点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达

在 Transformer 推动自然语言处理领域迅猛发展的当下,基于图神经网络的 NLP 研究也不容忽视。在近日的一篇综述论文中,来自京东硅谷研发中心、伦斯勒理工学院、浙江大学等机构和高校的研究者首次对用于 NLP 的图神经网络(GNN)进行了全面综述。其中涵盖大量相关和有趣的主题,如用于 NLP 的自动图构建、图表示学习和各种先进的基于 GNN 的编码器 - 解码器模型以及各种 NLP 任务中的 GNN 应用。本文共同一作为吴凌飞(京东硅谷研发中心)与 Yu Chen(伦斯勒理工学院)。

论文地址:https://arxiv.org/pdf/2106.06090.pdf在解决自然语言处理(NLP)领域的各式问题时,深度学习(DL)已经成为当今的主导方法,尤其是当操作大规模文本语料时。传统的典型方法是将文本序列视为一组 token,比如 BoW(词袋)和 TF-IDF。随着近来词嵌入技术的成功,NLP 任务通常会将句子表示成 token 序列。因此,循环神经网络(RNN)和卷积神经网络(CNN)等常用深度学习技术已经在文本序列建模方面得到了广泛应用。但是,对于大量各式各样的 NLP 问题,图结构才是最好的表示方式。举个例子,使用文本序列中的句子结构信息(比如依存关系和结构成本解析树),可通过整合特定于当前任务的知识来为原始序列数据提供增补。类似地,序列数据中的语义信息(比如摘要含义表示图和信息抽取图等语义解析图)也可用于增补原始序列数据。因此,这些图结构的数据可以编码实体 token 之间成对的关系,进而可用于学习信息更丰富的表示。遗憾的是,在欧几里得数据(如图像)或序列数据(如文本)上具有颠覆性能力的深度学习技术却无法直接应用于图结构数据,这是因为图数据比较复杂,涉及到结构不规则和节点近邻数据大小不一致等情况。因此,这激起了图深度学习的研究浪潮,尤其是图神经网络的发展。这波位于图深度学习和 NLP 交集处的研究浪潮已经影响到了大量 NLP 任务。在开发不同的 GNN 变体以及将它们用于许多 NLP 任务(包括分类任务、关系抽取和生成任务)上,研究社区兴趣浓厚并且已经取得了一些成功。尽管有这些成功的研究案例,但用于 NLP 的图深度学习研究仍旧面临着许多挑战:如何将原始文本序列数据自动转换成高度结构化的图结构数据?这是 NLP 领域的一个重大问题,因为大多数 NLP 任务使用的初始输入都是文本序列。为了将图神经网络用于 NLP 问题,一大关键步骤是基于文本序列来自动构建图,进而利用其底层的结构信息;
如何确定该使用哪种合适的表示学习技术?图包括无向图、有向图、多关系图和异构图等不同形式,因此为了学习不同图结构数据的特有特征,使用针对具体情况专门设计的 GNN 是至关重要的;
如何有效地建模复杂数据?这是一个重要的挑战,因为许多 NLP 任务都涉及到学习基于图的输入和其它高度结构化输出数据(比如序列、树以及不同类型的图数据)之间的映射关系。
这篇综述首次全面总结了用于自然语言处理的图神经网络。作者表示,这篇综述对机器学习和 NLP 社区而言都是符合时宜的。其中涵盖了广泛的相关主题,包括用于 NLP 的自动图构建、用于 NLP 的图表示学习、用于 NLP 的基于各种高级 GNN 的编码器 - 解码器模型(如 graph2seq、graph2tree 和 graph2graph)以及 GNN 在各种不同 NLP 任务中的应用。在篇幅长达 127 页的论文中,研究者做出了以下主要贡献:文中为用于 NLP 的 GNN 提出了一种新的分类法,其沿图构建、图表示学习和基于图的编码器 - 解码器模型三大主轴对当前相关研究进行了系统性的归纳组织;
本文为用于各种 NLP 任务的当前前沿的 GNN 方法进行了最全面的汇总。文章详细地描述了基于领域知识和语义空间的各种图构建方法、用于各种不同类别的图结构数据的图表示学习方法、使用不同输入和输出数据类型组合的基于 GNN 的编码器 - 解码器模型。文中也给出了必要的比较;
文中介绍了大量利用 GNN 的 NLP 应用,包括如何使用 GNN 在三大组件(图构建、图表示学习和嵌入初始化)中解决 NLP 任务并会提供对应的基准数据集、评估指标和开源代码;
文章最后还列出了为 NLP 任务充分使用 GNN 方面的各种突出难题,另外还讨论并建议了能产生丰富成果的未经探索的研究方向。
