
PyTorch vs LibTorch:网络推理速度谁更快?
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


极市导读
最近,在MLab团队内部,我们发现一个TorchScript模型在LibTorch中的推理速度变得很慢,于是本文从九个方面将PyTorch与LibTorch进行了对比,探究这个问题的原因。
背景
在Gemfield:部署PyTorch模型到终端(https://zhuanlan.zhihu.com/p/54665674)一文中,我们知道在实际部署PyTorch训练的模型时,一般都是要把模型转换到对应的推理框架上。其中最常见的就是使用TorchScript,如此以来模型就可在LibTorch C++生态中使用了,从而彻底卸掉了Python环境的负担和掣肘。
最近,在MLab团队内部,我们发现一个TorchScript模型在LibTorch中的推理速度变得很慢:推理时间大约是PyTorch的1.8倍左右。这就让Gemfield很尴尬了,C++程序居然比python程序还要慢(虽然python程序的大部分也是在C++中运行)。因为我们都拥有一个共识:没有特殊优化的情况下,C++程序一定不会比Python慢!特别是对于LibTorch来说,因为省却了用户API层面的内存布局转换(从普通C++类型的内存布局到python object的内存布局的转换),因此LibTorch比PyTorch速度快2%到10%才是预期中的事情。
尴尬还是次要的,性能测试过不了关,后续很多工作都不能进行。Gemfield来调查这个问题的思路如下:
PyTorch vs LibTorch的时候,性能测试报告中的时间数据可靠吗? PyTorch vs LibTorch的时候,这两者基于的代码版本一样吗? PyTorch vs LibTorch的时候,硬件、Nvidia驱动、软件栈一样吗? PyTorch vs LibTorch的时候,推理进程对系统资源的占用情况一样吗? PyTorch vs LibTorch的时候,网络对于不同的input size有什么不一样的推理速度吗? PyTorch vs LibTorch的时候,有什么profiler工具吗? PyTorch vs LibTorch的时候,有什么特别的环境变量设置的不一样吗? PyTorch vs LibTorch的时候,程序所链接的共享库一样吗? PyTorch vs LibTorch的时候,这两者所使用的编译选项一样吗? 在解决类似的LibTorch性能问题时,我们能为大家提供什么便利呢?
1. PyTorch vs LibTorch:时间数据
一个初入CUDA生态的人,最容易犯的错误之一就是测试cuda代码的执行时间:
start_time = time.time()outputs = civilnet(img)print('gemfield model_time: ',time.time()-start_time)
上述代码是错误的。因为cuda的异步执行特点,如果要测量完整的cuda运算时间,我们需要加上torch.cuda.synchronize() 同步API,如下所示:
torch.cuda.synchronize()start_time = time.time()outputs = civilnet(img)torch.cuda.synchronize()print('gemfield model_time: ',time.time()-start_time)
在C++代码中同理:
...start = std::chrono::system_clock::now();output = civilnet->forward(inputs).toTensor();at::cuda::CUDAStream stream = at::cuda::getCurrentCUDAStream();AT_CUDA_CHECK(cudaStreamSynchronize(stream));forward_duration = std::chrono::system_clock::now() - start;msg = gemfield_org::format(" time: %f", forward_duration.count() );std::cout<<"civilnet->forward(inputs).toTensor() "<<msg<<std::endl;
这样以来,程序输出的时间就可以反应真实的网络运算时间。如果嫌上述代码有点复杂的话,可以设置一个环境变量来近似等价:CUDA_LAUNCH_BLOCKING :
export CUDA_LAUNCH_BLOCKING = 1
设置了这个环境变量后,程序中的CUDA代码就是同步执行的。你就不需要再添加上述cuda同步API了。经过这一步检查,确认性能报告中的数据是准确的。
2. PyTorch vs LibTorch:代码版本
在DeepVAC生态下,DeepVAC封装PyTorch,Libdeepvac封装LibTorch,且基于PyTorch仓库的同一个版本:1.8.1。经过这一步检查,确认版本没有问题。
3. PyTorch vs LibTorch:硬件、Nvidia驱动、软件栈
多亏了MLab HomePod这一迄今为止最先进的容器化PyTorch训练环境,我们有了一致的软件栈,具体来说就是:
宿主机OS:Ubuntu 20.04 软件环境:MLab HomePod 1.0 CPU:Intel(R) Core(TM) i9-9820X CPU @ 3.30GHz GPU:NVIDIA GTX 2080ti GPU驱动:NVIDIA-SMI 450.102.04 Driver Version: 450.102.04 CUDA Version: 11.0
经过这一步检查,软硬件栈也是一致的。
4. PyTorch vs LibTorch:进程对系统资源的占用
Gemfield主要看的是AI推理进程对如下系统资源的使用:
CPU利用率 内存 GPU利用率 显存 该进程的线程数
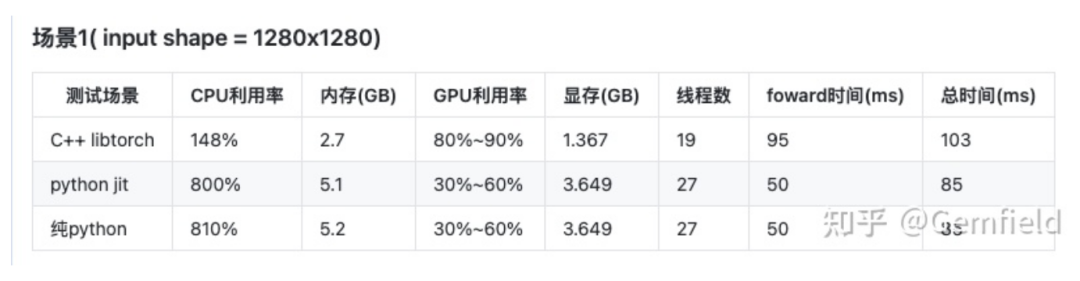
模型1
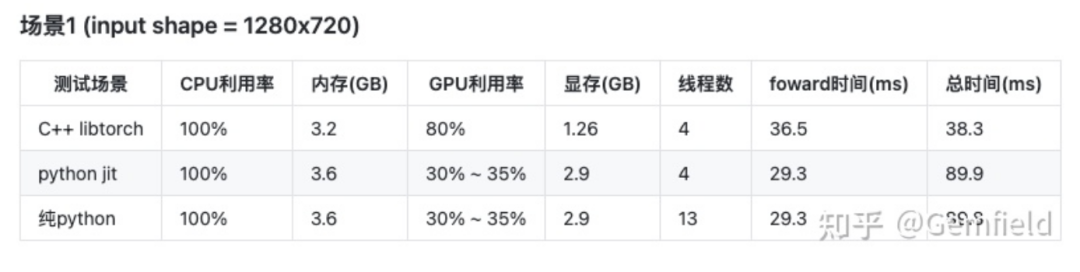
模型2
其中的python jit指的是使用python代码加载TorchScript模型:
civilnet = torch.jit.load("resnet50.pt")
嗯,对比之下,发现PyTorch 和LibTorch的资源使用情况明显不同。这里的现象总结如下:不知怎么的,相比LibTorch,PyTorch能使用更多的系统资源!
5. PyTorch vs LibTorch:网络的不同大小的输入
Gemfield使用224x224、640x640、1280x720、1280x1280作为输入尺寸,测试中观察到的现象总结如下:
在不同的尺寸上,Gemfield观察到LibTorch的速度比PyTorch都要慢; 输出尺寸越大,LibTorch比PyTorch要慢的越多。
6. PyTorch vs LibTorch:使用PyTorch profiler工具
PyTorch提供了内置的profiler工具,python和C++中都可以使用。
python代码如下:
with torch.profiler.profile(activities=[torch.profiler.ProfilerActivity.CPU,torch.profiler.ProfilerActivity.CUDA],# In this example with wait=1, warmup=1, active=2,# profiler will skip the first step/iteration,# start warming up on the second, record# the third and the forth iterations, by gemfield.schedule=torch.profiler.schedule(wait=1,warmup=1,active=2),on_trace_ready=torch.profiler.tensorboard_trace_handler('./gemfield')as p:for iter in range(N):your_code_here# send a signal to the profiler that the next iteration has startedp.step()
C++中如下:
//文件名很重要torch::autograd::profiler::RecordProfile guard("gemfield/gemfield.pt.trace.json");
写出的文件可以使用tensorboard打开:
gemfield@ThinkPad-X1C:~$ tensorboard --logdir gemfieldTensorFlow installation not found - running with reduced feature set.I0409 21:30:59.472155 140264193779264 plugin.py:85] Monitor runs beginI0409 21:30:59.472792 140264193779264 plugin.py:100] Find run gemfield under /home/gemfield/gemfieldI0409 21:30:59.477127 140264193779264 plugin.py:281] Load run gemfieldI0409 21:30:59.792165 140264193779264 plugin.py:285] Run gemfield loadedI0409 21:30:59.799130 140264185386560 plugin.py:117] Add run gemfieldServing TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_allTensorBoard 2.3.0 at http://localhost:6006/ (Press CTRL+C to quit)
从输出的log可以看到我们需要在浏览器打开地址:http://localhost:6006/,如下图所示:
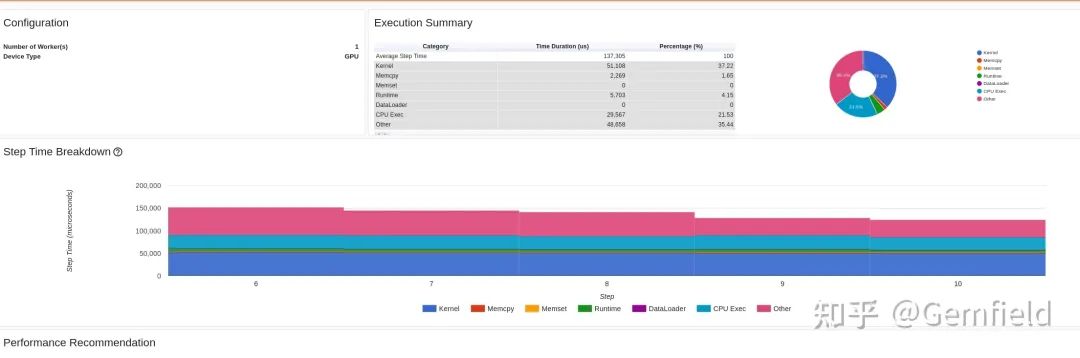
overview
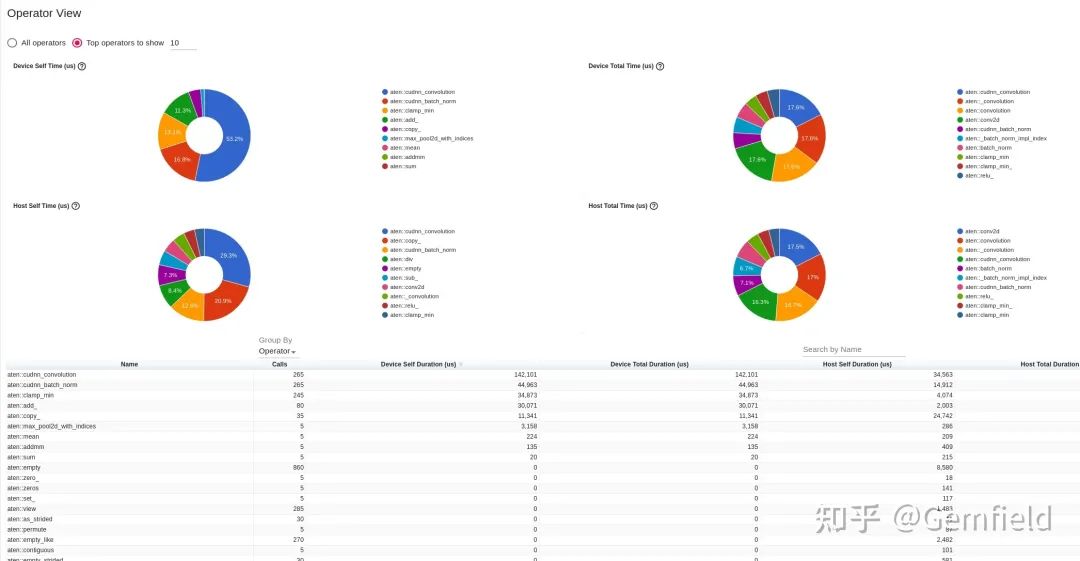
operator
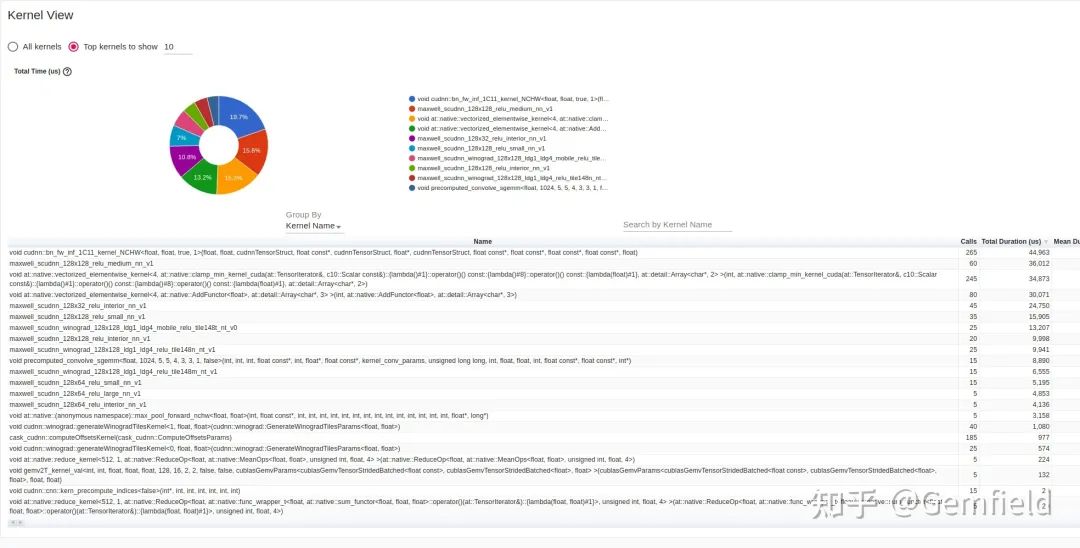
GPU kernel

trace
现象总结如下:没有看到明显瓶颈。整个推理下来,LibTorch是一种均匀的慢——在所有的网络算子上,LibTorch都比PyTorch更慢。
7. PyTorch vs LibTorch:特别的环境变量
线程数
在类似问题的github issue中,Gemfield先后看到有人提到了:
OMP_NUM_THREADS at::init_num_threads()
Gemfield尝试如下:
设置环境变量OMP_NUM_THREADS(会影响C++中的at::get_num_threads()):
#从4到16export OMP_NUM_THREADS = 8
另外,C++代码也设置不同的参数进行验证:
at::init_num_threads();//从4到16at::set_num_threads(16);//从4到16at::set_num_interop_threads(16);std::cout<<"civilnet thread num: "<<at::get_num_threads()<<" | "<<at::get_num_interop_threads()<<std::endl;
