
Flink CDC 原理及生产实践
点击上方蓝色字体,选择“设为星标”




 MySQL CDC连接器允许从MySQL数据库读取快照数据和增量数据。本文档根据官网翻译了如何设置MySQL CDC连接器以对MySQL数据库运行SQL查询。
MySQL CDC连接器允许从MySQL数据库读取快照数据和增量数据。本文档根据官网翻译了如何设置MySQL CDC连接器以对MySQL数据库运行SQL查询。
依赖关系
为了设置MySQL CDC连接器,下表提供了使用构建自动化工具(例如Maven或SBT)和带有SQL JAR捆绑包的SQL Client的两个项目的依赖项信息。
1、Maven依赖
com.alibaba.ververica
flink-connector-mysql-cdc
1.1.0
2、SQL客户端JAR
下载flink-sql-connector-mysql-cdc-1.1.0.jar并将其放在下 /lib/。
设置MySQL服务器
您必须定义一个对Debezium MySQL连接器监视的所有数据库具有适当权限的MySQL用户。
1、创建MySQL用户
mysql> CREATE USER 'user'@'localhost' IDENTIFIED BY 'password';
2、向用户授予所需的权限
mysql> GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'user' IDENTIFIED BY 'password';
3、最终确定用户的权限
mysql> FLUSH PRIVILEGES;
注意
1、MySQL CDC源代码如何工作
启动MySQL CDC源时,它将获取一个全局读取锁(FLUSH TABLES WITH READ LOCK),该锁将阻止其他数据库的写入。然后,它读取当前binlog位置以及数据库和表的schema。之后,将释放 全局读取锁。然后,它扫描数据库表并从先前记录的位置读取binlog。Flink将定期执行checkpoints以记录binlog位置。如果发生故障,作业将重新启动并从checkpoint完成的binlog位置恢复。因此,它保证了仅一次的语义。
2、向MySQL用户授予RELOAD权限
如果未授予MySQL用户RELOAD权限,则MySQL CDC源将改为使用表级锁,并使用此方法执行快照。这会阻止写入更长的时间。
3、全局读取锁(FLUSH TABLES WITH READ LOCK)
全局读取锁 在读取binlog位置和schema期间保持。这可能需要几秒钟,具体取决于表的数量。全局读取锁定会阻止写入,因此它仍然可能影响在线业务。如果要跳过读取锁,并且可以容忍至少一次语义,则可以添加'debezium.snapshot.locking.mode' = 'none'选项以跳过锁。
4、为每个作业设置一个differnet SERVER ID 每个用于读取binlog的MySQL数据库客户端都应具有唯一的ID,称为server id。MySQL服务器将使用此ID维护网络连接和binlog位置。如果不同的作业共享相同的server id,则可能导致从错误的binlog位置进行读取。提示:默认情况下,启动TaskManager时,server id是随机的。如果TaskManager失败,则再次启动时,它可能具有不同的server id。但这不应该经常发生(作业异常不会重新启动TaskManager),也不会对MySQL服务器造成太大影响。
因此,建议为每个作业设置不同的server id ,例如:
通过SQL Hints:SELECT * FROM source_table /+ OPTIONS('server-id'='123456') / ;
通过Stream ApI的 创建source时设置:MySQLSource.builder().xxxxxx.serverId(123456);
重点:Mysq的binlog 可以说是针对库级别,所以相同的server id去拉一个库里的不同表或者相同表可能会造成数据丢失。所以建议设置server id。
5、扫描数据库表期间无法执行检查点
在扫描表期间,由于没有可恢复的位置,因此我们无法执行checkpoints。为了不执行检查点,MySQL CDC源将保持检查点等待超时。超时检查点将被识别为失败的检查点,默认情况下,这将触发Flink作业的故障转移。因此,如果数据库表很大,则建议添加以下Flink配置,以避免由于超时检查点而导致故障转移:
execution.checkpointing.interval: 10min
execution.checkpointing.tolerable-failed-checkpoints: 100
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 2147483647
6、设置MySQL会话超时
为大型数据库创建初始一致的快照时,在读取表时,您建立的连接可能会超时。您可以通过在MySQL配置文件中配置Interactive_timeout和wait_timeout来防止此行为。
interactive_timeout:服务器在关闭交互式连接之前等待活动的秒数。
wait_timeout:服务器在关闭非交互式连接之前等待其活动的秒数。
如何创建MySQL CDC表
1、Sql的方式:(1)定义表如下:
-- register a MySQL table 'orders' in Flink SQL
CREATE TABLE orders (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'mydb',
'table-name' = 'orders'
);
-- read snapshot and binlogs from orders table
SELECT * FROM orders;
2、Stream API
MySQL CDC连接器也可以是DataStream源。您可以创建SourceFunction,如下所示:
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import com.alibaba.ververica.cdc.debezium.StringDebeziumDeserializationSchema;
import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;
public class MySqlBinlogSourceExample {
public static void main(String[] args) throws Exception {
SourceFunction sourceFunction = MySQLSource.builder()
.hostname("localhost")
.port(3306)
.databaseList("inventory") // monitor all tables under inventory database
.username("flinkuser")
.password("flinkpw")
.deserializer(new StringDebeziumDeserializationSchema()) // converts SourceRecord to String
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env
.addSource(sourceFunction)
.print().setParallelism(1); // use parallelism 1 for sink to keep message ordering
env.execute();
}
}
特征
1、Exactly-Once Processing 一次处理 MySQL CDC连接器是Flink Source连接器,它将首先读取数据库快照,然后即使发生故障,也将以完全一次的处理继续读取二进制日志。请阅读连接器如何执行数据库快照。
2、Single Thread Reading 单线程阅读 MySQL CDC源无法并行读取,因为只有一个任务可以接收Binlog事件。
常见问题
1、如何跳过快照并仅从binlog中读取?可以通过选项进行控制debezium.snapshot.mode,您可以将其设置为:
never:指定连接永远不要使用快照,并且在第一次使用逻辑服务器名称启动时,连接器应该从binlog的开头读取;请谨慎使用,因为只有在binlog保证包含数据库的整个历史记录时才有效。
schema_only:如果自连接器启动以来不需要数据的连续快照,而只需要它们进行更改,则可以使用该schema_only选项,其中连接器仅对模式(而不是数据)进行快照。
2、如何读取包含多个表(例如user_00,user_01,...,user99)的共享数据库?该table-name选项支持正则表达式以监视多个与正则表达式匹配的表。因此,您可以设置table-name为user.*监视所有user_前缀表。database-name选项相同。请注意,共享表应该在相同的架构中。
3、ConnectException:收到用于处理的DML'...',binlog可能包含使用语句或基于混合的复制格式生成的事件 如果有上述异常,请检查是否binlog_format为ROW,您可以通过show variables like '%binlog_format%'在MySQL客户端中运行来进行检查。请注意,即使binlog_format您的数据库配置为ROW,也可以通过其他会话更改此配置,例如SET SESSION binlog_format='MIXED'; SET SESSION tx_isolation='REPEATABLE-READ'; COMMIT;。还请确保没有其他会话正在更改此配置
实践中遇到的问题
1、不同的kafka版本依赖冲突会造成cdc报错:http://apache-flink.147419.n8.nabble.com/cdc-td8357.html#a8393
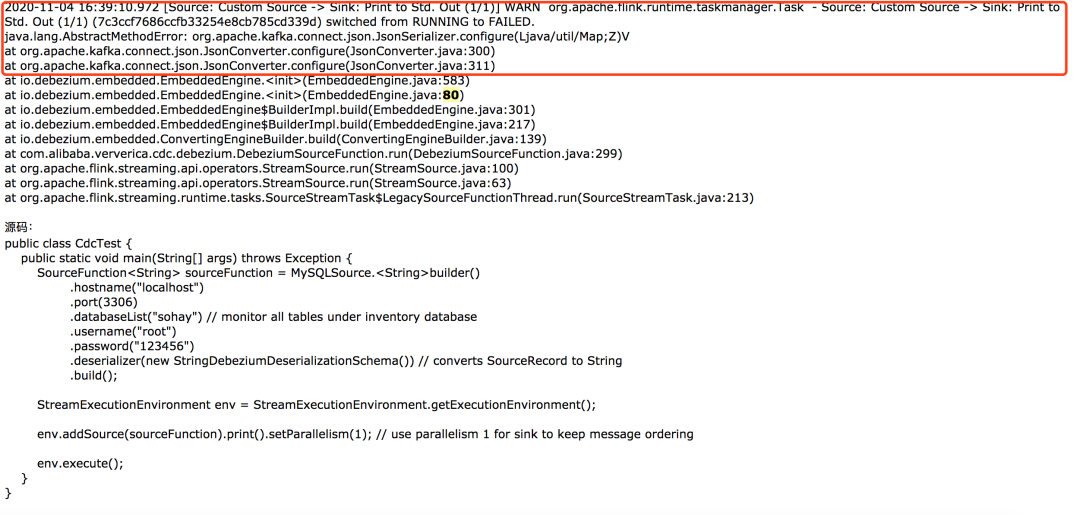
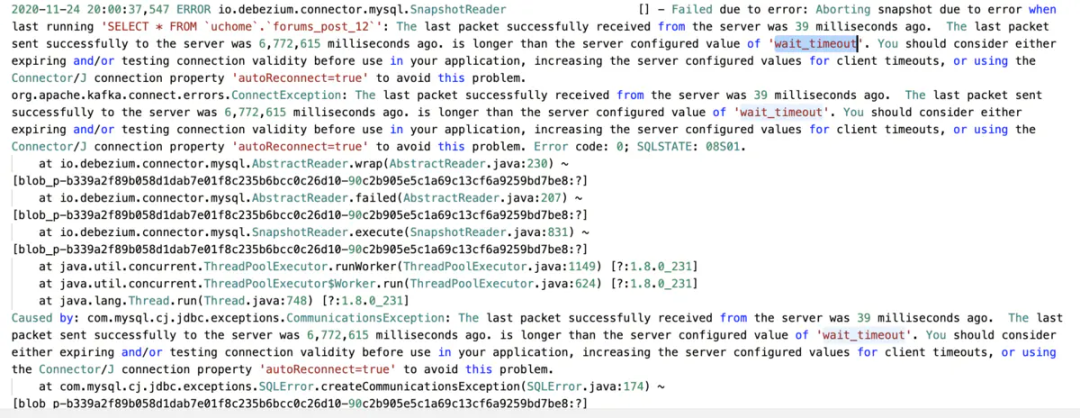
2、超时问题:根据上面提到设置wait_timeout解决。


版权声明:
编辑 《大数据技术与架构》
插画 《大数据技术与架构》
文章链接 https://www.jianshu.com/p/439b1d1247b2
文章不错?点个【在看】吧! ?