
LSTM原理及生成藏头诗(Python)
一、基础介绍
1.1 神经网络模型
常见的神经网络模型结构有前馈神经网络(DNN)、RNN(常用于文本 / 时间系列任务)、CNN(常用于图像任务)等等。具体可以看之前文章:一文概览神经网络模型。
前馈神经网络是神经网络模型中最为常见的,信息从输入层开始输入,每层的神经元接收前一级输入,并输出到下一级,直至输出层。整个网络信息输入传输中无反馈(循环)。即任何层的输出都不会影响同级层,可用一个有向无环图表示。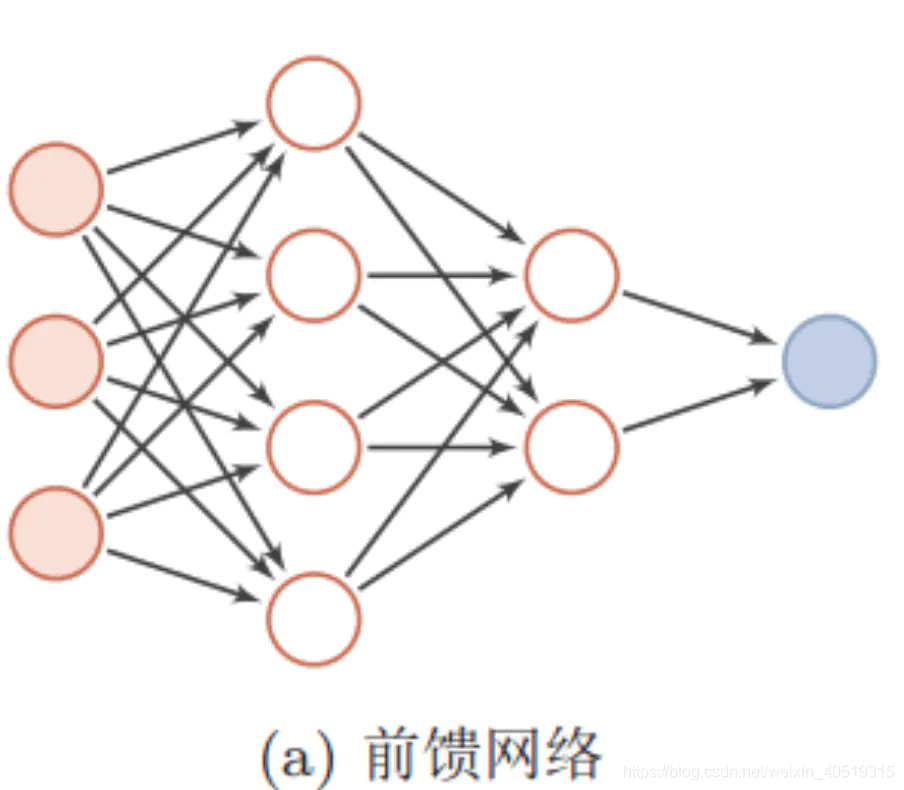
1.2 RNN 介绍
循环神经网络(RNN)是基于序列数据(如语言、语音、时间序列)的递归性质而设计的,是一种反馈类型的神经网络,它专门用于处理序列数据,如逐字生成文本或预测时间序列数据(例如股票价格、诗歌生成)。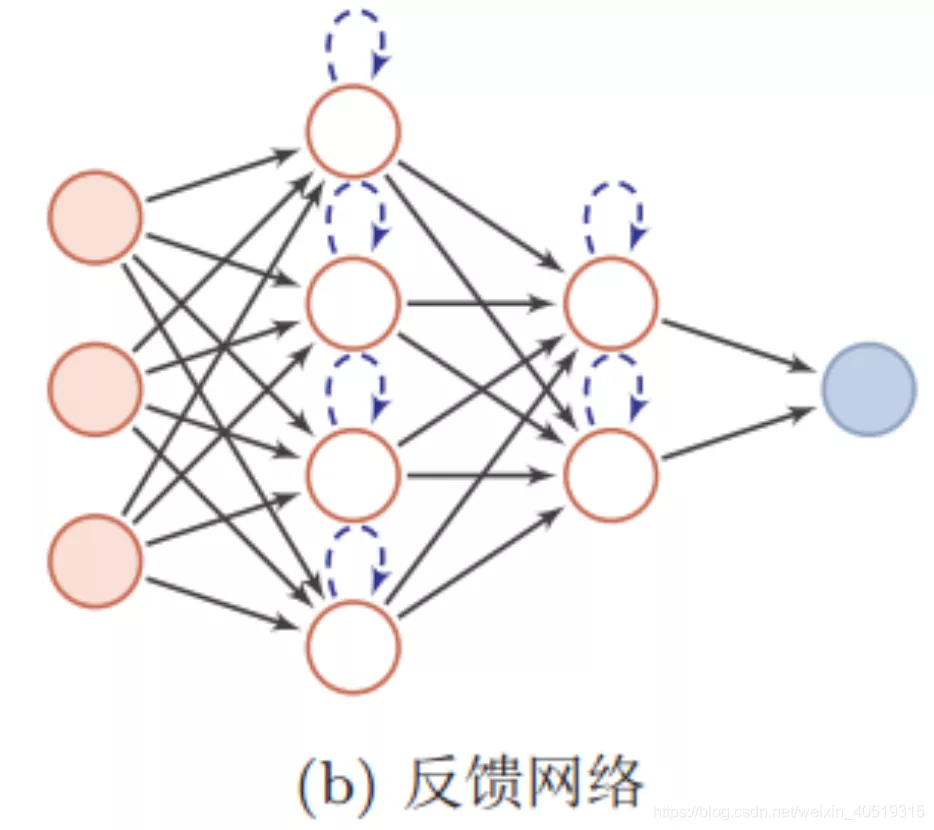
RNN和全连接神经网络的本质差异在于“输入是带有反馈信息的”,RNN除了接受每一步的输入x(t) ,同时还有输入上一步的历史反馈信息——隐藏状态h (t-1) ,也就是当前时刻的隐藏状态h(t) 或决策输出O(t) 由当前时刻的输入 x(t) 和上一时刻的隐藏状态h (t-1) 共同决定。从某种程度,RNN和大脑的决策很像,大脑接受当前时刻感官到的信息(外部的x(t) )和之前的想法(内部的h (t-1) )的输入一起决策。
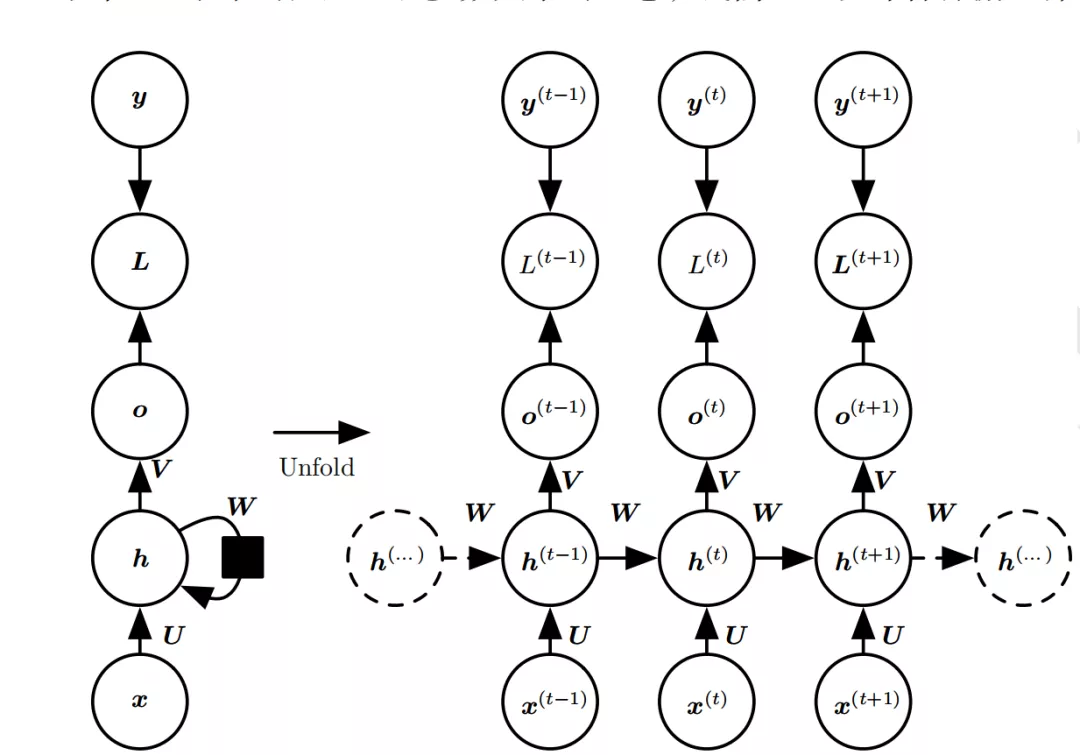
RNN的结构原理可以简要概述为两个公式,具体介绍可以看下【一文详解RNN】:
RNN的隐藏状态为:h(t) = f( U * x(t) + W * h(t-1) + b1), f为激活函数,常用tanh、relu;
