
如何用Python下载百度指数的数据
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好我是小小明,今天给大家演示如何使用python直接采集百度指数的数据。
百度指数(Baidu Index) 是以百度海量网民行为数据为基础的数据分析平台,它能够能够告诉用户:某个关键词在百度的搜索规模有多大,一段时间内的涨跌态势以及相关的新闻舆论变化,关注这些词的网民是什么样的,分布在哪里,同时还搜了哪些相关的词。
百分十先生分享过如何使用uiautomation采集百度指数:百度指数 如何批量获取?
不过个人感觉这方法好像有点杀鸡用牛刀,对于网页使用selenium完全足以,当然对于专门针对selenium进行反爬检测的网页就需要特殊修改。
本文不演示如何使用UI自动化工具采集百度指数,为了采集更简单将直接读取并解析接口。
关于uiautomation,PC端的UI自动化可以查看教程:
https://blog.csdn.net/as604049322/article/details/121391639打开百度指数发现查看指数必须要先登录,比如我们对比一个python和Java最近一周的指数:
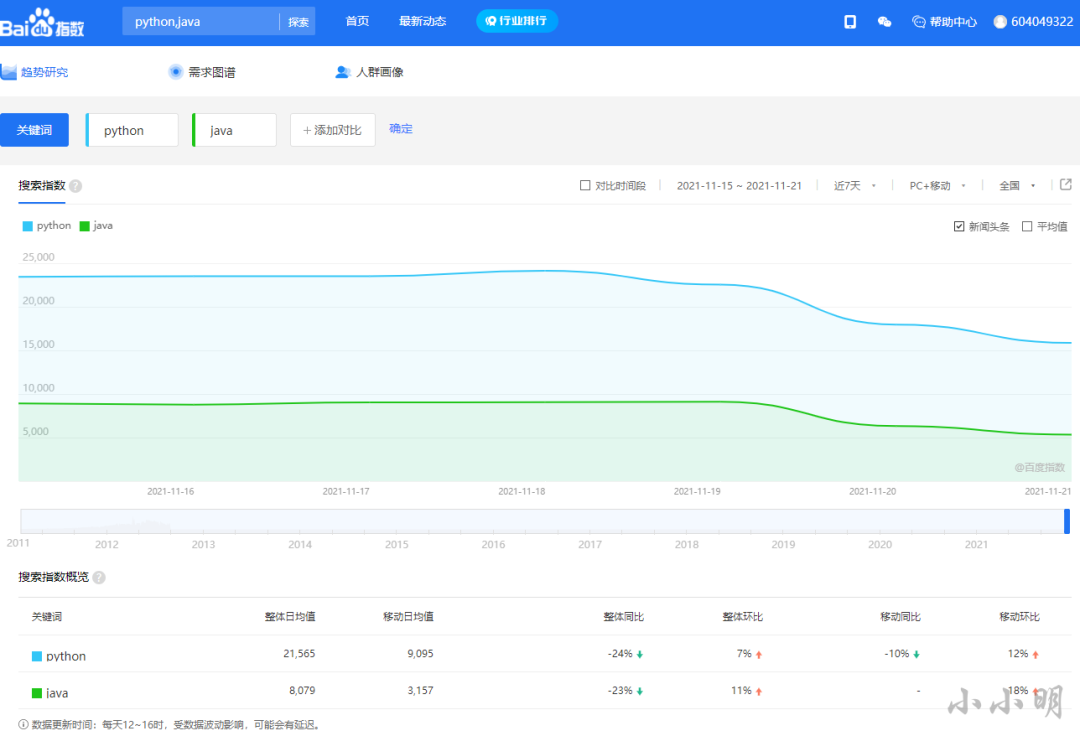
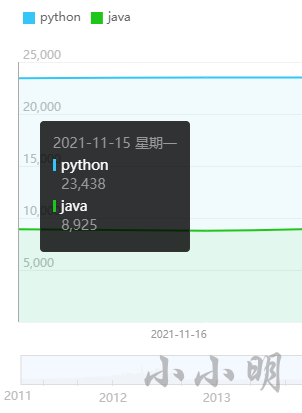
当鼠标移动到每天的坐标上时会显示当天的数据,例如:
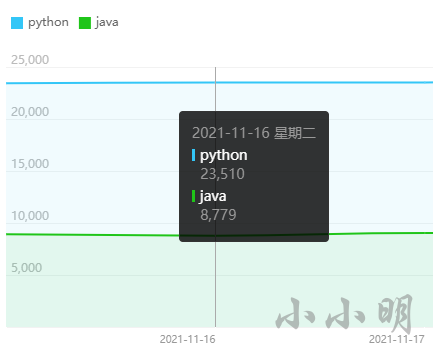
如果我们采用UI自动化的方式,至少得模拟移动到每天的坐标。
打开开发者工具,重新查询发现获取数据的接口:
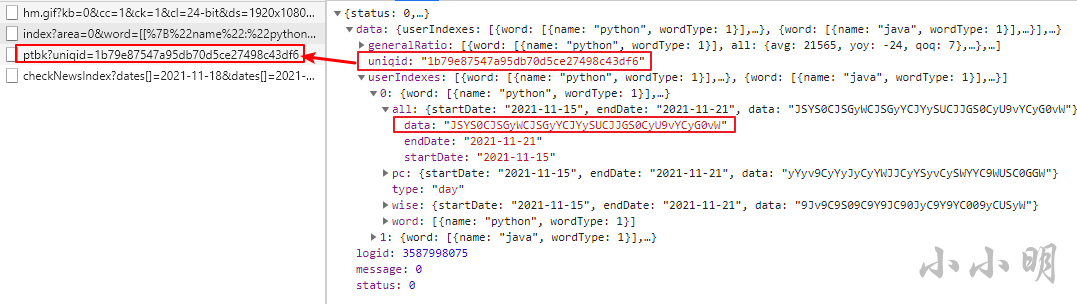
实际的指数数据就存储在这个data字段中,但是以某种加密方式加密了。
然后注意第二个接口的某个参数与当前接口返回的数据某个值一致。
此时我全局搜索decrypt,找到了加密函数:
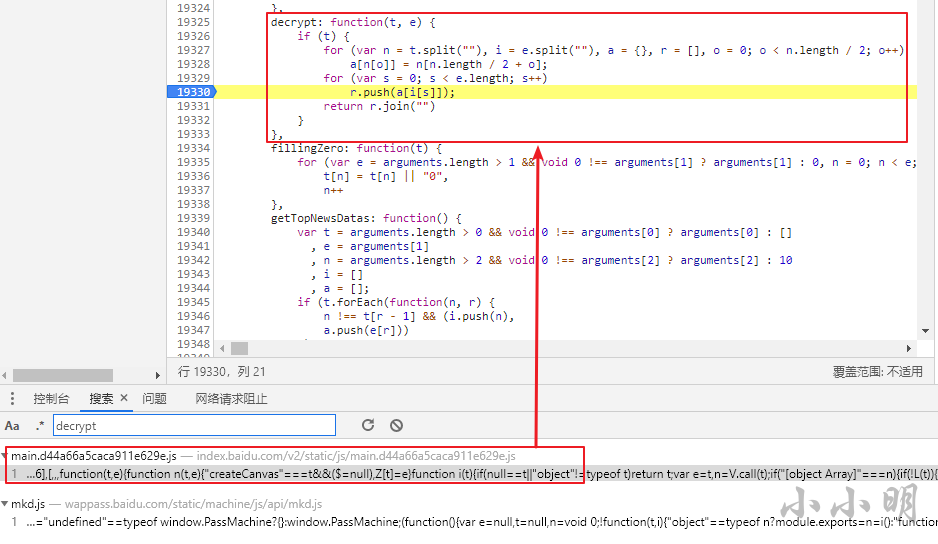
此时打上断点重新搜索,可以看到传入该函数的t参数与ptbk接口返回的值一致:
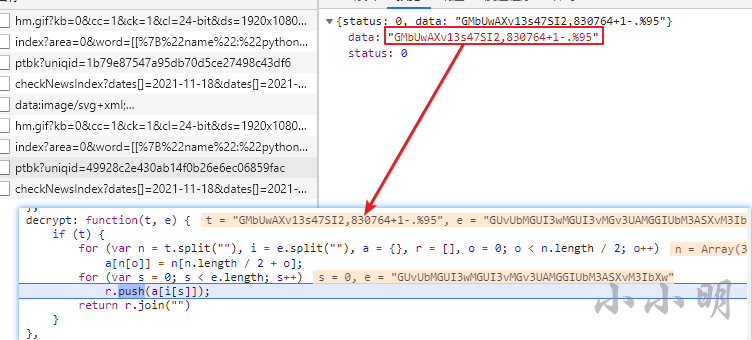
说明我们只需要将这段js翻译为python来解密加密数据即可。
下面我们总结一下指数数据获取的思路:
通过index接口获取uniqid和加密后的指数数据userIndexes
通过ptbk接口传入uniqid获取密钥key
通过解密函数根据密钥key解密userIndexes
下面我们分别用代码来实现,首先获取指数数据:
import requestsimport jsonheaders = {"Connection": "keep-alive","Accept": "application/json, text/plain, */*","User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36","Sec-Fetch-Site": "same-origin","Sec-Fetch-Mode": "cors","Sec-Fetch-Dest": "empty","Referer": "https://index.baidu.com/v2/main/index.html","Accept-Language": "zh-CN,zh;q=0.9",'Cookie': cookie,}words = '[[{"name":"python","wordType":1}],[{"name":"java","wordType":1}]]'start = '2021-11-15'end = '2021-11-21'url = f'http://index.baidu.com/api/SearchApi/index?area=0&word={words}&area=0&startDate={start}&endDate={end}'res = requests.get(url, headers=headers)data = res.json()['data']data
