
从bitmap到布隆过滤器,再到高并发缓存设计策略

作者:that_is_cool
blog.csdn.net/that_is_cool/article/details/91346356
前言:怎么能把风马牛不相及的概念串在一块,就得看笔者的本事了。
bitmap和布隆过滤器
海量整数中是否存在某个值--bitmap
在一个程序中,经常有让我们判断一个集合中是否存在某个数的case;大多数情况下,只需要用map或是list这样简单的数据结构,如果使用的是高级语言,还能乘上快车调用几个封装好的api,加几个if else,两三行代码就可以在控制台看自己“完美”而又“健壮”的代码跑起来了。
但是,事无完美,在高并发环境下,所有的case都会极端化,如果这是一个十分庞大的集合(给这个庞大一个具体的值吧,一个亿),简单的一个hash map,不考虑链表所需的指针内存空间,一亿个int类型的整数,就需要380多M(4byte × 10 ^8),十亿的话就是4个G,不考虑性能,光算算这内存开销,即使现在满地都是128G的服务器,也不好吃下这一壶。
bitmap则使用位数代表数的大小,bit中存储的0或者1来标识该整数是否存在,具体模型如下:
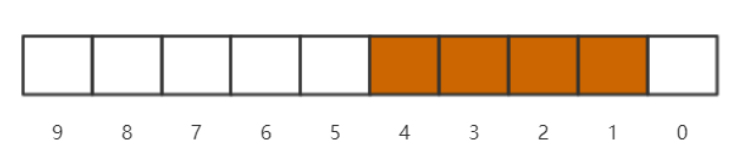
计算一下bitmap的内存开销,如果是1亿以内的数据查找,我们只需要1亿个bit = 12MB左右的内存空间,就可以完成海量数据查找了,是不是极其诱人的一个内存缩减,以下为Java实现的bitmap代码:
public class MyBitMap {
private byte[] bytes;
private int initSize;
public MyBitMap(int size) {
if (size <= 0) {
return;
}
initSize = size / (8) + 1;
bytes = new byte[initSize];
}
public void set(int number) {
//相当于对一个数字进行右移动3位,相当于除以8
int index = number >> 3;
//相当于 number % 8 获取到byte[index]的位置
int position = number & 0x07;
//进行|或运算 参加运算的两个对象只要有一个为1,其值为1。
bytes[index] |= 1 << position;
}
public boolean contain(int number) {
int index = number >> 3;
int position = number & 0x07;
return (bytes[index] & (1 << position)) != 0;
}
public static void main(String[] args) {
MyBitMap myBitMap = new MyBitMap(32);
myBitMap.set(30);
myBitMap.set(13);
myBitMap.set(24);
System.out.println(myBitMap.contain(2));
}
}
使用简单的byte数组和位运算,就能做到时间与空间的完美均衡,是不是美美哒,wrong!试想一下,如果我们明确这是一个一亿以内,但是数量级只有10的集合,我们使用bitmap,同样需要开销12M的数据,如果是10亿以内的数据,开销就会涨到120M,bitmap的空间开销永远是和他的数据取值范围挂钩的,只有在海量数据下,他才能够大显身手。
再说说刚刚提到的那个极端case,假设这个数据量在一千万,但是取值范围好死不死就在十个亿以内,那我们不可避免还是要面对120M的开销,有方法应对么?