在Gemfield当前的版本中,这个线程数从4到16都不影响网络都推理速度。排除此项。
cudnn
torch.backends.cudnn.deterministic和torch.backends.cudnn.benchmark这两个参数是True还是False影响某些模型的性能:
cudnn.benchmark = False & cudnn.deterministic=True 的时候,会使用cudnn的默认算法实现; cudnn.benchmark = False/True & cudnn.deterministic=False 的时候,cudnn会选择自认为的最优算法。
用C++代码进行实验:
......std::cout<<"userEnabledCuDNN: "<<at::globalContext().userEnabledCuDNN()<<std::endl;std::cout<<"userEnabledMkldnn: "<<at::globalContext().userEnabledMkldnn()<<std::endl;std::cout<<"benchmarkCuDNN: "<<at::globalContext().benchmarkCuDNN()<<std::endl;std::cout<<"deterministicCuDNN: "<<at::globalContext().deterministicCuDNN()<<std::endl;at::globalContext().setUserEnabledCuDNN(true);at::globalContext().setUserEnabledMkldnn(true);at::globalContext().setBenchmarkCuDNN(true);at::globalContext().setDeterministicCuDNN(true);
发现在不同程度上修改了默认值后,性能反而会降低...。排除此项。
8. PyTorch vs LibTorch:程序链接的共享库
通过使用ldd命令,Gemfield观察到了PyTorch所链接的共享库和LibTorch所链接的共享库的区别:
intel mkl:pytorch为conda安装的动态库,LibTorch(libdeepvac版)为静态库:
Found a library with BLAS API (mkl). Full path: ($PREFIX/lib/libmkl_intel_lp64.so$PREFIX/lib/libmkl_gnu_thread.so;$PREFIX/lib/libmkl_core.so;-fopenmp;/usr/lib/x86_64-linux-gnu/libpthread.so;/usr/lib/x86_64-linux-gnu/libm.so;/usr/lib/x86_64-linux-gnu/libdl.so)
libcudnn:pytorch为libcudnn_static.a静态库,LibTorch(libdeepvac版)为动态库。
其它的库依赖都一模一样,Gemfield决定更换下试试。凭借着MLab HomePod和libdeepvac项目,我们可以通过cmake命令调整一下参数,就转而让C++代码去链接pytorch所使用的共享库:
cmake -DUSE_MKL=ON -DUSE_CUDA=ON -DCMAKE_BUILD_TYPE=Release -DCMAKE_PREFIX_PATH="/opt/public/airlock/opencv4deepvac;/opt/conda/lib/python3.8/site-packages/torch/" -DCMAKE_INSTALL_PREFIX=../install ..由于这样操作还引入了下面小节中的变量,所以这里就不总结了,我们继续......
9. PyTorch vs LibTorch:编译选项
Gemfield通过比对CI系统上这两者的编译日志,试图发现它俩是否在release mode、-O3等常见编译优化选项上有区别——结果发现完全相同。但是,山重水复疑无路,柳暗花明又一村。Gemfield发现了其它方面的区别,这些区别体现在以下方面:
是否使用KINETO; nvcc flag少了一个参数:-Xfatbin;-compress-all; CAFFE2_USE_MSVC_STATIC_RUNTIME: OFF/ON 是否使用了magma_v2; USE_OBSERVERS : ON/OFF USE_DISTRIBUTED : ON/OFF
这些不同的地方,有的一眼看过去就毫不相关,有些...却是答案所在。还是和上述步骤一样,凭借着MLab HomePod和libdeepvac项目,我们可以通过cmake命令调整一下参数,就转而让C++代码去链接pytorch所使用的共享库:
cmake -DUSE_MKL=ON -DUSE_CUDA=ON -DCMAKE_BUILD_TYPE=Release -DCMAKE_PREFIX_PATH="/opt/public/airlock/opencv4deepvac;/opt/conda/lib/python3.8/site-packages/torch/" -DCMAKE_INSTALL_PREFIX=../install ..如此以来,PyTorch代码和libtorch代码所使用的底层库都一模一样(包括其当初的编译选项),这样如果还出现性能差异的话,我只能把它归咎为libtorch c++ frontend层面的bug了。
那么经过上面的调试,我们带来了什么结果呢?这是性能测试报告:
性能测试报告
https://github.com/DeepVAC/libdeepvac/issues/30
在CUDA上, 对于ResNet50,在224x224的输入上,LibTorch碾压了PyTorch,而在其它三种输入上,LibTorch都略慢于PyTorch;而在另外一种模型上,LibTorch在小尺寸上同样碾压PyTorch,但在大尺寸输入上被PyTorch碾压...这也是到目前为止Gemfield最大的疑惑。
在CPU上, 对于ResNet50,不论输入的大小是多少,LibTorch都碾压了PyTorch。而且输入越小,碾压态势越明显。
考虑到CUDA和CPU设备上不同的表现以及指标,Gemfield猜测:在LibTorch的调用栈上,C++ frontend无意或有意的多设置了或者少设置了和CUDA显存相关的配置,这个设置限制了进程对CUDA显存的使用。
10. PyTorch vs LibTorch:我们可以为你做什么?
要跑出来benchmark相关的报告需要引入非常多的琐碎工作,而且经常会有所疏漏,甚至还有未知领域。有鉴于此,我们把这个benchmark测试代码封装为DeepVAC中的python模块和libdeepvac项目中的test_resnet_benchmark.cpp。为了方便LibTorch用户调试性能问题,我们引入了如下的步骤。依据此步骤,你可以最大限度的排除多余的变量,从而使得性能变化只取决你的硬件和驱动版本,从而加速问题调查。
PyTorch resnet50 benchmark步骤
部署MLab HomePod; HomePod上安装DeepVAC Python包:pip install deepvac; 下载预训练的ResNet50模型(比如:https://download.pytorch.org/models/resnet50-0676ba61.pth): HomePod上运行benchmark命令:
python -m deepvac.syszux_resnet benchmark <pretrained_model.pth> <your_img.jpg>上述命令默认会使用CUDA设备,如果CUDA找不到(本来就没有,或者设置相关环境变量),就会使用CPU;
为LibTorch生成TorchScript模型:
python -m deepvac.syszux_resnet test <pretrained_model.pth> <your_img_directory>默认会生成gemfield_script.pt文件。
LibTorch resnet50 benchmark步骤
部署MLab HomePod; HomePod上克隆libdeepvac项目:
git clone https://github.com/DeepVAC/libdeepvac
编译:https://github.com/DeepVAC/libdeepvac#benchmark HomePod上运行benchmark程序:
#CUDA./bin/test_resnet_benchmark cuda:0 <gemfield_script.pt> <your_img.jpg>#CPU./bin/test_resnet_benchmark cpu <gemfield_script.pt> <your_img.jpg>
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!