文章的主题。
TF-IDF的一个主要缺点是它无法处理单词的同义词和多义词问题。这是因为TF-IDF是基于单词的字面意义进行计算的,它无法理解单词的语义。
例如,考虑两个单词:"car"和"automobile"。这两个单词的意思是相同的,但是TF-IDF会将它们视为两个完全不同的单词。因此,如果一个文档中出现了"car",而另一个文档中出现了"automobile",那么TF-IDF可能会认为这两个文档的相似度不高,尽管它们实际上是在讨论同一个主题。
另一个TF-IDF的缺点是,它假设所有的单词都是独立的,不考虑单词之间的顺序和语境。这就导致TF-IDF无法理解词组或短语的意义,也无法处理否定和讽刺等复杂的语言现象。
为了改进这些问题,我们可以考虑使用其他类型的词嵌入方法,如Word2Vec或GloVe,这些方法可以捕捉到词之间的语义关系,并且可以处理词频偏斜的问题。
01
概述
LSA (Latent Semantic Analysis),潜在语义分析,是一种自然语言处理、信息检索的技术,用于分析和比较文档中的语义结构。LSA 使用统计计算方法以及无监督的学习技术在大量文本数据中寻找隐藏的(latent)语义结构。这种技术基于奇异值分解(SVD)对词-文档矩阵进行降维,挖掘词与词之间、文档与文档之间以及词与文档之间的关系。通过将单词和文档映射到一个"概念"空间来理解语义。这个"概念"空间是一个多维空间,其中每个维度代表一个"概念"或"主题"。例如,如果我们在处理新闻文章,那么这些"概念"可能包括"政治"、"经济"、"体育"等。
LSA 使用词-文档矩阵(行代表唯一的单词,列代表文档),其中每个元素表示特定单词在特定文档中出现的频率。然后,LSA 对这个矩阵进行奇异值分解(SVD),得到的结果可以用于识别文档和单词之间的模式。SVD 是一种矩阵分解技术,它将原始矩阵分解为三个矩阵的乘积,这三个矩阵分别代表了单词、概念和文档。
LSA 被广泛应用于信息检索和信息过滤等任务。例如,搜索引擎可以使用 LSA 来理解用户的查询,然后找到最相关的文档。此外,LSA 还被用于自动文档分类、自动文档摘要、自动文档链接等任务。例如,新闻聚合网站可以使用 LSA 来自动分类新闻文章,或者生成新闻摘要。
LSA 的发展历史可以追溯到20世纪80年代,当时的研究主要集中在信息检索领域。随着时间的推移,LSA 的应用领域已经扩展到了许多其他的自然语言处理任务。例如,LSA 现在也被用于情感分析、机器翻译和语音识别等任务。
02
LSA的工作机理
下面的图表,展示了 LSA 如何将文档和单词映射到一个"概念"空间,以及如何在各种 AI 应用中使用这种映射。
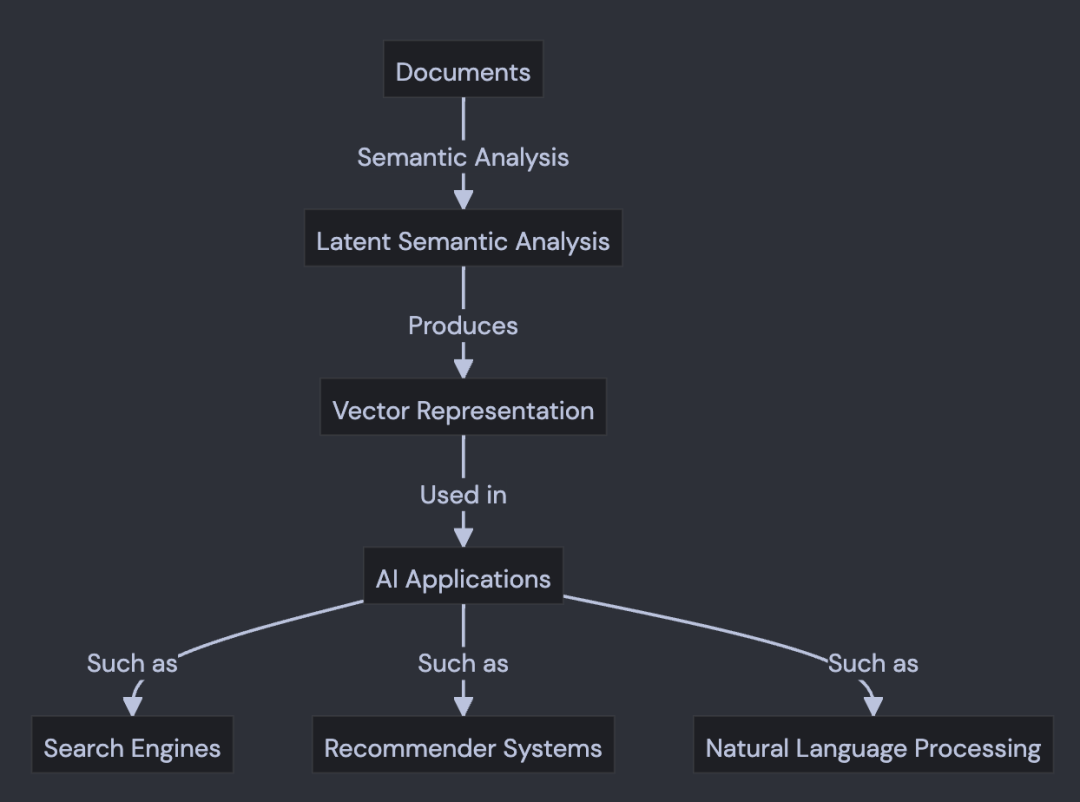
LSA的主要步骤包括:
1. 创建一个词-文档矩阵,其中每个元素表示一个词在一个文档中出现的频率。