这篇综述提出的分类法如下图 1 所示,其对用于 NLP 的 GNN 进行了系统性的组织归纳并将其分为三大方向:图构建、图表示学习和编码器 - 解码器模型。另外也涵盖相关应用。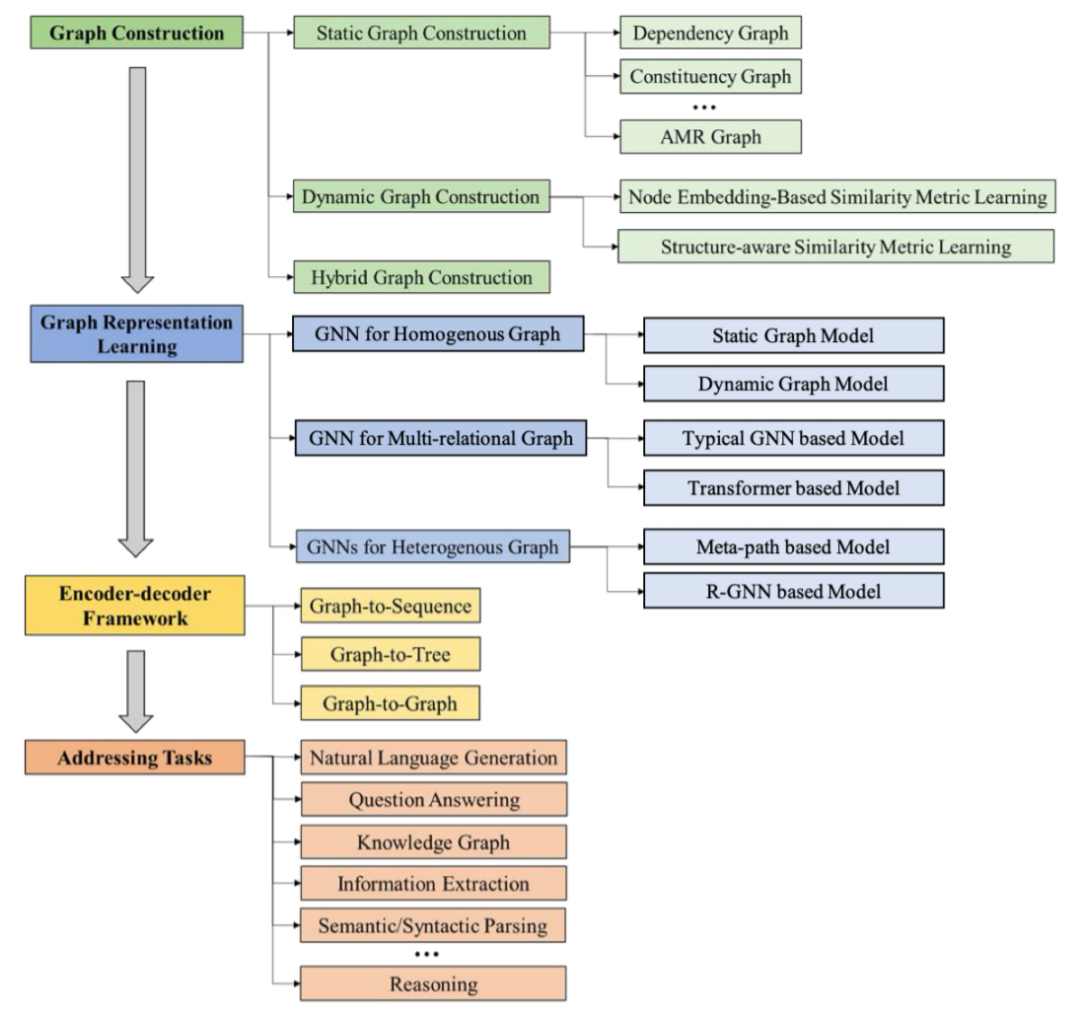
下面将简要介绍论文的核心内容框架,详情请参阅原论文。本节首先将立足于图来介绍 NLP 问题,然后会简要介绍在解决 NLP 问题方面一些代表性的传统图方法。我们表示自然语言的方式反映了自身看待自然语言的方法,也因此对我们处理和理解语言的方式有根本性的影响。一般来说,表示自然语言的方式有三种。最简单的方法是将自然语言表示成一组 token。这种看待自然语言的方式完全忽视了 token 在文本中的特定位置,只考虑了不同 token 在文本中出现的次数。
一种更自然的方法是将自然语言表示成 token 序列。这是人类通常讲述和书写自然语言的方式。
第三种方法是将自然语言表示成图。图在 NLP 中无处不在。尽管将文本视为序列数据可能是最显而易见的方式,但在 NLP 社区,将文本表示成各式各样的图是由来已久的操作。文本或世界知识的常见图表示包括依存关系图、结构成分图、AMR 图、IE 图、词汇网络和知识图谱。此外,文本图的元素也可以包含多个层级,比如文档、段落、句子和词。
相比于前两个角度,从这个角度看待自然语言能够捕获到更丰富的文本元素关系。很多传统的基于图的方法(比如随机游走、标签传播)已经在一些挑战性的 NLP 问题上得到了成功应用,包括词义消歧、名称消歧、共指消解、情感分析和文本聚类。本节将介绍各种已成功应用于 NLP 应用的基于图的经典算法。随机游走算法:随机游走这类基于图的算法会在图中产生随机路径。在一次随机游走收敛之后,可得到图中所有节点之上的一个平稳分布;
图聚类算法:常见的图聚类算法包括谱聚类、随机游走聚类和最小切割(min-cut)聚类;
图匹配算法:图匹配算法的目标是计算两个图的相似度;
标签传播算法:标签传播算法(LPA)是一种半监督的基于图的算法,其可将标签从已标注的数据点传播到之前未标注的数据点。
