
一个Tensor在深度学习框架中的执行过程简单梳理
❝0x0. 前言撰文:BBuf。审稿:王迎港。
相信看到这篇文章的人都对深度学习框架是有所了解和熟悉的,也多多少少会使用Python写一些神经网络相关的代码。例如我们可以在PyTorch写出下面的代码:
import torch
x = torch.tensor([-1.0, 2.0], device="cuda")
y = torch.relu(x)
print(y)
使用PyTorch运行之后我们会获得如下结果:
tensor([0., 2.], device='cuda:0')
对于x这个输入Tensor来说,它被喂给了relu这个Op,然后输出结果,一切看起来都很简单和正常。但如果有人问你是否清楚这背后到底发生了什么,relu这个Op对应的Cuda Kernel是在什么时候被GPU调用的,相信一部分人是不会很清楚的。因为包括我的大多数人习惯在舒适区使用深度学习框架,对背后的原理可能没有深入了解,所以回答不了也很正常。
这篇文章我就将尝试解开这个问题,但我并不是以PyTorch为例来讲解,而是以OneFlow为例子。为什么以OneFlow为例子呢?首先我在OneFlow工作,对这背后的执行机制比PyTorch要清楚一些,在调用链跟踪的时候会更流畅。其次,OneFlow背后这套运行机制含有挺多PyTorch不存在的设计思想,相信读者看完之后对深度学习框架系统设计方面有更多的思考和启发。
所以,接下来就一起看看一个Tensor在OneFlow深度学习框架中的执行过程吧。为了简单起见,本文只考虑单机单卡模式下的Op执行过程,不涉及OneFlow特有的consistent模式(和分布式相关),如果你对这部分感兴趣可以自行查看。
0x1. Python和C++的桥梁当我们敲下如下代码并将其移交给OneFlow执行时:
import oneflow as flow
x = flow.tensor([-1.0, 2.0], device="cuda")
y = flow.relu(x)
print(y)
系统首先创建了一个在GPU上的输入Tensor,然后调用了导出到python端的c++ functional接口relu。这里涉及到pybind11绑定相关的Python wrapper和C++ relu functor。这个交互的上层,同事在OneFlow学习笔记:python到C++调用过程分析 这篇文章有解析过了,感兴趣可以看看。我们上面Python代码中的flow.relu这个Op最终调用的是ReLU C++ Functor的实现,我们看一下代码。
class ReluFunctor {
public:
ReluFunctor() { op_ = CHECK_JUST(one::OpBuilder("relu").Input("x", 1).Output("y", 1).Build()); }
Maybe operator()(const std::shared_ptr& x, bool inplace) const {
if (inplace) {
...
} else {
return OpInterpUtil::Dispatch(*op_, {x});
}
}
private:
std::shared_ptr op_;
};
这段代码里面的op_是一个OpExpr的指针,然后在构造函数里面调用了OpBuilder函数来创建了一个新的OpExpr。从后面的实际调用代码OpInterpUtil::Dispatch可以发现这里的算子构建和执行是分开的(因为Dispatch函数是同时将OpExpr和输入Tensor等分发出去,没有直接分发执行的结果Tensor出去,所以这里还没有真正的执行Op),这里的OpInterpUtil::Dispatch是负责将OpExpr,输入Tensor和其它参数(ReLU这个算子没有除输入外的参数)分发出去,还没有真正的执行。
OpExpr可以简单理解为是OneFlow算子的统一抽象。OpExpr大体可以分为BuiltinOpExpr、FunctionOpExpr和其他类别的OpExpr,其中BuiltinOpExpr又可以细分为UserOpExpr和其他非UserOpExpr,用户可以通过OpBuilder构建出UserOpExpr。
不需要完全理解OpExpr的定义,我们只需要知道这里是通过OpBuilder类构造了一个新的OpExpr,这个OpExpr有Op name,UserOpConf proto_这个序列化Op信息的ProtoBuf对象,以及输入输出Tensor的名字等关键信息。然后顺着这个Dispatch函数可以发现最后在oneflow/core/framework/op_interpreter/op_interpreter_util.cpp中调用到了GetInterpreter函数的Apply方法:
/* static */ Maybe<void> OpInterpUtil::Dispatch(const OpExpr& op_expr, const TensorTuple& inputs,
TensorTuple* outputs,
const OpExprInterpContext& ctx) {
return JUST(GetInterpreter(inputs, ctx, op_expr))->Apply(op_expr, inputs, outputs, ctx);
}
这里的OpExprInterpContext对象会存储Op的动态属性,设备信息,分布式信息等,对于Relu Functor来说,这里为空,所以我们这里不关注这个对象。再往下跟就属于InterPreter的内容了,新开一节来讲。