RNN的输出为:o(t) = g( V * h(t) + b2),g为激活函数,当用于分类任务,一般用softmax;
1.3 从RNN到LSTM
但是在实际中,RNN在长序列数据处理中,容易导致梯度爆炸或者梯度消失,也就是长期依赖(long-term dependencies)问题,其根本原因就是模型“记忆”的序列信息太长了,都会一股脑地记忆和学习,时间一长,就容易忘掉更早的信息(梯度消失)或者崩溃(梯度爆炸)。
梯度消失:历史时间步的信息距离当前时间步越长,反馈的梯度信号就会越弱(甚至为0)的现象,梯度被近距离梯度主导,导致模型难以学到远距离的依赖关系。
改善措施:可以使用 ReLU 激活函数;门控RNN 如GRU、LSTM 以改善梯度消失。
梯度爆炸:网络层之间的梯度(值大于 1)重复相乘导致的指数级增长会产生梯度爆炸,导致模型无法有效学习。
改善措施:可以使用 梯度截断;引导信息流的正则化;ReLU 激活函数;门控RNN 如GRU、LSTM(和普通 RNN 相比多经过了很多次导数都小于 1激活函数,因此 LSTM 发生梯度爆炸的频率要低得多)以改善梯度爆炸。
所以,如果我们能让 RNN 在接受上一时刻的状态和当前时刻的输入时,有选择地记忆和遗忘一部分内容(或者说信息),问题就可以解决了。比如上上句话提及”我去考试了“,然后后面提及”我考试通过了“,那么在此之前说的”我去考试了“的内容就没那么重要,选择性地遗忘就好了。这也就是长短期记忆网络(Long Short-Term Memory, LSTM)的基本思想。
二、LSTM原理