图神经网络(GNN)是一类直接基于图结构数据运作的现代神经网络,本节将介绍 GNN 的基础知识和基本方法。图神经网络本质上就是图表示学习模型,可应用于以节点为中心的任务和以图为中心的任务。GNN 可学习图中每个节点的嵌入并将节点嵌入聚合起来得到图嵌入。图过滤并不改变图的结构,但会优化节点嵌入。可通过堆叠多层图过滤层来生成最终的节点嵌入。图过滤:图过滤器有多种实现方式,它们可大致分为基于谱的图过滤器、基于空间的图过滤器、基于注意力的图过滤器和基于循环的图过滤器。从概念上讲,基于谱的图过滤器基于谱图论(spectral graph theory),而基于空间的方法会使用图中空间上邻近的节点来计算节点嵌入。某些基于谱的图过滤器可以转换成基于空间的图过滤器。基于注意力的图过滤器的灵感来自于自注意力机制,其会为不同的近邻节点分配不同的权重。基于循环的图过滤器会引入门控机制,模型参数在不同的 GNN 层共享。图池化:图池化层的设计目的是为以图为中心的下游任务生成图层面的表示,比如基于从图过滤学习到的节点嵌入来执行图分类和预测。这是因为所学习到的节点嵌入对以节点为中心的任务来说是足够的,但是以图为中心的任务则需要图的整体表示。为此,我们需要归纳总结节点嵌入信息和图结构信息。图池化层可分为两大类:平式图池化(flat graph pooling)和分层式图池化。平式图池化会直接从节点嵌入一步到位地生成图层面的表示。相对而言,分层式图池化包含多个图池化层,并且每个池化层都在一些叠放的图过滤器之后。本节简要介绍了一些代表性的平式池化层和分层式池化层。前一节介绍了当输入为图时的 GNN 基础知识和基本方法。不幸的是,对于大多数 NLP 任务而言,输入一般并不是图,而是文本序列。因此,为了利用 GNN,基于文本序列来构建用作输入的图就成了一个必需的步骤。本章将重点介绍两大类用在各种 NLP 任务中构建图结构输入的图构建方法,即静态图构建和动态图构建。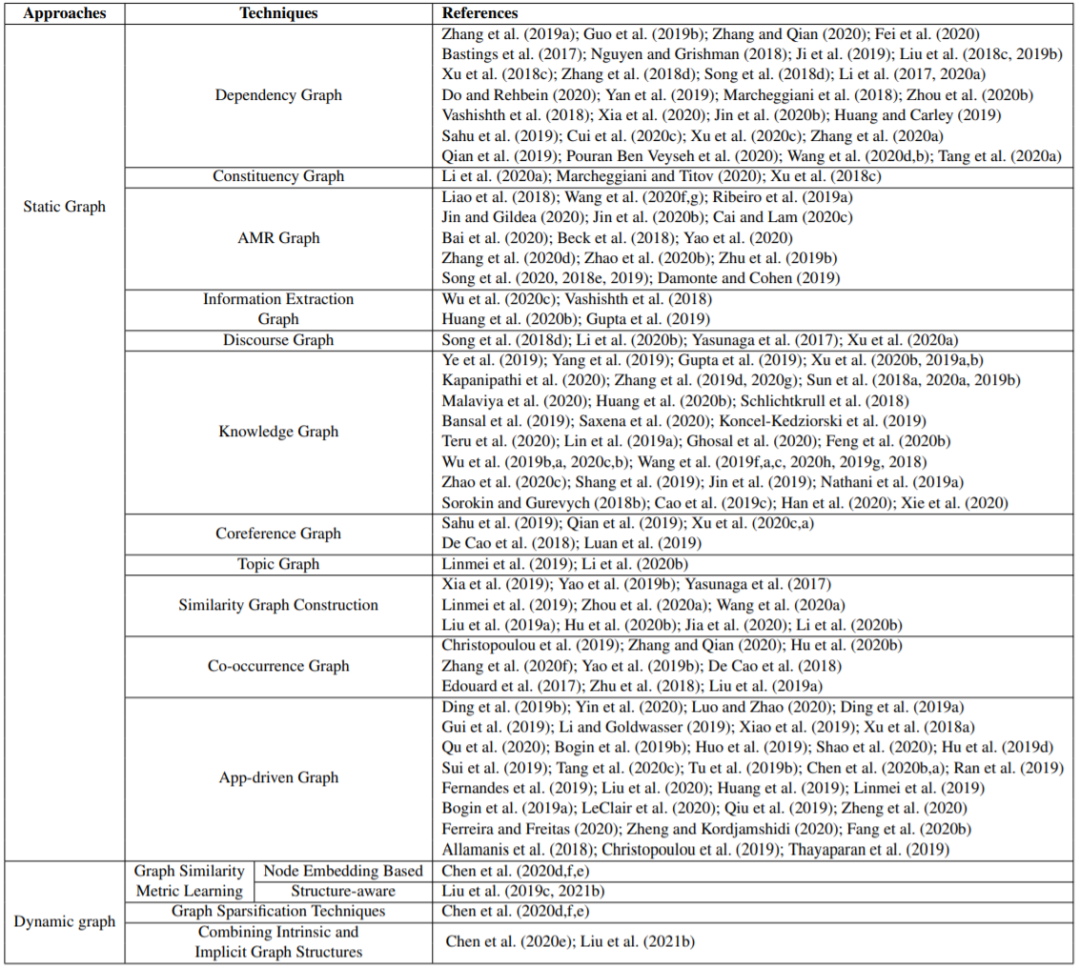
静态图构建方法的目标是在预处理阶段构建图结构,其通常使用的是已有的关系解析工具(比如依存关系解析)或人工定义的规则。从概念上讲,静态图会整合隐藏在原始文本中的不同领域 / 外部知识,这能在原始文本的基础上增补丰富的结构化信息。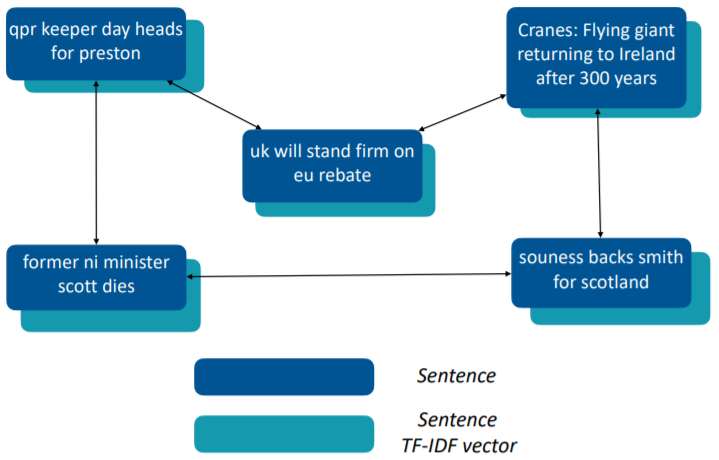
