
【NLP】利用维基百科促进自然语言处理
编译 | VK
来源 | Towards Data Science

介绍
自然语言处理(NLP)正在兴起。计算语言学和人工智能正在联手促进新的突破。
虽然研究的重点是大幅改善自然语言处理技术,但企业正将这项技术视为一项战略资产。主要原因是存在着大量文本数据。谈到数字化,尤其是对企业而言,重要的是要记住,文档本身就是数字化的,因此,文本数据是知识的主要来源。
然而,当我们试图磨练一个自然语言处理任务时,最大的瓶颈之一是数据的训练。当涉及到实际的应用程序时,例如在特定领域中,我们面临着低资源数据的问题。训练数据有两个主要问题:(i)获取大量数据的困难;(ii)为训练和测试注释可用数据的过程非常耗时。
面对这些问题,计算机科学界给予了极大的关注。特别是,最新的计算进展提出了两种方法来克服低资源数据问题:
微调预训练的语言模型,如BERT或GPT-3;
利用高质量的开放数据存储库,如Wikipedia或ConceptNet。
目前大多数计算语言学开放库都提供了基于这两种方法之一的NLP工具开发架构。我们现在演示如何利用Wikipedia提高两个NLP任务的性能:命名实体识别和主题模型。
从句子中提取维基百科信息
有几种工具可用于处理来自维基百科的信息。对于文本数据的自动处理,我们使用了一个名为SpikeX的spaCy开放项目。
SpikeX是一个spaCy管道的管道集合,spaCy管道是一个用于NLP的python库。SpikeX由一家意大利公司(Erre Quadro Srl)开发,旨在帮助构建知识提取工具。
pip install --no-cache -U git+https://github.com/erre-quadro/spikex.git@develop
spikex download-wikigraph enwiki_core
spacy download en_core_web_sm
SpikeX有两个主要功能:
1.给定一个Wikipedia页面,它会提取所有相应的类别。
from wasabi import msg
from time import process_time as time
page = "Natural_Language_Processing"
print(f"Categories for `{page}`:")
t = time()
for c in wg.get_categories(page):
print("\t", c)
for cc in wg.get_categories(c):
print("\t\t->", cc)
msg.good(f"Success in {time() - t:.2f}s")
“Natural_Language_Processing”的类别:
Categories for `Natural_Language_Processing`:
Category:Artificial_intelligence
-> Category:Emerging_technologies
-> Category:Cybernetics
-> Category:Subfields_of_computer_science
-> Category:Computational_neuroscience
-> Category:Futures_studies
-> Category:Cognitive_science
-> Category:Personhood
-> Category:Formal_sciences
Category:Speech_recognition
-> Category:Artificial_intelligence_applications
-> Category:Computational_linguistics
-> Category:Human–computer_interaction
-> Category:Digital_signal_processing
-> Category:Speech
Category:Natural_language_processing
-> Category:Artificial_intelligence_applications
-> Category:Computational_linguistics
Category:Computational_linguistics
-> Category:Computational_social_science
2.给定一个句子,它会在文本中找到与维基百科页面标题匹配的块。
from spacy import load as spacy_load
from spikex.wikigraph import load as wg_load
from spikex.pipes import WikiPageX
# 加载一个spacy模型,然后获取doc对象
nlp = spacy_load('en_core_web_sm')
doc = nlp('Elon Musk runs Tesla Motors')
# 加载WikiGraph
wg = wg_load('enwiki_core')
# 获取WikiPageX并提取所有页面
wikipagex = WikiPageX(wg)
doc = wikipagex(doc)
# 查看从文档中提取的所有页面
for span in doc._.wiki_spans:
print(span)
print(span._.wiki_pages)
print('------')
Elon Musk
('Elon_Musk', 'Elon_musk', 'Elon_Musk_(book)', 'Elon_Musk_(2015_book)', 'Elon_Musk_(2015)', 'Elon_Musk_(biography)', 'Elon_Musk_(2015_biography)', 'Elon_Musk_(Ashlee_Vance)')
------
Elon
('Elon_(Judges)', 'Elon_(name)', 'Elon_(Hebrew_Judge)', 'Elon_(Ilan)', 'Elon_(disambiguation)', 'Elon_(biblical_judge)', 'Elon_(chemical)', 'Elon')
------
Musk
('Musk', 'MuSK', 'Musk_(wine)', 'Musk_(song)', 'Musk_(Tash_Sultana_song)', 'Musk_(disambiguation)')
------
runs
('Runs_(baseball_statistics)', 'Runs', 'Runs_(cricket)', 'Runs_(music)', 'Runs_(baseball)', 'Runs_(Baseball)', 'Runs_(musical)')