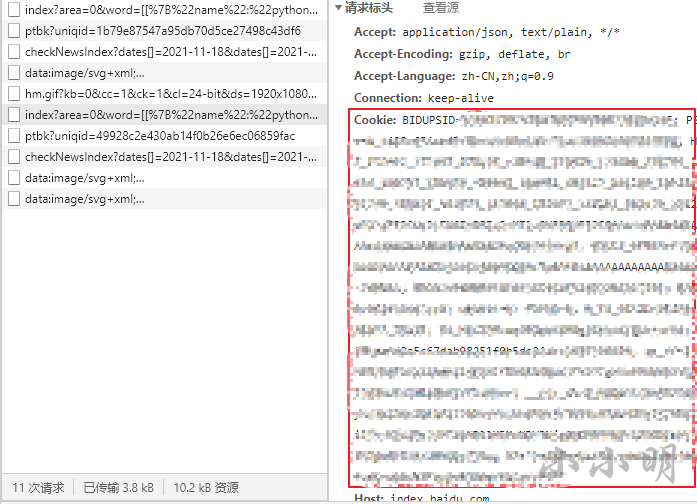
cookie需要在登录后复制粘贴获取,就是请求中的这段字符串(直接复制粘贴即可):
结果:
{'userIndexes': [{'word': [{'name': 'python', 'wordType': 1}],'all': {'startDate': '2021-11-15','endDate': '2021-11-21','data': 'WQ3Q-nWQ.yGnWQ.y3nW3yQsnWW.Q-nysXV3ny.-VG'},'pc': {'startDate': '2021-11-15','endDate': '2021-11-21','data': 'y3yVXny3yWyny3GWWny3QyVnyQG33nXGsQn-..G'},'wise': {'startDate': '2021-11-15','endDate': '2021-11-21','data': 'XWVXnXQ-XnX3XWnX-WynX3X3n--XynsQyG'},'type': 'day'},{'word': [{'name': 'java', 'wordType': 1}],'all': {'startDate': '2021-11-15','endDate': '2021-11-21','data': '-XW.n-ssXnXG3GnXG..nXyyGnVQyWn.QQQ'},'pc': {'startDate': '2021-11-15','endDate': '2021-11-21','data': '.VVVn.3Xsn.XX3n.-VWn.sW3nQG-snWVWQ'},'wise': {'startDate': '2021-11-15','endDate': '2021-11-21','data': 'QW.XnQW-WnQG3VnQyXQnQQ-VnQWW.nWsyG'},'type': 'day'}],'generalRatio': [{'word': [{'name': 'python', 'wordType': 1}],'all': {'avg': 21565, 'yoy': -24, 'qoq': 7},'pc': {'avg': 12470, 'yoy': -32, 'qoq': 3},'wise': {'avg': 9095, 'yoy': -10, 'qoq': 12}},{'word': [{'name': 'java', 'wordType': 1}],'all': {'avg': 8079, 'yoy': -23, 'qoq': 11},'pc': {'avg': 4921, 'yoy': -33, 'qoq': 6},'wise': {'avg': 3157, 'yoy': '-', 'qoq': 18}}],'uniqid': '5f0a123915325e28d9f055409955c9ad'}
这些数据中,wise表示移动端,all表示pc端+移动端。userIndexes是指数详情数据,generalRatio是概览数据。
下面我们只关心各个关键字的整体表现。
下面我们获取uniqid并获取ptbk:
uniqid = data['uniqid']res = requests.get(f'http://index.baidu.com/Interface/ptbk?uniqid={uniqid}', headers=headers)ptbk = res.json()['data']ptbk
'LV.7yF-s30WXGQn.65+1-874%2903,'下面我将下面这段Js代码翻译为python:
decrypt: function(t, e) {if (t) {for (var n = t.split(""), i = e.split(""), a = {}, r = [], o = 0; o < n.length / 2; o++)a[n[o]] = n[n.length / 2 + o];for (var s = 0; s < e.length; s++)r.push(a[i[s]]);return r.join("")}}
python代码:
def decrypt(ptbk, index_data):n = len(ptbk)//2a = dict(zip(ptbk[:n], ptbk[n:]))return "".join([a[s] for s in index_data])
然后我们遍历每个关键字解密出对应的指数数据:
for userIndexe in data['userIndexes']:name = userIndexe['word'][0]['name']index_data = userIndexe['all']['data']r = decrypt(ptbk, index_data)print(name, r)
python 23438,23510,23514,24137,22538,17964,15860java 8925,8779,9040,9055,9110,6312,5333
检查实际网页中的数据发现确实一致:
那么我们就可以轻松获取任意指定关键字的指数数据。下面我将其整体封装一下,完整代码为:
import requestsimport jsonfrom datetime import date, timedeltaheaders = {"Connection": "keep-alive","Accept": "application/json, text/plain, */*","User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36","Sec-Fetch-Site": "same-origin","Sec-Fetch-Mode": "cors","Sec-Fetch-Dest": "empty","Referer": "https://index.baidu.com/v2/main/index.html","Accept-Language": "zh-CN,zh;q=0.9",'Cookie': cookie,}def decrypt(ptbk, index_data):n = len(ptbk)//2a = dict(zip(ptbk[:n], ptbk[n:]))return "".join([a[s] for s in index_data])def get_index_data(keys, start=None, end=None):words = [[{"name": key, "wordType": 1}] for key in keys]words = str(words).replace(" ", "").replace("'", "\"")today = date.today()if start is None:start = str(today-timedelta(days=8))if end is None:end = str(today-timedelta(days=2))url = f'http://index.baidu.com/api/SearchApi/index?area=0&word={words}&area=0&startDate={start}&endDate={end}'print(words, start, end)res = requests.get(url, headers=headers)data = res.json()['data']uniqid = data['uniqid']url = f'http://index.baidu.com/Interface/ptbk?uniqid={uniqid}'res = requests.get(url, headers=headers)ptbk = res.json()['data']result = {}result["startDate"] = startresult["endDate"] = endfor userIndexe in data['userIndexes']:name = userIndexe['word'][0]['name']tmp = {}index_all = userIndexe['all']['data']index_all_data = [int(e) for e in decrypt(ptbk, index_all).split(",")]tmp["all"] = index_all_dataindex_pc = userIndexe['pc']['data']index_pc_data = [int(e) for e in decrypt(ptbk, index_pc).split(",")]tmp["pc"] = index_pc_dataindex_wise = userIndexe['wise']['data']index_wise_data = [int(e)for e in decrypt(ptbk, index_wise).split(",")]tmp["wise"] = index_wise_dataresult[name] = tmpreturn result
测试一下:
get_index_data(["python", "java"]){'startDate': '2021-11-15','endDate': '2021-11-21','python': {'all': [23438, 23510, 23514, 24137, 22538, 17964, 15860],'pc': [14169, 14121, 14022, 14316, 13044, 9073, 8550],'wise': [9269, 9389, 9492, 9821, 9494, 8891, 7310]},'java': {'all': [8925, 8779, 9040, 9055, 9110, 6312, 5333],'pc': [5666, 5497, 5994, 5862, 5724, 3087, 2623],'wise': [3259, 3282, 3046, 3193, 3386, 3225, 2710]}}
结果非常不错。
这篇文章出自小小明的博客,原文链接:
https://blog.csdn.net/as604049322/article/details/121490054也可以点击阅读原文前往。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~