图 6:相似度图构建的一个示例。使用句子作为节点并使用 TF-IDF 向量来初始化它们的特征。虽然静态图构建在将数据的先验知识编码进图结构方面有优势,但也存在一些局限性。首先,为了构建表现合理的图拓扑结构,需要大量人力和领域专业知识;其次,人工构建的图结构可能很容易出错(有噪声或不完备);第三,由于图构建阶段和图表示学习阶段是分开的,所以在图构建阶段引入的误差无法得到校正,并可能累积到后续阶段,从而影响结果表现;最后,图构建过程的信息往往仅来自机器学习实践者的想法,而它们对下游而言可能并不是最优的。为了解决上述难题,最近有的 NLP GNN 探索了动态图构建方法,这无需人类来提供领域专业知识。大多数动态图构建方法的目标都是根据情况动态地学习图结构(即加权的邻接矩阵),并且图构建模块可与后续的图表示学习模块联合优化,以端到端地方式解决下游任务。如下图 10 所示,动态图创建方法通常包含一个图相似度度量学习组件,其可根据嵌入空间中每对节点的相似度来学习一个邻接矩阵;另外还有一个图稀疏化组件,其可从所学习到的全连接图提取一个稀疏图。有研究发现,将本身固有的图结构与学习到的隐含图结构组合起来有助于实现更好的学习效果。此外,为了有效地联合执行图结构学习和表征学习,研究社区也提出了多种学习范式。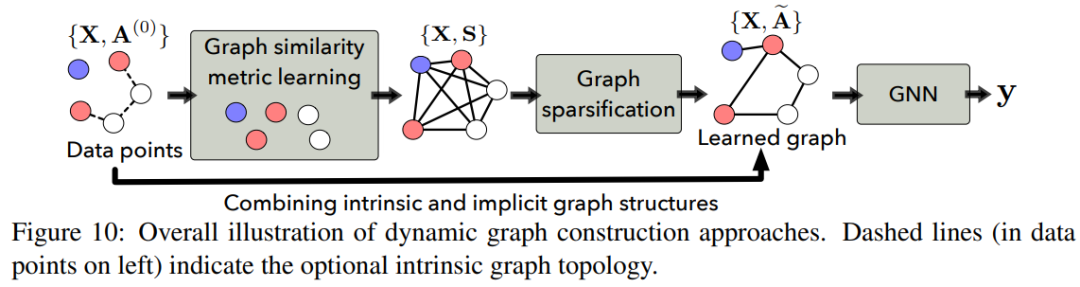
图 10:动态图构建的整体图示。虚线(左侧的数据点中)表示可选的本身固有的图拓扑关系。本节将讨论用于各种 NLP 任务的直接操作结构化图的多种图表示学习技术。图表示学习的目标是通过机器学习模型找到将图的结构和属性信息整合进低维嵌入中的方法。一般而言,基于原始文本数据构建的图要么是同构的,要么就是异构的。用于同构图的 GNN:GCN、GAT 和 GraphSage 等大多数图神经网络都是为同构图设计的,但是同构图并不适用于很多 NLP 任务;
用于多关系图的图神经网络:在实践中,许多图的边都有多种类型,比如知识图谱、AMR 图等,这样的图可以构建为多关系图形式;
用于异构图的图神经网络:在实践中,许多图的节点和边都有多种类型,这样的图被称为异构图。
在 NLP 领域,编码器 - 解码器架构是最常用的机器学习框架之一,比如 Seq2Seq 模型。由于 GNN 在建模图结构数据方面能力非凡,近期在开发基于 GNN 的编码器 - 解码器框架方面出现了许多研究成果,包括图到树(Graph-to-Tree)模型和图到图(Graph-to-Graph)模型。本节首先将介绍典型的 Seq2Seq 模型,然后讨论用于不同 NLP 任务的基于不同图的编码器 - 解码器模型。包括如下: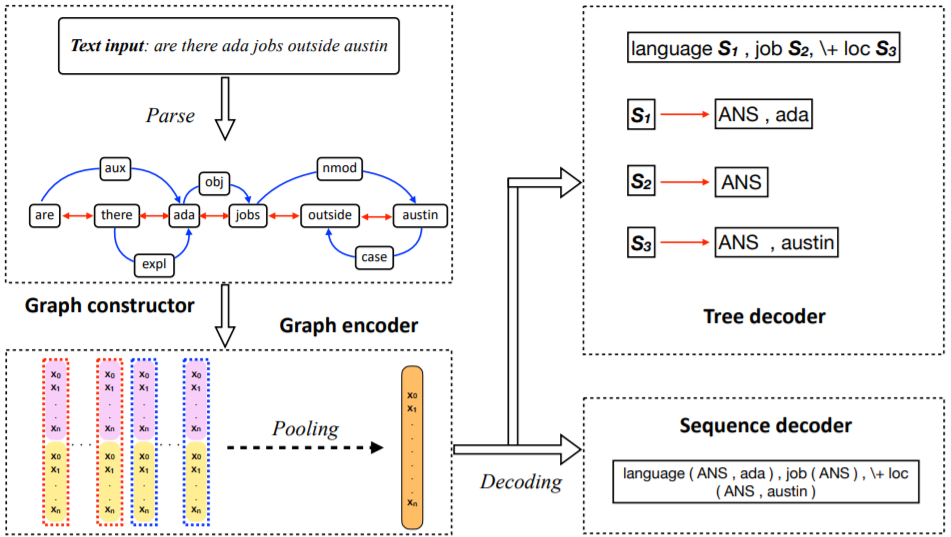
