
为什么我总写 Bug ?

总结常见的 Bug,帮大家避坑
写代码的过程中,难免会出现各种各样的 Bug。但实际上,很多 Bug 产生的原因是类似的。于是我总结了一些自己学编程时写 Bug 的诱因,希望大家引以为戒,在以后写代码的时候能更多注意。
常见 Bug 诱因汇总
中文编码
以java为例,下面是两行最最最简单的 Java 代码,上面的代码能运行,下面的代码会报错:
// 教程中的,能运行
System.out.println("Hello!");
// 我写的,会报错
System.out.println("Hello!");
明明我的代码和教程中的一模一样,为啥就是运行不了呢?

这是初学编程的同学总会遇到的一个问题,仔细一看,原来是行尾的分号误用成中文的了。。。
这种 Bug 往往都是由于刚开始学编程时不注意或不习惯输入法的切换而导致的,不过写一段时间代码后,就会好很多。而且一般编辑器是能够识别出错误位置的,根据报错信息去修改就好了。

此外,有时我不小心把项目文件名从英文改成了中文,也会出现乱码、无法读取文件之类的问题。
代码不规范
我以前不注意代码规范,觉得反正是我自己写的代码,写的快、写的爽就完事了,管那么多干嘛?
但后来因为变量命名太过随意,导致自己写的代码自己都看不懂,更别提其他人来阅读和协作开发了。

就连之前粗心拼错的变量名也根本不敢乱改,生怕漏改了一个地方,就会报找不到变量的错误了!

复制粘贴
复制粘贴可以说是我写代码时用的最多的技能了。
正常操作是:3 秒粘贴一个文件,随便改两下,代码能跑就行。
复制粘贴虽然好,但稍有不注意,可能就会漏修改一些变量名或注释,比如下图的 student :

这样的次数多了,往往会导致整个项目中出现很多相同的变量,其他同学要引入时,根本不知道应该选哪个!

硬编码
写代码时经常会用到一些常量,就是固定的值,比如网站的地址、最大最小值、机器的 IP 地址等。
有时,为了图省事,我就是不单独为这些值定义变量。哪里用到这些值,我就复制粘贴一遍,直接写死到代码里,比如:
// 连接数据库,IP 写死
DB db = new DB("10.0.0.1");
这样虽然简单粗暴,但假如哪一天这些死值需要修改了,就得从所有文件中一个个去找用到这些值的代码,再一个个改掉,不仅麻烦,还很容易出现遗漏,从而产生 Bug。
未释放资源
想从数据库中获取数据,就要先和数据库建立连接,占用连接资源。
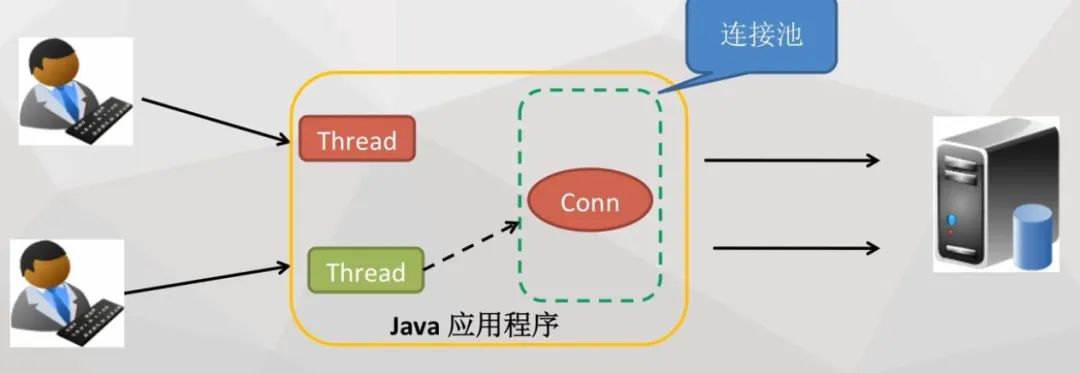
拿到需要的数据后呢,我就忘了要把资源进行释放(close),结果导致数据库连接很快被占满,其他程序想访问都访问不了,导致很多功能失效。
不仅是新手,甚至有几年编程经验的同学都可能会犯这个错,因为不释放资源并不会功能的可用性,而且不压测的话很难发现这个 Bug。
此外,还有 HTTP 连接、文件输入输出流,这些都是资源,都要注意是否需要手动释放,稍有不慎,就会导致资源泄露的 Bug。
圈复杂度过高
圈复杂度是衡量代码复杂度的标准,简单地说,if / else 分支越多,圈复杂度越大,往往表示代码越复杂。
记得我就写过一个特别复杂的逻辑,几十个分支语句一层套一层:
if (xxx) {
} else if (xxx) {
if (xxx) {
if (xxx) {
} else if (xxx) {
if (xxx) {
💩
}
}
}
}
起初是懒得去优化代码,但等到后来意识到情况不妙,想优化代码时,却发现这屎山已经动不得了。不光别人看不懂,我自己都看不懂了!
这种代码一旦要加增改逻辑,就很容易出现 Bug。所以建议在写复杂逻辑前先画流程图,理清楚代码、多写注释,还可以适当地用抽象、封装、设计模式之类的技术来减少代码的圈复杂度。
依赖冲突
依赖 是指我们项目中要用到的框架、类库等等别人写好的代码和工具。
像我以前做项目图省事,要用到什么库都往项目里塞,而且都用最新版本的。直到工作后才发现,对于一个大项目,很多人同时开发,往往要引入很多很多依赖,稍有不慎就产生 依赖冲突 。
比如我给类库 A 引入了类库 C 的 1.0 版本,类库 B 引入了类库 C 的 2.0 版本,那如果项目要同时引入类库 A 和类库 B,到底该用类库 C 的哪个版本呢?
依赖冲突的后果往往就是项目起不来,更严重的是直到项目执行到冲突的函数时才突发 Bug。
不区分环境
以前,我做网站时为了方便,在自己电脑上开发时,和已上线的项目用的是同一套环境,连接的是同一个数据库。
结果有一天,我就忘记了这个事,在开发时造了一条假的不行的假数据,还不小心上传了我的玉照:
结果大意了,这条数据实际上被插入到了线上的数据库中,导致线上几万个用户全都能看见。
这还是小事,万一你在本地开发时写了个 Bug,不小心把线上数据全给删了,那真的是要欲哭无泪了!
不做自测
企业开发中,测试是很重要的。一般情况下,除了测试同学要设计用例外、开发同学也要写单元测试来自测。
像我以前就很自信,自己写好的代码能跑就行,从来不测试,就是一把梭!