LSTM是种特殊RNN网络,在RNN的基础上引入了“门控”的选择性机制,分别是遗忘门、输入门和输出门,从而有选择性地保留或删除信息,以能够较好地学习长期依赖关系。如下图RNN(上) 对比 LSTM(下):
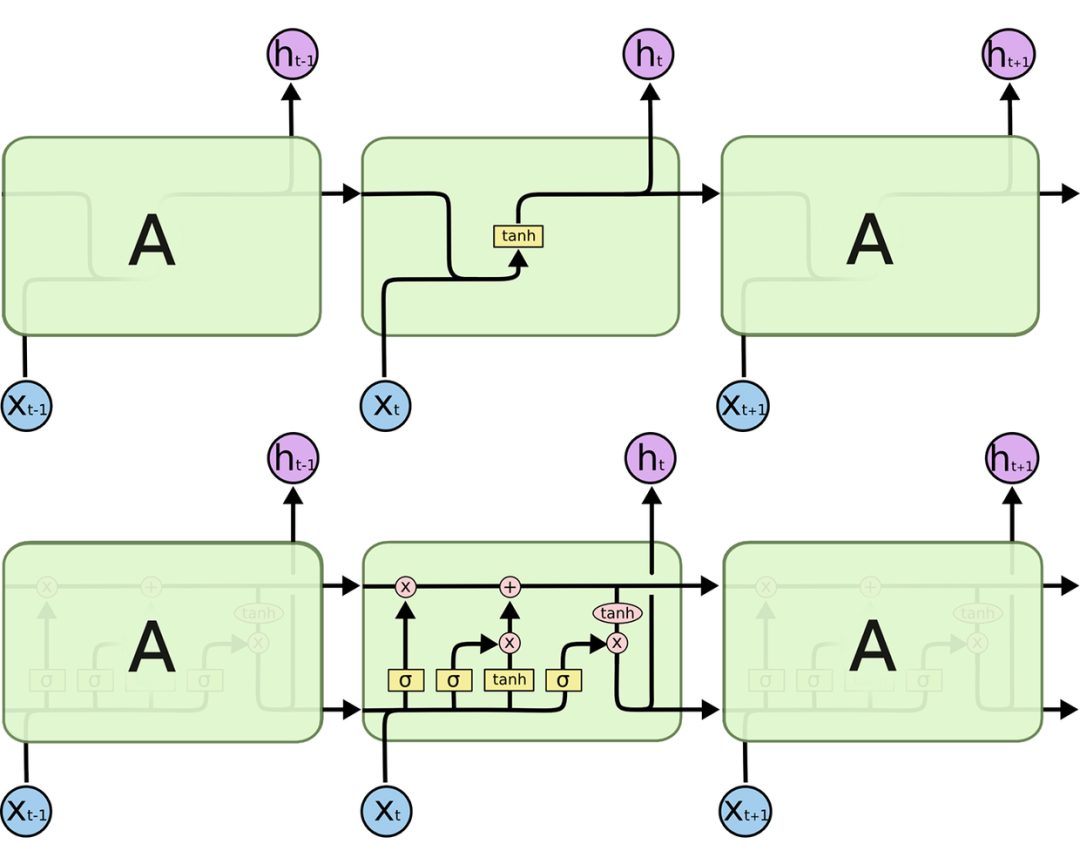
2.1 LSTM的核心
在RNN基础上引入门控后的LSTM,结构看起来好复杂!但其实LSTM作为一种反馈神经网络,核心还是历史的隐藏状态信息的反馈,也就是下图的Ct: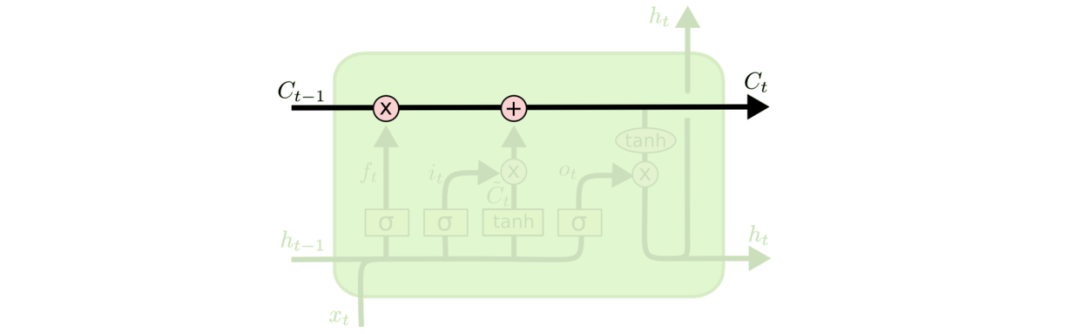 对标RNN的ht隐藏状态的更新,LSTM的Ct只是多个些“门控”删除或添加信息到状态信息。由下面依次介绍LSTM的“门控”:遗忘门,输入门,输出门的功能,LSTM的原理也就好理解了。
对标RNN的ht隐藏状态的更新,LSTM的Ct只是多个些“门控”删除或添加信息到状态信息。由下面依次介绍LSTM的“门控”:遗忘门,输入门,输出门的功能,LSTM的原理也就好理解了。
2.2 遗忘门
LSTM 的第一步是通过"遗忘门"从上个时间点的状态Ct-1中丢弃哪些信息。
具体来说,输入Ct-1,会先根据上一个时间点的输出ht-1和当前时间点的输入xt,并通过sigmoid激活函数的输出结果ft来确定要让Ct-1,来忘记多少,sigmoid后等于1表示要保存多一些Ct-1的比重,等于0表示完全忘记之前的Ct-1。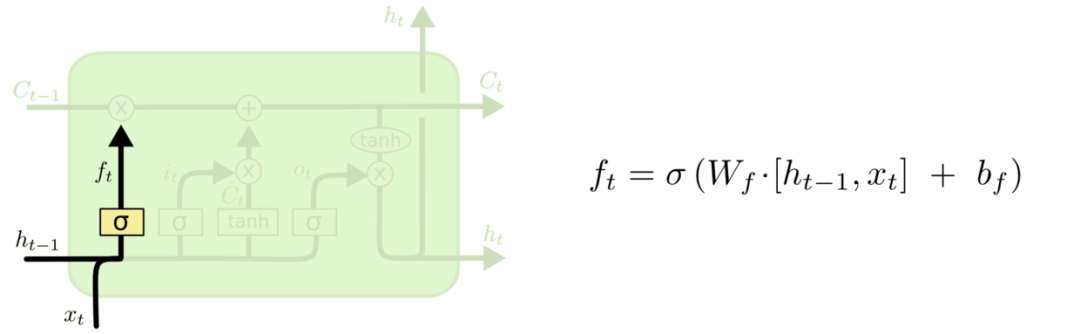
2.3 输入门
下一步是通过输入门,决定我们将在状态中存储哪些新信息。
我们根据上一个时间点的输出ht-1和当前时间点的输入xt 生成两部分信息i t 及C~t,通过sigmoid输出i t,用tanh输出C~t。之后通过把i t 及C~t两个部分相乘,共同决定在状态中存储哪些新信息。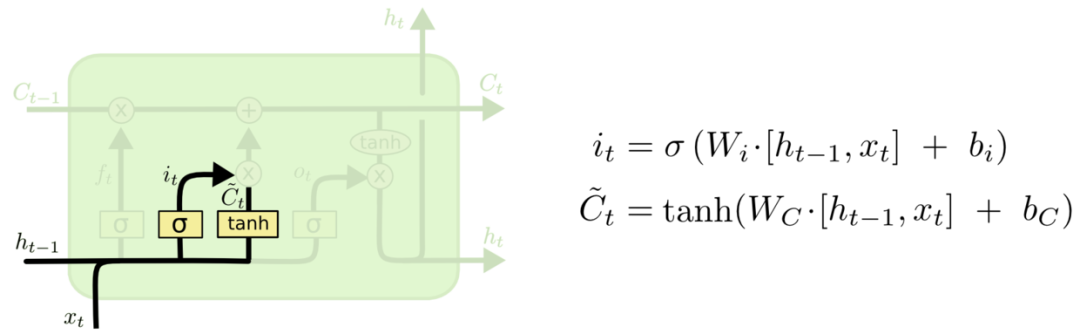