图 11:基于图的编码器 - 解码器模型的整体架构,其中包含 Graph2Seq 和 Graph2Tree。S_1 和 S_2 等节点表示子树节点,新的分支由此而生。这章将讨论使用 GNN 的许多不同类型的典型 NLP 应用,包括自然语言生成、机器阅读理解、问答、对话系统、文本分类、文本匹配、主题建模、情感分类、知识图谱、信息抽取、语义和句法解析、推理和语义角色标注。下表 3 总结了所有应用的子任务和评估指标。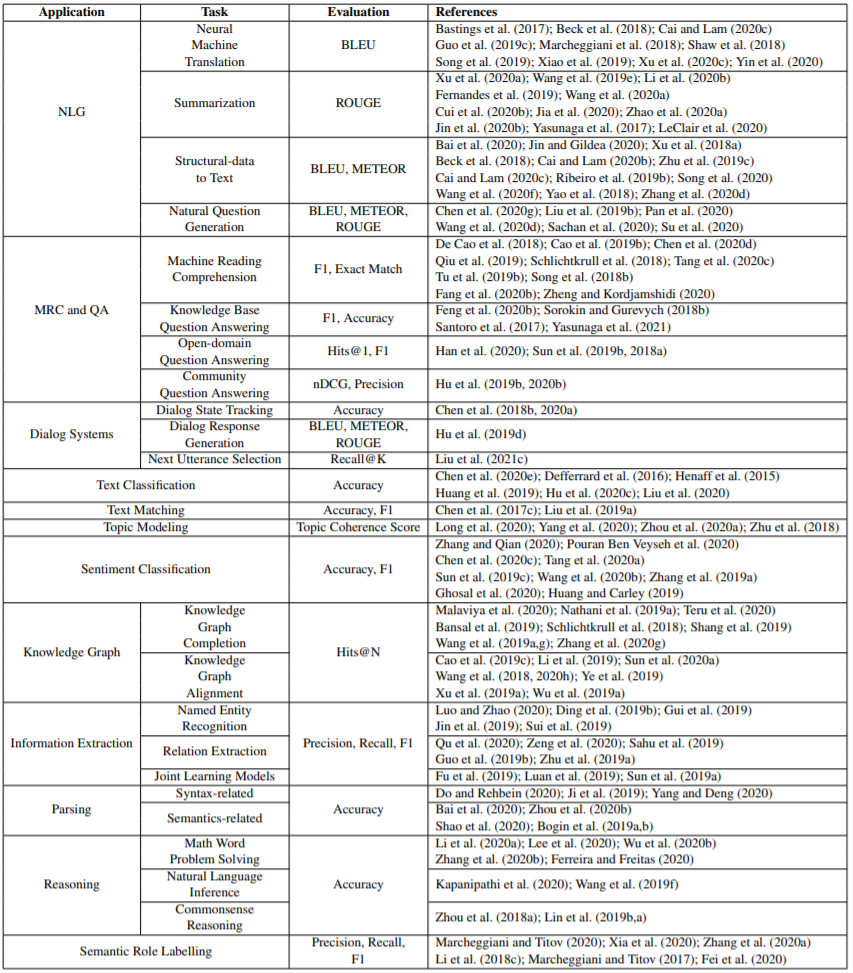
表 3:使用 GNN 的典型 NLP 应用和相关研究工作。本章将讨论用于 NLP 的 GNN 的多种常见挑战,并会指出未来的研究方向。动态图构建:即便动态图构建方面已有一些研究成果,但 NLP 领域的大多数 GNN 应用仍旧严重依赖领域专业知识来构建静态图。用于 NLP 的动态图构建仍旧处于早期探索阶段,仍面临着许多挑战;
在 NLP 方面,GNN 与 Transformer 哪个更好:Transformer 凭借其在许多 NLP 应用中的出色表现而赢得了远远更多的研究关注。由于两类技术各自都有相较于彼此的明显优势,因此其中还有一些有趣的研究方向值得探究;
用于 NLP 的图到图模型:在为 NLP 任务使用图到图模型方面,还存在一些普遍性难题值得探索;
NLP 中的知识图谱:知识图谱已成为许多 NLP 任务的重要组件,但也存在许多挑战,涉及知识图谱增强、知识图谱嵌入和完成以及知识图谱对齐;
多关系图神经网络:尽管进展颇丰,但由于图中存在多式多样的关系,因此解决超参数化问题仍旧是一大挑战。
吴凌飞博士现任京东硅谷研发中心的首席科学家。吴博士曾经是IBM T. J. Watson Research Center研究科学家和团队带头人。吴博士在2016年从威廉玛丽大学取得计算机博士学位。他的研究内容包括机器学习,表征学习,和自然语言处理。