------
Tesla Motors
('Tesla_motors', 'Tesla_Motors')
------
Tesla
('Tesla_(band)', 'Tesla_(unit)', 'Tesla_(Czechoslovak_company)', 'Tesla_(crater)', 'Tesla_(microarchitecture)', 'Tesla_(2020_film)', 'Tesla_(car)', 'Tesla_(GPU)', 'TESLA', 'Tesla_(physicist)', 'Tesla_(group)', 'Tesla_(opera)', 'Tesla_(Bleach)', 'Tesla_(company)', 'Tesla_(disambiguation)', 'Tesla_(2016_film)', 'TESLA_(Czechoslovak_company)', 'Tesla_(unit_of_measure)', 'Tesla_(vehicles)', 'Tesla_(vehicle)', 'Tesla_(film)', 'Tesla_(album)', 'Tesla_(Flux_Pavilion_album)', 'Tesla_(surname)', 'Tesla')
------
Motors ('Motors')
如我们所见,在第一个示例中,SpikeX提取Wikipedia页面“Natural_Language_Processing”所属的所有类别。例如,“Natural_Language_Processing/`”属于“人工智能”、“语音识别”和“计算语言学”的范畴。
在第二个例子中,对于“Elon Musk runs Tesla Motors”这句话,SpikeX提取了该句中可能在Wikipedia上有一个页面的所有页面。
我们现在了解如何使用这两个特性来执行命名实体识别和主题模型。
命名实体识别
命名实体识别(Named Entity Recognition,NER)是一项NLP任务,它试图将文本中提到的实体定位并分类为预定义的类别(如人名、组织、位置等)。
有不同的方法处理这项任务:基于规则的系统,训练深层神经网络的方法,或是训练语言模型的方法。例如,Spacy嵌入了一个预训练过的命名实体识别系统,该系统能够从文本中识别常见的类别。
我们现在着手构建一个能够识别属于某个维基百科类别的文本片段的NER系统。让我们考虑下面的例句:
“Named Entity Recognition and Topic Modeling are two tasks of Natural Language Processing”
这个句子可能包含三个实体:“命名实体识别”,“主题模型”和“自然语言处理”。这三个实体各自有属于特定类别的维基百科页面。

在这幅图中,我们可以看到不同的类别是如何在三个实体之间传播的。在这种情况下,类别可以看作是我们要从文本中提取的实体的标签。我们现在可以利用SpikeX的两个特性来构建一个定制的NER系统,它接受两个变量的输入:(i)句子的文本和(ii)我们想要检测的类别。
from wasabi import msg
from spacy import load as spacy_load
from spikex.wikigraph import load as wg_load
from spikex.pipes import WikiPageX
def wiki_entity_recognition(text, entity_root):
entities = []
wg = wg_load("enwiki_core") # 加载WikiGraph
wikipagex = WikiPageX(wg) # 创建wikipagex
nlp = spacy_load("en_core_web_sm")
doc = wikipagex(nlp(text)) # get doc with wiki pages extracted 获取doc文档
entity_root = entity_root.replace(" ", "_") # 修复空格,只是以防万一
# 获取距离为2的根目录的上下文
context = set(wg.get_categories(entity_root, distance=2))
for span in doc._.wiki_spans:
page_seen = set()
for page in span._.wiki_pages:
# 避免重复
pageid = wg.get_pageid(page)
if pageid in page_seen:
continue
page_seen.add(pageid)
# 检查与上下文的交集
categories = set(wg.get_categories(page))
if len(set.intersection(categories, context)) == 0:
continue
# 实体
entities.append((span, page))
return entities
# 定义文本
text = "Named Entity Recognition and Topic Modeling are two tasks of Natural Language Processing"
# 定义类别
entity_root = "Computational linguistic"
for ent in wiki_entity_recognition(text, entity_root):
print("%s - %s"%(ent[0],ent[1].upper()))
Named Entity Recognition - COMPUTATIONAL LINGUISTIC
Topic Modeling - COMPUTATIONAL LINGUISTIC
Natural Language Processing - COMPUTATIONAL LINGUISTIC
将维基百科的类别定义为NER任务的标签提供了定义NER系统的可能性,从而避免了数据训练问题。进一步的例子是使用display表示基于维基百科类别的NER系统提取的实体。

在这个例子中,“Programming Language”和“Computational Linguistics”作为输入给出,然后在文本中搜索。
主题模型
当谈到主题模型时,我们通常指的是能够发现文本体的“隐藏语义结构”的NLP工具。
最近,有人讨论“为了自动文本分析的目的,主题的定义在某种程度上取决于所采用的方法”[1]。潜Dirichlet分配(LDA)是一种流行的主题模型方法,它使用概率模型在文档集合中提取主题。
另一个著名的方法是TextRank,它使用网络分析来检测单个文档中的主题。近年来,自然语言处理领域的研究也引入了一些能够在句子水平上提取主题的方法。一个例子是语义超图,这是一种“结合机器学习和符号方法的优点,从句子的意义推断主题的新技术”[1]。
我们现在看到如何使用Wikipedia在句子和文档级别执行主题模型。
让我们考虑专利US20130097769A1的以下文本。
Encapsulated protective suits may be worn in contaminated areas to protect the wearer of the suit. For example, workers may wear an encapsulated protective suit while working inside of a nuclear powered electrical generating plant or in the presence of radioactive materials. An encapsulated protective suit may be a one-time use type of system, wherein after a single use the suit is disposed of. An encapsulated protective suit may receive breathing air during normal operating conditions via an external air flow hose connected to the suit. The air may be supplied, for example, by a power air purifying respirator (PAPR) that may be carried by the user.
topics = Counter()
for sent in doc.sents:
topics = Counter()
sent = nlp(sent.text)
sent = wikipagex(sent)
print(sent)
print('Topics in the sentence:')
for span in sent._.wiki_spans:
if (
len(span._.wiki_pages) > 1
or span[0].pos_ not in good_pos
or span[-1].pos_ not in good_pos
):
continue
topics.update(wg.get_categories(span._.wiki_pages[0], distance=2))
for topic, count in topics.most_common():
print('\t',topic.replace('Category:',''), "->", count)
print('----')
Sentence:
Encapsulated protective suits may be worn in contaminated areas to protect the wearer of the suit.
Topics in the sentence:
Safety -> 1
Euthenics -> 1
----
Sentence:
For example, workers may wear an encapsulated protective suit while working inside of a nuclear powered electrical generating plant or in the presence of radioactive materials.
Topics in the sentence:
Safety -> 1
Euthenics -> 1
Electricity -> 1
Electromagnetism -> 1
Locale_(geographic) -> 1
Electric_power_generation -> 1
Power_stations -> 1
Infrastructure -> 1
Energy_conversion -> 1
Chemistry -> 1
Radioactivity -> 1
----
Sentence:
An encapsulated protective suit may be a one-time use type of system, wherein after a single use the suit is disposed of.
Topics in the sentence:
Safety -> 1
Euthenics -> 1
Transportation_planning -> 1
Feminist_economics -> 1
Schools_of_economic_thought -> 1
Land_management -> 1
Architecture -> 1
Planning -> 1
Transport -> 1
Feminism -> 1
Urban_planning -> 1
Feminist_theory -> 1
Urbanization -> 1
Spatial_planning -> 1
Social_sciences -> 1
----
Sentence:
An encapsulated protective suit may receive breathing air during normal operating conditions via an external air flow hose connected to the suit.
Topics in the sentence:
Safety -> 1
Euthenics -> 1
Chemical_industry -> 1
Gases -> 1
Industrial_gases -> 1
Breathing_gases -> 1
Diving_equipment -> 1
Respiration -> 1
Electromechanical_engineering -> 1
Heat_transfer -> 1
Home_appliances -> 1
Engineering_disciplines -> 1
Automation -> 1
Building_engineering -> 1
Temperature -> 1
Heating,_ventilation,_and_air_conditioning -> 1
----
Sentence:
The air may be supplied, for example, by a power air purifying respirator (PAPR) that may be carried by the user.
Topics in the sentence:
Personal_protective_equipment -> 1
Air_filters -> 1
Respirators -> 1
Protective_gear -> 1
----
专利文本的每一句话都用SpikeX进行处理,并从句子中检测到的相应Wikipedia页面中提取类别。我们把话题作为维基百科的分类。这样我们就有了第一个简单的话题检测。
这种方法不同于语义超图、文本秩或LDA,它在不直接引用术语的情况下查找句子主题的标签。提取的主题的标签是指与SpikeX匹配的Wikipedia页面的类别。如果我们使用这种方法聚合每个句子的主题,我们就可以更好地表示整个文档。
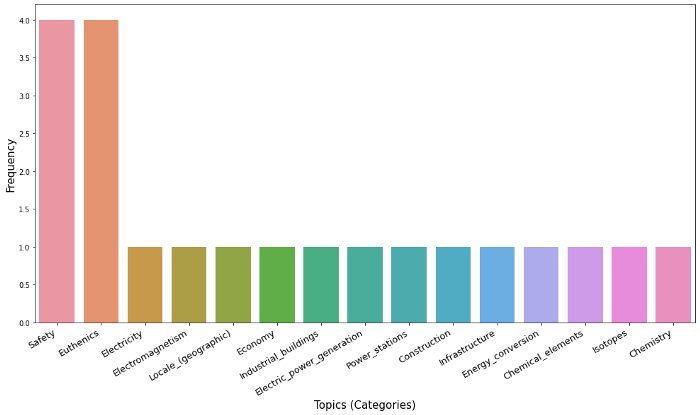
在句子中划分类别的频率可以更广泛地了解文本的主题分布。”“安全”和“安乐死”比其他类别出现得更频繁。
我们现在使用整个专利文本(可在Google专利中获得)来查找分类分布。
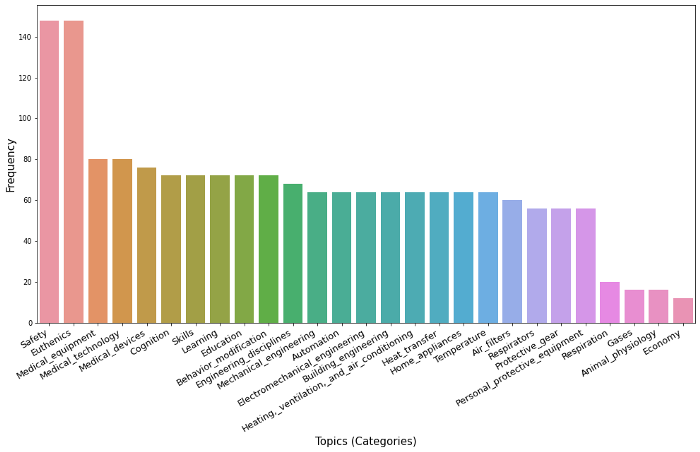
如我们所见,我们可以自动检测整个文档的主题(或类别)(在本例中是专利)。看看前5个类别,我们可以推断出这项专利是关于什么的。这是在没有任何训练的情况下完成的。
结论
Wikipedia作为知识的来源已经被开发了十多年,并且在各种应用中被反复使用:文本注释、分类、索引、聚类、搜索和自动分类生成。事实上,Wikipedia的结构有许多有用的特性,使其成为这些应用程序的良好候选。
这篇文章演示了如何使用这个强大的源代码来改进NLP的简单任务。然而,并不是说这种方法优于其他最先进的方法。评估自然语言处理任务准确性的精确度和召回率的典型测量方法,在这篇文章中没有显示。
此外,这种方法也有优点和缺点。其主要优点在于避免了训练,从而减少了耗时的注释任务。可以将维基百科视为一个庞大的训练机构,其贡献者来自世界各地。
这对于有监督的任务(如NER)和无监督的任务(如主题模型)都是如此。这种方法的缺点是双重的。首先,维基百科是一个公共服务,作为一个由专家和非专家贡献的知识库。其次,从主题模型的结果可以看出,自然语言的歧义性会导致偏误表现。词义消歧和非专家驱动的数据整理明显影响整个系统的可靠性。
参考引用
[1] Menezes, Telmo, and Camille Roth. “Semantic hypergraphs.” arXiv preprint arXiv:1908.10784 (2019).
往期精彩回顾 本站qq群851320808,加入微信群请扫码: