
LRC-BERT:对比学习潜在语义知识蒸馏|AAAI 2021

新智元报道
新智元报道
作者:高德智能技术中心
【新智元导读】高德智能技术中心研发团队在工作中设计了对比学习框架进行知识蒸馏,并在此基础上提出COS-NCE LOSS,该论文已被AAAI2021接收。
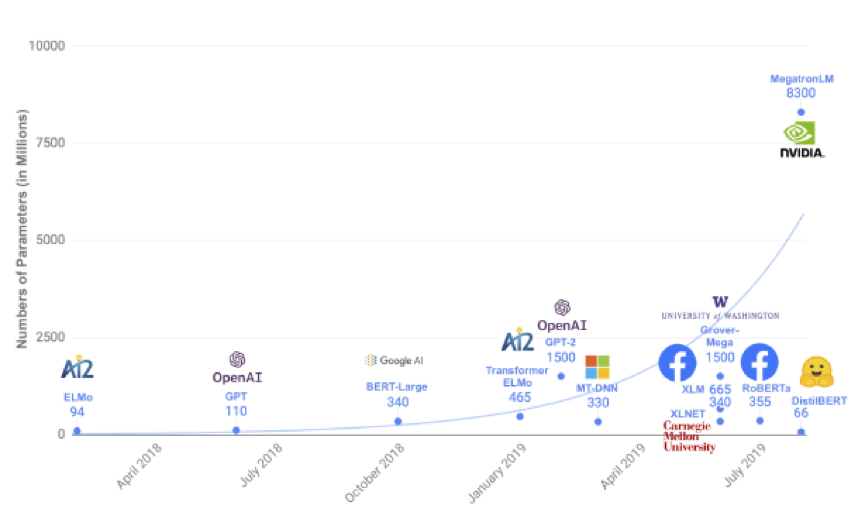
而NLP领域近期最重要的进展当属预训练模型,Google发布的BERT预训练语言模型一经推出霸占了NLP各大榜单,提升了诸多 NLP 任务的性能,在11种不同NLP测试中创出最佳成绩,预训练模型成为自然语言理解主要趋势之一。
背景介绍
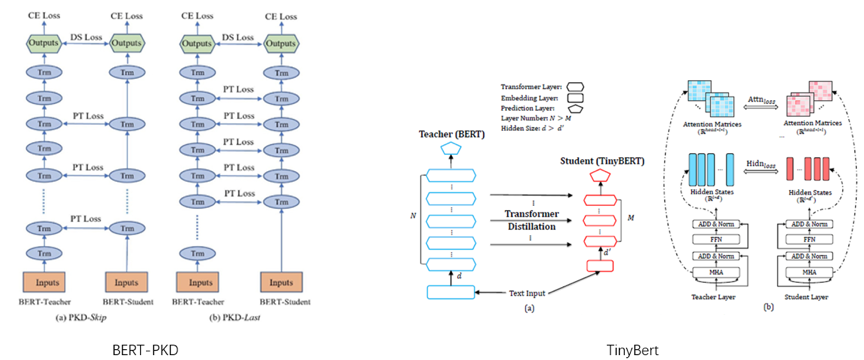
方法
3.1 问题定义
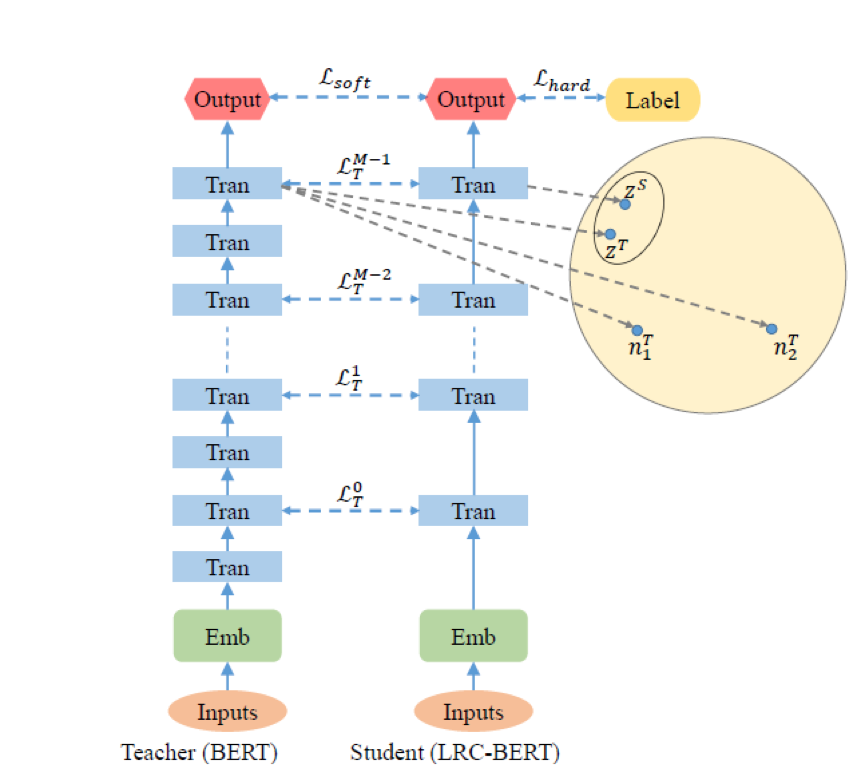
teacher网络定义为fT(x,θ):x为模型输入,θ为模型参数,模型输出为ZT。student网络定义为 fS(x,θ‘) 同时输出为ZS 。目标是student的fS(x,θ') 表达更加贴近fT(x,θ)表达,同时最小化prediction layer loss,使student与teacher具有同样的性能。
3.2 模型蒸馏结构
如下图即为LRC-BERT结构,对比学习作用在中间层表达使student能够学习到teacher潜在语义信息。举例来说,对于student表达ZS与teacher特征表达ZT靠近,而要远离负例n1T和n2T。
3.3 COS-based NCE loss
对比学习的概念很早就有,但真正成为热门方向是在2020年的2月份,Hinton组的Ting Chen提出了SimCLR[9],用该框架训练出的表示以7%的提升刷爆了之前的SOTA,甚至接近有监督模型的效果。
对比学习目标是为输入X学习一个表示 Z(最好的情况就是知道Z就能知道X),衡量方式采用互信息I(X,Z),最大化互信息的目标进行推导就会得到对比学习的loss(也称InfoNCE),其核心是通过计算样本表示间的距离,拉近正样本,拉远负样本获取X深层信息表达。
本文设计了对比损失COS-NCE用于中间层知识蒸馏。对于一个给定的teacher网络fT(x,θ) 以及student网络fS(x,θ'),任何一个正例随机选择 K negative samples N = {n1-, n2-, ......., nk- },因此得到teacher中间层表达ZT,student中间层表达ZS ,以及K个负例表达 N= {n1-, n2-, ......., nk- }。
不同于之前对比学习采用Euclidean distance or mutual information作为loss, 本文提出cos角度度量方式来进行对比学习。如下图所示
(a)在特征空间ZS与ZT角度更加贴近,而与负例nTcos角度差异变大。
(b)对于不同的student fs1 fs2(student fs1 语义与teacher语义更相似):在Euclidean distance(绿色)上Zs2更加贴近ZT,然而在基于cos-based距离衡量上Zs1相对比Zs2更贴合ZT,可见cos-based更加符合语义特征表达度量。

COS-based NCE loss公式如下,g(..,..) -> [0,2]用来衡量两个向量角度distance,g(x,y)越小代表两个向量越相似,g(x,y)=2代表两个向量不相似状态的边界。COS-NCE设计动机是最小化ZS和ZT的角度distance,最大化ZS和NT角度distance。
如下图所示,g(niT, zS ) 与g(zT, zS ) 的距离需要被放大,本文的处理是将最大化问题转换成最小化问题,其具体定义为:2-(g(niT, zS ) -g(zT, zS ))。
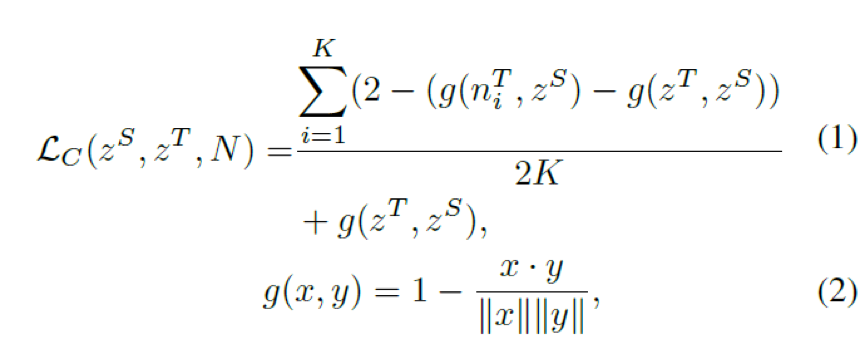
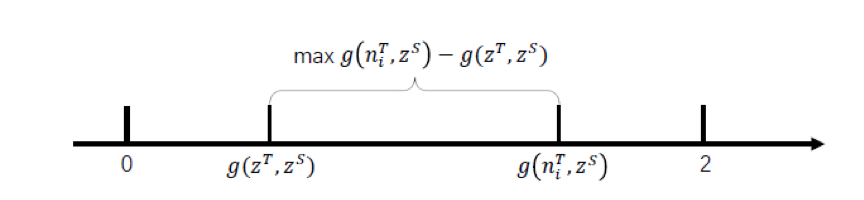
3.4 Distillation for transformer-layer
COS-NCE用于transformer-layer的蒸馏,每个tranformer-layer包含multi head attention以及FFN,本文针对FFN的输出进行蒸馏。这里假定teacher有N-transformer layer,student 有M-transformer layer。
这里我们选择使用uniform的方式完成teacher的N-transformerlayer与student的M-transformerlayer之间的映射。公式如下,hiS ∈ Rl×d 表示student网络i-th transformer layer的输出。hφiT ∈ Rl×d‘表示teacher网络φi-th transformer 的输出。j = φi即为层数映射函数student学习teacher对应层数输出,l 表示文本长度,d‘ d 表示teacher student hidden size( d的维度少于d')。
HiT = { h0,iT, h1,iT, ........, hk-1,iT } 对应teacher网络i-th transformer Knegative 样本。W ∈ Rd×d‘为维度映射参数,目的将student与teacher hidden size对齐。
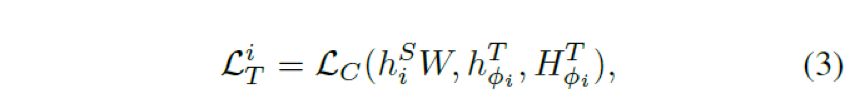
3.5 Distillation for predict-layer
更好的适配下游预测任务,本文采用student的预测层输出学习teacher的预测层输出,即softloss。同时student学习real label,即hardloss。其中KL divergencce用于student学习teacher预测分布,cross-entropy loss用于student学习real label。
yS、yT分别是student、teacher的预测输出,t controls the smoothness of the output distribution, y为真实label。公式6是最终损失函数, α β γ分别是不同损失的加权系数。
为了让模型更加高效的学习中间层表达,本文采用两阶段训练方法,在第一阶段我们先关注中间层的对比损失 α β γ 设置为 1,0,0。在第二阶段 β γ 权重设置大于0保证模型有能力预测下游任务。
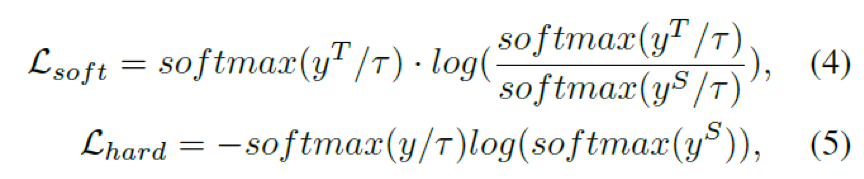
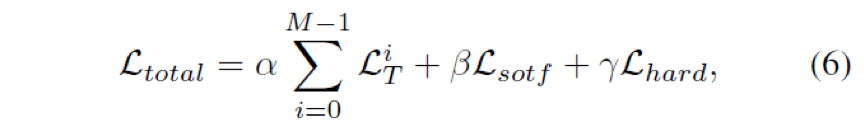
3.6 Training based on Gradient Perturbation
模型结构是影响鲁棒性重要因素,因此如何让模型更加鲁棒成为模型压缩算法中一个重要的关注点。之前在模型压缩剪枝算法中引入过正则化以增加可靠性,而本文引入了梯度扰动技术增强LRC-BERT的鲁棒性。
下图展示梯度扰动过程,本文没有直接使用Ltotal对model进行反向梯度传播,而是优先计算emb的梯度▽Ltotal(embS) 将其作用于embS输入进行扰动。最终使用梯度扰动之后loss对model进行参数更新。如下公式embS'是增加梯度扰动的表示。

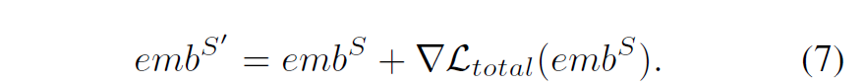
实验
4.1 数据集
GLUE Benchmark https://gluebenchmark.com/(通用语言理解评估基准)是衡量自然语言理解技术水平的重要指标。数据集包含了自然语言推断、语义相似度、问答匹配、情感分析等9项任务。本文将LRC-BERT在GLUE数据集合上进行评测。
4.2 实验参数设置
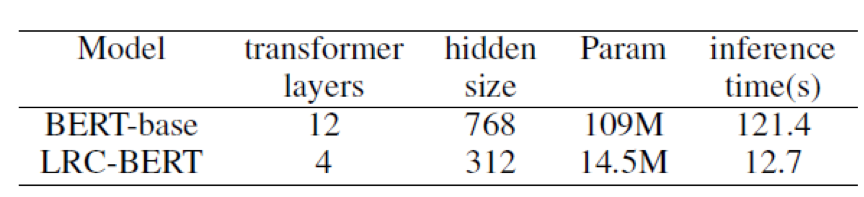
本文采用BERT-Base作为teacher,其包含12层transformer,每层包含12 attention head,768 hidden size, 3072 intermediate size。student网络采用4层transformer,每层包含12 attention head,312 hidden size, 1200 intermediate size。为了更好验证LRC-BERT有效性,本文设置了两组模型:LRC-BERT包含预训练(使用Wikipedia corpus)、specific tasks蒸馏;LRC-BERT1直接进行specific tasks蒸馏。
蒸馏实验中,学习率选择 { 5e-5, 1e-4, 3e-4 }, batch size 16。MRPC RTE CoLA 训练数据少于10K的数据集采用 90 epoch,其他数据集合采用18 epochs。两阶段实验设置,80% steps使用第一阶段 { α :β :γ = 1 : 0 : 0 },剩下20%step使用第二阶段训练{ α :β :γ = 1 : 1 : 3 },t 设置1.1。
4.3 主要实验结果
主要实验结果如下:(1)LRC-BERT明显优于DistillBERT、BERT-PKD、TinyBERT。平均预测效果LRC-BERT保留BERT-base 97.4%的性能。说明LRC-BERT的有效性。(2)训练数据量较大的数据集合上(>100K), LRC-BERT1直接在下游任务上蒸馏。对比TinyBERT分别在MNLI-m, MNLI-mm,QQP,QNLI上分别提高0.3%,0.8%,0.6%,0.6%。(3)LRC-BERT对比LRC-BERT1s在MRPC,RTE,CoLA分别提高4%,12.1%,14.9%。
同时另一个重要参考指标是模型推理速度,下图所示LRC-BERT取得了9.6×速度提升,modelsize上取得了7.5× 收益。

4.4 消融实验
消融实验在MNLI-m, MNLI-mm, MPRC, CoLA数据集合上从loss function 以及 梯度扰动上进行分析。
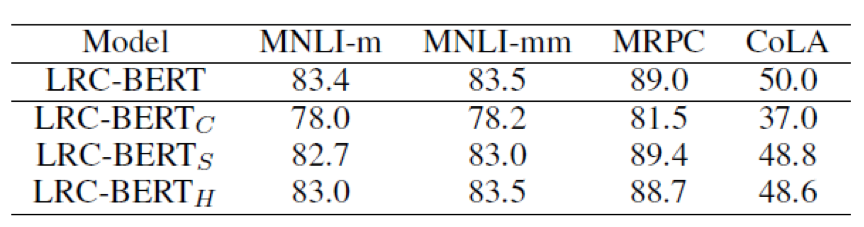
Effect of different loss function,本文分别移除COS-NCE,softloss, hardloss 验证模型效果,分别用LRC-BERTC LRC-BERTS LRC-BERTH 表示。如下图所示,COS-NCE影响权重最大去除后在如下实验中效果最差,特别在CoLA数据集合上去除COS-NCE效果从50到37。而softloss, hardloss对最终效果影响有限。综上三种损失对LRC-BERT均有效。
