
「Python数据分析系列」数据科学基本介绍
作者 | Joel Grus
译者 | cloverErna
校对 | gongyouliu
编辑 | auroral-L
第一章 数据科学基本介绍
1.1数据的崛起
1.2什么是数据科学
1.3激励假设:DataSciencester
1.3.1寻找关键联系人
1.3.2你可能知道的数据科学家
1.3.3工资和工作年限
1.3.4付费账户
1.3.5感兴趣的主题
1.3.6展望
1.1 数据的崛起
生活中,数据无处不在。网站会记录每个用户的每次点击。智能手机会记录你每时每刻的位置和速度。“量化自我的人”戴着智能计步器记录自己的心率、运动习惯、饮食习惯和睡眠模式。智能汽车记录驾驶习惯,智能家居记录生活习惯,智能购物设备记录购买习惯。互联网本就是一幅巨大的知识图谱,其中包括(除此之外)有无数交叉引用的百科全书,如电影、音乐、体育赛事、弹球机、表情包、鸡尾酒等特定领域的数据库,以及很多政府部门发布的不计其数的统计数据(其中一些还挺真实的) 充斥在你的头脑中。
在这些数据中隐藏着无数问题的答案,有些问题甚至无人提及。我们将在本书中学习如何找到这些答案。
1.2 什么是数据科学
有一个笑话说,数据科学家是计算机科学家中的统计学家,也是统计学家中的计算机科学家。(哈哈,好像并不好笑。)事实上,一些数据科学家从实际的角度看就是统计学家,而其他数据科学家则与软件工程师没什么区别。有些数据科学家是机器学习专家,有些数据科学家则在机器学习方面知之甚少。有些数据科学家是博士,出版过令人印象深刻的学术作品,而有些数据科学家却从未阅读过学术论文(这有点尴尬)。所以说,无论如何定义数据科学,你都会发现有些数据科学从业者与那些定义完全不相称。
尽管如此,这并不能阻止我们尝试定义数据科学家。我们会说数据科学家是从凌乱的数据中提取有用信息的人。今天,世界各地有无数人在此领域耕耘。
例如,交友网站 OkCupid 要求其会员回答成百上千个问题,以便为他们找到最合适的交友对象。但它也会分析这些听起来无害的问题,比如你可以从某人回答的问题中得出他/她有多可能在第一次约会时和你上床。
Facebook 要求你填写家乡位置和居住位置的信息,表面上是为了让你的朋友更容易找到你并与你联系,但它也会分析这些位置,以研究全球移民模式以及各个橄榄球队的粉丝群的分布情况。
大型零售商 Target 会跟踪你线上和线下的购买习惯和互动习惯。它使用这些数据预测哪些顾客怀孕了,以便更好地向她们推销母婴商品。
2012年,奥巴马的竞选团队雇用了数十名数据科学家,他们通过数据挖掘和实验的方式来识别需要额外关注的选民,选择最佳的针对特定捐助者的筹款呼吁和方案,并将投票努力集中在最有可能有用的地方。在2016年,特朗普的竞选活动测试了令人震惊的各种在线广告,并分析了这些数据,以找出哪些是有效的,哪些是无效的。
现在,如果你开始觉得上面的例子枯燥,那么让我们看一些更有意义的善举:一些数据科学家偶尔会利用他们的技能提高政府的工作效率,帮助无家可归者,并改善公共健康等。当然,如果你能想出提高广告点击率的好方法,这同样会对你的职业生涯有帮助。
1.3 激励假设:DataSciencester
恭喜!你刚刚被聘请来领导 DataSciencester 的数据科学工作。DataSciencester 是数据科学家的社交网络。
虽然是为数据科学家服务,但 DataSciencester 从未真正实践数据科学工作。(公正地说,DataSciencester 从未真正构建自己的产品。)这是你的工作!在本书中,我们将通过解决在工作中遇到的实际问题来学习数据科学的概念。我们有时会研究用户直接提供的数据,有时会研究用户与网站交互生成的数据,有时甚至会研究我们自己设计的实验所产生的数据。
由于 DataSciencester 具有强大的原创精神,因此我们将从头开始构建自己的工具。完成这些工作后,你会对数据科学的基础知识有一个非常深刻的理解。你能将这项技能应用于更有前景的公司,或者着手解决任何有趣的问题。
欢迎加入 DataSciencester,祝你好运!(星期五可以穿牛仔裤上班,卫生间在大厅的右边。)
1.3.1 寻找关键联系人
这是你在DataSciencester工作的第一天,网络部副总有一堆关于用户的问题没有解决。以前他都没有能讨教的人,现在你来了,他很高兴。
具体来说,他希望你确定谁是数据科学家中的“关键联系人”。为此,他为你提供了整个DataSciencester用户网络的数据。(在实际工作中,人们通常不会向你提供所需的数据。第9章专门讨论了获取数据的方法。)
这是些什么样的数据呢?它是一个用户信息列表,每一行都由包含用户ID(即id,一串数字)和用户名称(即name)的字典(dict)组成:
users = [{ "id": 0, "name": "Hero" },{ "id": 1, "name": "Dunn" },{ "id": 2, "name": "Sue" },{ "id": 3, "name": "Chi" },{ "id": 4, "name": "Thor" },{ "id": 5, "name": "Clive" },{ "id": 6, "name": "Hicks" },{ "id": 7, "name": "Devin" },{ "id": 8, "name": "Kate" },{ "id": 9, "name": "Klein" }]
他还为你提供了“朋友关系”的数据,这是由一对对 ID 组成的列表:

例如,元组 (0, 1) 表示 id 为 0 的数据科学家 Hero 和 id 为 1 的数据科学家 Dunn 是朋友。用户关系网络见图 1-1。
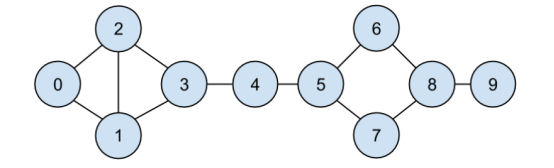
将朋友关系表示为元组(pairs)的列表并不是最简单的表示方法。如果要找到用户1的所有朋友,你必须迭代每个元组对以寻找哪个包含1。如果你有很多元组对,则会需要很长时间。
相反,让我们创建一个dict,其中键(key)是用户id,对应的值(value)是朋友id的列表。(dict的查询效率非常高。)
我们仍需要查看每一对元组来创建 dict,但只需执行一次,之后我们将可以方便地查找:

现在 dict 中有了朋友关系的列表,我们可以轻松地根据图中内容来提问,例如:“每个用户平均拥有多少个朋友?”
首先通过对所有用户的朋友列表长度求和,来找到连接总数:


然后将其除以用户数:

这样,如果我们找到拥有最多朋友的用户,就找到了拥有最多联系人的用户。
由于用户不多,因此我们也能很容易地按照用户朋友数量从多到少将他们排序:

我们刚刚所做事情的一种解读是,识别人际关系网络中心节点的一种方法。事实上,我们刚刚计算的是度中心性(degree centrality),这是一种网络度量(见图 1-2)。
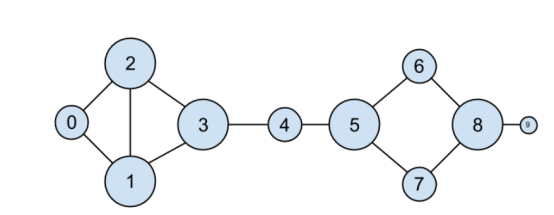
度中心性很容易计算,但它并不总能给出理想或期望的结果。例如,在 DataSciencester 网络中,Thor(id 为 4)只有 2 个朋友,而 Dunn(id 为 1)有3个。然而,在网络关系图上,直觉上认为Thor应该更具中心性。在第22章中,我们将更详细地研究网络,并探讨更复杂的中心性概念,这些概念可能与我们的直觉一致,也可能不一致。
1.3.2 你可能知道的数据科学家
当你正在填写新员工入职表时,人力部副总走到你桌旁。他希望鼓励会员之间建立更多联系,因此要求你设计一个“你可能知道的数据科学家”的提示函数。
你的第一直觉是用户可能知道他们朋友的朋友。因此你写了一些代码,依次迭代计算每个用户的朋友信息,并收集其朋友的朋友的信息:

当我们对 user[0](Hero)调用这个函数时,它的结果如下所示:

这个列表中用户 0 出现了两次,因为 Hero 确实是他的两个朋友的朋友。虽然用户 1 和用户 2 已经是 Hero 的朋友,但这个列表中还是包括了用户 1 和用户 2。因为 Chi 可通过两个不同的朋友联系到,所以 3 也出现了两次:

有趣的是,人们能通过多种方式成为朋友的朋友。受此启发,或许我们可以换一种数(count)共同朋友的方式来试着解决这个问题。我们应该排除已成为朋友的用户:

这个结果正确地说明 Chi(id 为 3)与 Hero(id 为 0)有两个共同的朋友,但与 Clive(id 为 5)只有一个共同的朋友。
作为一名数据科学家,你知道你可能也喜欢结交拥有共同兴趣的用户。(这是展示数据科学的“专业技能”的一个很好的例子。)在问了一圈人之后,你开始处理数据,设计出如下列表,其中每个元素都是成对的数据 (user_id, interest):

例如,Hero(id 为 0)与 Klein(id 为 9)没有任何共同的朋友,但他们对 Java 和大数据都感兴趣。
构建一个函数来查找具有特定兴趣的用户很容易:

这非常有效,但上面的算法每次搜索都需要遍历整个兴趣列表。如果用户很多或用户的兴趣很多(或者我们只是想多进行一些搜索),则最好建立一个从兴趣到用户的索引:
另一个从用户到兴趣的索引:

现在很容易找到与给定用户拥有最多共同兴趣的用户。
1.迭代用户的兴趣。
2.对于每个兴趣,迭代寻找具有该兴趣的其他用户。
3.记录每个用户在每次迭代中出现的次数。
代码如下所示:
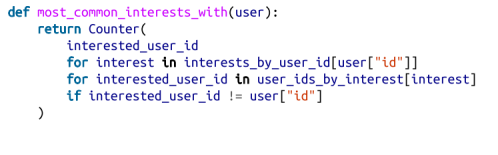
然后,结合共同的朋友和共同的兴趣,我们可以建立一个更全面的“你可能知道的数据科学家”的特征。第23章将继续探讨这类应用。
1.3.3 工资和工作年限
你准备去吃午饭时,公共关系部副总问你,是否可以提供一些有关数据科学家收入的有趣信息。工资数据相当敏感,因此他设法为你提供了一个匿名数据集,其中包含每个用户的工资(salary,以美元为单位)和作为数据科学家的工作年限(tenure,以年为单位):

第一步自然是绘制数据的散点图(第 3 章将介绍如何实现),你可以在图 1-3 中看到结果。
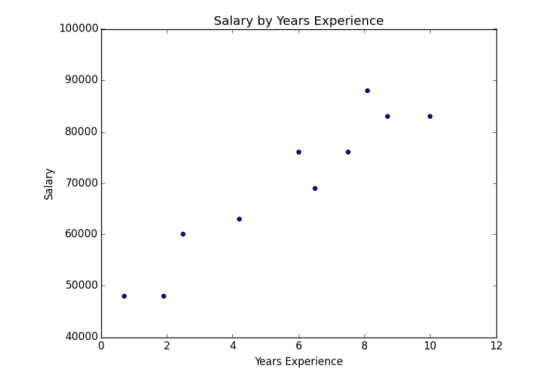
显然,经验丰富的人往往收入更高。怎么才能把这变成一个有趣的事实呢?第一个想法是查看每个任期的平均工资:

事实证明这并不是特别有说服力,因为任意两个用户的工作年限都不同,这意味着我们只是报告了用户的个人工资状况:

可能把工作年限分组以后会更有意义:

然后可以将每个组对应的工资合并在一起:
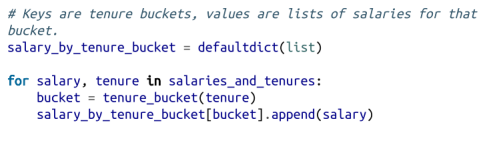
最后计算每组的平均工资:


这个结果看起来更有趣:

现在你可以说:“拥有 5 年以上工作经验的数据科学家比新人收入高 65% !”
但是,我们是以非常随意的方式分组的。我们原本希望说明的是多一年工作经验对平均工资的影响。除了发现一个更有趣的现象外,这使我们能够对不知道的工资做出预测。第 14 章将探讨这个想法。
1.3.4 付费账户
当你回到办公桌前,收益部副总正在等你。他希望更好地了解哪些用户会为账户付款,哪些用户不会。(他知道用户的名字,但这不是特别有用。)
你注意到多年经验与付费账户之间似乎存在某种对应关系:
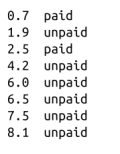
工作经验很少和工作经验丰富的用户倾向于付费,而有一些工作经验的用户则不会。因此,如果你想创建一个模型——即使这些数据不足以建立模型——你可能会尝试将工作经验很少和工作经验丰富的用户预测为“付费”,而将有一些经验的用户预测为“不付费”:

当然,我们会持续关注这个人工经验模型。
随着更多数据(和更多数学知识)的引入,我们可以建立一个模型,根据用户的工作年限预测他付费的可能性。第16章将研究这类问题。
1.3.5 感兴趣的主题
当你正准备结束第一天的工作时,内容策略部副总来向你要数据,他想了解用户最感兴趣的主题,以便可以相应地规划他的博客日历。你已拥有来自朋友推荐项目的原始数据:


找到最受欢迎的兴趣的一种简单(并不是特别令人兴奋)的方法是计算兴趣词汇的个数:
1.小写每个兴趣(因为不同的用户可能不会小写他们的兴趣);
2.将其分成单词;
3.数结果。
代码如下所示:

这样可以轻松列出多次出现的单词:

它给出了你期望的结果(除非你期望“scikit-learn”被分成两个单词,那样就不会得到预期的结果了):

第21章将介绍从数据中提取主题的更复杂的方法。
1.3.6 展望
第一天非常成功!你一定很累,赶紧在有人继续问问题之前回家吧。晚上好好休息,明天要参加新员工入职培训。(是的,在入职培训前,你已工作了一整天。明天去人力资源部报到吧。)
相关阅读: