
天猫面试真题:如何进行数据库设计?
这是一道天猫面试真题,90%以上的求职者都回答不到点上去~
前言
我们知道,软件工程是为了解决软件危机的,它是采用工程的概念、原理、 技术和方法来开发与维护软件,把经过时间考验而证明正确的管理技术和当前能够得到的最好的技术方法结合起来。
在软件开发的过程中,数据库设计是非常重要的,它需要根据需求分析设抽象出 E-R 图,逻辑结构设计,数据库选型,物理设计,实施及运维。下面就聊聊那些年数据库设计的那些事。
数据库设计基本步骤
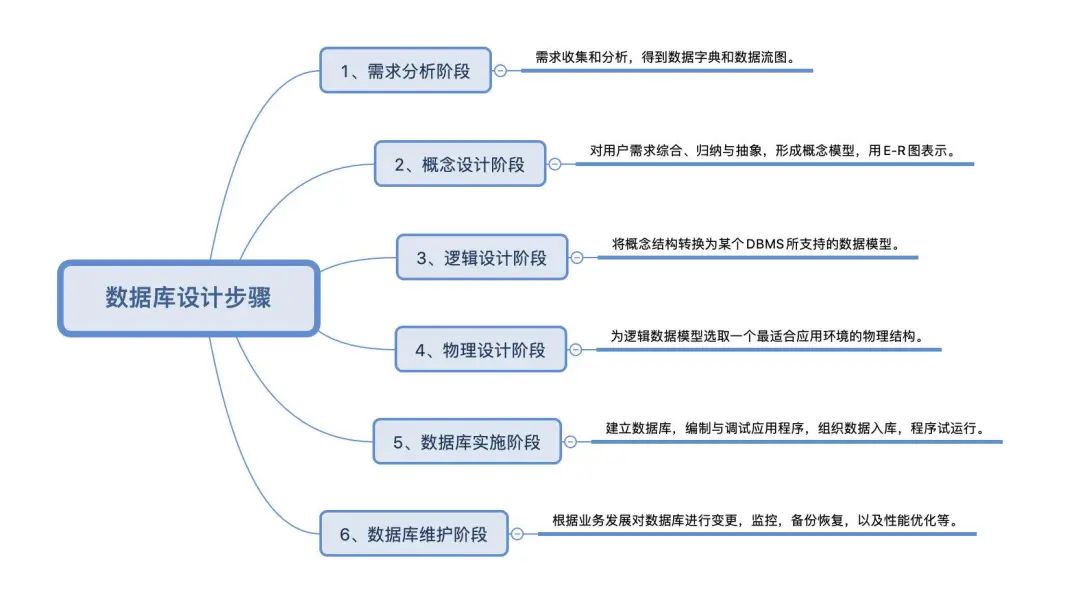
需求分析阶段
要进行数据库设计首先要了解用户需求,参与到用户需求分析中去,需求分析常用 SA(Structured Analysis:结构化分析方法)强调开发方法的结构合理性以及所开发软件的结构合理性的软件开发方法,是生命周期法的继承与发展,是生命周期法与结构化程序设计思想的结合。
其基本思想是用系统工程的思想和工程化得方法,根据用户至上的原则,自始自终按照结构化、模块化,自顶向下地对系统进行分析与设计。建立的主要步骤如下:
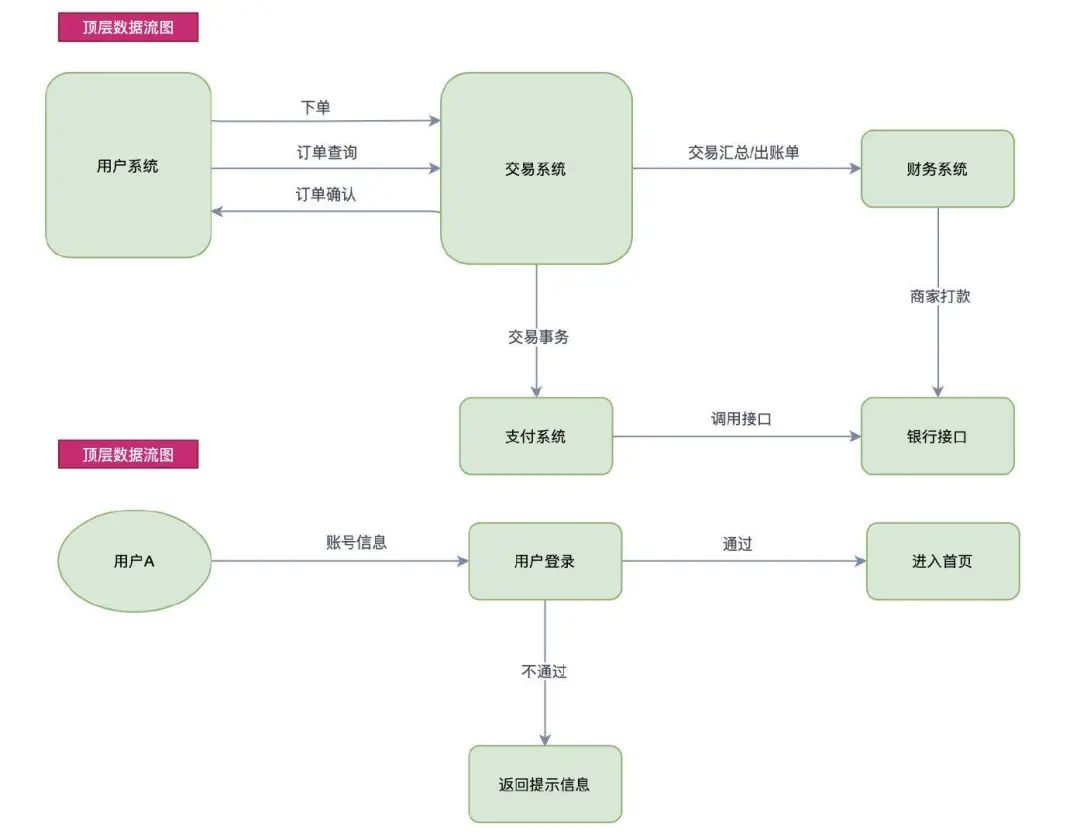
首先画系统的输入输出,先画顶层数据流程图(DFD:Data Flow Diagram),顶层数据流程图只包含一个加工,用以表示被开发的系统,然后考虑该系统有哪些输入、输出数据流。 画系统内部,即画下层数据流层图。
下面是一个交易系统的 DFD,需要先画出顶层数据流图,主要包括系统子模块之间的交互,然后再进一步对子模块进行分解。
概念设计阶段
概念设计是整个数据库设计的关键,它是对需求分析阶段的成果进行综合,归档以及抽象出一个独立具体的 DBMS 模型,与具体的 RDBMS 产品无关。
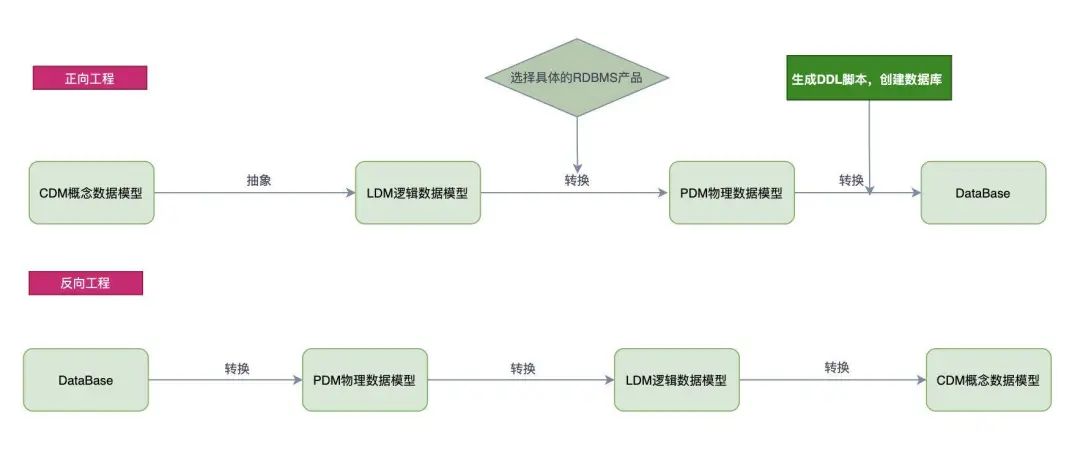
在实际的开发中,常用 E-R(Entity-Relationship:实体关系)图来表示,常用的工具 PowerDesigner,可以实现 CDM(概念数据模型)->LDM(逻辑数据模型)->PDM(物理数据模型)->Database 的自动转换,这个过程称为正向工程,如果有 database 建库脚本,也可以通过 PowerDesigner 工具生成 CDM,即 Database->PDM->LDM->CDM,称为反向工程。
 概念设计通常采用自底向上,首先定义各系统局部的概念模型,然后再将他们集成合并起来,得到全局的概念模型。
概念设计通常采用自底向上,首先定义各系统局部的概念模型,然后再将他们集成合并起来,得到全局的概念模型。
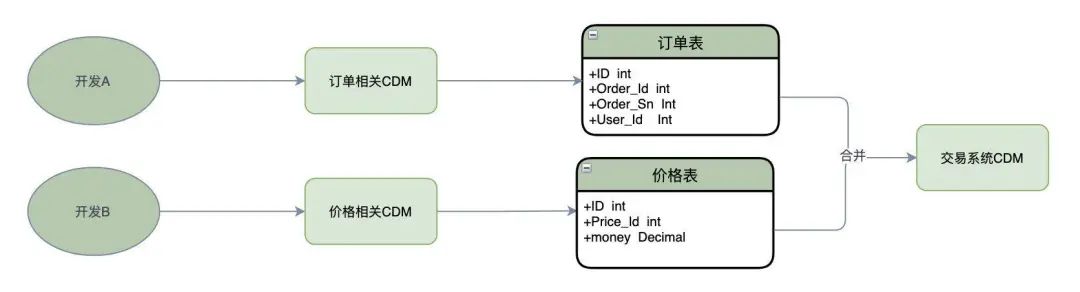
举个例子说明下,现在负责交易系统的开发,主要涉及订单,价格模块,分别交给不同的开发去设计开发。
首先每个人要根据需求分析抽象出自己的实体 Entity 及之间的关系 Relationship,设计初步完成之后就要开会讨论了,把每个开发的 ER 图合并起来,就得到全局交易系统的 CDM。
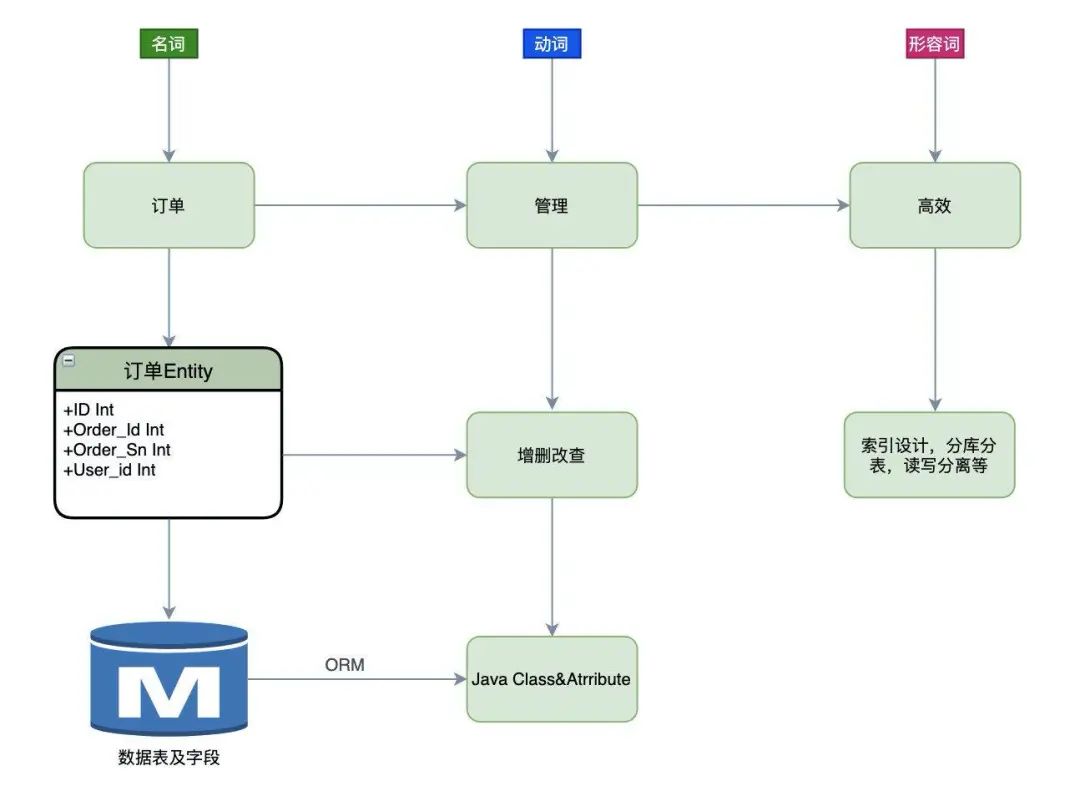
名词动词形容词分析法
开发如何根据需求分析设计 ER 图,完成模块的详细设计,提供接口文档,最重要的是需求分析抽象 CDM 阶段的 ER 图,一种行之有效的方法就是名称动词形容词分析法,下面就详细解释下这种分析方法。
还是举例说明吧,现在让我负责交易系统的订单这块的开发,在需求分析文档里看到一句话实现订单的高效管理,分析的过程如下:
名称:订单,订单就是一个 Entity,也可以拆分成多个 Entity,抽象出每个 Entity 的 Attribute(前期可能由于需求不明确,可以只做确认的内容),Entity 通过 PowerDesigner 的正向工程转换成数据库里的数据表,Attribute 就是表的字段;数据表通过 ORM 映射到 Java 里的就是 Class,字段就是 private 属性。
动词:管理,也就是要对订单要进行增删改查 CRUD 操作。
形容词:高效,首先想到在订单表上创建合适的索引吧,其次根据业务的发展,订单表太大会影响写入性能,是否要进行读写分离,分库分表操作。
数据库设计三范式
第一范式 1NF:确保每个字段保持原子性,不可分割。
对于用户表 users 来说,有用户姓名(一般由 first_name 和 last_name 组成),如果使用类似 Oracle 的复合数据类型,就违反了 1NF。
