
不和女朋友大【看】一场,圣诞节就算白过了

点击上方蓝字关注我们


圣诞节要到了,想好晚上要和ta要去看什么电影吗?
1.首先我们打开猫眼电影网站Top100。可以从页面看到的信息有电影名称、上映时间、演员列表和评分。没错,这些信息我全要!
https://maoyan.com/board/4?offset=0
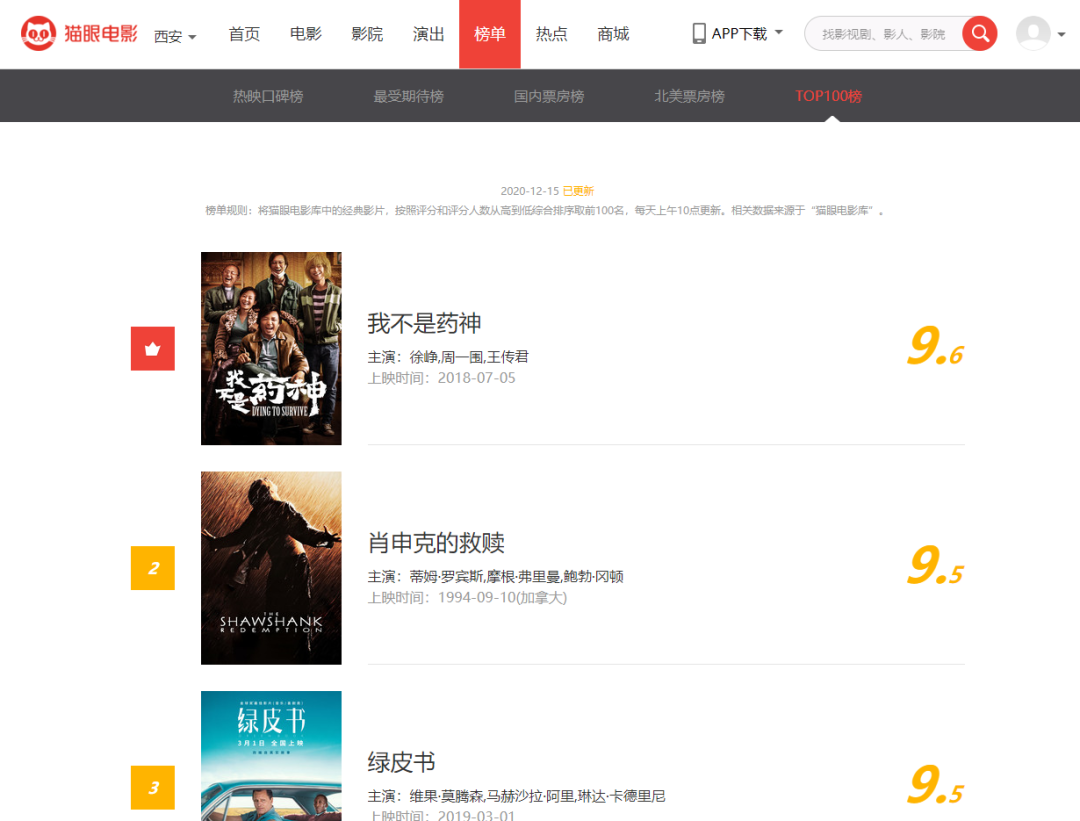
2.爬虫第一步,确定真实的url;首先我们F12打开开发者模式找到链接。
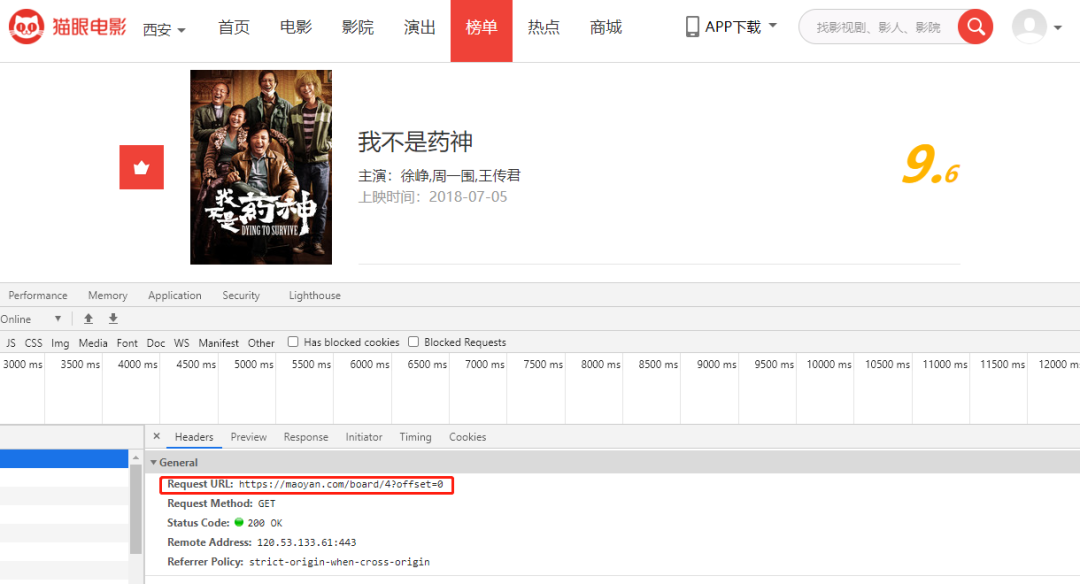
3.第二步,模拟浏览器发送请求。代码如下:
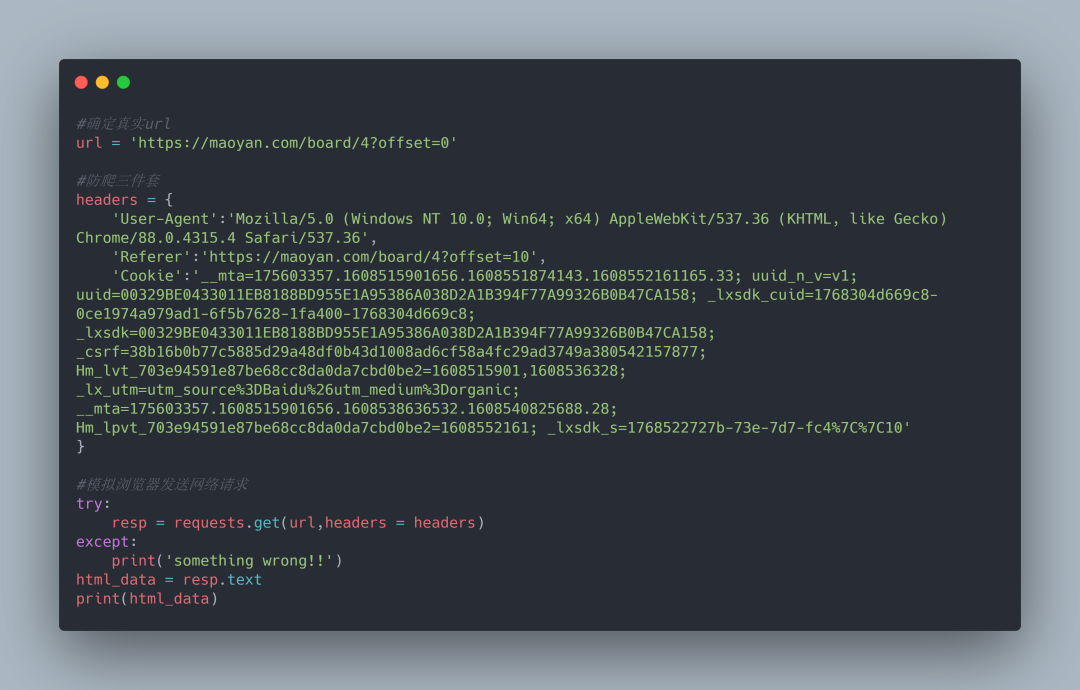
4.可以看到已经获取到了当前页面的全部数据,我们来输入电影名字测试一下,也可以成功获取到数据。
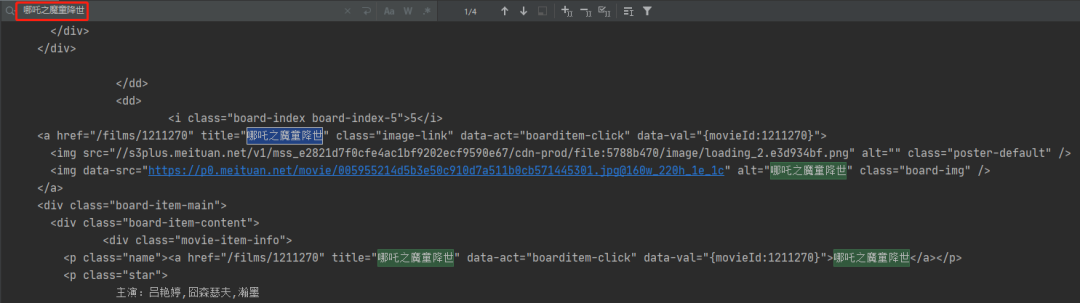
5.爬虫第三步解析数据,我们打开浏览器开发者模式找到我们所需数据具体位置
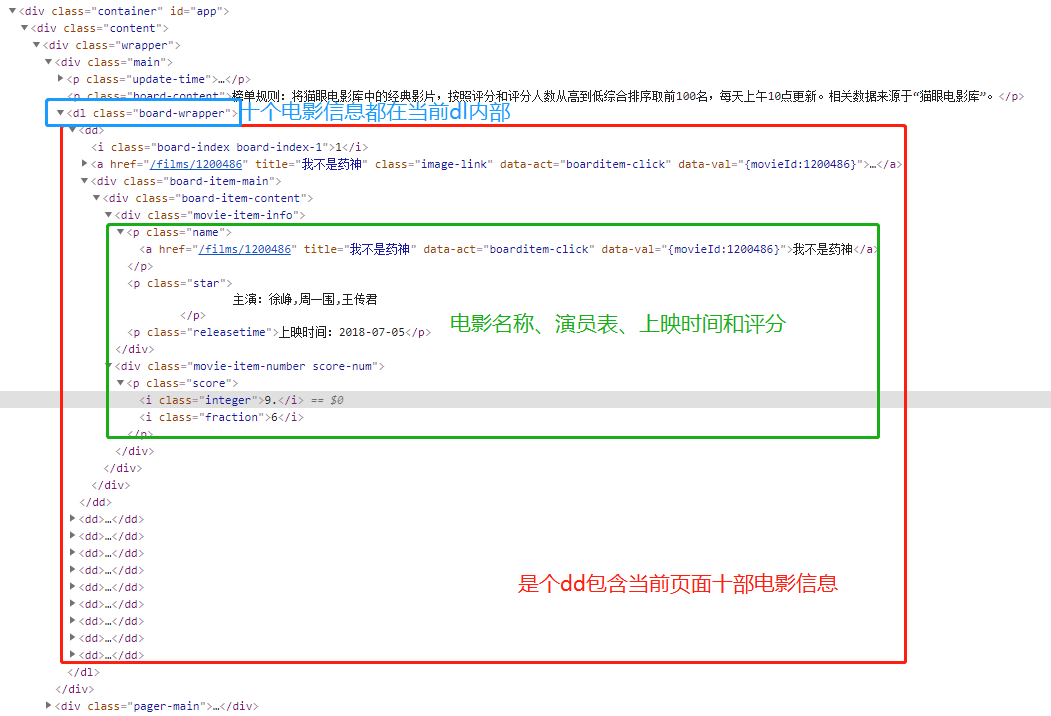
5.1如上图所示,我们需要电影信息需要首先找到这些信息所在位置,分析可知这些信息都在dd标签内部。十个dd标签有都在dl父标签内部。所以我们首先需要确定的是dl的位置。
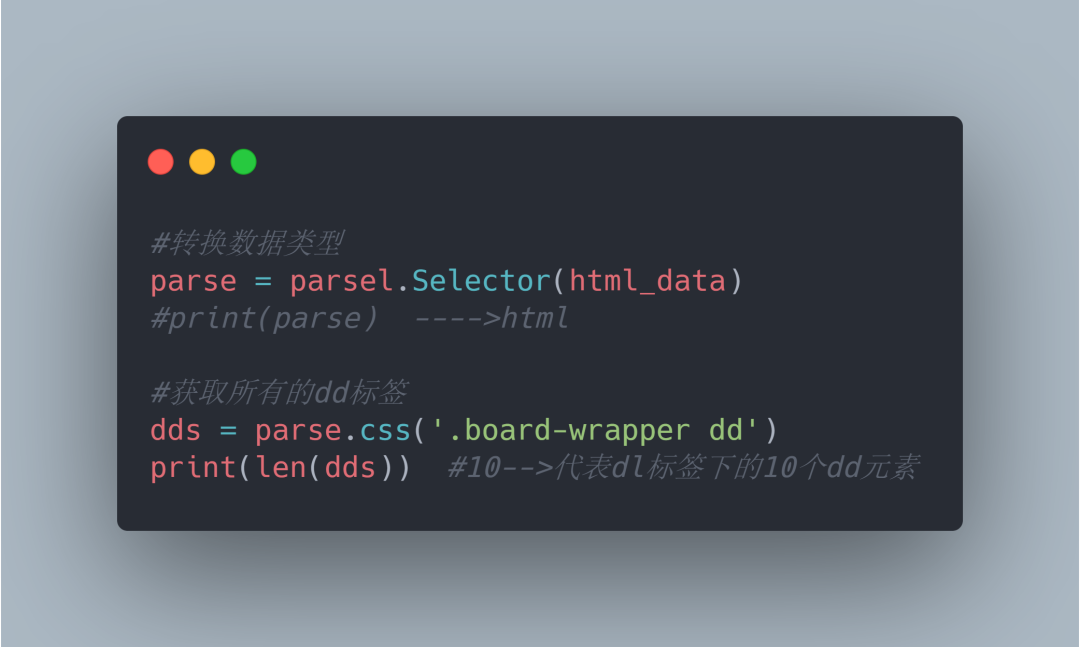
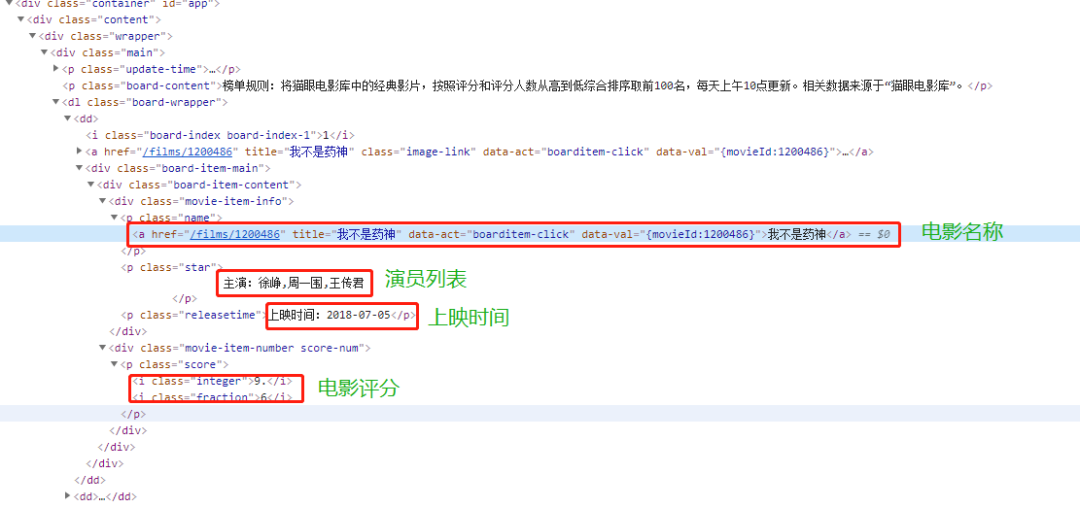
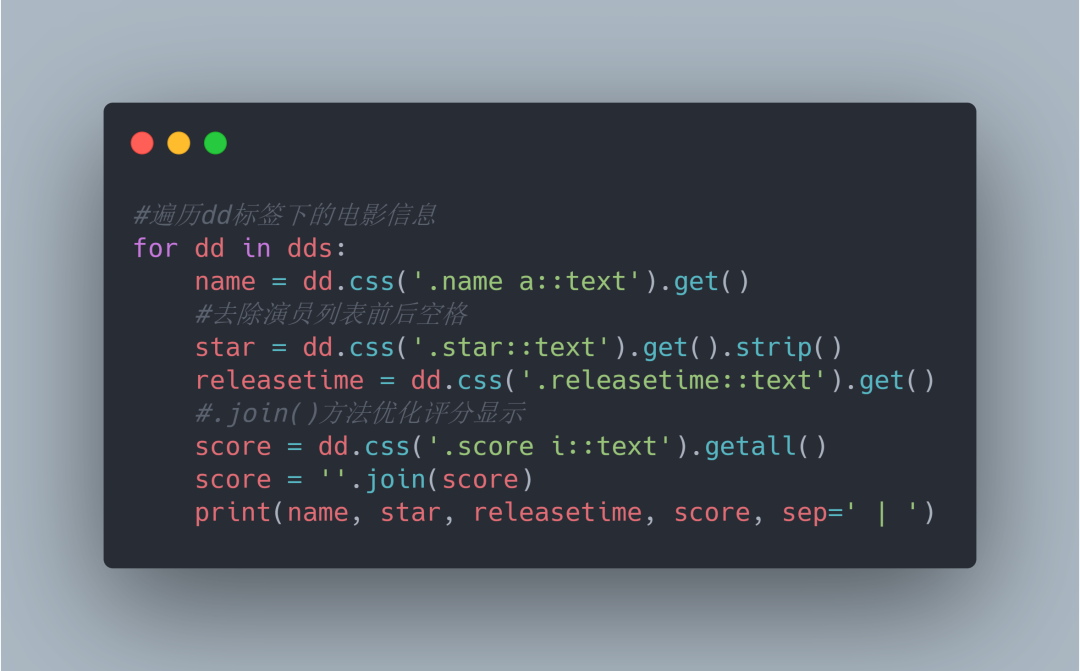
5.3电影信息代码和运行结果如下:
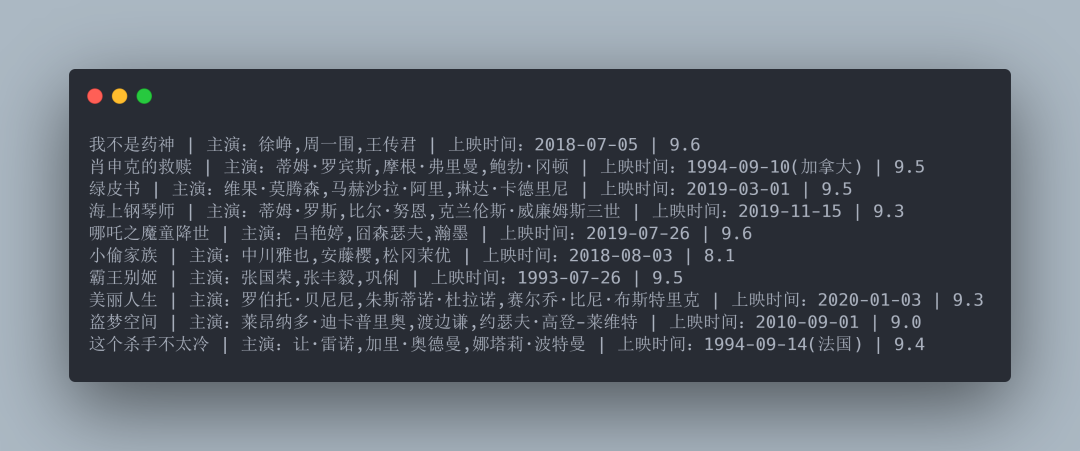
6.爬虫第四步保存数据,这里我们使用的是csv来保存数据到datda.csv文件中。

来看一下运行结果。


好了。到此为止已经爬取成功第一页电影信息。
后续几页查看网页链接发现只有后面参数有变化,规律如下。
所以只需添加循环对offset参数进行遍历即可。详见源码!

为了更友好的人机交互后续对部分代码也已经进行了优化。
有兴趣了解的小伙伴回复'TOP100'即可查看全部源码。
扫描二维码
获取更多精彩
印象python
回复下方 「关键词」,获取优质资源
回复关键词 「linux」,即可获取 185 页 Linux 工具快速教程手册和154页的Linux笔记。
回复关键词 「Python进阶」,即可获取 106 页 Python 进阶文档 PDF
回复关键词 「Python面试题」,即可获取最新 100道 面试题 PDF
回复关键词 「python数据分析」,即可获取47页python数据分析与自然语言处理的 PDF
回复关键词 「python爬虫」,满满五份PPT爬虫教程和70多个案例
回复关键词 「Python最强基础学习文档」,即可获取 168 页 Python 最强基础学习文档 PDF,让你快速入门Python 推荐我的微信号
来围观我的朋友圈,我的经验分享,技术更新,不定期送书,坑位有限,速速扫码添加!
备注:开发方向_昵称_城市,另送你10本Python电子书。点个在看你最好看