吴博士带领的Graph4NLP (Deep Learning on Graphs for Natural Language Processing) 团队(12+ 研究科学家)致力于机器学习与文本数据挖掘领域的基础研究,并运用机器学习与文本数据挖掘方法解决实际问题。其学术成果先后发表在NeurIPS, ICML, ICLR, ACL, EMNLP, KDD, AAAI, IJCAI等国际顶级会议及期刊上,发表论文超过80多篇。代表作包括IDGL, MGMN, Graph2Seq, GraphFlow。多项学术论文获得著名国际大会的最佳论文和最佳学术论文奖,包括IEEE ICC 2019。吴博士同时现任IEEE影响因子最高期刊之一IEEE Transactions on Neural Networks and Learning Systems(TNNLS) 和 ACM SIGKDD 旗舰期刊 ACM Transactions on Knowledge Discovery from Data (TKDD) 的副主编。多次组织和担任国际顶级会议大会或者领域主席,如AAAI, IJCAI, KDD, NeurIPS, ICLR, ICML, ACL, EMNLP。
个人主页:https://sites.google.com/a/email.wm.edu/teddy-lfwu/home陈宇博士现任Facebook AI硅谷总部的研究科学家。陈博士在2020年从美国伦斯勒理工学院取得计算机科学博士学位,并获校优秀博士学位论文奖及系优秀研究生奖。当前研究方向为机器学习和自然语言处理。其学术成果先后发表在NeurIPS, ICLR, IJCAI,NAACL,KDD等多个国际顶级会议上,并曾获AAAI DLGMA’20最佳学生论文奖。其研究成果被国内外多家媒体报道,包括World Economic Forum, TechXplore等。
陈宇博士参与的DLG4NLP系列tutorial被NAACL’21,IJCAI’21,KDD’21,SIGIR’21等国际顶级会议录用。陈博士多次担任国际顶级会议(如ACL,EMNLP,NAACL,IJCAI)和期刊(如TNNLS,TKDE,TASL,IJIS)的程序委员会成员和审稿人。陈博士是4项美国专利的发明人。

个人主页:http://academic.hugochan.net/
