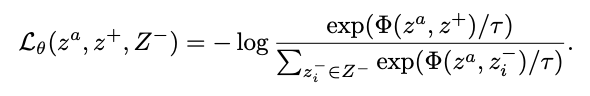来源:towardsdatascience
编辑:QJP、小智
【新智元导读】近日,两位Facebook的研究员小哥,提出了一种新的对比各种自监督学习框架的方法,结果显示SimCLR、CPC、AMDIM这些框架,彼此之间并无本质差异。
对比自监督学习将取代监督式深度学习主导地位的预言,已经「甚嚣尘上」。
Hinton大力推广的SimCLR就是其中一种。
对比自监督学习(CLS)是从无标签数据中选择和对比Anchor,Positive,Negative(APN)三种特征,学习到有用表征的方法。
近日,Facebook的两位研究员,使用一个新的框架来对比分析了目前三个主流的自监督学习算法:SimCLR、CPC、AMDIM。结果显示,尽管这些方法表面上看起来非常不同,但实际上他们互相之间只有微小的差异。
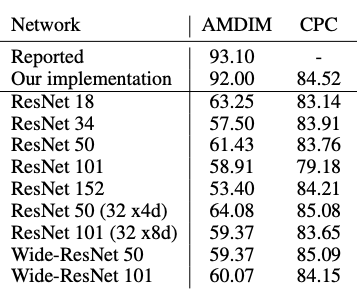
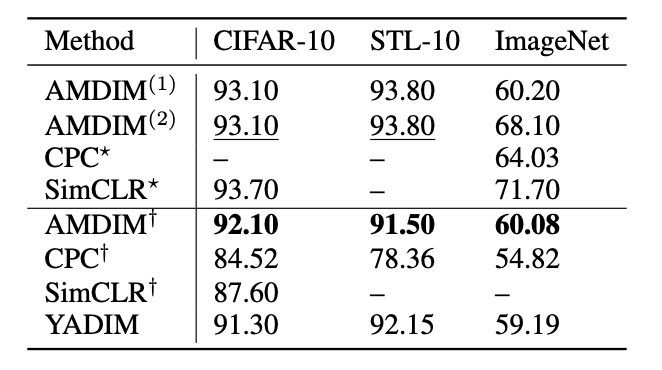
在有监督学习中,系统会给定一个输入x和一个标签y。而在自监督学习中,系统只给定了输入x,系统需要从输入x的一部分来预测输入的其他部分,输入既是source,也是target。俗话说,近朱者赤近墨者黑,机器学习中也有一种类似思想的算法就是聚类,对比学习与这种思想也是十分相似,通过三个要素来完成这个任务,即积极的,锚定的和消极的表征。对于一张图片,我们需要一张相似的图片来构建一个正例二元组,需要一个相似的图片和一张不相关的图片来构成一个负例三元组。 但是在自监督学习中,样本的标签y是不知道的,所以无法得知两张照片是否相似。如果假设每张图片都有自己的标签,那就可以通过各种方法来形成这些三元组。有了标签以后,就可以通过新提出的框架对各种CLS方法进行评估。下面,这个框架通过五种视角来对比CLS的各种方法,包括:在深度学习中,数据增强的目的就是为了扩充数据集,通过对输入图像进行翻转、对称、抖动、灰度等各种操作来增加数据的量。CPC除了使用抖动、灰度和翻转之外,还使用了一种新的变换,就是将原来的图像分割成Patches小块。通过CPC管道,可以生成多组正负样本对。AMDIM管道是通过执行完一些基本的翻转抖动等操作以后,对同一个图像使用两次数据增强管道,生成两个版本的图像。在他们的论文中,发现变换方式的选择对于方法最后的表现十分重要,事实上,这些方法的表现都是通过选择特定的变换来驱动的。对比CLS方法的第二个视角是编码器Encoder。CLS方法大多只是使用了不同宽度和深度的ResNet架构,通过消融实验可以发现,AMDIM不能够很好的泛化,而CPC受到编码器结构变化的影响较小。在消融实验中还有一个额外的发现,更宽的编码器在对比学习中的表现更好。这是「魔术」发生的地方,也是他们不同之处最大的地方。CPC通过在隐藏空间中预测未来信息来学习表征。把图片当成一条时间线,过去的信息在左上方,未来的信息在右下方。AMDIM是比较从CNN不同层的得到特征图之间的表征方式。这些表征来自于两个部分:一个图像的多个视图和CNN的中间层。SimCLR与AMDIM类似,但是进行了两个改进:一是只使用最后一个特征图,二是通过投影头运行特征映射并比较两个向量(类似于 CPC 上下文投影)。用来比较这些方法还有两种方式:相似性度量和损失函数。相似性度量使用了点积或者余弦距离,作者的实验表明,相似性的选择是无关紧要的。损失函数都使用了NCE损失。研究人员找到了一种新的方法来显示这个框架的用途,这种方法叫做Yet Another DIM (YADIM).3.对一个图像进行多个版本的编码,并使用最后一层的特征图进行比较。可以看出,尽管融合了AMDIM和CPC的模型效果最优,但是YADIM的效果也仅差了一点。SimCLR像AMDIM一样,通过最大化同一图像的两个视图之间的相似性来提取表征。SimCLR与AMDIM相似,但进行了一些小调整。首先,它使用非定制的通用ResNet。其次,它使用了经过修改的数据增强管道。第三,它使用投影头添加了参数化的相似性度量。最后,它为NCE损失增加了比例系数(τ)。数据增强管道:SimCLR的数据增强跟AMDIM类似,对同一输入使用两次随机扩充,包括随机调整大小和裁剪,随机水平翻转,颜色抖动,随机灰度和高斯模糊。编码器:SimCLR中的编码器是一个可变宽度和深度的ResNet,SimCLR中的ResNet使用批量归一化。表征抽取:R与AMDIM类似,但只使用最后一个特征图,二是通过投影头进行特征映射并比较相似度。相似性度量:SimCLR使用投影头z =fφ将表示向量从编码器映射到另一个向量空间,即fφ:R c→R c,将两个向量之间的余弦相似度作为评分。损失函数:SimCLR使用NCE损失来调整相似性评分的范围。这种损失将锚点和正样本聚集在一起,而将锚点和负样本分开。如果再分析下AMDIM和CPC就不难发现,这些对比自监督学习框架都是大同小异,只是从上面五个角度做了微小改动而已。这也是首个在同一标准下对三大框架进行对比的工作,让我们从一个更高的视角窥探了对比自监督学习的原理,也为后来者提供了改进现有对比学习方法的新思路。