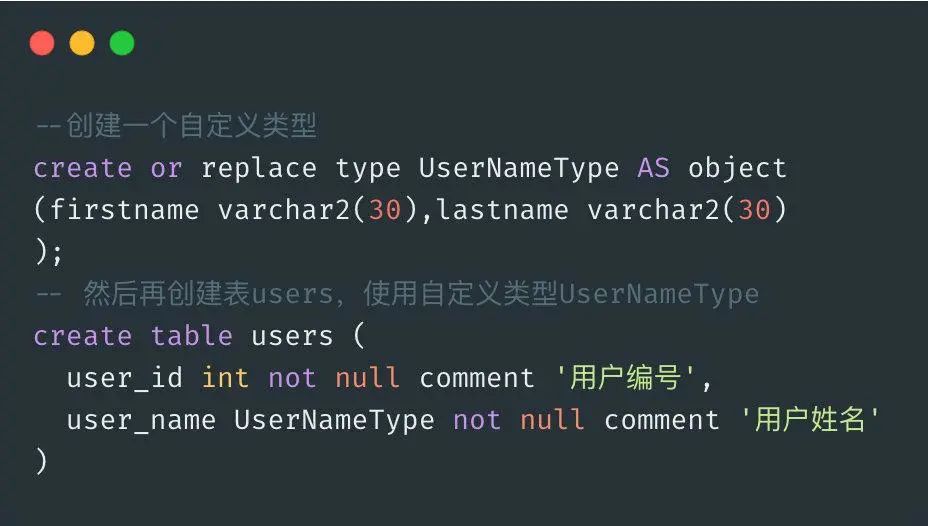
很明显 users 的字段 user_name 是一个自定类型,是可分解的,这就违反了 1NF。
第二范式 2NF:确保字段完全依赖于主键。
一个表中只能保存一种数据,不可以把多种数据保存在一张表里,假如一张表既存储了用户信息,又存储商品信息,还存储了订单信息,这样就违反了 2NF,而应该将用户表,商品表,订单表拆分成三张表,确保字段是该表拥有的。
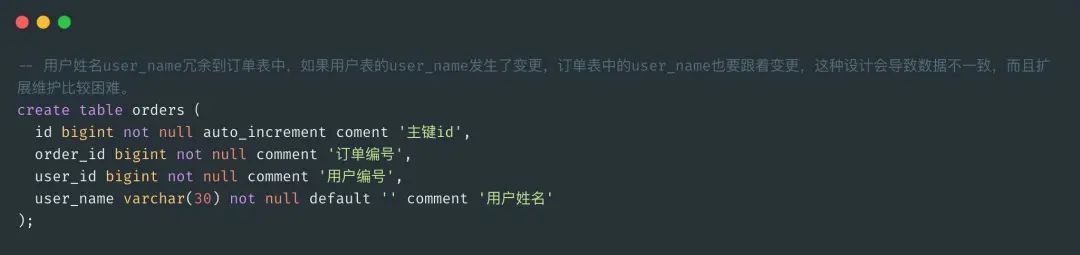
第三范式 3NF:必须满足 2NF,实体中每个属性与主键直接相关而不能间接相关。
这个也不难理解,对于订单表 orders 来讲,是要存储用户表 users 的 user_id,要明确哪个用户下的单,有些业务场景是要获取 users 表的用户姓名 user_name,为了减少 orders 和 users 表的关联查询,将 user_name 冗余到 orders 表中,这种设计就违反了 3NF,减少数据冗余,可以通过主外键进行表之间连接。
到底该不该使用外键 Foreign Key
外键目的是为了保证数据完整性和一致性,避免产生脏数据,设置外键有啥缺点呢。
影响写入性能:对于 insert 来说,每次都要判断从表的外键列是否在主表中存在(例如每次插入 orders 表,都要判断下 user_id 是否在 users 中存在),会降低数据库的写入性能,对于 MySQL 本来就只有 Master 输出写能力的数据库,就不太合适了,MySQL 开发规范规定不允许使用外键也是有一定道理的。 并发问题:在使用外键的情况下,每次修改数据都需要去另外一个表检查数据,需要获取额外的锁。在高并发大场景,使用外键造成死锁或锁等几率更大。
实际开发中,更多的是不靠外键来保证数据的完整性和一致性,而是通过的业务逻辑,比如用户要下单,必须先登录系统,下单只需要将登录的用户编号写入到订单表,这个用户必然是存在于用户表的,对于一个用户友好的系统来说,尽量让用户选择,不要人工输入,这样可以保证数据一致性,避免脏数据的产生。
逻辑设计阶段
逻辑设计阶段是将概念数据模型转换为具体的 DBMS 所支持的数据模型,并将进行优化。虽然 LDM 独立于 DBMS 的,但可以进行外键,索引,视图等对象的设计工作。
在此阶段,各子模块的 E-R 图之间的冲突主要有三类:属性冲突,命名冲突和结构冲突,同时 E-R 图向关系模型的转换,要解决如何将实体性和实体间的联系转换为关系模式,确定这些关系模式的属性和码,实际开发中,逻辑设计阶段不是必须的,有些是从 CDM 直接到 PDM 了。

数据库选型
数据库选型是非常重要的环节,一般在需求分析完成之后,通过架构评审会进行确认,数据库方面主要包括数据存储,检索,安全,读写分离,分库分表,数据归档,接入数据仓库都要进行确认,根据业务的场景对相关的数据库产品进行调研比对,选择最适合业务场景的数据库作为存储。
