
什么是布隆过滤器?如何解决高并发缓存穿透问题?
日常开发中,大家经常使用缓存,但是你知道大型的互联网公司面对高并发流量,要注意缓存穿透问题吗!!! 本文会介绍布隆过滤器,空间换时间,以较低的内存空间、高效解决这个问题。
本篇文章的目录:

1、性能不够,缓存来凑
现在的年轻人都喜欢网购,没事就逛逛淘宝,剁剁手,买些自己喜欢的东西,释放下工作压力。

地址:
https://detail.tmall.com/item.htm?id=628993216729
上图是一个天猫 iphone12 的商品详情页,id表示商品的编号
我们都知道淘宝的访问量是非常高的,为了提升系统的吞吐量,做了很多性能优化,其中非常重要一点是将信息异构到缓存中。
有句话说的好:性能不够,缓存来凑。
但是,使用缓存时,我们要关注一个重要问题,如果缓存没有命中怎么办?

2、缓存没有命中,怎么办?
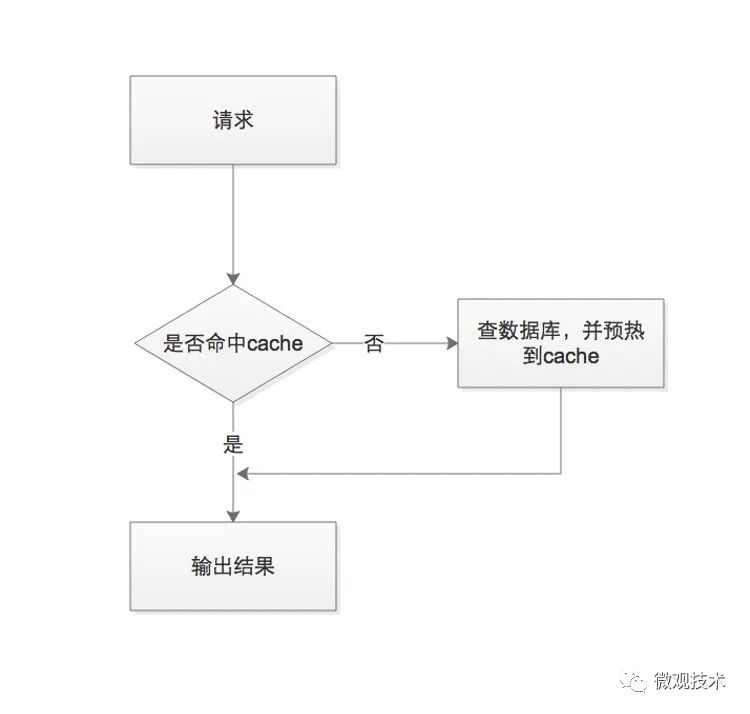
①我们先查询缓存,判断缓存中是否有数据 ②如果有数据,直接返回 ③如果缓存为空,我们需要再查一次数据库,并将数据格式异构化,然后预热到缓冲中,然后将结果返回
注意:
步骤 ③ 存在风险漏洞,如果缓存中数据不存在,压力会转嫁给数据库。假如被竞争对手利用,搞无效请求流量攻击,瞬间大量请求打到数据库中,对系统性能产生很大影响,很容易把数据库打挂,这种现象称为缓存穿透。
3、那么如何处理缓存穿透?
我们的思路是,缓存中能不能判断这个数据库值的存在性,如果真的不存在,直接返回,也避免一次数据库查询。
由于不存在是个无限边界,所以,我们采用反向策略,将存在的值建立一个高效的检索。每次缓存取值时,先走一次判空检索。
简单归纳下,这个框架的要求:
快速检索 内存空间要非常小
经调研,我们发现布隆过滤器具备以上两个条件。
4、什么是布隆过滤器?
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。
优点:空间效率和查询时间都远远超过一般的算法。 缺点:有一定的误识别率,删除困难。
5、布隆过滤器如何构建?
布隆过滤器本质上是一个 n 位的二进制数组,用0和1表示。
假如我们以商品为例,有三件商品,商品编码分别为,id1、id2、id3
a)首先,对id1,进行三次哈希,并确定其在二进制数组中的位置。

三次哈希,对应的二进制数组下标分别是 2、5、8,将原始数据从 0 变为 1。
b)对id2,进行三次哈希,并确定其在二进制数组中的位置。
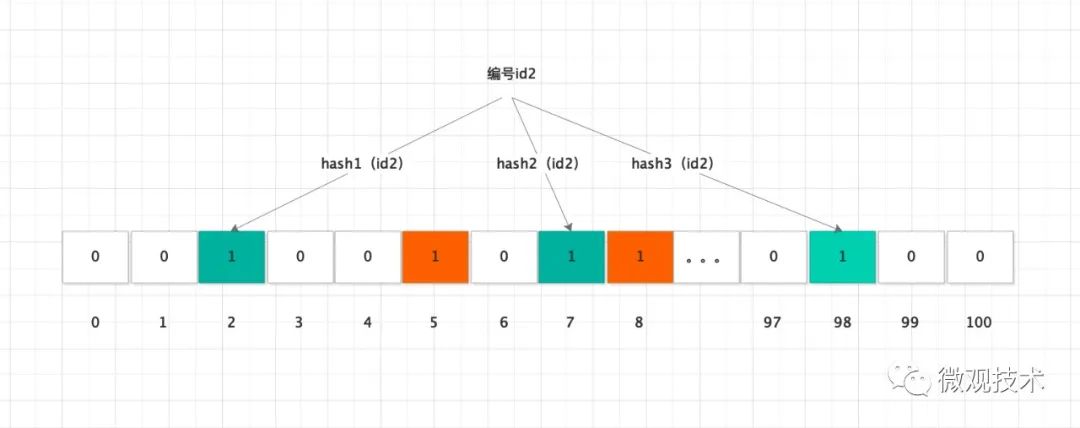
三次哈希,对应的二进制数组下标分别是 2、7、98,将原始数据从 0 变为 1。
下标 2,之前已经被操作设置成 1,则本次认为是哈希冲突,不需要改动。
Hash 规则:如果在 Hash 后,原始位它是 0 的话,将其从 0 变为 1;如果本身这一位就是 1 的话,则保持不变。
6、布隆过滤器如何使用?
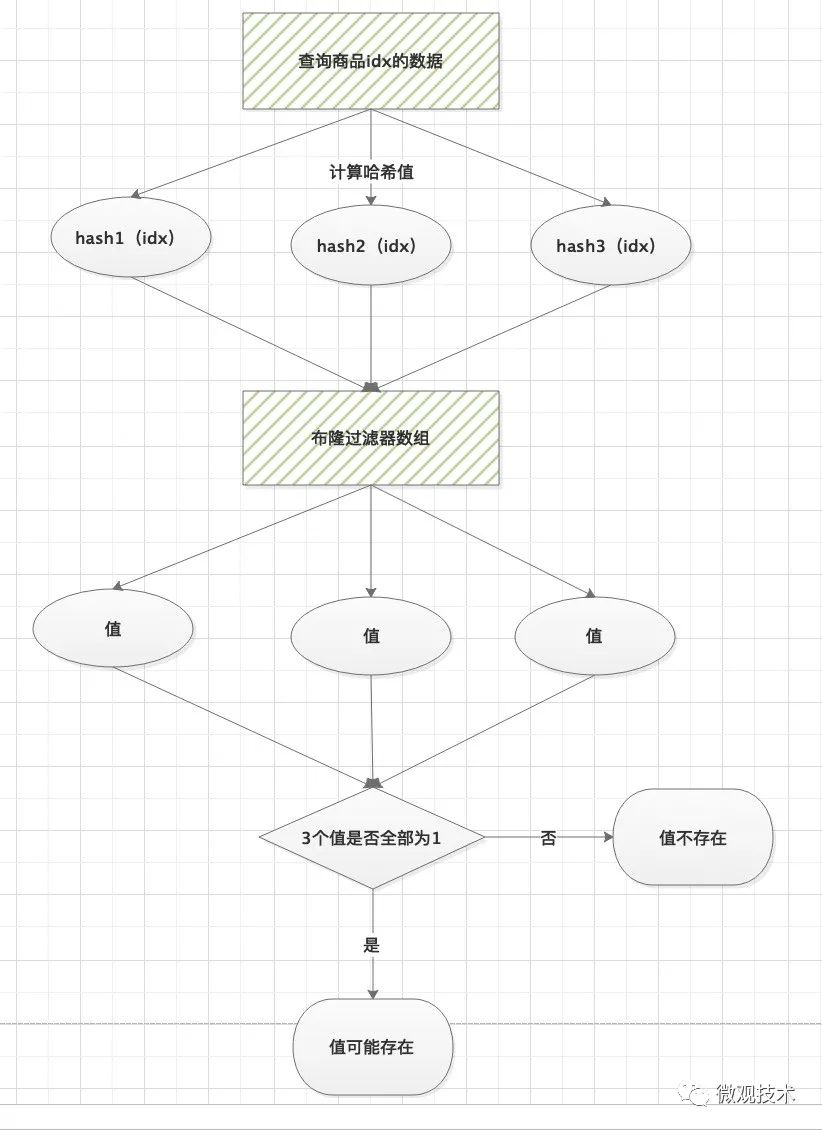
跟初始化的过程有点类似,当查询一件商品的缓存信息时,我们首先要判断这件商品是否存在。
通过三个哈希函数对商品id计算哈希值 然后,在布隆数组中查找访问对应的位值,0或1 判断,三个值中,只要有一个不是1,那么我们认为数据是不存在的。
注意:布隆过滤器只能精确判断数据不存在情况,对于存在我们只能说是可能,因为存在Hash冲突情况,当然这个概率非常低。
7、如何减少布隆过滤器的误判?
a)增加二进制位数组的长度。这样经过hash后数据会更加的离散化,出现冲突的概率会大大降低
b)增加Hash的次数,变相的增加数据特征,特征越多,冲突的概率越小
8、布隆过滤器会不会很费内存?
带着疑问,我们来做个实验
假设有1千万个数据,我们需要记录其是否存在。存在的话标记1,不存在标记为0。技术选型,框架采用Redis的BitMap存储。
数据初始化预热代码:
redisTemplate.executePipelined(new RedisCallback<Long>() {
@Nullable
@Override
public Long doInRedis(RedisConnection connection) throws DataAccessException {
connection.openPipeline();
for (int offset = 10000000; offset >= 0; offset--) {
boolean value = offset % 2 == 0 ? true : false;
connection.setBit("bloom-filter-data-1".getBytes(), offset, value);
}
connection.closePipeline();
return null;
}
});
System.out.println("数据预热完成");
性能有点慢,我们也可以采用分组形式,10000个数一组,多批次提交。

数据上传完了后,大小 1.19M,跟我们设想的一样。
计算公式: 10000000/8/1024/1024=1.19M
9、Java应用中,如何使用布隆过滤器?代码实例
Java语言的生态非常繁荣,提供了很多开箱即用的开源框架供我们使用。布隆过滤器也不例外,Java 中提供了一个 Redisson 的组件,它内置了布隆过滤器。
首先引入依赖包
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.11.1</version>
</dependency>
代码示例:
/**
* @author 微信公众号:微观技术
*/
@Test
public void test5() {
Config config = new Config();
config.useSingleServer().setAddress("redis://172.16.67.37:6379");
RedissonClient cient = Redisson.create(config);
RBloomFilter<String> bloomFilter = cient.getBloomFilter("test5-bloom-filter");
// 初始化布隆过滤器,数组长度100W,误判率 1%
bloomFilter.tryInit(1000000L, 0.01);
// 添加数据
bloomFilter.add("Tom哥");
// 判断是否存在
System.out.println(bloomFilter.contains("微观技术"));
System.out.println(bloomFilter.contains("Tom哥"));
}
运行结果:
false // 肯定不存在
true // 可能存在,有1%的误判率
注意:误判率设置过小,会产生更多次的 Hash 操作,降低系统的性能。通常我们的建议值是 1%
10、布隆过滤器二进制数组,如何处理删除?
初始化后的布隆过滤器,可以直接拿来使用了。但是如果原始数据删除了怎么办?布隆过滤器二进制数组如何维护?
直接删除不行吗?
还真不行!因为这里面有Hash冲突的可能,会导致误删。
怎么办?
方案1:开发定时任务,每隔几个小时,自动创建一个新的布隆过滤器数组,替换老的,有点CopyOnWriteArrayList的味道
方案2:布隆过滤器增加一个等长的数组,存储计数器,主要解决冲突问题,每次删除时对应的计数器减一,如果结果为0,更新主数组的二进制值为0
11、布隆过滤器的应用场景
本文重点介绍的,解决缓存穿透 网页爬虫对URL的去重,避免爬取相同的URL地址 反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱

【另类见解】秒杀其实很简单!!