0x2. Interpreter从上面的Op调用流程可以看出,我们在Python层的Op实际上是调用的导出到Python的Functor接口,而Functor接口会将OpExpr,输入Tensor和动态属性attr递交给Interpreter来处理,因为上面的GetInterpreter函数获取的就是一个Interpreter对象。Interpreter这个类就是专门用来解释Op执行过程的,上一节在Relu Functor里面的Dispatch就是把任务分发到Interpreter来执行。OneFlow的Interpreter又分为几种类型,如Eager Mirrored Interpreter,Eager Consistent Interpreter和LazyInterpreter,我们这篇文章的例子没有考虑分布式信息,所以输入Tensor都是Eager Mirroed Tensor,所以走的是Eager Mirrored Interpreter这个调用链。Mirrored Tensor和PyTorch的Tensor类似,在各个Rank上是独立的。
再往下跟一下我们发现上面的Apply实际上调用的是oneflow/core/framework/op_interpreter/eager_mirrored_op_interpreter.cpp文件中的NaiveInterpret函数,这个函数接收OpExpr对象,输入输出Tensor和一个OpExprInterpContext对象来对Op的device,输出dtype,输出shape等进行推导,然后根据推导的元信息(元信息对应TensorMeta类对象,把 Tensor 的基本信息:shape, dtype, stride 等抽出来一个类型,放一起方便管理)构造分别对应输入输出的BlobObject对象input_eager_blob_objects和output_eager_blob_objects(可理解为输入输出Tensor的数据指针),另外还会根据OpExpr和推导后的device构造一个特定执行kernel。最后将执行kernel,输入输出Tensor的数据指针以及OpExprInterpContext对象以指令的方式发给OneFlow的虚拟机(VM,可以理解为OneFlow的Eager运行时,后面会细讲)执行并获得结果。
这里我们分段看一下NaiveInterpret的实现。第一段:
Maybe<void> NaiveInterpret(const UserOpExpr& user_op_expr, const TensorTuple& inputs,
const Symbol& default_device, TensorTuple* outputs,
const OpExprInterpContext& ctx) {
const auto& attrs = ctx.attrs;
std::shared_ptr input_eager_blob_objects =
std::make_shared(inputs.size());
for (int i = 0; i < inputs.size(); i++) {
const auto& input_device = JUST(inputs.at(i)->device());
if (i > 0) {
CHECK_OR_RETURN(*default_device == *input_device) << Error::InputDeviceNotMatchError();
}
input_eager_blob_objects->at(i) = JUST(inputs.at(i)->eager_blob_object());
}
上面这段代码遍历输入Tensor的列表,将每一个输入Tensor的device和函数传入的默认device进行比较,如果发现输入Tensor的device和默认device不一致就抛出异常。可以对类似输入Tensor在CPU上,但nn.Module在GPU上的例子进行错误检查,输出设备不匹配的错误信息。如果设备都匹配上了,这个时候会将输入Tensor的eager_blob_object添加到input_eager_blob_objects这个列表中。输入Tensor的eager_blob_object是一个EagerBlobObject类型的指针,是输入Tensor的数据指针,后续通过它和OneFlow的虚拟机(VM)进行交互。
❝这里要补充说明一下OneFlow中Tensor,TensorImpl,TensorMeta和BlobObject的关系。Tensor 和 TensorImpl 用了桥接设计模式,Tensor 负责向上和 python 接口、autograd 的对接;TensorImpl 是向下负责真实数据这部分。TensorMeta 就是把 Tensor 的基本信息:shape, dtype, stride 等抽出来一个类型,放一起方便管理。BlobObject是真正的数据对象,数据指针在这个对象中,这个类被虚拟机使用来完成指令的计算任务。
第二段:
std::shared_ptr output_eager_blob_objects =
std::make_shared(outputs->size());
auto* output_tensor_metas = ThreadLocalDefaultOutputMutTensorMetas(outputs->size());
for (int i = 0; i < outputs->size(); i++) {
if (!outputs->at(i)) {
const auto& tensor_impl = std::make_shared();
outputs->at(i) = std::make_shared(tensor_impl);
output_tensor_metas->at(i) = tensor_impl->mut_tensor_meta();
} else {
bool has_eager_blob_object = JUST(outputs->at(i)->has_eager_blob_object());
CHECK_OR_RETURN(has_eager_blob_object);
output_eager_blob_objects->at(i) = JUST(outputs->at(i)->eager_blob_object());
}
}
这里首先声明了一个EagerBlobObjectList类型的指针output_eager_blob_objects 以及存储输出Tensor元信息的output_tensor_metas,然后遍历输出Tensor列表判断第i个Tensor是否已经有值,如果没有就申请一个MirroredTensor类型的指针并初始化为tensor_impl这个对象,并将output_tensor_metas在索引i处的值更新为tensor_impl的Tensor元信息,为接下来的形状和类型推导做准备(这里如果有值的话,那就是 inplace 调用了,如果加一些判断,可以发现有值的 BlobObject 和某个输入的 BlobObject 是同一个对象)。如果这个输出Tensor已经有值了(inplace模式),那么就判断它是否存在EagerBlobObject类型的数据指针,如果存在就将这个数据指针取出来放到刚才申请好的EagerBlobObjectList类型的output_eager_blob_objects列表里。后续的shape推导和dtype推导也将用到这个output_eager_blob_objects。
第三段:
Symbol op_device;
bool need_check_mem_case = true;
// Infer devices
if (!user_op_expr.has_device_infer_fn()) {
op_device = default_device;
for (int i = 0; i < outputs->size(); i++) {
auto* tensor_impl = JUST(TensorImpl4Tensor(outputs->at(i)));
*JUST(tensor_impl->mut_device()) = default_device;
}
} else {
need_check_mem_case = false;
op_device = JUST(user_op_expr.InferDevices(attrs, inputs, outputs));
}
// Infer shapes and dtypes
const auto& device_tag = JUST(op_device->of_type());
JUST(user_op_expr.InferPhysicalShapeAndDType(
attrs, device_tag,
[&](int32_t i) -> const TensorMeta* {
return CHECK_JUST(TensorImpl4Tensor(inputs.at(i)))->mut_tensor_meta();
},
[&](int32_t i) -> TensorMeta* {
// using thread_local TensorMeta pointer if inplace.
// using tensor_impl TensorMeta pointer if not inplace.
return output_tensor_metas->at(i);
}));
for (int i = 0; i < output_eager_blob_objects->size(); i++) {
auto* tensor_impl = JUST(TensorImpl4Tensor(outputs->at(i)));
if (!output_eager_blob_objects->at(i)) {
tensor_impl->mut_tensor_meta()->set_stride(std::make_shared(*tensor_impl->shape()));
const auto& dep_object = JUST(GetLocalDepObjectFromDevicePool(op_device));
JUST(tensor_impl->InitEagerBlobObject(dep_object));
output_eager_blob_objects->at(i) = JUST(tensor_impl->eager_blob_object());
} else {
// output i is inplaced.
// check thread_local TensorMeta and tensor_impl TensorMeta.
CHECK_OR_RETURN(tensor_impl->tensor_meta()->shape() == output_tensor_metas->at(i)->shape());
CHECK_OR_RETURN(tensor_impl->tensor_meta()->dtype() == output_tensor_metas->at(i)->dtype());
}
}
这一段代码是Op的device,shape和dtype推导。user_op_expr.has_device_infer_fn()用来判断当前的OpExpr是否存在device信息推导函数,如果没有就将输出Tensor的device信息更新为当前的default_device。如果有就直接从user_op_expr取出来即可。这里是否推导过在注册User Op的时候就已经决定了,我们可以在oneflow/core/framework/op_expr.cpp这里的UserOpExpr::Init看到对注册器是否有device推导函数的判断,另外我们可以在oneflow/ir/include/OneFlow/OneFlowUserOps.td这个td文件中看到哪些Op实现了device推导函数。
接下来调用了OpExpr中的InferPhysicalShapeAndDType完成对输出Tensor的shape和dtype推导。跟进InferPhysicalShapeAndDType函数可以发现它实际调用了注册User Op时定义的shape推导和dtype推导函数。然后会遍历output_eager_blob_objects并基于已经推导出的TensorMeta对它做更新或者检查(这里的TensorMeta检查就是因为上面提到的可能存在的Inplace的情况,inplace 前后的TensorMeta不能改变)。
最后一段:
const auto& kernel = JUST(user_op_expr.MutKernel4Device(op_device));
kernel->set_need_check_mem_case(need_check_mem_case);
for (int64_t index : kernel->output_tuple_indexes4mut2_obns()) {
output_eager_blob_objects->at(index)->set_is_shape_synced(false);
}
JUST(PhysicalRun([&](InstructionsBuilder* builder) -> Maybe<void> {
return builder->LocalCallOpKernel(kernel, input_eager_blob_objects, output_eager_blob_objects,
ctx, op_device);
}));
最后一段代码就是Interpreter和VM交互时最关键的一步了,这里用user_op_expr.MutKernel4Device构造了在op_device上的StatefulOpKernel ,并将output_eager_blob_objects中每个EagerBlobObject对象的is_shape_synced_属性设置为False,这个is_shape_synced_设置为False代表输出Tensor的形状是在运行时确定的,要Kernel执行完之后才能获得输出Tensor的shape。为什么这里要默认都设置为False呢?因为对于一个 Op 来说,它的 shape 是不是需要推导是 Op 自己的属性,这里默认会给一个 false。然后在 StatefulOpKernel 那里还有个 flag,这里就真正知道哪些 op 是动态 shape 了,如果不是动态 shape,就给这个 flag 置为 True,表示已经同步(不用同步)。这里的builder->LocalCallOpKernel函数就是在构建虚拟机(VM)的指令,而PhysicalRun负责给虚拟机发送这个指令并执行获得最终结果。
OneFlow Eager的运行时被抽象为虚拟机(VM)。当我们执行flow.relu(x)这句代码时,会通过上面的Interpreter发一个LocalCallOpKernel指令给VM。VM再执行这个指令的时候会为输出Tensor申请显存,调用ReLU的Cuda Kernel进行计算并将计算结果写到输出Tensor。
我们先介绍一下虚拟机一些概念,然后再追关键代码进一步说明。
OneFlow程序在运行期间虚拟机会在后台不断的轮询,如果有新的可以执行的指令就执行,没有就继续轮询。虚拟机有两种线程,称作scheduler线程以及worker线程(如果我们运行Python脚本,Python脚本是在主线程也叫main线程中运行)。虚拟机的轮询是在scheduler线程中,而worker线程则是处理一些阻塞的操作,这种操作比较慢不适合放到scheduler线程里面做。
刚才我们已经多次提到指令这个名词,虚拟机执行的最小单位就是指令。OneFlow中的指令类型有AccessBlobByCallback,LocalCallOpKernel,ReleaseTensor等。AccessBlobByCallback用于读取和修改Blob的值的指令,而LocalCallOpKernel是运行一个Op的指令,ReleaseTensor就是释放声明周期已经结束的Tensor的内存。每一种指令都会携带一个parallel_desc表示指令在哪些设备上执行(例如只在 1 号卡上执行,或在所有的卡上执行),还会绑定一个 StreamType,表示指令在哪种 Stream 上执行(在我们文章开头举的例子中,ReLU对应的LocalCallOpKernel就是在CudaStream上执行)。以LocalCallOpKernel为例,根据StreamType的不同有以下类型的指令:
Maybe<const std::string&> GetLocalCallInstructionName(const std::string& type) {
static const HashMap<std::string, std::string> type2instr_name{
{"cpu", "cpu.LocalCallOpKernel"},
{"gpu", "gpu.LocalCallOpKernel"},
{"cuda", "gpu.LocalCallOpKernel"},
{"cuda_h2d", "cuda_h2d.LocalCallOpKernel"},
{"cuda_d2h", "cuda_d2h.LocalCallOpKernel"},
{"comm_net", "cpu.LocalCallOpKernel"},
{"sync_launched_nccl", "gpu.LocalCallOpKernel"},
{"async_launched_nccl", "async.gpu.LocalCallOpKernel"},
// no compute instruction on critical_section device.
{"critical_section", "UNIMPLEMENTED INSTRUCTION NAME"},
};
return MapAt(type2instr_name, type);
}
以cpu.LocalCallOpKernel指令来看就将它的stram_type绑定为CpuStreamType,在oneflow/core/eager/cpu_opkernel_instruction_type.cpp的定义如下:
class CpuLocalCallOpKernelInstructionType final : public LocalCallOpKernelInstructionType {
public:
CpuLocalCallOpKernelInstructionType() = default;
~CpuLocalCallOpKernelInstructionType() override = default;
using stream_type = vm::CpuStreamType; // 绑定stream_type
private:
const char* device_tag() const override { return stream_type().device_tag(); }
};
COMMAND(vm::RegisterInstructionType("cpu.LocalCallOpKernel"));
每种StreamType都可以设置这种类型的Stream是否工作在scheduler线程上,初始化和查询指令状态,完成指令计算等工作。
❝这里的Stream是虚拟机里面的device抽象,每一种Stream对应一种device。另外指令都有Infer和Compute过程,Infer是推导元信息,而Compute才是真正的启动计算Kernel进行执行。
接下来我们看看指令间的依赖关系,虚拟机的指令是乱序执行的,但对有依赖关系的指令的执行顺序也是有要求的。例如用户发射了a和b两条指令,然后a指令要修改Blob c的值,但b指令要读取Blob c的值,那a指令就得先于b指令执行。
那么指令间的依赖关系是如何构建的呢?指令间的依赖关系是依靠指令携带的操作数来实现的,操作数的主要类型有 const、mut、mut2。const 对应输入(读取),mut 和 mut2 对应输出(写入)。上述的 a 指令有一个 mut operand c,b 指令有一个 const operand c。这样,通过检查 a 和 b 指令中 c 的类型,就可以在 a 和 b 之间建立依赖关系:b 的 infer 一定要在 a infer 完成之后、b 的 compute 一定要在 a compute 之后。mut2 operand 是为了处理一些 output shape 在 compute 阶段才能确定的 op(如 unique),例如,如果 a 以 mut2 operand 形式持有 c,那么 b 的 infer 和 compute 都需要发生在 a 的 compute 之后。从oneflow/core/eager/local_call_opkernel_phy_instr_operand.h定义的LocalCallOpKernelPhyInstrOperand指令来看,它重载了ForEachConstMirroredObject,ForEachMutMirroredObject,ForEachMut2MirroredObject三种方法,分别对应的是const,mut,mut2操作数。在重载的每个方法里去调用传入的回调函数(const std::function)来构建指令间的依赖关系,以const为例:
void LocalCallOpKernelPhyInstrOperand::ForEachConstMirroredObject(
const std::function<void(vm::MirroredObject* compute)>& DoEach) const {
const auto& input_list = inputs();
for (int64_t index : opkernel().input_tuple_indexes4const_ibns()) {
const auto& input = input_list->at(index);
DoEach(CHECK_JUST(input->compute_local_dep_object())->mut_mirrored_object());
}
}
for (int64_t index : opkernel().input_tuple_indexes4const_ibns()) 这行代码用来遍历StatefulOpKernel对象里面的const操作数,得到它在Input Tuple里面的下标获得index,然后根据index取出这个下标对应的对应的EagerBlobObject对象。再对这个EagerBlobObject上的compute_local_dep_object调用DoEach这个回调,相当于以const的方式去消费这个compute_local_dep_object。mut和mut2类似。
这里还要说明一下虚拟机的指令间依赖关系具体是怎么建立的。在oneflow/core/vm/virtual_machine_engine.cpp里面的HandlePending成员函数里面,ConsumeMirroredObjects这个函数中的for (const auto& operand : operands) 针对每种operand调用ForEachMutMirroredObject函数,比如对于mut来说:
for (const auto& operand : operands) {
if (operand->has_mut_operand()) {
ForEachMutMirroredObject(interpret_type, id2logical_object,
operand->mut_operand(), global_device_id,
ConsumeMutMirroredObject);
} ...
}
templatetypename DoEachT>
void VirtualMachineEngine::ForEachMutMirroredObject(
const InterpretType interpret_type, Id2LogicalObject* id2logical_object,
const ModifiedOperand& mut_operand,
int64_t global_device_id, const DoEachT& DoEach) {
const Operand& operand = mut_operand.operand();
if (interpret_type == InterpretType::kCompute) {
ForEachMirroredObject<&IdUtil::GetValueId>(id2logical_object, operand, global_device_id,
DoEach);
} else if (interpret_type == InterpretType::kInfer) {
ForEachMirroredObject<&IdUtil::GetTypeId>(id2logical_object, operand, global_device_id, DoEach);
} else {
UNIMPLEMENTED();
}
}
这里的DoEachT就是ConsumeMutMirroredObject,即消费MutMirroredObject。继续跟进ConsumeMutMirroredObject的实现:
const auto& ConsumeMirroredObject = [&](OperandAccessType access_type,
MirroredObject* mirrored_object) {
auto* access = AccessMirroredObject(access_type, mirrored_object, instruction);
instruction->mut_mirrored_object_id2access()->Insert(access);
return access;
};
这里的AccessMirroredObject将这个指令添加到了会访问这个mirrored_object的指令列表里面。
RwMutexedObjectAccess* VirtualMachineEngine::AccessMirroredObject(OperandAccessType access_type,
MirroredObject* mirrored_object,
Instruction* instruction) {
auto access = access_pool_.make_shared(instruction, mirrored_object, access_type);
auto* ptr = access.Mutable();
instruction->mut_access_list()->PushBack(ptr);
mirrored_object->mut_rw_mutexed_object()->mut_access_list()->EmplaceBack(std::move(access));
return ptr;
}
RwMutexedObject这里是对mirrored_object的读写进行加锁。有了指令的依赖关系之后我们就可以构造指令边了,构建完指令边之后虚拟机就可以执行有指令节点构成的一个Dag。处理Dag的一个有效方式是拓扑排序,但在OneFlow的虚拟机里面是通过ready_instruction_list和pending_instaruction_list将其做成一个迭代的方式,即scheduler轮询的时候只需要不断处理这两个list即可。这里再看一下指令边的构建流程,在ConsumeMirroredObjects的这部分:
void VirtualMachineEngine::TryConnectInstruction(Instruction* src_instruction,
Instruction* dst_instruction) {
if (unlikely(src_instruction == dst_instruction)) { return; }
if (likely(EdgeDispatchable(src_instruction, dst_instruction))) { return; }
auto edge = instruction_edge_pool_.make_shared(src_instruction, dst_instruction);
src_instruction->mut_out_edges()->PushBack(edge.Mutable());
dst_instruction->mut_in_edges()->PushBack(edge.Mutable());
}
void VirtualMachineEngine::ConnectInstructionsByWrite(RwMutexedObjectAccess* dst_access) {
CHECK(dst_access->is_mut_operand());
auto* mirrored_object = dst_access->mut_mirrored_object();
auto* dst_instruction = dst_access->mut_instruction();
auto* access_list = mirrored_object->mut_rw_mutexed_object()->mut_access_list();
if (likely(access_list->Begin() == dst_access)) { return; }
INTRUSIVE_FOR_EACH_PTR(src_access, access_list) {
if (unlikely(src_access == dst_access)) { break; }
TryConnectInstruction(src_access->mut_instruction(), dst_instruction);
CHECK_EQ(src_access->mut_rw_mutexed_object(), mirrored_object->mut_rw_mutexed_object());
access_list->Erase(src_access);
}
}
void VirtualMachineEngine::ConnectInstructionsByRead(RwMutexedObjectAccess* dst_access) {
CHECK(dst_access->is_const_operand());
auto* mirrored_object = dst_access->mut_mirrored_object();
auto* dst_instruction = dst_access->mut_instruction();
auto* first = mirrored_object->mut_rw_mutexed_object()->mut_access_list()->Begin();
if (first->is_mut_operand()) {
TryConnectInstruction(first->mut_instruction(), dst_instruction);
} else if (first->is_const_operand()) {
// do nothing
} else {
UNIMPLEMENTED();
}
}
if (likely(phy_instr_operand)) {
// Connect instructions by write before connecting by read.
for (auto* mirrored_object : phy_instr_operand->output_dependences()) {
ConnectInstructionsByWrite(
AccessMirroredObject(kMutableOperandAccess, mirrored_object, instruction));
}
for (auto* mirrored_object : phy_instr_operand->input_dependences()) {
ConnectInstructionsByRead(
AccessMirroredObject(kConstOperandAccess, mirrored_object, instruction));
}
}
会去分析两个指令的关系,例如一个读一个写,或者两个读或者写,来分别构造指令边,把两个指令连在一起。
因此,虚拟机的指令依赖关系并不是虚拟机内嵌的,而是通过消费指令的操作数实现出来的,并且除了消费操作数构造指令依赖关系,还可以消费device。以LocalCallOpKernelPhyInstrOperand指令的mut操作数为例,这里会拿到StatefulOpKernel对应的device,比如cuda,然后每个device方法上也有一个local_dep_object成员,每个指令都以mut形式来消费device上的local_dep_object,这样就实现了比如前后两个指令都在同一个device上执行,那么这两个指令的执行顺序一定是需要按照发射时的顺序进行执行的这种依赖关系,因为它们都以mut的方式消费了同一个local_dep_object。
❝0x4. VM和Interpreter的整体调用链这里的
local_dep_object是专门用来帮助虚拟机构建指令边的一个 对象。这个对象被EagerBlobObject,Device持有,然后按先后顺序消费它就建立了指令之间的联系。
虚拟机的基础知识就点到为止了,因为我的理解目前也十分有限。这一节再宏观的梳理一下Interpter和虚拟机的调用链。首先,Python层调用OneFlow的Op会发经过Interpreter去构建虚拟机的指令并执行。以ReLU为例,在Interpreter的最后一步是:
JUST(PhysicalRun([&](InstructionsBuilder* builder) -> Maybe<void> {
return builder->LocalCallOpKernel(kernel, input_eager_blob_objects, output_eager_blob_objects,
ctx, op_device);
}));
然后跟进LocalCallOpKernel的实现:
Maybe<void> InstructionsBuilder::LocalCallOpKernel(
const std::shared_ptr& opkernel,
