
Pulsar 技术系列 - 深度解读Pulsar Schema


导读
Apache Pulsar 是一个多租户、高性能的服务间消息传输解决方案,支持多租户、低延时、读写分离、跨地域复制、快速扩容、灵活容错等特性。数平MQ团队对 Pulsar 做了深入调研以及大量的性能和稳定性方面的优化。本文是Pulsar技术系列中的一篇,主要介绍Pulsar Schema。

为什么使用Pulsar Schema?
如果 producer 端要发送 POJO 类型的数据,则 Pulsar 需要一套序列化和反序列化工具,先将对象转化为字节数据再发送出去,下面为有无 schema 的两种情况:
无 Schema 的情况:
若在不指定 schema 的情况下创建 producer,则 producer 只能发送字节数组类型的消息。在有 POJO 类数据要发送时,需要在发送消息前将 POJO 序列化为字节。
代码示例:
Producer<byte[]> producer = client.newProducer().topic(topic).create();User user = new User(“Bill”, 40);byte[] message = … // serialize the `user` by yourself;producer.send(message);
有 Schema 的情况:
若在指定 schema 的情况下创建 producer,则 producer 可以直接将类发送到 topic,无需考虑如何将 POJO 序列化为字节。
代码示例:
Producer<User> producer = client.newProducer(JSONSchema.of(User.class)).topic(topic).create();User user = new User(“Bill”, 40);producer.send(user);
此外,在上述 producer 发送数据、consumer 接收数据的流程中,还需考虑以下情况:
信息对象里是否有字段缺失
结构里是否有字段类型发生改变
在这些情况下,为保证生产-消费模式的正常运行,所有 producer 与其相对应的 consumer 都需要进行相同的变化,若引入 schema 机制,可以简化上述操作。
Pulsar Schema基本概念
Pulsar Schema 包含:
Schema Type
Pulsar Schema 支持的类型可分为 Primitive type 和 Complex type
Primitive type 包含的类型有 :
Primitive type | 描述 |
BOOLEAN | 1 比特二进制数值 |
INT8 | 8 位有符号整数 |
INT16 | 16 位有符号整数 |
INT32 | 32 位有符号整数 |
INT64 | 64 位有符号整数 |
FLOATE | 单精度浮点数 |
DOUBLE | 双精度浮点数 |
BYTES | 字节序列 |
STRING | Unicode 字符集序列 |
TIMESTAMP(DATE, TIME) | 时间戳,保存形式为 64 位有符号整数 |
INSTANCE(2.7 版本新增) | 精度为纳秒的瞬时时间 |
LOCAL_DATE(2.7 版本新增) | 本地时间,格式为:yyyy-mm-dd |
LOCAL_TIME(2.7 版本新增) | 本地时间,格式为:hh-mm-ss |
LOCAL_DATE_TIME(2.7 版本新增) | 本地时间,格式为:yyyy-mm-dd : hh-mm-ss |
Complex type 目前支持的类型有:
Complex type | 描述 |
key/value | 表示键值对 |
struct | 表示 AVRO、JSON 和 Protobuf |
Key/Value :
该模式下,Pulsar 将键和值的 schemaInfo 存储在一起
Pulsar 提供以下两种编码方式:
类型 | 描述 |
INLINE | 键和值以消息有效负载的形式存储 |
SEPARATED | 键以消息键的形式存储,值以消息有效负载的形式存储 |
下面是使用 INLINE 编码类型构造 key/value schema:
Schema<KeyValue<Integer, String>> kvSchema = Schema.KeyValue(Schema.INT32,Schema.STRING,KeyValueEncodingType.INLINE);
Struct使用方式
Pulsar 提供以下三种方式使用 Struct:
Static
Generic
SchemaDefinition
1. Static:
如果我们已知要发送消息的数据类型,可以使用 static schema, 如下所示。
要发送的类为 User,结构如下:
public class User {String name;int age;}
使用 struct schema 创建生产者发送消息:
Producer producer = client.newProducer(Schema.AVRO(User.class)).create();producer.newMessage().value(User.builder().userName("Pulsar-user").userId(1L).build()).send();
使用 struct schema 创建消费者接收消息:
Consumer consumer = client.newConsumer(Schema.AVRO(User.class)).create();User user = consumer.receive();
2. Generic:
如果我们不知道要发送消息的数据类型,可以使用 GenericSchemaBuilder 定义 struct schema,如下所示。
使用 RecordSchemaBuilder 构建一个 schema:
RecordSchemaBuilder recordSchemaBuilder = SchemaBuilder.record("schemaName");recordSchemaBuilder.field("intField").type(SchemaType.INT32);SchemaInfo schemaInfo =recordSchemaBuilder.build(SchemaType.AVRO);Producer producer =client.newProducer(Schema.generic(schemaInfo)).create();
使用 RecordSchemaBuilder 构建一个 struct schema:
producer.newMessage().value(schema.newRecordBuilder().set("intField", 32).build()).send();
3. SchemaDefinition:
可以通过 SchemaDefinition 生成一个 struct schema,示例如下。
要发送的类为 User,结构如下:
public class User {String name;int age;}
使用 Schema Definition 生成一个 producer 并发送消息:
SchemaDefinition<User> schemaDefinition =SchemaDefinition.builder().withPojo(User.class).build();Producer<User> producer = client.newProducer(schemaDefinition).create();producer.newMessage().value(User.builder().userName("Pulsar-user").userId(1L).build()).send();
使用 SchemaDefinition 生成一个 consumer 并发送消息:
SchemaDefinition<User> schemaDefinition = SchemaDefinition.builder().withPojo(User.class).build();Consumer<User> consumer = client.newConsumer(schemaDefinition).subscribe();User user = consumer.receive();
SchemaInfo
SchemaInfo 是定义 schema的 一种数据结构,它包含以下字段:
字段 | 说明 |
name | schema 名称 |
type | schema 类型,类型常用的JSON格式 |
schema | schema 数据是一个由 8 位无符号字节和模式类型特定组成的序列 |
properties | 存放用户自定义属性 |
示例如下:
{"name": "test-string-schema","type": "STRING","schema": "","properties": {}}
Pulasr Schema 工作流程
在生产者端:
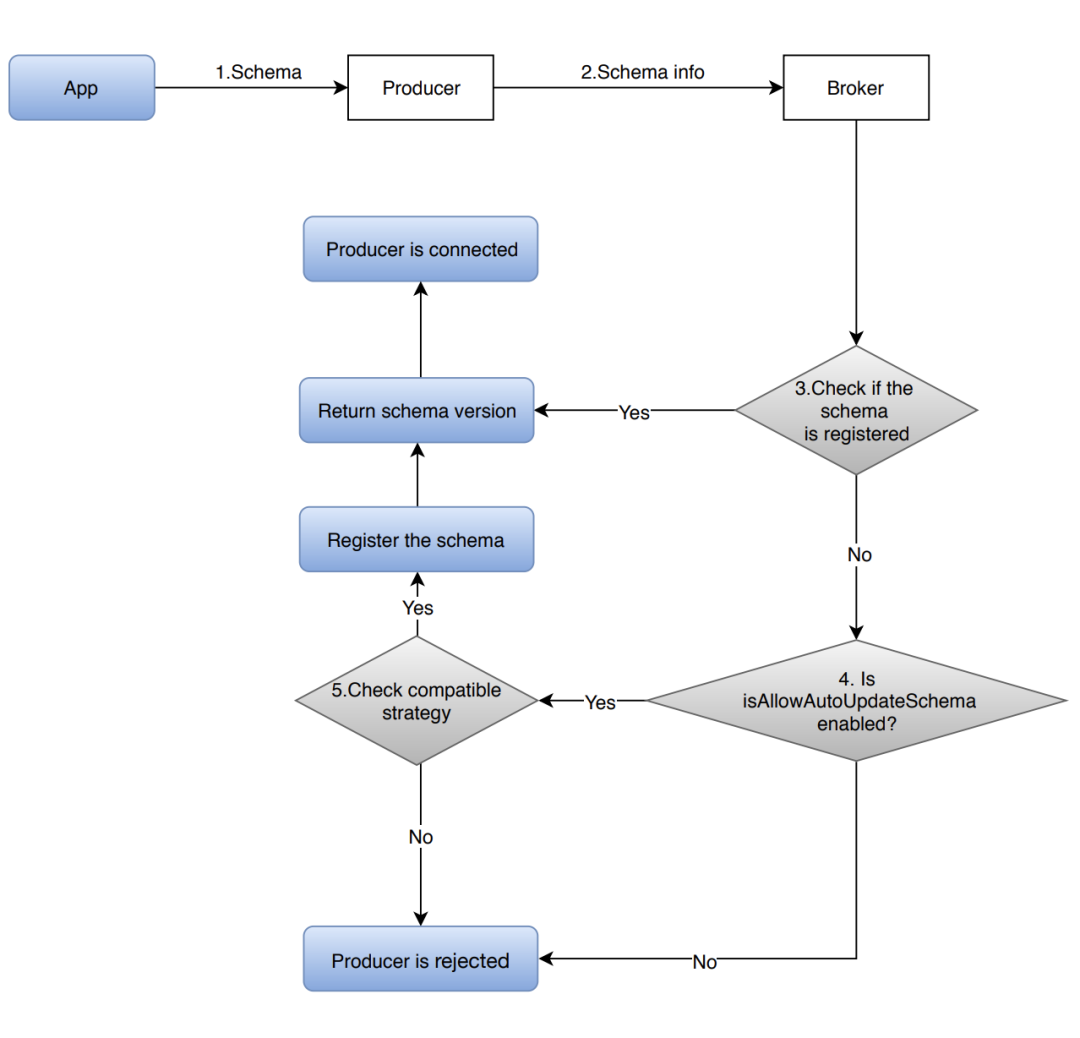

在消费者端:
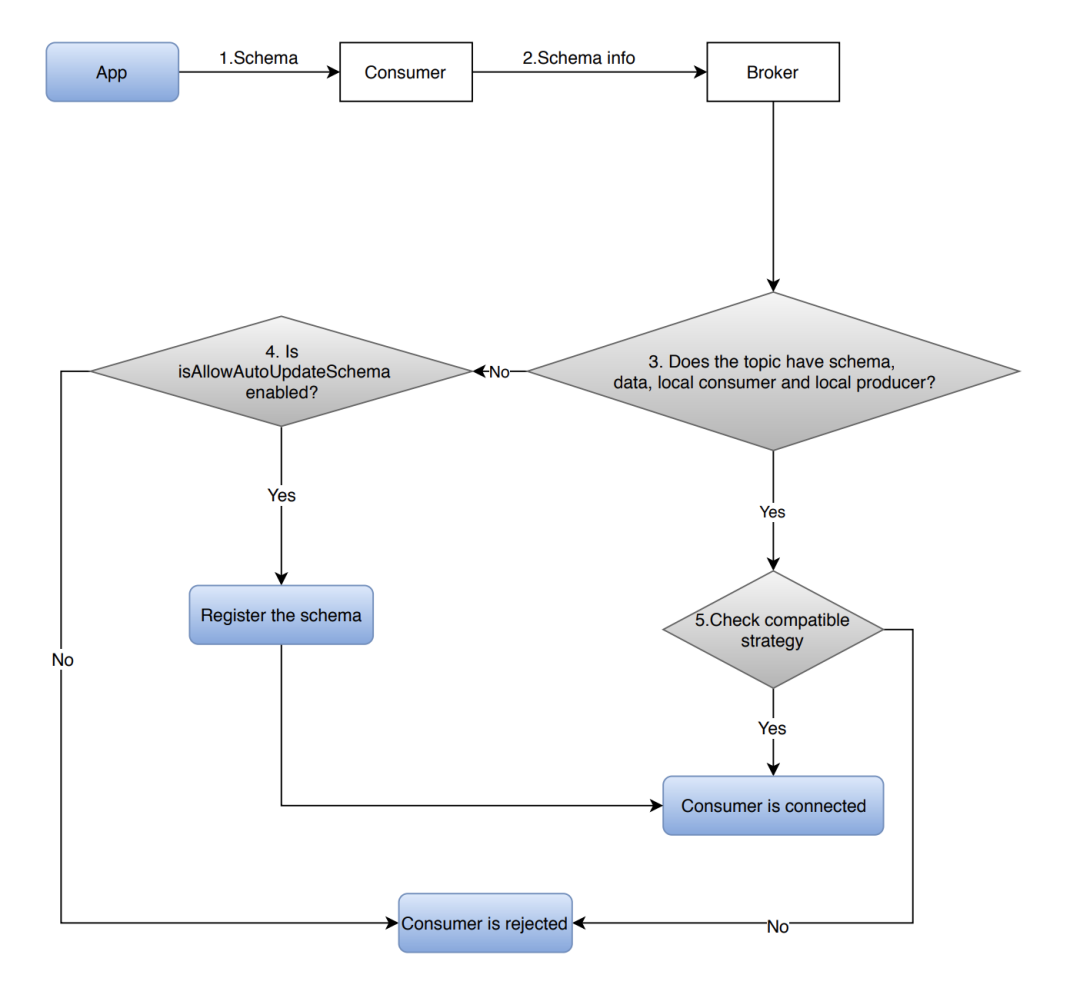

Pulsar Schema 机制
Schema Version
Org. apache. Pulsar.common. schema 的 SchemaInfo With Version 有两个字段:long 类型的 version 和 SchemaInfo 类型的 schemaInfo。Topic 下注册的 schema 会带有一个版本号,若版本号发生变化,需在原有版本号基础上+1。Producer 发送带有 schemaInfo 的消息会附加一个版本号,所以当该消息被 consumer 消费时,客户端可以通过该版本号来获取对应的 schemaInfo,然后根据该 schemaInfo 对消息反序列化。
Schema Evolution
如果遇到业务发生变化的场景时,我们也许需要更新一下 schema,这种更新被称为 schema evolution,很显然,如果 schema 发生了更改,下游的 consumer 会受到影响,所以 schema evolution 应该能保证下游 consumer 能无缝处理旧版本和新版本的数据,这部分机制被称为 schema compatibility,该部分将在下一小节详细介绍。
以下为 schema evolution 的流程:
Producer、consumer 或 reader 连接至 broker 时,broker 会根据 schema Registry Compatibility Checkers 配置部署 schema compatibility checker,强制进行 schema 兼容性检查。
Producer、consumer 或 reader 将 schemaInfo 发送给 broker,broker 收到后查询该 schema 类型的 schema compatibility checker,并根据 schema compatibility 策略检测该 schemaInfo 是否与 topic 目前版本的 schema 兼容(schema compatibility 策略被设置 namespace 级别,作用于该 namespace 下的所有 topic)
Schema Compatibility Strategy
上小节介绍了 schema evolution,本小节将介绍 schema compatibility。Pulsar 有 8 种 schema 兼容性检查策略,如下表所示:
假设一个 topic 有三个 schema(V1, V2, V3),V1 是最早版本,V3 是最新版本。
兼容性检查策略名称 | 定义 | 是否允许更改 | 检查Schema | 优先级 |
ALWAYS_COMPATIBLE | 总是兼容(禁止兼容性检查) | 允许所有更改 | 所有版本 | Any order |
ALWAYS_INCOMPATIBLE | 总是不兼容(禁止Schema Evolution)
| 禁止所有更改 | 无 | 无 |
BACKWARD | 使用 schema v3的消费者可以处理使用 schema v2 或 v3 的生产者编写的数据 | - 添加可选字段 - 删除字段 | 最新版本 | Consumer |
BACKWARD_TRANSITIVE | 使用 schema v3的消费者可以处理使用 schema v1、v2 或 v3 的生产者编写的数据 | - 添加可选字段 - 删除字段 | 所有版本 | Consumer |
FORWARD | 使用 schema v2 或 v3 的消费者可以处理使用 schema v3 的生产者编写的数据 | - 添加字段 - 删除可选字段 | 最新版本 | Producer |
FORWARD_TEANSITIVE | 使用 schema v1、v2 或 v3 的消费者可以处理使用 schema v3的生产者编写的数据 | - 添加字段 - 删除可选字段 | 所有版本 | Producer |
FULL(默认策略) | 使用 schema v2 或 v3 的消费者可以处理使用 schema v2 或 v3的生产者编写的数据 | 修改可选字段 | 最新版本 | Any order |
FULL_TRANSITIVE | 使用 schema v1、v2 或 v3 的消费者可以处理使用 schema v1、v2 或 v3 的生产者编写的数据 | 修改可选字段 | 所有版本 | Any order |
Auto Schema
如果不知道topic的模式类型,可以使用Auto Schema来生成,Auto Schema 有以下两种类型:
Auto Schema 类型 | 描述 |
AUTO_PRODUCE
| 为 producer 验证发送的字节是否与 topic 的 schema 兼容。
|
AUTO_CONSUME | 为 topic 验证发送的字节是否与consumer兼容。AUTO_CONSUME 仅支持 AVRO,JSON 和 Protobuf Native Schema, 它将消息反序列化为Generic Record。 |
AUTO_PRODUCE 示例:
假设以下情况:
目前需要处理来自 Kafka topic k 消息
有一个 Pulsar topic P, 但是不清楚该 topic 的 schema 类型