布隆过滤器
如果面对笔者说的以上问题,我们结合一下常规的解决方案,譬如说hash一下,我将十亿以内的某个数据,hash成一亿内的某个值,再去bitmap中查怎么样,如下图,布隆过滤器就是这么干的:
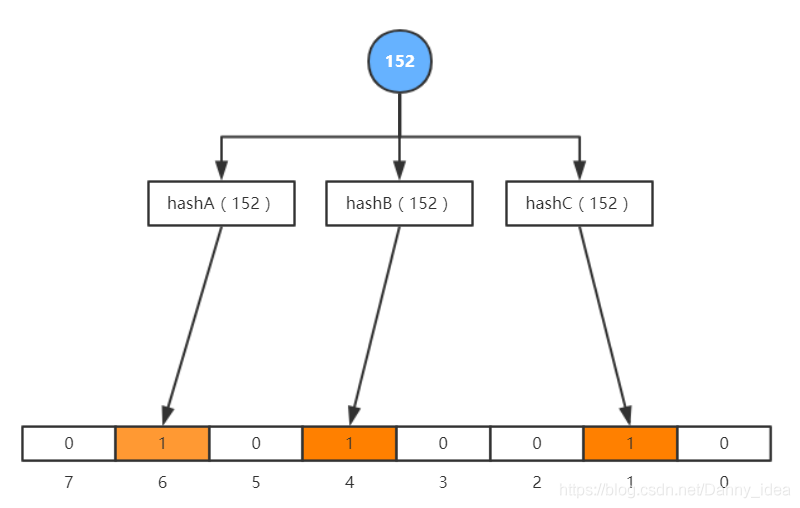
像上面的图注所说,我们可以利用多个hash算法减小碰撞概率,但只要存在碰撞,就一定会有错误判断,我们无法百分百确定一个值是否真的存在,但是hash算法的魅力在于,我不能确定你是否存在,但是我可以确定你是否真的不存在,这也就是以上的实现为什么称之“过滤器”的原因了。
高并发缓存设计策略
why cache??
如果读者是一个计算机专业的同学,cache这个词应该是能达到让耳朵起茧的出现频次。在计算机体系中,cache是介于cpu以及内存之间,用来缓和cpu和内存处理速度差距的那么一个和事佬;在OS中,page cache又是内存和IO之间的和事佬。
cache是个和事老??听着似乎怪怪的,但是也蛮形象的啦。
前面讲了大半截的算法理论,为了防止读者犯困,直接进入下半部分主题,高并发缓存设计。
即使是在软件层,我们同样需要这么一个和事老,从最简单的服务架构开始,通常我们在服务端发起请求,然后CURD某个关系型数据库例如Mysql。但是,类似这样的架构都需要有一个磁盘作为终端持久化,即使增加索引,使用B+树的这种数据结构进行优化查询,效率还是会卡在需要频繁寻道的IO上。这个时候,一个和事老的作用就十分明显了,我们会添加一些内存操作,来缓和IO处理速度慢带来的压力。cache is not a problem,how to use it is actually a problem。
缓存一致性问题
缓存处理的机制有以下几种:
cache aside; read through; write through; write behind caching;
缓存穿透问题
所谓的缓存击穿,就是当请求发出,而无法在缓存中读到数据时,请求还是会作用到database,这样的话,缓存减压的效果就不复存在了。
设想这么一个场景,如果一个用户,使用大流量恶意频繁地去查询一条数据库中没有的记录,一直击穿缓存,势必会把database打死,如何避免缓存击穿,这就是一个问题了。
有两种方案,第一种,在缓存中添加空值,如果在database中查询无果,我们大可以把值设置为null,防止下次再次访问数据库,这样做简单便捷,但是多少有些浪费空间。
第二种方案,就是使用布隆过滤器(点题),在cache与web服务器中间加一层布隆过滤器,对访问的key做记录,如此以来,同样可以解决缓存击穿的问题。
缓存雪崩问题
缓存雪崩发生于在某个时间点,缓存同时失效,例如缓存设置了失效时间,这会联动的导致大量缓存击穿问题。
加分布式锁是一种解决方案,只有拿到锁的请求才能访问database。但是这样治标不治本,当请求量过多时,大量的线程阻塞,也会把内存撑坏的。
预热数据,分散地设置失效时间,这样可以减少缓存雪崩发生的概率。
提高缓存可用性,cache的单点一样是会是缓存雪崩的隐患,大部分缓存中间件都提供高可用架构,如redis的主从+哨兵架构。