
300元Python私活,实现网易云课堂爬虫
今天是周六,起来的比较晚,突然收到帅帅老师的微信,大概意思是有一个单子,上次的这个单子,接单人说没时间做,退给他了,前几天这个单子其实我已经试着做了一下,也实现了功能,把结果也发给帅帅老师了,正好上次的接单人没有时间,真是一个意外的惊喜,瞬间睡意全无,开干。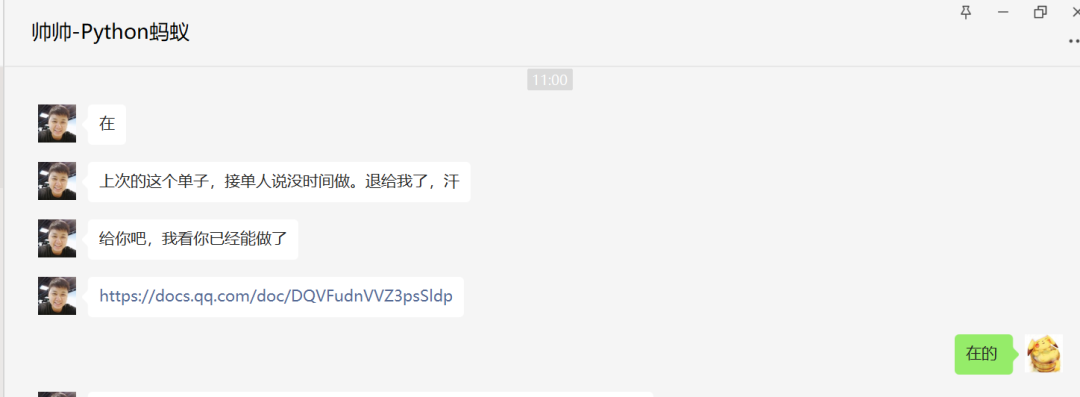
爬取目标
网易云课堂套餐的首页和单个课程信息
爬取过程
1、 打开套餐首页测试链接,这里需要记录套餐名字;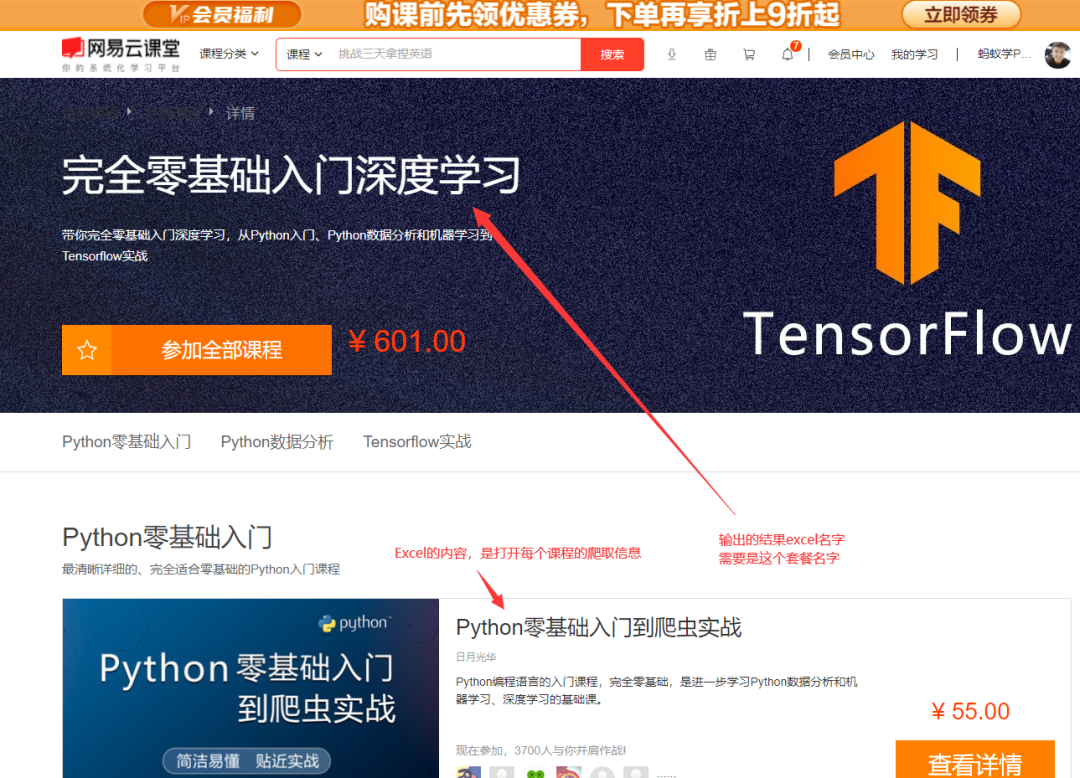 2、 得到里面的每个课程的URL
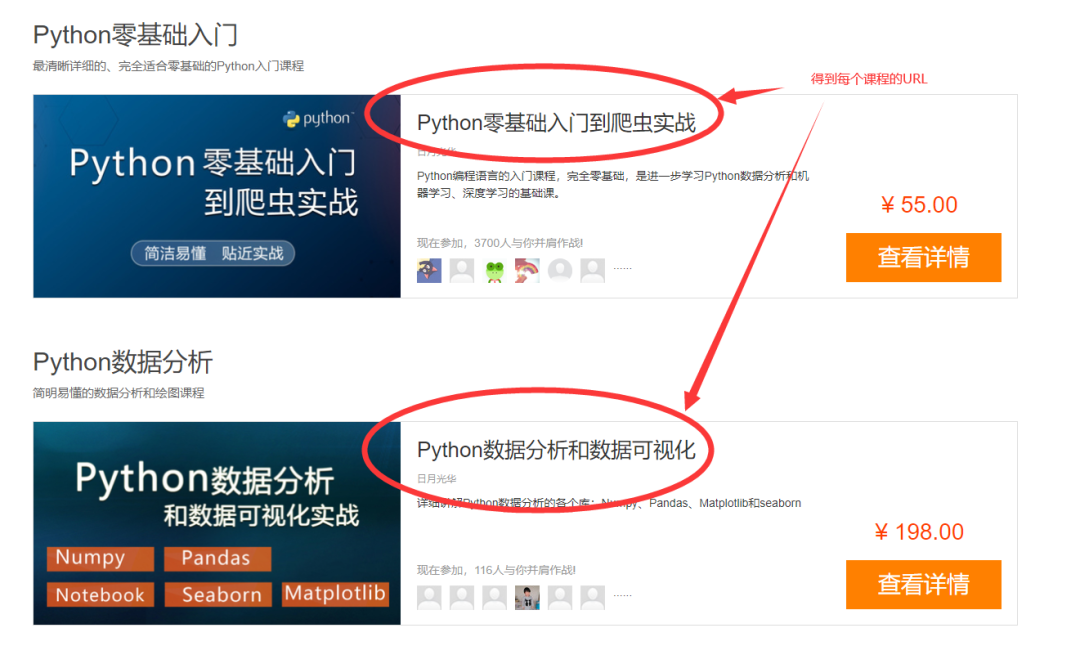
2、 得到里面的每个课程的URL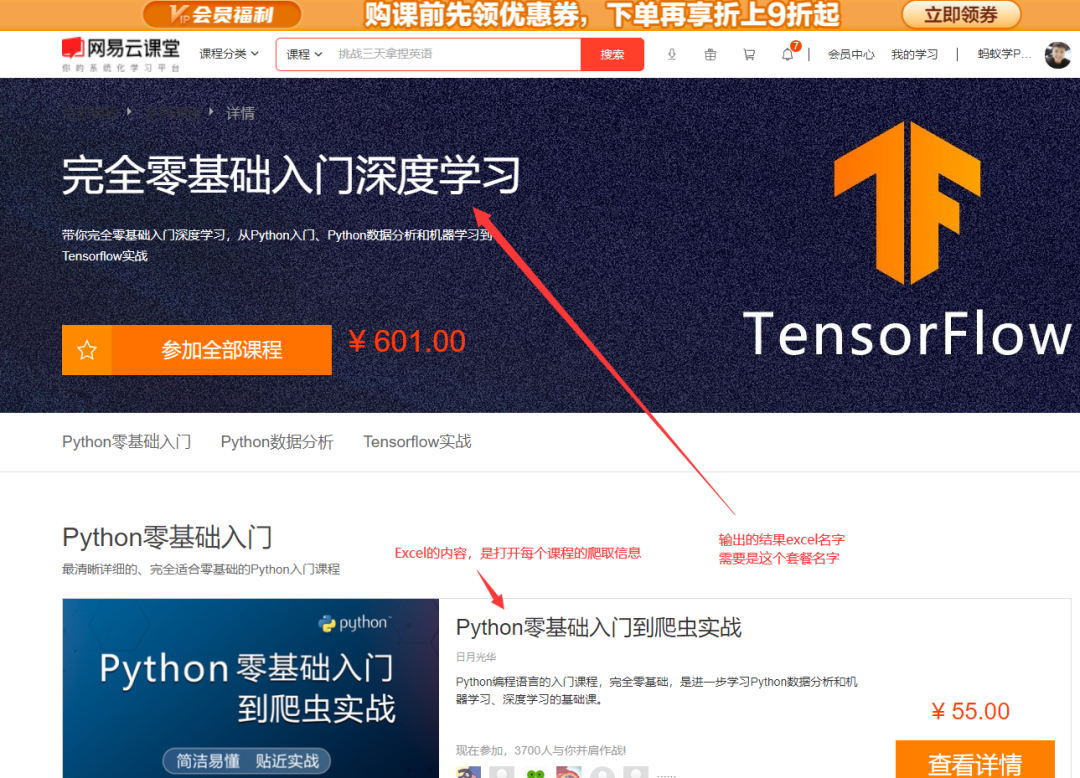
3、 访问每个课程的URL,得到如下信息:
4、 存入最终的Excel文件
文件名:套餐名字,例如 完全零基础入门深度学习.xlsx
代码实现
其中用到的技术,是前不久从帅帅老师视频那里学到的selenium,代码结构如下:
driver = webdriver.Chrome()
driver.get(url)
WebDriverWait(self.driver, timeout=10).until
driver.execute_script
driver.page_source
html.xpath('//*[@class="section"]')
node.xpath('./span[3]/text()')
在帅帅老师的指点下,还用到了显示等待WebDriverWait()新知识,爬取效率由原来的196秒缩减到85秒。
保存excel还用到了openpyxl模块,其实也可以用pandas的to_excel进行数据的保存,这里使用了openpyxl。代码结构如下:
wb = Workbook()
ws1 = self.wb.active
ws1.title