在输入门 + 遗忘门控制下,当前时间点状态信息Ct为:
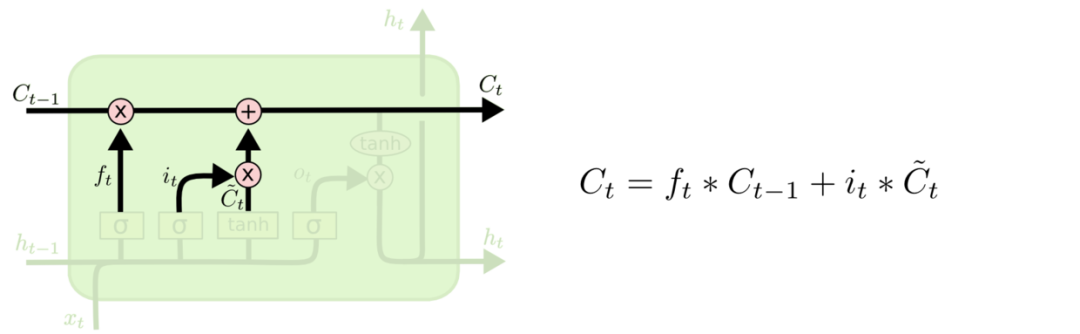
2.4 输出门
最后,我们根据上一个时间点的输出ht-1和当前时间点的输入xt 通过sigmid 输出Ot,再根据Ot 与 tanh控制的当前时间点状态信息Ct 相乘作为最终的输出。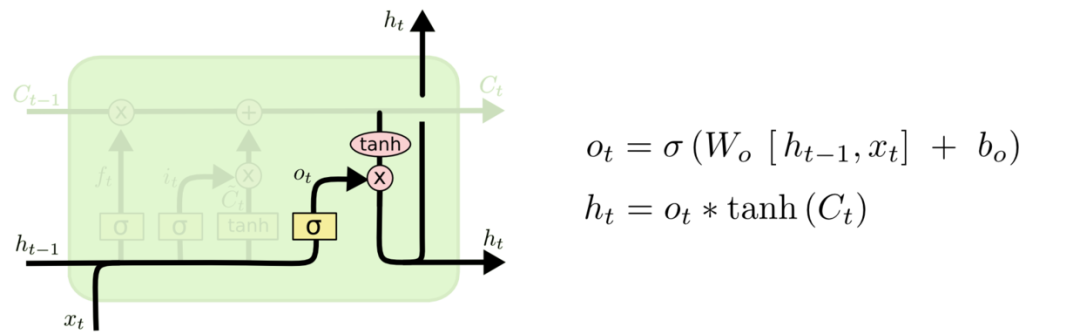
综上,一张图可以说清LSTM原理: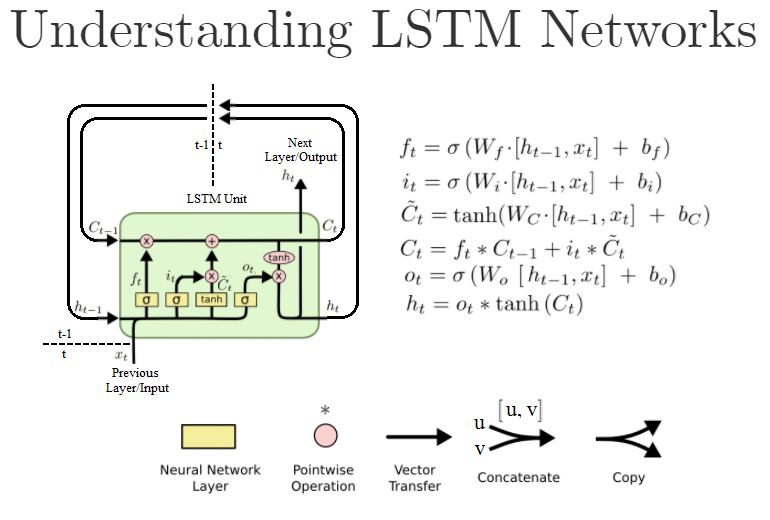
三、LSTM简单写诗
本节项目利用深层LSTM模型,学习大小为10M的诗歌数据集,自动可以生成诗歌。
如下代码构建LSTM模型。
## 本项目完整代码:github.com/aialgorithm/Blog
# 或“算法进阶”公众号文末阅读原文可见
model = tf.keras.Sequential([
# 不定长度的输入
tf.keras.layers.Input((None,)),
# 词嵌入层
tf.keras.layers.Embedding(input_dim=tokenizer.vocab_size, output_dim=128),
# 第一个LSTM层,返回序列作为下一层的输入
tf.keras.layers.LSTM(128, dropout=0.5, return_sequences=True),
# 第二个LSTM层,返回序列作为下一层的输入
tf.keras.layers.LSTM(128, dropout=0.5, return_sequences=True),