举个例子:对于一个 DAU 1000W TPS 3W 的交易的业务场景,如果使用 MySQL 来存储,我们知道原生的 MySQL 写入瓶颈,以及订单相关表数据量增长过快导致的性能问题,不太适合这种高并发写的场景,可以考虑使用分布式 MySQL,例如常见的 DRDS,TiDB,OceanBase。既可以解决原生 MySQL 写入瓶颈,同时也可以处理单表数据量大导致的分库分表问题。
同样对于优酷,爱奇艺这种视频类系统,使用 MySQL 来存储就不太合适了,应该采用 MongoDB 集群来存储;对于京东,淘宝的这种搜索服务采用 ElastSearch 数据库集群处理会更高效。
物理设计阶段
逻辑设计阶段和数据库选型完成之后,就可以通过 LDM 生成 PDM 了,在物理设计阶段,需要设计跟 RDBMS 相关的对象,例如设计存储过程,触发器,用户自定义函数,表空间等。

数据库实施阶段

例如选择的是 MySQL 数据库,通过 PDM 生成数据库的建库脚本之后,需要进行规范性检查,通过之后就可以创建表结构,规范性检查可以借助开源的 SQL 审核工具,如 Yearning,Archery 都可以设置规则,检查之后会给出整改建议,能够帮我们自动实现 SQL Review。Yearning 是用 go 开发,目前只支持 MySQL 数据库,Archery 可以支持多种数据库。下面是 Yearning 自动化 SQL 审核平台的一个 DDL 工单的检测示例。
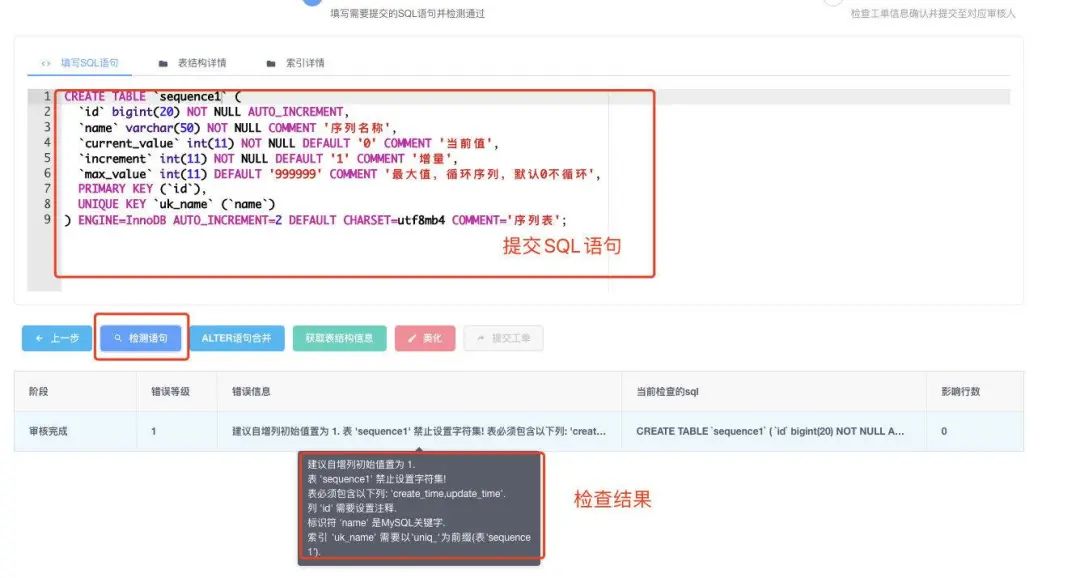
检测通过后就可以提交工单了,审核通过后就会自动执行 DDL 脚本建库。
数据库维护阶段
数据库维护阶段主要包括业务支撑和数据库运维,简单总结了下,如下图所示。
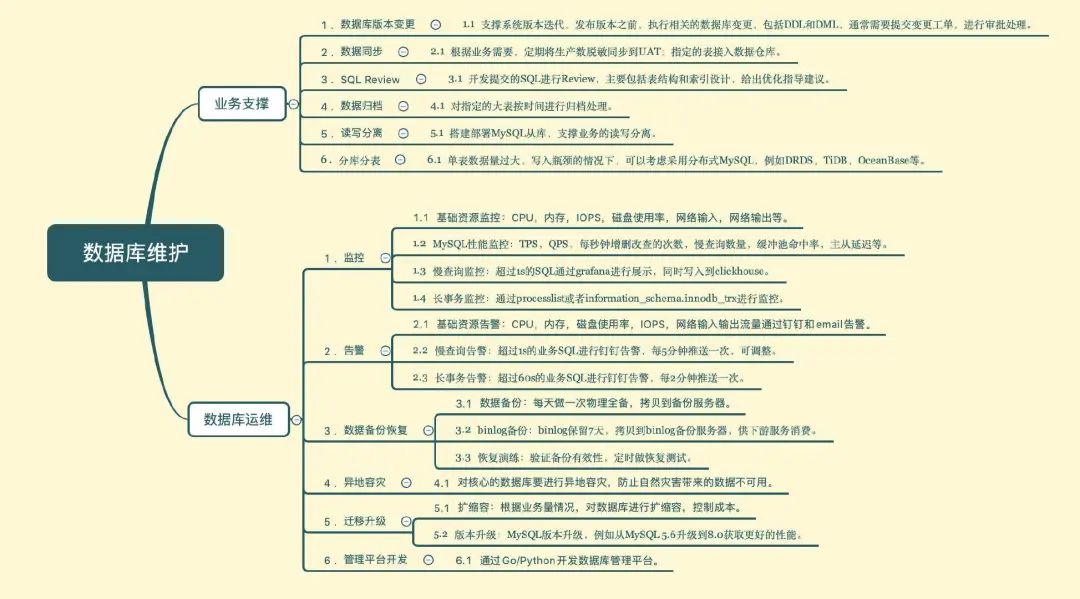
总结
实际开发中,数据库设计阶段是非常重要,通常都是开发自己根据业务模块的需求去分析,抽取成 CDM 中的 E-R 图,转换成 LDM,经过数据库选型及生成 PDM,最终生成数据库表,然后才能开始 coding,测试、发布上线以及版本迭代,为了保证线上业务的安全稳定高效,就需要对数据库进行精细化管理和维护。
仔细观察不难发现,数据库设计的核心就是对需求分析的理解以及抽取沉底出 E-R 图,这就需要对行业及相关业务有深刻立即及抽象能力,大家有木有发现,招聘 Java 工程师的前面附加了业务属性,例如用户域 Java 工程师,支付域 Java 工程师,主要体现在需求分析抽象以及数据模型设计能力上,开发过程中多参与业务需求讨论是非常有必要的。今天就聊这么多,希望对大家有所帮助。
推荐?: Github掘金计划:Github上的一些优质项目搜罗
推荐?: Github 2020 年度报告,值得一看 -「编程杂感」第 5 期
我是Guide哥,Java后端开发,拥抱开源,喜欢烹饪,自由的少年。一个三观比主角还正的技术人。我们下期再见!