Effect of gradient perturbation,梯度扰动能够在训练过程中影响中间层数据分布,同样验证效果采用LRC-BERTg作为去除gradient perturbation模型。下图展示在MNLI-m训练过程中training loss变化,在第二阶段LRC-BERT损失振幅相对比LRC-BERTg减弱,LRC-BERT趋于稳定状态。

Analysis of Two-stage Training Method,采用两阶段的目的是为了让student在训练开始阶段更加专注于学习teacher中间层表达,同样设置LRC-BERT2去除二阶段训练直接采用{ α :β :γ = 1 : 1 : 3 }在MNLI-m进行训练。效果如下图所示,去除两阶段效果下降明显,同样也能够说明COS-NCE在中间层蒸馏的作用。

Analysis of Two-stage Training Method,COS-NCE采用cos角度distance对中间层transformer蒸馏,同时本文采用BERTM(中间层使用MSE替换COS-NCE作为loss)为对比。随机抽取case分析,前两个case LRC-BERT以及BERTM预测正确,而后面两个BERTM预测比较波动导致预测错误,LRC-BERT angular distance在预期范围内,由此可见LRC-BERT 能够有效捕捉到深层语义信息。

在高德具体业务场景的落地
动态事件是指由于道路通行能力变化影响用户出行事件,包括封闭、施工、事故等。作为高德交通动态事件重要获取途径NLP事件抽取业务,主要流程为收集交通官方平台以及各个媒体平台信息,经过命名实体识别、事件拆分组合最终输出动态事件,影响Amap用户出行规划路线,如下图示例。
本⽂提出的方法已在高德交通动态事件抽取中落地,LRC-BERT保留了BERT-base 97%的性能,人工评测平日准确率提高4%,召回率提高3%;节假日准确率提高5%,召回率提高7%。此外,本方法训练方法简单,复现成本低,可广泛应用在使用自然语言理解(NLU)各个业务线,提高模型推理速度降低部署成本。

总结
本文创新提出了对比学习框架进行知识蒸馏,并在基础上提出COS-NCE LOSS可以有效的捕捉潜在语义信息。梯度扰动技术首次引入到知识蒸馏中,在实验中验证其能够提升模型的鲁棒性。
为了更加高效提取中间层潜在语义信息采用使用两阶段模型训练方法。GLUE Benchmark实验结果表明LRC-BERT模型有效性。