# 对每一个时间点的输出都做softmax,预测下一个词的概率
tf.keras.layers.TimeDistributed(tf.keras.layers.Dense(tokenizer.vocab_size, activation='softmax')),
])
# 查看模型结构
model.summary()
# 配置优化器和损失函数
model.compile(optimizer=tf.keras.optimizers.Adam(), loss=tf.keras.losses.categorical_crossentropy)
模型训练,考虑训练时长,就简单训练2个epoch。
class Evaluate(tf.keras.callbacks.Callback):
"""
训练过程评估,在每个epoch训练完成后,保留最优权重,并随机生成SHOW_NUM首古诗展示
"""
def __init__(self):
super().__init__()
# 给loss赋一个较大的初始值
self.lowest = 1e10
def on_epoch_end(self, epoch, logs=None):
# 在每个epoch训练完成后调用
# 如果当前loss更低,就保存当前模型参数
if logs['loss'] <= self.lowest:
self.lowest = logs['loss']
model.save(BEST_MODEL_PATH)
# 随机生成几首古体诗测试,查看训练效果
print("cun'h")
for i in range(SHOW_NUM):
print(generate_acrostic(tokenizer, model, head="春花秋月"))
# 创建数据集
data_generator = PoetryDataGenerator(poetry, random=True)
# 开始训练
model.fit_generator(data_generator.for_fit(), steps_per_epoch=data_generator.steps, epochs=TRAIN_EPOCHS,
callbacks=[Evaluate()])
加载简单训练的LSTM模型,输入关键字(如:算法进阶)后,自动生成藏头诗。可以看出诗句粗略看上去挺优雅,但实际上经不起推敲。后面增加训练的epoch及数据集应该可以更好些。
# 加载训练好的模型
model = tf.keras.models.load_model(BEST_MODEL_PATH)
keywords = input('输入关键字:\n')
# 生成藏头诗
for i in range(SHOW_NUM):
print(generate_acrostic(tokenizer, model, head=keywords),'\n')

- END -参考资料:https://colah.github.io/posts/2015-08-Understanding-LSTMs/
https://towardsdatascience.com/illustrated-guide-to-lstms-and-gru-s-a-step-by-step-explanation-44e9eb85bf21
https://www.zhihu.com/question/34878706
文章首发公众号“算法进阶”,文末阅读原文可访问文章相关代码