
如何用 Python 买彩票
作者:hhh_Moon_hhh
https://blog.csdn.net/m0_54218263/article/details/116001249
一、需求介绍
二、以极速飞艇为例进行数据分析
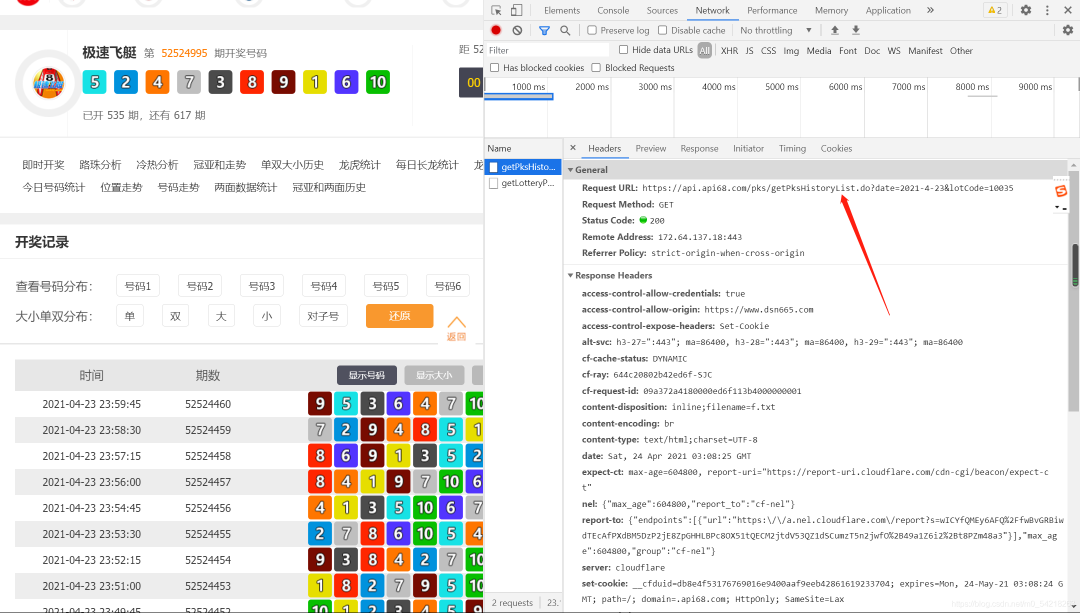
②、请求头
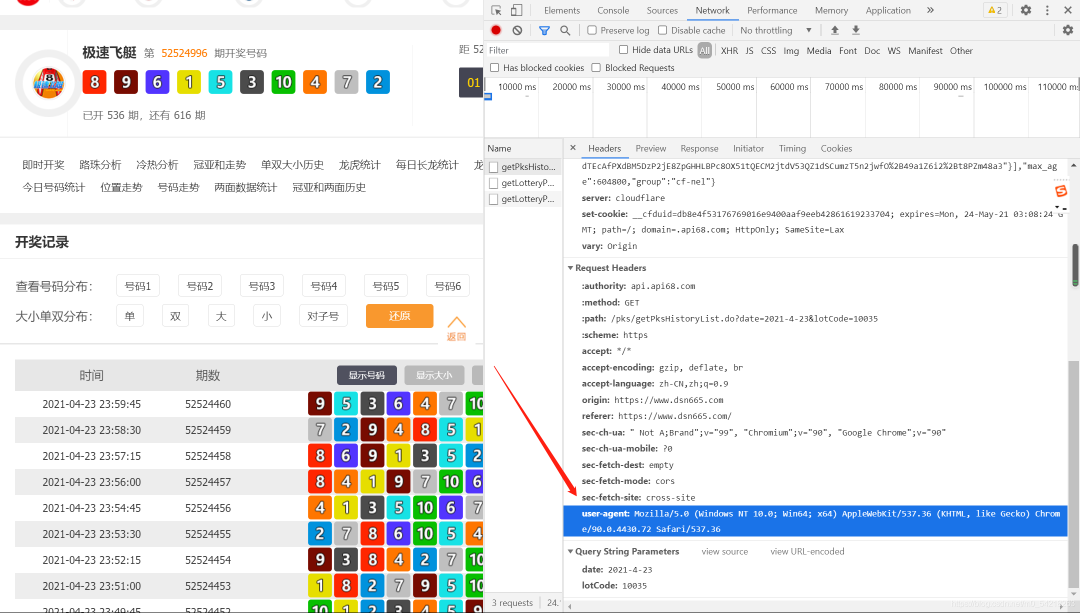
然后我们在程序中进行代码书写获取数据:

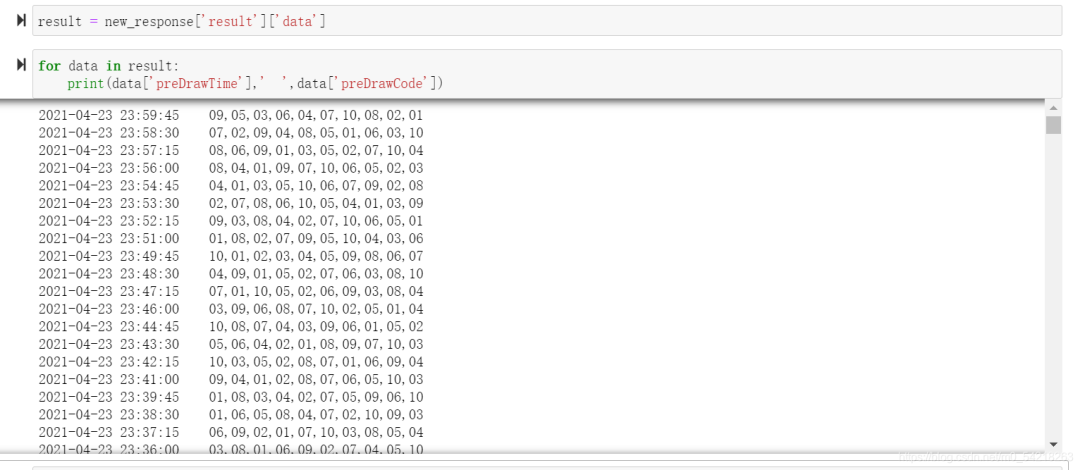
然后进行一定的预处理:
def reverse_list(lst):"""准换列表的先后顺序:param lst: 原始列表:return: 新的列表"""return [ele for ele in reversed(lst)]low_list = ["01", "02", "03", "04", "05"]# 设置比较小的数字的列表high_list = ["06", "07", "08", "09", "10"]# 设置比较大的数字的列表N = 0# 设置一个数字N来记录一共有多少期可以购买n = 0# 设置一个数字n来记录命中了多少期彩票record_number = 1# 设置记录数据的一个判断值list_data_number = []# 设置一个空的列表来存储一天之中的连续挂掉的期数dict_time_record = {}# 设置一个空的字典来存储连挂掉的期数满足所列条件的时间节点for k in range(1152):# 循环遍历所有的数据点if k < 1150:new_result1 = reverse_list(new_response["result"]["data"])[k]# 第一期数据new_result2 = reverse_list(new_response["result"]["data"])[k + 1]# 第二期数据new_result3 = reverse_list(new_response["result"]["data"])[k + 2]# 第三期数据data1 = new_result1['preDrawCode'].split(',')# 第一期数据data2 = new_result2['preDrawCode'].split(',')# 第二期数据data3 = new_result3['preDrawCode'].split(',')# 第三期数据for m in range(10):# 通过循环来判断是否满足购买的条件,并且实现一定的功能if m == 0:if data2[0] == data1[1]:# 如果相等就要结束循环N += 1# 可以购买的期数应该要自加一if (data2[0] in low_list and data3[0] in low_list) or (data2[0] in high_list and data3[0] in high_list):n += 1# 命中的期数应该要自加一# 如果命中了的话,本轮结束,开启下一轮list_data_number.append(record_number)if f"{record_number}" in dict_time_record.keys():# 如果已经有了这个键,那么值添加时间点dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])else:# 如果没有这个键,那么添加一个键值对,值为一个列表,而且初始化为当前的时间dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]record_number = 1# 初始化下一轮的开始else:record_number += 1# 如果没有命中的话,次数就应该要自加一break# 如果满足相等的条件就要结束循环elif m == 9:# 与上面差不多的算法if data2[9] == data1[8]:# 如果相等N += 1if (data2[9] in low_list and data3[9] in low_list) or (data2[9] in high_list and data3[9] in high_list):n += 1list_data_number.append(record_number)if f"{record_number}" in dict_time_record.keys():dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])else:dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]record_number = 1else:record_number += 1breakelse:# 与上面差不多的算法if data2[m] == data1[m + 1] or data2[m] == data1[m - 1]:# 如果相等N += 1if (data2[m] in low_list and data3[m] in low_list) or (data2[m] in high_list and data3[m] in high_list):n += 1list_data_number.append(record_number)if f"{record_number}" in dict_time_record.keys():dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])else:dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]record_number = 1else:record_number += 1breakprint(f"日期:{new_response['result']['data'][0]['preDrawTime'][:10]},总的梯子数为{N}个,一共有{n}次命中,一共有{N - n}次挂了")# 打印时间,以及,可以购买的期数,命中的期数,没有命中的期数list_data_number.sort()# 按照大小顺序来进行排序dict_record = {}# 设置空字典进行记录for i in list_data_number:if f"{i}" in dict_record.keys(): # 判断是否已经有了这个数字?dict_record[f"{i}"] += 1# 如果有的话,那么就会自加一else: # 如果没有的话,那么就会创建并且赋值等于 1dict_record[f"{i}"] = 1# 创建一个新的字典元素,然后进行赋值为 1for j in dict_record.keys():if (int(j) >= 6) and (int(j) < 15):# 实际的结果表明,我们需要的是大于等于6期的数据,而没有出现大于15的数据,因此有这样的一个关系式print(f"买{j}次才中奖的次数为{dict_record[j]}")# 打印相关信息print(dict_time_record[j])str0 = ""for letter in dict_time_record[j]:str0 += letterstr0 += ", "print(str0)# 打印相关信息
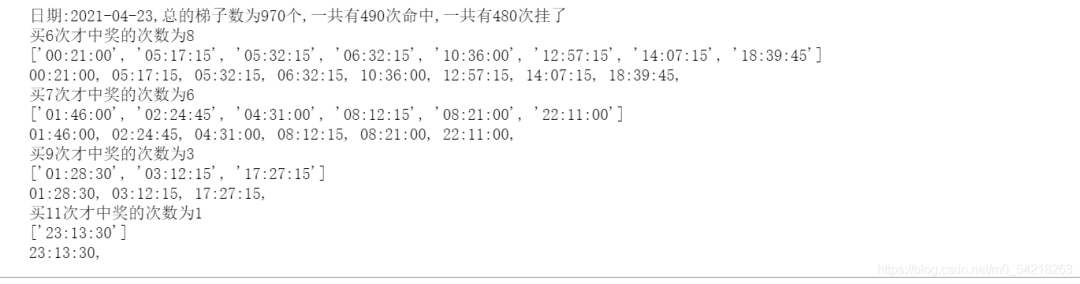
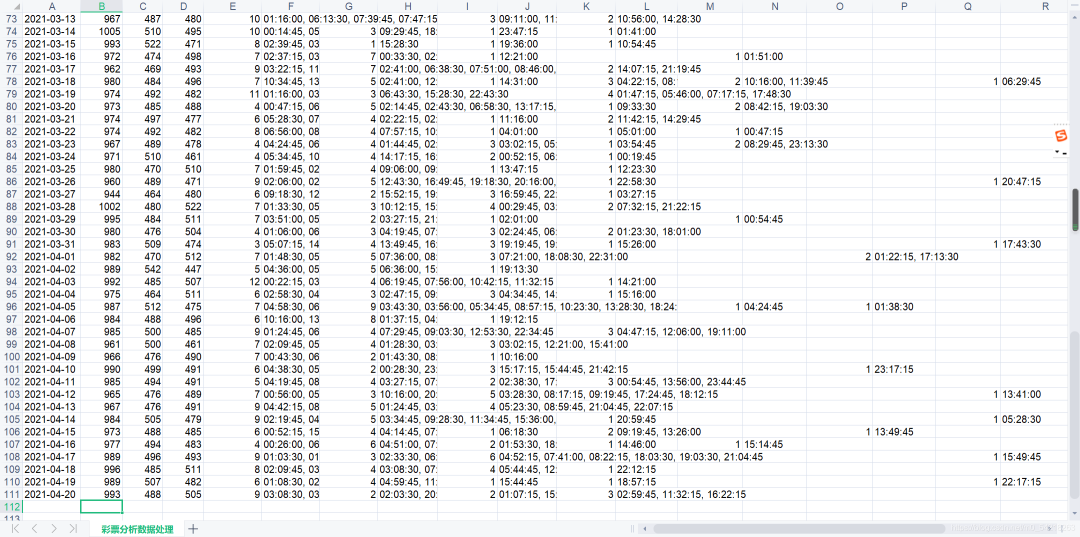
运行结果的展示如下图所示:
data_list = []for h in range(31):data_list.append(f'1-{h + 1}')for h in range(28):data_list.append(f'2-{h + 1}')for h in range(31):data_list.append(f'3-{h + 1}')for h in range(20):data_list.append(f'4-{h + 1}')
三、完整的代码展示
import requestsimport chardetimport jsonimport xlwt # excel 表格数据处理的对应模块def reverse_list(lst):"""准换列表的先后顺序:param lst: 原始列表:return: 新的列表"""return [ele for ele in reversed(lst)]data_list = []for h in range(31):data_list.append(f'1-{h + 1}')for h in range(28):data_list.append(f'2-{h + 1}')for h in range(31):data_list.append(f'3-{h + 1}')for h in range(20):data_list.append(f'4-{h + 1}')wb = xlwt.Workbook() # 创建 excel 表格sh = wb.add_sheet('彩票分析数据处理') # 创建一个 表单sh.write(0, 0, "日期")sh.write(0, 1, "梯子数目")sh.write(0, 2, "命中数目")sh.write(0, 3, "挂的数目")sh.write(0, 4, "6次中的数目")sh.write(0, 5, "6次中的时间")sh.write(0, 6, "7次中的数目")sh.write(0, 7, "7次中的时间")sh.write(0, 8, "8次中的数目")sh.write(0, 9, "8次中的时间")sh.write(0, 10, "9次中的数目")sh.write(0, 11, "9次中的时间")sh.write(0, 12, "10次中的数目")sh.write(0, 13, "10次中的时间")sh.write(0, 14, "11次中的数目")sh.write(0, 15, "11次中的时间")sh.write(0, 16, "12次中的数目")sh.write(0, 17, "12次中的时间")sh.write(0, 18, "13次中的数目")sh.write(0, 19, "13次中的时间")sh.write(0, 20, "14次中的数目")sh.write(0, 21, "14次中的时间")# wb.save('test4.xls')sheet_seek_position = 1# 设置表格的初始位置为 1for data in data_list:low_list = ["01", "02", "03", "04", "05"]high_list = ["06", "07", "08", "09", "10"]N = 0n = 0url = f'https://api.api68.com/pks/getPksHistoryList.do?date=2021-{data}&lotCode=10037'headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ''AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/90.0.4430.72 Safari/537.36'}response = requests.get(url=url, headers=headers)response.encoding = chardet.detect(response.content)['encoding']new_response = json.loads(response.text)sh.write(sheet_seek_position, 0, new_response['result']['data'][0]['preDrawTime'][:10])# 在表格的第一个位置处写入时间,意即:datarecord_number = 1 # 记录数据的一个判断值,设置为第一次,应该是要放在最外面的啦list_data_number = []# 设置一个空列表来存储一天之中的连续挂的期数dict_time_record = {}for k in range(1152):# record_number = 1,应该要放外面# 记录数据的一个判断值,设置为第一次if k < 1150:new_result1 = reverse_list(new_response["result"]["data"])[k]new_result2 = reverse_list(new_response["result"]["data"])[k + 1]new_result3 = reverse_list(new_response["result"]["data"])[k + 2]data1 = new_result1['preDrawCode'].split(',')data2 = new_result2['preDrawCode'].split(',')data3 = new_result3['preDrawCode'].split(',')for m in range(10):if m == 0:if data2[0] == data1[1]:N += 1if (data2[0] in low_list and data3[0] in high_list) or (data2[0] in high_list and data3[0] in low_list):n += 1# 如果命中了的话,本轮结束,开启下一轮list_data_number.append(record_number)if f"{record_number}" in dict_time_record.keys():dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])else:dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]# print(record_number)record_number = 1 # 初始化else:record_number += 1 # 没中,次数加一# 自加一breakelif m == 9:if data2[9] == data1[8]:N += 1if (data2[9] in low_list and data3[9] in high_list) or (data2[9] in high_list and data3[9] in low_list):n += 1list_data_number.append(record_number)if f"{record_number}" in dict_time_record.keys():dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])else:dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]# print(record_number)record_number = 1else:record_number += 1breakelse:if data2[m] == data1[m + 1] or data2[m] == data1[m - 1]:N += 1if (data2[m] in low_list and data3[m] in high_list) or (data2[m] in high_list and data3[m] in low_list):n += 1list_data_number.append(record_number)if f"{record_number}" in dict_time_record.keys():dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])else:dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]# print(record_number)record_number = 1else:record_number += 1breakprint(f"日期:{new_response['result']['data'][0]['preDrawTime'][:10]},总的梯子数为{N}个,一共有{n}次命中,一共有{N - n}次挂了")sh.write(sheet_seek_position, 1, N)sh.write(sheet_seek_position, 2, n)sh.write(sheet_seek_position, 3, N - n)# new_list_data_number = list_data_number.sort()list_data_number.sort()# 进行排序dict_record = {}# 设置空字典for i in list_data_number:if f"{i}" in dict_record.keys(): # 判断是否已经有了这个数字?dict_record[f"{i}"] += 1# 如果有的话,那么就会自加一else: # 如果没有的话,那么就会创建并且赋值等于 1dict_record[f"{i}"] = 1# 创建一个新的字典元素,然后进行赋值为 1# print(dict_record)# print(f"买彩票第几次才中奖?")# print(f"按照我们的规律买彩票的情况:")for j in dict_record.keys():if (int(j) >= 6) and (int(j) < 15):print(f"买{j}次才中奖的次数为{dict_record[j]}")print(dict_time_record[j])str0 = ""for letter in dict_time_record[j]:str0 += letterstr0 += ", "print(str0)sh.write(sheet_seek_position, 4 + (int(j) - 6) * 2, dict_record[j])# 写入几次sh.write(sheet_seek_position, 4 + (int(j) - 6) * 2 + 1, str0[:-2])# 注意这里应该要改为 -2# 写入几次对应的时间# print(j)sheet_seek_position += 1# 每次写完了以后,要对位置进行换行,换到下一行,从而方便下一行的写入# 保存wb.save('极速飞艇彩票分析结果.xls')
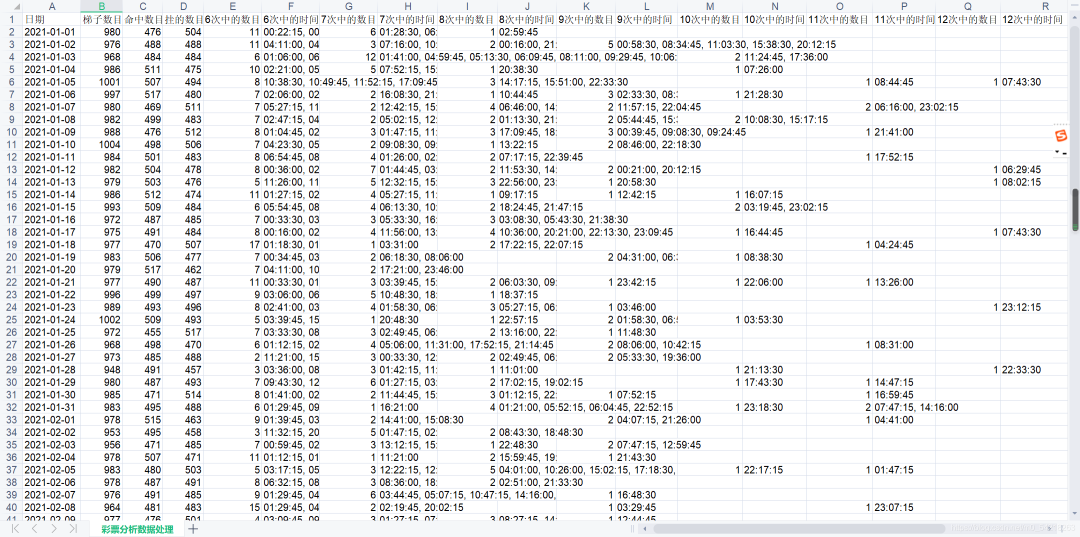
运行结果展示:
展示1、
展示2、
for m in range(10):if m == 0:if data2[0] == data1[1]:N += 1if (data2[0] in low_list and data3[0] in low_list) or (data2[0] in high_list and data3[0] in high_list):n += 1# 如果命中了的话,本轮结束,开启下一轮list_data_number.append(record_number)if f"{record_number}" in dict_time_record.keys():dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])else:dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]# print(record_number)record_number = 1 # 初始化else:record_number += 1 # 没中,次数加一# 自加一breakelif m == 9:if data2[9] == data1[8]:N += 1if (data2[9] in low_list and data3[9] in low_list) or (data2[9] in high_list and data3[9] in high_list):n += 1list_data_number.append(record_number)if f"{record_number}" in dict_time_record.keys():dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])else:dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]# print(record_number)record_number = 1else:record_number += 1breakelse:if data2[m] == data1[m + 1] or data2[m] == data1[m - 1]:N += 1if (data2[m] in low_list and data3[m] in low_list) or (data2[m] in high_list and data3[m] in high_list):n += 1list_data_number.append(record_number)if f"{record_number}" in dict_time_record.keys():dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])else:dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]# print(record_number)record_number = 1else:record_number += 1break
总结
最后,如果本文对你有帮助的话,请在留言区给个三连哦!
推荐阅读:
入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径
干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |
趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!
AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影
自动化办公: PDF提取图片和表格 | html一键保存pdf | Pdf转Word轻松搞定表格和水印! | Pdf转Word
年度爆款文案
点阅读原文,领廖雪峰视频资料!


评论