const one::EagerBlobObjectListPtr& input_eager_blob_objects,
const one::EagerBlobObjectListPtr& output_eager_blob_objects,
const std::shared_ptr<const one::ConsistentTensorInferResult>& consistent_tensor_infer_result,
const one::OpExprInterpContext& ctx, Symbol op_device) {
const auto& parallel_desc_sym = JUST(Placement4Device(op_device)).shared_from_symbol();
for (const auto& input : *input_eager_blob_objects) {
const auto& blob_last_used_device = JUST(input->last_used_device());
if (blob_last_used_device != op_device) {
auto* dep_object = JUST(input->compute_local_dep_object());
JUST(SoftSyncStream(dep_object, "mut", blob_last_used_device));
}
input->set_last_used_device(op_device);
}
auto phy_instr_operand = JUST(vm::LocalCallOpKernelPhyInstrOperand::New(
opkernel, input_eager_blob_objects, output_eager_blob_objects, consistent_tensor_infer_result,
ctx, *one::CurrentDevVmDepObjectConsumeMode()));
auto instruction = intrusive::make_shared(
Global::Get()->mut_vm(), JUST(op_device->local_call_instruction_name()),
parallel_desc_sym, phy_instr_operand);
instruction_list_->EmplaceBack(std::move(instruction));
for (const auto& output : *output_eager_blob_objects) {
if (!output->producer_op_device().has_value()) {
JUST(output->init_producer_op_device(op_device));
}
output->set_last_used_device(op_device);
}
return Maybe<void>::Ok();
}
auto instruction = intrusive::make_shared这句代码,构建了一条新的指令给它绑定了一个parallel_desc,表示在哪些设备上执行(例如只在 0 号卡上执行,或在所有的卡上执行)和一个 StreamType,表示指令在哪种 stream 上执行。而这句代码上面的 auto phy_instr_operand = JUST(vm::LocalCallOpKernelPhyInstrOperand::New...是用来将指令和操作数进行绑定的。现在指令有了,接下来就应该和VM进行交互基于这些新建的指令构建指令边并执行了,这个交互的接口是PhysicalInterpreter::Run(从PhysicalRun跳进去)。
Maybe<void> PhysicalInterpreter::Run(
const std::functionvoid >(InstructionsBuilder*)>& Build) {
InstructionsBuilder instructions_builder(mut_id_generator(), mut_instruction_list(),
mut_eager_symbol_list());
JUST(Build(&instructions_builder));
if (instructions_builder.instruction_list().empty()) {
CHECK(instructions_builder.eager_symbol_list().eager_symbol().empty());
return Maybe<void>::Ok();
}
return Global::Get()->RunPhysicalInstruction(
instructions_builder.mut_instruction_list(), instructions_builder.eager_symbol_list());
}
跳到RunPhysicalInstruction的定义,在oneflow/core/eager/eager_oneflow.cpp:
Maybe<void> EagerOneflow::RunPhysicalInstruction(
vm::InstructionMsgList* instruction_list,
const vm::cfg::EagerSymbolList& cfg_eager_symbol_list) {
vm::EagerSymbolList eager_symbol_list;
cfg_eager_symbol_list.ToProto(&eager_symbol_list);
return RunPhysicalInstruction(instruction_list, eager_symbol_list);
}
它的入参就是我们构造指令那个地方定义的全局InstructionsBuilder对象的mut_instruction_list和eager_symbol_list(是虚拟机里面的对象)。再跳转一下RunPhysicalInstruction(instruction_list, eager_symbol_list)可以看到如下定义:
Maybe<void> EagerOneflow::RunPhysicalInstruction(vm::InstructionMsgList* instruction_list,
const vm::EagerSymbolList& eager_symbol_list) {
for (const auto& eager_symbol : eager_symbol_list.eager_symbol()) {
JUST(StorageAdd(eager_symbol));
}
return vm::Run(instruction_list);
}
Maybe<void> Run(vm::InstructionMsgList* instr_msg_list) {
auto* virtual_machine = JUST(GlobalMaybe());
JUST(virtual_machine->Receive(instr_msg_list));
return Maybe<void>::Ok();
}
这里的virtual_machine->Receive(instr_msg_list)就可以获取刚才构建的指令了。
Maybe<bool> VirtualMachineEngine::Receive(
intrusive::shared_ptr&& compute_instr_msg) {
InstructionMsgList instr_msg_list;
instr_msg_list.EmplaceBack(std::move(compute_instr_msg));
return Receive(&instr_msg_list);
}
获取到指令之后就可以在VM的Scheduler线程进行轮询的时候处理这些指令了,即oneflow/core/vm/virtual_machine_engine.cpp这里的VirtualMachineEngine::Schedule函数:
void VirtualMachineEngine::Schedule() {
// Release finished instructions and try to schedule out instructions in DAG onto ready list.
if (unlikely(mut_active_stream_list()->size())) { ReleaseFinishedInstructions(); }
// TODO(lixinqi): remove this line after disabling vm single-client support.
if (unlikely(mut_delete_logical_object_list()->size())) { TryDeleteLogicalObjects(); }
// Try run the first barrier instruction.
if (unlikely(mut_barrier_instruction_list()->size())) { TryRunBarrierInstruction(); }
// Handle pending instructions, and try schedule them to ready list.
// Use thread_unsafe_size to avoid acquiring mutex lock.
// The inconsistency between pending_msg_list.list_head_.list_head_.container_ and
// pending_msg_list.list_head_.list_head_.size_ is not a fatal error because
// VirtualMachineEngine::Schedule is always in a buzy loop. All instructions will get handled
// eventually.
// VirtualMachineEngine::Receive may be less effiencient if the thread safe version
// `pending_msg_list().size()` used here, because VirtualMachineEngine::Schedule is more likely
// to get the mutex lock.
if (unlikely(pending_msg_list().thread_unsafe_size())) { HandlePending(); }
// dispatch ready instructions and try to schedule out instructions in DAG onto ready list.
if (unlikely(mut_ready_instruction_list()->size())) { DispatchAndPrescheduleInstructions(); }
}
Schedule函数在不断的轮询,整体功能大概可以分为接受main线程发出的指令,轮询指令的完成情况,处理阻塞指令以及Dispatch已经就绪的指令。实际上当我们点进HandlePending可以发现,它正是在消费我们的local_dep_opbject进行指令的构建和指令边链接,和上面分析的过程也对应上了。
关于Interpreter和VM我大概就梳理到这里,实际上里面的细节比我想象的复杂很多,我对OneFlow的整体知识欠缺得还很多,所以目前理解也比较初级请见谅。最后再放一张某个网络训练时生成的nsys图:
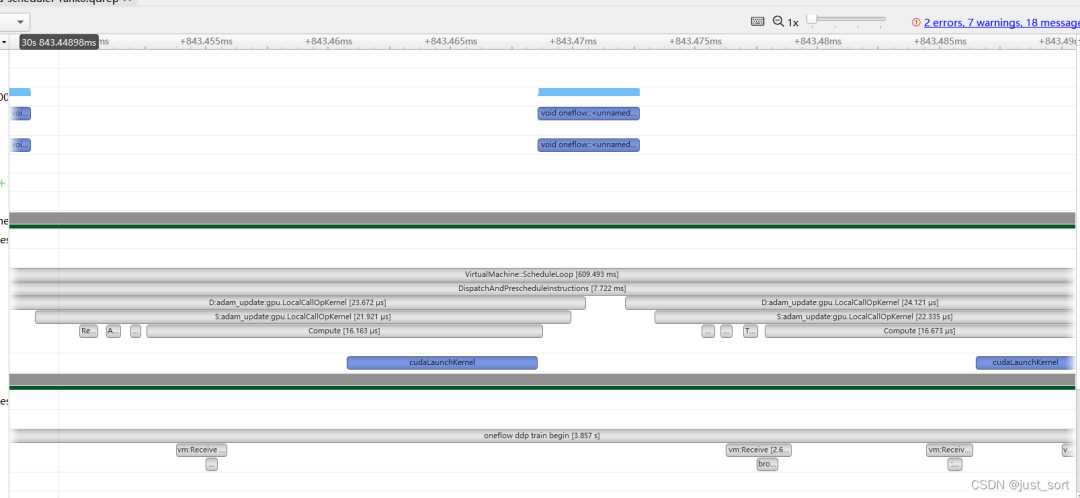 可以看到虚拟机正在工作,scheduler线程正在分发就绪的指令并且launch Adam的cuda kernel执行参数更新0x6. 总结
可以看到虚拟机正在工作,scheduler线程正在分发就绪的指令并且launch Adam的cuda kernel执行参数更新0x6. 总结这篇文章以oneflow.relu这个op为例,介绍了要执行这个Op需要依赖的Interpreter和VM机制,对想了解OneFlow Eager执行机制的同事以及用户希望有一点帮助。
- 设计模式之桥接模式:https://segmentfault.com/a/1190000041225650
- https://github.com/Oneflow-Inc/oneflow