2. 对词-文档矩阵进行奇异值分解(SVD),得到三个矩阵:词矩阵、奇异值矩阵和文档矩阵。
3. 通过保留前k个最大的奇异值来近似词-文档矩阵,这样就可以减少噪声和提取最重要的语义特征。
假设我们有以下三篇文章:
1. 文章A: "The cat sat on the mat."
2. 文章B: "The dog sat on the log."
3. 文章C: "Cats and dogs are mortal enemies."
首先,我们需要创建一个词-文档矩阵。在这个例子中,我们的矩阵可能如下所示:
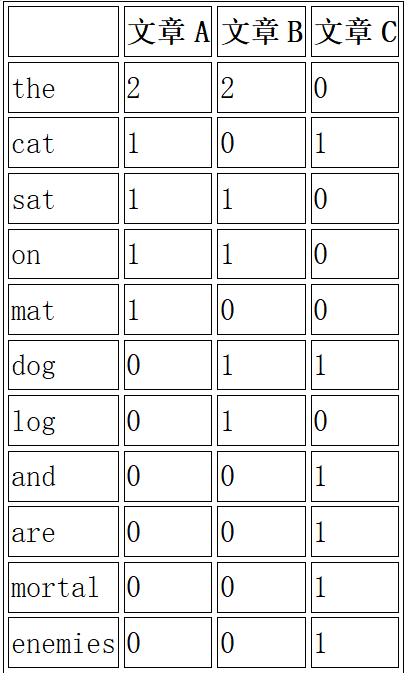
然后,我们对这个矩阵进行奇异值分解(SVD),得到三个矩阵:U(词矩阵)、Σ(奇异值矩阵)和V(文档矩阵)。我们可以通过保留前k个最大的奇异值来近似词-文档矩阵,这样就可以减少噪声和提取最重要的语义特征。
我们采用可以通过Python 程序进行奇异值分解。由于篇幅关系,我没有把源代码放在这里,感兴趣的读者,可以联系作者。
我们的计算结果如下:
Sigma values: [3.77394233 2.39944979]
在上述例子中,我们使用了奇异值分解(SVD)对词-文档矩阵进行分解,得到了三个矩阵:U、Σ和V。
1. U 矩阵:这是一个词-主题矩阵,每一行对应一个词,每一列对应一个主题。在这个例子中,我们选择了两个主题(由 n_components 参数决定),所以 U 矩阵有两列。U 矩阵的每个元素表示对应的词在对应的主题中的权重。例如,U 矩阵的第一行 [2.7876937, -0.47829262] 表示第一个词 "the" 在两个主题中的权重。
2. Σ 矩阵:这是一个对角矩阵,对角线上的元素是奇异值,表示了每个主题的重要性。在这个例子中,我们有两个主题,所以 Σ 矩阵有两个元素 [3.77394233, 2.39944979],第一个主题的重要性更高。
3. V 矩阵:这是一个文档-主题矩阵,每一行对应一个主题,每一列对应一个文档。在这个例子中,我们有三篇文档,所以 V 矩阵有三列。V 矩阵的每个元素表示对应的文档在对应的主题中的权重。例如,V 矩阵的第一列 [0.69692343, -0.11957316] 表示第一篇文档 "文章A" 在两个主题中的权重。
通过这三个矩阵,我们可以得到每个词在每个主题中的权重,每个文档在每个主题中的权重,以及每个主题的重要性。这为我们提供了一种理解和表示词、文档和主题关系的方式。
注:LSA中的“主题”的解释
在上述例子中,“两个主题”是指我们在进行奇异值分解(SVD)时选择的主题数量。这个数量是可以自由选择的,它决定了我们想要从数据中提取多少个主题或概念。