但进入企业工作后,我发现不写单元测试真的很容易出现各种细节问题。可能下个版本改了行代码,之前正常的功能就突然报错了。
而且越往后发现问题,修改的成本就越大,要花更多时间去排查和修改 Bug,加班也在所难免。
不做评估
以前在学校写代码,我一般就是学什么技术就用什么、会什么就用什么,也不去管是否能满足性能、数据量的要求。
进入大公司后,才意识到系统评估和技术选型的重要性。一般要评估系统的并发量、数据的量级、接口时延等,根据这些来选择合适的技术。
比如公司有一个千万数据量的项目,如果我不做评估和选型,无脑用 MySQL 数据库、并且不做任何优化,那这个系统估计分分钟挂掉。

自作主张
在学校的时候习惯了单兵作战,想改什么代码就改什么,也不去思考对现有系统、对其他系统的影响。
但在企业中,尤其是调用关系很复杂的链路系统中,如果你修改了接口的返回值,或者改变了接口的并发量、返回时长等。分分钟,依赖你接口的同事就都来登门拜谢了。

为了预防这种情况,建议整理下自己的接口依赖哪些接口、又被哪些接口调用。在你需要改动代码时,需要评估改动对于其他系统的影响,并且及时通知相关负责人。而不是自作主张,只关注自己的一亩三分地。
文档读不全
现在的技术框架啥的,一般都提供了非常详细的使用文档。
但我以前读文档时,为了追求效率,只要看到有自己需要的函数,立刻就直接复制过来用了,而不是选择把文档完整读完。
结果呢,因为盲目自信,很多文档中重点强调的注意事项没有看到,导致了很多傻不拉几的低级 Bug,还在网上到处搜解决方案,浪费时间。
版本号错误
读文档和看教程学技术可不一样,不要盲目追求最新的,而是要根据实际情况,选择和自己项目中引入一致的版本。
记得我刚开始跟着文档学编程时,写的很多 Bug 都是因为阅读文档前没有注意版本号,导致很多使用到的语法不是被淘汰了就是还不支持,然后就会怀疑人生。
不了解需求
写代码之前,一定要了解需求,就是要做什么?为什么要做?
否则就会像我刚进入公司时,有个功能点没搞懂,也不去问、不敢问产品同学,全靠自己自由发挥。就最后哪怕我的代码能运行、没 Bug,但并不是用户想要的,那不就表示:我程序的存在本身就是个 Bug?
不做设计
写代码和盖房子一样,一定要先想好怎么写代码,再去写。
尤其是业务流程复杂的时候,不要仗着自己聪明或者经验丰富,就不写方案、不做设计,而是直接打开编辑器就写代码。
这样做很容易遗漏一些要考虑的关键点,说不定直到最后,才发现有大问题,结果整段逻辑都要全部删掉重新写!效率反而更低。
最后,一定要记住!想学好编程,就要多写代码、多试错、多解决 Bug、多积累总结。几年之后,再来看当时的翻车经历,也是宝贵的财富啊。
往期推荐
今天因为您的点赞和在看,让我元气满满!
今天因为您的点赞和在看,让我元气满满!