但是在自监督学习中,样本的标签y是不知道的,所以无法得知两张照片是否相似。如果假设每张图片都有自己的标签,那就可以通过各种方法来形成这些三元组。有了标签以后,就可以通过新提出的框架对各种CLS方法进行评估。下面,这个框架通过五种视角来对比CLS的各种方法,包括:在深度学习中,数据增强的目的就是为了扩充数据集,通过对输入图像进行翻转、对称、抖动、灰度等各种操作来增加数据的量。CPC除了使用抖动、灰度和翻转之外,还使用了一种新的变换,就是将原来的图像分割成Patches小块。通过CPC管道,可以生成多组正负样本对。AMDIM管道是通过执行完一些基本的翻转抖动等操作以后,对同一个图像使用两次数据增强管道,生成两个版本的图像。在他们的论文中,发现变换方式的选择对于方法最后的表现十分重要,事实上,这些方法的表现都是通过选择特定的变换来驱动的。对比CLS方法的第二个视角是编码器Encoder。CLS方法大多只是使用了不同宽度和深度的ResNet架构,通过消融实验可以发现,AMDIM不能够很好的泛化,而CPC受到编码器结构变化的影响较小。在消融实验中还有一个额外的发现,更宽的编码器在对比学习中的表现更好。这是「魔术」发生的地方,也是他们不同之处最大的地方。CPC通过在隐藏空间中预测未来信息来学习表征。把图片当成一条时间线,过去的信息在左上方,未来的信息在右下方。AMDIM是比较从CNN不同层的得到特征图之间的表征方式。这些表征来自于两个部分:一个图像的多个视图和CNN的中间层。SimCLR与AMDIM类似,但是进行了两个改进:一是只使用最后一个特征图,二是通过投影头运行特征映射并比较两个向量(类似于 CPC 上下文投影)。用来比较这些方法还有两种方式:相似性度量和损失函数。相似性度量使用了点积或者余弦距离,作者的实验表明,相似性的选择是无关紧要的。损失函数都使用了NCE损失。研究人员找到了一种新的方法来显示这个框架的用途,这种方法叫做Yet Another DIM (YADIM).3.对一个图像进行多个版本的编码,并使用最后一层的特征图进行比较。可以看出,尽管融合了AMDIM和CPC的模型效果最优,但是YADIM的效果也仅差了一点。SimCLR像AMDIM一样,通过最大化同一图像的两个视图之间的相似性来提取表征。SimCLR与AMDIM相似,但进行了一些小调整。首先,它使用非定制的通用ResNet。其次,它使用了经过修改的数据增强管道。第三,它使用投影头添加了参数化的相似性度量。最后,它为NCE损失增加了比例系数(τ)。数据增强管道:SimCLR的数据增强跟AMDIM类似,对同一输入使用两次随机扩充,包括随机调整大小和裁剪,随机水平翻转,颜色抖动,随机灰度和高斯模糊。编码器:SimCLR中的编码器是一个可变宽度和深度的ResNet,SimCLR中的ResNet使用批量归一化。表征抽取:R与AMDIM类似,但只使用最后一个特征图,二是通过投影头进行特征映射并比较相似度。相似性度量:SimCLR使用投影头z =fφ将表示向量从编码器映射到另一个向量空间,即fφ:R c→R c,将两个向量之间的余弦相似度作为评分。损失函数:SimCLR使用NCE损失来调整相似性评分的范围。这种损失将锚点和正样本聚集在一起,而将锚点和负样本分开。如果再分析下AMDIM和CPC就不难发现,这些对比自监督学习框架都是大同小异,只是从上面五个角度做了微小改动而已。这也是首个在同一标准下对三大框架进行对比的工作,让我们从一个更高的视角窥探了对比自监督学习的原理,也为后来者提供了改进现有对比学习方法的新思路。
参考链接:
https://towardsdatascience.com/a-framework-for-contrastive-self-supervised-learning-and-designing-a-new-approach-3caab5d29619