应用需要从kafka topic K 读取消息,然后写入到Pulsar topic P
基于上面情况,可以使用 AUTO_PRODUCE 验证 K 生成的字节是否可以发送到 P
Produce<byte[]> PulsarProducer =client.newProducer(Schema.AUTO_PRODUCE())….create();byte[] kafkaMessageBytes = … ;PulsarProducer.produce(kafkaMessageBytes);
AUTO_CONSUME 示例:
假设以下情况:
目前有一个 Pulsar topic P.
消费端 (例如 MySQL) 需要从 topic P 读取消息
应用读取来自 P 的消息,然后将读取的消息写入到 MySQL.
基于上面情况,可以使用AUTO-CONSUME验证P生成的字节是否可以发送到MySQL
Consumer<GenericRecord> PulsarConsumer =client.newConsumer(Schema.AUTO_CONSUME())….subscribe();Message<GenericRecord> msg = consumer.receive() ;GenericRecord record = msg.getValue();
Schema AutoUpdate
如果 schema 通过了 schema 兼容性检测,则 producer 将自己的 schema 版本与 topic schema 版本同步
对于生产者,AutoUpdate 的流程如下:

对于消费者,AutoUpdate 的流程如下:

免费体验馆
消息队列CKafka
分布式、高吞吐量、高可扩展性的消息服务,具备数据压缩、同时支持离线和实时数据处理等优点。
扫码即可免费体验
免费体验路径:云产品体验->基础->消息队列CKafka
消息队列TDMQ
一款基于 Apache 顶级开源项目 Pulsar 自研的金融级分布式消息中间件。其计算与存储分离的架构设计,使得它具备极好的云原生和 Serverless 特性,用户按量使用,无需关心底层资源。
扫码点击“立即使用”,即可免费体验
微服务平台TSF
稳定、高性能的技术中台。一个围绕着应用和微服务的 PaaS 平台,提供应用全生命周期管理、数据化运营、立体化监控和服务治理等功能。TSF 拥抱 Spring Cloud 、Service Mesh 微服务框架,帮助企业客户解决传统集中式架构转型的困难,打造大规模高可用的分布式系统架构,实现业务、产品的快速落地。
扫码点击“免费体验”,即可免费体验
微服务引擎TSE
高效、稳定的注册中心托管,助力您快速实现微服务架构转型。
扫码点击“立即申请”,即可免费体验
弹性微服务TEM
面向微服务应用的 Serverless PaaS 平台,实现资源 Serverless 化与微服务架构的完美结合,提供一整套开箱即用的微服务解决方案。弹性微服务帮助用户创建和管理云资源,并提供秒级弹性伸缩,用户可按需使用、按量付费,极大程度上帮用户节约运维和资源成本。让用户充分聚焦企业核心业务本身,助力业务成功。
扫码点击“立即申请”,即可免费体验
往期
推荐
《【阵容扩大】三位腾讯Maintainer加入Apache Pulsar生态项目RocketMQ-on-Palsar》
《Apache Pulsar事务机制原理解析|Apache Pulsar 技术系列》

扫描下方二维码关注本公众号,
了解更多微服务、消息队列的相关信息!
解锁超多鹅厂周边!

戳原文,了解更多腾讯微服务平台相关信息