主题在这里可以被理解为一组相关的词的集合,这些词在一起可以表示某种特定的概念或主题。例如,在一个关于体育的文档集中,一个主题可能包含像“球队”、“比赛”、“运动员”这样的词,而另一个主题可能包含像“训练”、“健身”、“健康”这样的词。
在我们的例子中,我们选择了两个主题,这意味着我们试图找到两组词,这两组词可以最好地表示我们的文档集的主题或概念。然而,这两个主题具体代表什么,通常是难以直接解释的,因为它们是通过机器学习算法从数据中自动提取出来的,可能并不直接对应我们通常理解的具体主题。
最后,我们可以使用U矩阵中的行作为词嵌入。这些嵌入不仅考虑了词频,还考虑了词语之间的语义关系。例如,"cat"和"dog"可能会有相似的嵌入,因为它们在文档中出现的上下文相似。
03
LSA的优劣势分析
潜在语义分析(LSA)是一种常用的文本分析方法,它通过分析单词的共现模式,将单词映射到一个"概念"空间,从而能够处理单词的同义词和多义词问题。例如,"汽车"和"车辆"这两个词虽然字面上不同,但在很多上下文中,它们的意思是相同的,LSA能够识别出这种语义相似性。
LSA 的一个主要优点是它能够处理单词的同义词和多义词问题。例如,LSA 能够理解"汽车"和"车辆"是同义词。举个具体的例子,考虑两个句子:"我需要一支笔来写信"和"我需要一支钢笔来书写一封信件"。尽管这两个句子中的单词并不完全相同,但是它们的意思是相似的。如果我们只是基于单词的字面意义来比较这两个句子,可能会认为它们的相似度不高。但是,如果我们使用LSA,那么这两个句子会被映射到相近的位置,因为它们都涉及到"写"和"信"这两个概念。
然而,LSA也存在一些缺点。首先,由于LSA基于的是词-文档矩阵,这个矩阵只记录了每个单词在每个文档中出现的频率,而没有记录单词出现的顺序,因此,LSA无法处理词序信息。例如,"猫追狗"和"狗追猫"这两个句子的意思完全不同,但在LSA中,它们会被映射到完全相同的位置。
另一个LSA的缺点是,当处理大规模数据集时,可能会遇到计算复杂性问题。因为LSA需要对词-文档矩阵进行奇异值分解,这个操作的计算复杂性随着文档数量和词汇表大小的增加而增加。
TF-IDF 和 LSA的对比小结
1. TF-IDF是一种用于计算词语重要性的数值方法,它只考虑了词频(TF)和逆文档频率(IDF)两个因素,没有考虑词语的语义信息。
2. LSA是一种用于从文本数据中提取语义结构的方法,它通过对词-文档矩阵进行奇异值分解,可以挖掘词语之间的语义关系。
3. TF-IDF更注重于单个文档中词语的重要性,而LSA更注重于整个语料库中词语的语义关系。
4. TF-IDF计算简单,容易理解,但是无法捕捉词语的语义关系。LSA虽然计算复杂,但是可以提取出词语的语义信息。
本文为“词嵌入技术详解系列之基础技术(上篇)”,了解更多请点击以下链接:
关联 · 阅读
词嵌入技术详解系列之基础技术(下篇)
报告推荐


推荐阅读
本文由「流媒体网」原创出品,