ws1.append(['课程序号', '课程名字', '课程URL'])
ws1.append(content)
wb.save(filename=self.dest_filename)
话不多说直接上完整代码
import pandas as pd
from lxml import etree
import time, re
from openpyxl import Workbook
from selenium import webdriver
from fake_useragent import UserAgent
from selenium.webdriver.support.wait import WebDriverWait
class WangYiYunKeTang():
def __init__(self):
# 伪装请求头
user_agent = UserAgent().random
self.headers = {'User-Agent': user_agent}
self.wb = Workbook()
# 定义一个工作簿名称
self.dest_filename = '网易云课堂的套餐课信息.xlsx'
# 激活一个表单
self.ws1 = self.wb.active
# 为工作表起名字
self.ws1.title = '详情数据'
# 添加标题
self.ws1.append(['课程序号', '课程名字', '课程URL', '多少人学过', '课程价格(元)', '第几课时', '课时标题', '时长', '时长秒数(秒)'])
# 获取每个课程的URL
def getEachCourseUrl(self):
url = 'https://study.163.com/series/1202914611.htm'
self.driver.get(url)
time.sleep(1)
js = 'window.scrollTo(0, document.body.scrollHeight)'
self.driver.execute_script(js)
time.sleep(1)
page_text = self.driver.page_source
html = etree.HTML(page_text)
# 每个课程的URL列表
href = html.xpath('//*[@class="wrap m-test5-wrap f-pr f-cb"]/a/@href')
return href
# 获取每个课程的详细信息
def getEachCourseDetailed(self):
href = self.getEachCourseUrl()
# href = ['/course/introduction/1209400837.htm']
# print(href)
for idx, i in enumerate(list(href)):
# 获取课程id
id = ''.join(re.findall('\d', i))
# 拼接每个课程的URL完整地址
url = f'https://study.163.com/course/introduction.htm?courseId={id}#/courseDetail?tab=1'
# 课程URL
print(url)
self.driver.get(url)
# 课时、关于我们等关键词出现了,页面就是加载完毕
WebDriverWait(self.driver, timeout=10).until(
lambda x: "关于我们" in self.driver.page_source and "课时" in self.driver.page_source)
# time.sleep(1)
js = 'window.scrollTo(0, document.body.scrollHeight)'
self.driver.execute_script(js)
# time.sleep(1)
page_text = self.driver.page_source
html = etree.HTML(page_text)
# 课程名字
name = html.xpath('//*[@class="u-coursetitle f-fl"]/h2/span/text()')[0]
# 多少人学过
many_people = html.xpath('//*[@class="u-coursetitle f-fl"]/div/span[1]/text()')[0].replace('人学过', '')
# 课程价格
price = html.xpath('//*[@class="price"]/text()')[0].replace('¥ ', '')
nodes = html.xpath('//*[@class="section"]')
for node in nodes:
# 第几课时
class_hour = node.xpath('./span[1]/text()')[0].replace('课时', '')
# 课程标题
class_title = node.xpath('./span[3]/text()')[0]
# 时长,时长有空的情况需要判断
duration = node.xpath('./span[4]/span[1]/text()')
duration = duration[0] if len(duration) > 0 else '无时长'
# 时长切分成分和秒
if duration != '无时长':
duration_split = duration.split(':')
# 时长秒数
duration_second = int(duration_split[0]) * 60 + int(duration_split[1])
content = [idx + 1, name, url, many_people, price, class_hour, class_title, duration,
duration_second]
# 调用写excel方法
self.write_excel(content)
print(content, '写入excel成功')
else:
duration_second = '无秒数'
content = [idx + 1, name, url, many_people, price, class_hour, class_title, duration,
duration_second]
# 调用写excel方法
self.write_excel(content)
print(content, '写入excel成功')
# 写excel
def write_excel(self, content):
# 添加数据
self.ws1.append(content)
# 保存文件
self.wb.save(filename=self.dest_filename)
# 主函数
def main(self):
# 开始时间
start_time = time.time()
# 统一获取driver
self.driver = webdriver.Chrome()
# 调用获取每个课程的详细信息方法
self.getEachCourseDetailed()
# 总耗时
use_time = int(time.time()) - int(start_time)
print(f'爬取总计耗时:{use_time}秒')
# 退出
self.driver.quit()
if __name__ == '__main__':
wyykt = WangYiYunKeTang()
wyykt.main()
当然,中间调试花了一些时间,因为获取到html页面后用xpath定位元素的时候没有找对,反复调试了一番。运行程序之后,只花了85s的时间就完成了数据的爬取,在没有用到并发技术情况下还算比较快的了。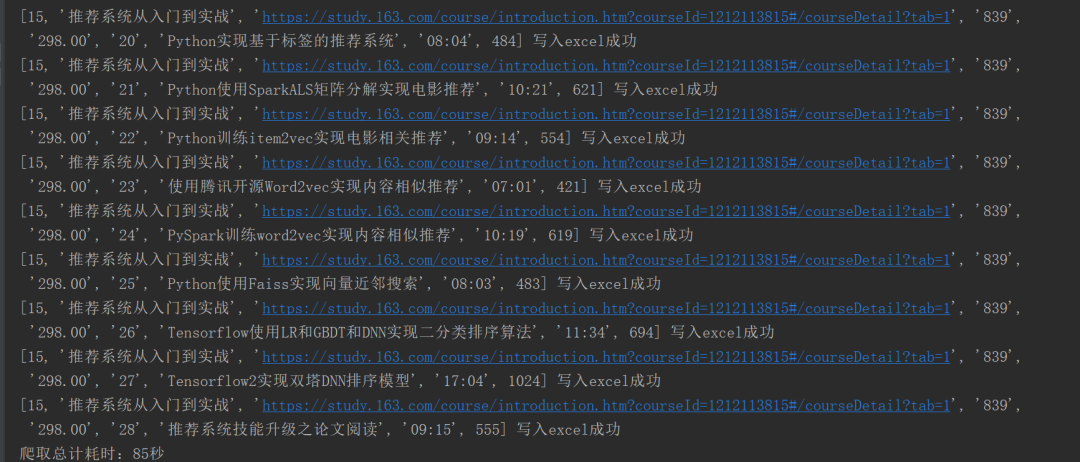
最后展示一下成果
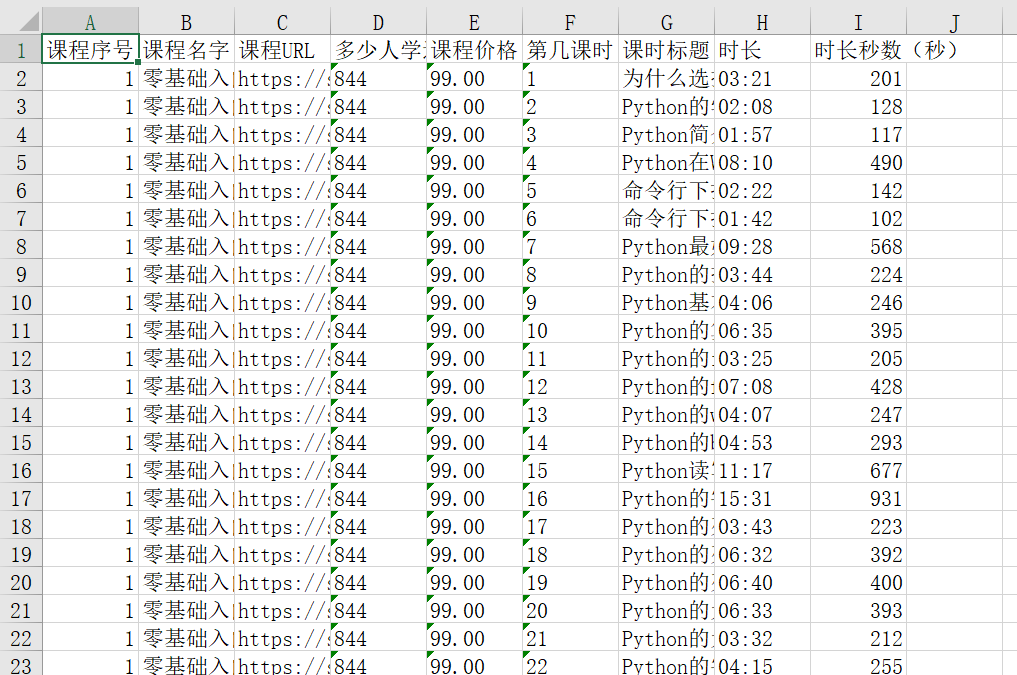
今天也多了一笔额外的收入,开心开心


↓点击阅读原文,欢迎了解蚂蚁老师的Python大套餐,购买课程提供11答疑、副业接单权限。
评论