
【NLP】一文了解命名实体识别

导读:从1991年开始,命名实体识别逐渐开始走进人们的视野,在各评测会议的推动下,命名实体识别技术得到了极大地发展,从最初的基于规则和字典的方法,到现在热门的注意力机制、图神经网络等方法,命名实体识别已经在各开放数据集上取得了很高的准确率,但从自然语言处理实际应用的角度来看,命名实体识别技术依旧面临着很大的挑战。
什么是命名实体
1991年Rau等学者首次提出了命名实体识别任务,但命名实体(named entity,NE)作为一个明确的概念和研究对象,是在1995年11月的第六届MUC会议(MUC-6,the Sixth Message Understanding Conferences)上被提出的。当时的MUC-6和后来的MUC-7并未对什么是命名实体进行深入的讨论和定义,只是说明了需要标注的实体是“实体的唯一标识符(unique identifiers of entities)”,规定了NER评测需要识别的三大类(命名实体、时间表达式、数量表达式)、七小类实体,其中命名实体分为:人名、机构名和地名 。MUC 之后的ACE将命名实体中的机构名和地名进行了细分,增加了地理-政治实体和设施两种实体,之后又增加了交通工具和武器。CoNLL-2002、CoNLL-2003 会议上将命名实体定义为包含名称的短语,包括人名、地名、机构名、时间和数量,基本沿用了 MUC 的定义和分类,但实际的任务主要是识别人名、地名、机构名和其他命名实体 。SIGHAN Bakeoff-2006、Bakeoff-2007 评测也大多采用了这种分类。
除了主流的 NER 评测会议之外,也有学者专门就命名实体的含义和类型进行讨论,Petasis等认为命名实体就是专有名词(proper noun,PN),作为某人或某事的名称。Alfonseca 等从构建本体的角度,提出命名实体就是能用来解决特定问题的我们感兴趣的对象(objects)。Sekine 等认为通用的 7 小类命名实体并不能满足自动问答和信息检索应用的需求,提出了包含 150 种实体类别的扩展命名实体层级(extended named entity hierarchy),并在后来将类别种数增加到200个。
Borrega等从语言学角度对命名实体进行了详细的定义,规定只有名词和名词短语可以作为命名实体,同时命名实体必须是唯一且没有歧义的。比较特别的是,该研究将命名实体分为强命名实体(strong named entities,SNE)和弱命名实体(weak named entities,WNE),其中 SNE 对应词汇,而WNE对应短语,SNE 和 WNE 又可以细分为若干个小类。虽然该研究将每种类别都进行了详细的定义和阐释,但可能由于过于复杂而不利于计算机自动识别,因此该研究并未得到太多关注。
Nadeau等指出,“命名实体”中的“命名(named)”表示:只关心那些表示所指对象(referent)的严格指示词(rigid designators)。严格指示词的概念源于Kripke的观点,“对于一个对象 x,如果在所有存在 x 的世界中,指示词 d 都表示 x,而不表示别的对象,那么 x 的指示词 d 是严格的”。
Marrero等总结了前人对命名实体的定义,并将之归纳为语法类别、严格指示、唯一标识和应用目的四种类别。作者先假设每种类别都能作为定义命名实体的标准,再通过分析和举例等方式否定其作为标准的可行性。最后得出的结论是,应用方面的需求目的,是定义命名实体唯一可行的标准。
命名实体是命名实体识别的研究主体,而命名实体识别通常认为是从原始文本中识别有意义的实体或实体指代项的过程,即在文本中标识命名实体并划分到相应的实体类型中,通常实体类型包括人名、地名、组织机构名、日期等。举例说明,“当地时间 14 日下午,叙利亚一架军用直升机在阿勒坡西部乡村被一枚恶意飞弹击中。”这句话中包含的实体有:日期实体“14 日下午”、组织机构实体“叙利亚”、地名实体“阿勒坡西部乡村”、装备实体“军用直升机”和“飞弹”,如图1所示。

图1
命名实体识别的特点、难点、热点
特点
评判一个命名实体是否被正确识别包括两个方面:实体的边界是否正确;实体的类型是否标注正确。
对比中文和英文本身的语言特点,英语中的命名实体具有比较明显的形态标志,如人名、地名等实体中的每个词的第一个字母要大写等,而且,英文句子中的每个词都是通过空格自然分开,所以英文的实体边界识别相对中文来说比较容易,故而其任务的重点是确定实体的类型。相比于英文,中文里的汉字排列紧密,中文的句子由多个字符组成且单词之间没有空格,这一自身独特的语言特征增大了命名实体识别的难度。
难点
(1)领域命名实体识别局限性。目前命令实体识别只是在有限的领域和有限的实体类型中取得了较好的成绩,如针对新闻语料中的人名、地名、组织机构名的识别。但这些技术无法很好地迁移到其他特定领域中,如军事、医疗、生物、小语种语言等。一方面,由于不同领域的数据往往具有领域独特特征,如医疗领域中实体包括疾病、症状、药品等,而新闻领域的模型并不适合;另一方面,由于领域资源匮乏造成标注数据集缺失,导致模型训练很难直接开展。
(2)命名实体表述多样性和歧义性。自然语言的多样性和歧义性给自然语言理解带来了很大挑战,在不同的文化、领域、背景下,命名实体的外延有差异,是命名实体识别技术需要解决的根本问题。获取大量文本数据后,由于知识表示粒度不同、置信度相异、缺乏规范性约束等问题,出现命名实体表述多样、指代不明确等现象。
(3)命名实体的复杂性和开放性。传统的实体类型只关注一小部分类型,例如“人名”“地名”“组织机构名”,而命名实体的复杂性体现在实际数据中实体的类型复杂多样,需要识别细粒度的实体类型,将命名实体分配到更具体的实体类型中。目前业界还没有形成可遵循的严格的命名规范。命名实体的开放性是指命名实体内容和类型并非永久不变,会随着时间变化发生各种演变,甚至最终失效。命名实体的开放性和复杂性给实体分析带来了巨大的挑战,也是亟待解决的核心关键问题。
热点
通 过 调 研 近 三 年 来 ACL,AAAI,EMNLP,COLING,NAACL 等自然语言处理顶级会议中命名实体识别相关的论文,总结并选择了若干具有代表性的研究热点进行展开介绍,分别是匮乏资源命名实体识别、细粒度命名实体识别、嵌套命名实体识别、命名实体链接。
(1) 匮乏资源命名实体识别
命名实体识别通常需要大规模的标注数据集,例如标记句子中的每个单词,这样才能很好地训练模型。然而这种方法很难应用到标注数据少的领域,如生物、医学等领域。这是因为资源不足的情况下,模型无法充分学习隐藏的特征表示,传统的监督学习方法的性能会大大降低。
近来,越来越多的方法被提出用于解决低资源命名实体识别。一些学者采用迁移学习的方法,桥接富足资源和匮乏资源,命名实体识别的迁移学习方法可以分为两种:基于并行语料库的迁移学习和基于共享表示的迁移学习。利用并行语料库在高资源和低资源语言之间映射信息,Chen 和 Feng 等提出同时识别和链接双语命名实体。Ni 和 Mayhew 等创建了一个跨语言的命名实体识别系统,该系统通过将带注释的富足资源数据转换到匮乏资源上,很好地解决了匮乏资源问题。Zhou等采用双对抗网络探索高资源和低资源之间有效的特征融合,将对抗判别器和对抗训练集成在一个统一的框架中进行,实现了端到端的训练。
还有学者采用正样本-未标注样本学习方法(Positive-Unlabeled,PU),仅使用未标注数据和部分不完善的命名实体字典来实现命名实体识别任务。Yang 等学者采用 AdaSampling 方法,它最初将所有未标记的实例视为负实例,不断地迭代训练模型,最终将所有未标注的实例划分到相应的正负实例集中。Peng 等学者实现了 PU 学习方法在命名实体识别中的应用,仅使用未标记的数据集和不完备的命名实体字典来执行命名实体识别任务,该方法无偏且一致地估算任务损失,并大大减少对字典大小的要求。
因此,针对资源匮乏领域标注数据的缺乏问题,基于迁移学习、对抗学习、远监督学习等方法被充分利用,解决资源匮乏领域的命名实体识别难题,降低人工标注工作量,也是最近研究的重点。
(2)细粒度命名实体识别
为了智能地理解文本并提取大量信息,更精确地确定非结构化文本中提到的实体类型很有意义。通常这些实体类型在知识库的类型层次结构中可以形成类型路径 ,例如,牛顿可以按照如下类型的路径归类:物理学家 /科学家/人。知识库中的类型通常为层次结构的组织形式,即类型层次。
大多数命名实体识别研究都集中在有限的实体类型上,MUC-7只考虑了 3 类:人名、地名和组织机构名,CoNLL-03增加了其他类,ACE引入了地缘 政治、武器、车辆和设施 4 类 实 体,Ontonotes类型增加到 18 类,BBN有 29 种实体类型。Ling 和 Daniel 定义了一个细粒度的112 个标签集。
学者们在该领域已经进行了许多研究,通常学习每个实体的分布式表示,并应用多标签分类模型进行类型推断。Neelakantan 和 Chang利用各种信息构造实体的特征表示,如实体的文字描述、属性和类型,之后,学习预测函数来推断实体是否为某类型的实例。Yaghoobzadeh 等重点关注实体的名称和文本中的实体指代项,并为实体和类型对设计了两个评分模型。这些工作淡化了实体之间的内部关系,并单独为每个实体分配类型。Jin 等以实体之间的内部关系为结构信息,构造实体图,进一步提出了一种网络嵌入框架学习实体之间的相关性。最近的研究表明以卷积方式同时包含节点特征和图结构信息,将实体特征丰富到图结构将获益颇多。此外,还有学者考虑到由于大多数知识库都不完整,缺乏实体类型信息,例如在 DBpedia 数据库中 36.53%的实体没有类型信息。因此对于每个未标记的实体,Jin 等充分利用其文本描述、类型和属性来预测缺失的类型,将推断实体的细粒度类型问题转化成基于图的半监督分类问题,提出了使用分层多图卷积网络构造 3 种连通性矩阵,以捕获实体之间不同类型的语义相关性。
此外,实现知识库中命名实体的细粒度划分也是完善知识库的重要任务之一。细粒度命名实体识别现有方法大多是通过利用实体的固有特征(文本描述、属性和类型)或在文本中实体指代项来进行类型推断,最近有学者研究将知识库中的实体转换为实体图,并应用到基于图神经网络的算法模型中。
(3)嵌套命名实体识别
通常要处理的命名实体是非嵌套实体,但是在实际应用中,嵌套实体非常多。大多数命名实体识别会忽略嵌套实体,无法在深层次文本理解中捕获更细粒度的语义信息。如图2 所示,在“3 月 3 日,中国驻爱尔兰使馆提醒旅爱中国公民重视防控,稳妥合理加强防范。”句子中提到的中国驻爱尔兰使馆是一个嵌套实体,中国和爱尔兰均为地名,而中国驻爱尔兰使馆为组织机构名。普通的命名实体识别任务只会识别出其中的地名“中国”和“爱尔兰”,而忽略了整体的组织机构名。
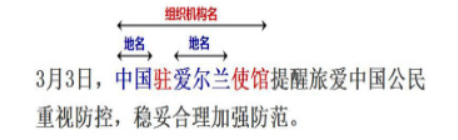
图2
学者们提出了多种用于嵌套命名实体识别的方法。Finkel 和 Manning基于 CRF 构建解析器,将每个命名实体作为解析树中的组成部分。Ju 等动态堆叠多个扁平命名实体识别层,并基于内部命名实体识别提取外部实体。如果较短的实体被错误地识别,这类方法可能会遭受错误传播问题的困扰。嵌套命名实体识别的另一系列方法是基于超图的方法。Lu和Roth 首次引入了超图,允许将边缘连接到不同类型的节点以表示嵌套实体。Muis 和Lu使用多图表示法,并引入分隔符的概念用于嵌套实体检测。但是这样需要依靠手工提取的特征来识别嵌套实体,同时遭受结构歧义问题的困扰。Wang 和 Lu提出了一种使用神经网络获取分布式特征表示的神经分段超图模型。Katiyar 和Cardie提出了一种基于超图的计算公式,并以贪婪学习的方式使用 LSTM 神经网络学习嵌套结构。这些方法都存在超图的虚假结构问题,因为它们枚举了代表实体的节点、类型和边界的组合。Xia等提出了 MGNER 架构,不仅可以识别句子中非重叠的命名实体,也可以识别嵌套实体,此外不同于传统的序列标注任务,它将命名实体识别任务分成两部分开展,首先识别实体,然后进行实体分类。
嵌套实体识别充分利用内部和外部实体的嵌套信息,从底层文本中捕获更细粒度的语义,实现更深层次的文本理解,研究意义重大。
(4)命名实体链接
命名实体链接主要目标是进行实体消歧,从实体指代项对应的多个候选实体中选择意思最相近的一个实体。这些候选实体可能选自通用知识库,例如维基百科、百度百科,也可能来自领域知识库,例如军事知识库、装备知识库。图3给出了一个实体链接的示例。短文本“美海军陆战队 F/A-18C战斗机安装了生产型 AN/APG-83 雷达”,其中实体指代项是“生产型 AN/APG-83 雷达”,该实体指代项在知识库中可能存在多种表示和含义,而在此处短文本,其正确的含义为“AN/APG-83 可扩展敏捷波束雷达”。

图3
实体链接的关键在于获取语句中更多的语义,通常使用两种方法。一种是通过外部语料库获取更多的辅助信息,另一种是对本地信息的深入了解以获取更多与实体指代项相关的信息。Tan 等提出了一种候选实体选择方法,使用整个包含实体指代项的句子而不是单独的实体指代项来搜索知识库,以获得候选实体集,通过句子检索可以获取更多的语义信息,并获得更准确的结果。Lin 等寻找更多线索来选择候选实体,这些线索被视为种子实体指代项,用作实体指代项与候选实体的桥梁。Dai 等使用社交平台 Yelp 的特征信息,包括用户名、用户评论和网站评论,丰富了实体指代项相关的辅助信息,实现了实体指代项的歧义消除。因此,与实体指代项相关的辅助信息将通过实体指代项和候选实体的链接实现更精确的歧义消除。
另一些学者使用深度学习研究文本语义。Francis-Landau 等使用卷积神经网络学习文本的表示形式,然后获得候选实体向量和文本向量的余弦相似度得分。Ganea 和 Hofmann专注于文档级别的歧义消除,使用神经网络和注意力机制来深度表示实体指代项和候选实体之间的关系。Mueller和 Durrett将句子左右分开,然后分别使用门控循环单元和注意力机制,获得关于实体指代项和候选实体的分数。Ouyang 等提出一种基于深度序列匹配网络的实体链接算法,综合考虑实体之间的内容相似度和结构相似性,从而帮助机器理解底层数据。目前,在实体链接中使用深度学习方法是一个热门的研究课题。
命名实体识别的研究方法
命名实体识别从早期基于词典和规则的方法,到传统机器学习的方法,后来采用基于深度学习的方法,一直到当下热门的注意力机制、图神经网络等研究方法,命名实体识别技术路线随着时间在不断发展,技术发展趋势如图4所示。
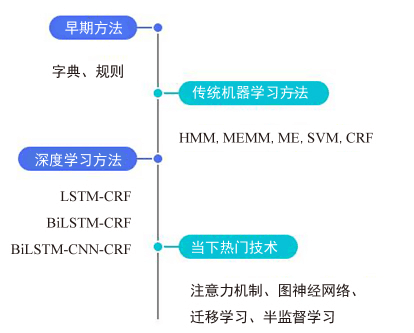
图4
基于规则和字典的方法
基于规则和字典的方法是最初代的命名实体识别使用的方法,这些方法多采用由语言学家通过人工方式,依据数据集特征构建的特定规则模板或者特殊词典。规则包括关键词、位置词、方位词、中心词、指示词、统计信息、标点符号等。词典是由特征词构成的词典和外部词典共同组成,外部词典指已有的常识词典。制定好规则和词典后,通常使用匹配的方式对文本进行处理以实现命名实体识别。
Rau等学者首次提出将人工编写的规则与启发式想法相结合的方法,实现了从文本中自动抽取公司名称类型的命名实体。这种基于规则的方法局限性非常明显,不仅需要消耗巨大的人力劳动,且不容易在其他实体类型或数据集扩展,无法适应数据的变化情况。
基于传统机器学习的方法
在基于机器学习的方法中,命名实体识别被当作是序列标注问题。与分类问题相比,序列标注问题中当前的预测标签不仅与当前的输入特征相关,还与之前的预测标签相关,即预测标签序列之间是有强相互依赖关系的。采用的传统机器学习方法主要包括:隐马尔可夫模型(Hidden Markov Model,HMM)、最大熵(Maximum Entropy,ME)、最大熵马尔可夫模型( Maximum Entropy Markov Model,MEMM)、支持向量机(Support Vector Machine,SVM)、条件随机场 ( Conditional Random Fields,CRF) 等。
在这 5 种学习方法中,ME 结构紧凑,具有较好的通用性,其主要缺点是训练时间复杂性非常高,甚至导致训练代价难以承受,另外由于需要明确的归一化计算,导致开销比较大。HMM 对转移概率和表现概率直接建模,统计共现概率。ME 和 SVM 在正确率上要 HMM 高一些,但是 HMM 在训练和识别时的速度要快一些。MEMM 对转移概率和表现概率建立联合概率,统计条件概率,但由于只在局部做归一化容易陷入局部最优。CRF 模型统计全局概率,在归一化时考虑数据在全局的分布,而不是仅仅在局部进行归一化,因此解决了 MEMM 中标记偏置的问题。在传统机器学习中,CRF 被看作是命名实体识别的主流模型,优点在于在对一个位置进行标注的过程中 CRF 可以利用内部及上下文特征信息。
还有学者通过调整方法的精确率和召回率对传统机器学习进行改进。Culotta 和 McCallum计算从 CRF 模型提取的短语的置信度得分,将这些得分用于对实体识别进行排序和过滤。Carpenter 从HMM 计算短语级别的条件概率,并尝试通过降低这些概率的阈值来增加对命名实体识别的召回率。对给定训练好的 CRF 模型,Minkov 等学者通过微调特征的权重来判断是否是命名实体,更改权重可能会奖励或惩罚 CRF 解码过程中的实体识别。
基于深度学习的方法
随着深度学习的不断发展,命名实体识别的研究重点已转向深层神经网络(Deep Neural Network,DNN),该技术几乎不需要特征工程和领域知识 。Collobert 等学者首次提出基于神经网络的命名实体识别方法,该方法中每个单词具有固定大小的窗口,但未能考虑长距离单词之间的有效信息。为了克服这一限制,Chiu 和 Nichols提出了一种双向 LSTM-CNNs 架构,该架构可自动检测单词和字符级别的特征。Ma 和 Hovy进一步将其扩展到 BiLSTM-CNNs-CRF 体系结构,其中添加了 CRF 模块以优化输出标签序列。Liu 等提出了一种称为 LM-LSTM-CRF 的任务感知型神经语言模型,将字符感知型神经语言模型合并到一个多任务框架下,以提取字符级向量化表示。这些端到端模型具备从数据中自动学习的功能,可以很好地识别新实体。
部分学者将辅助信息和深度学习方法混合使用进行命名实体识别。Liu 等在混合半马尔可夫条件随机场(Hybrid Semi-Markov Conditional Random Fields,HSCRFs) 的体系结构的基础上加入了Gazetteers 地名词典,利用实体在地名词典的匹配结果作为命名实体识别的特征之一。一些研究尝试在标签级别跨数据集共享信息,Greenberg等提出了一个单一的 CRF 模型,使用异构标签集进行命名实体识别,此方法对平衡标签分布的领域数据集有实用性。Augenstein 等使用标签向量化表示在任务之间进一步播信息。Beryozkin 等建议使用给定的标签层次结构共同学习一个在所有标签集中共享其标签层的神经网络,取得了非常优异的性能。
近年来,在基于神经网络的结构上加入注意力机制、图神经网络、迁移学习、远监督学习等热门研究技术也是目前的主流研究方向。
公开的数据集和评价指标
公开的数据集
常用的命名实体识别数据集有 CoNLL 2003,CoNLL 2002,ACE 2004,ACE 2005 等。数据集的具体介绍如下:
① CoNLL 2003 数据集包括1393 篇英语新闻文章和 909 篇德语新闻文章,英语语料库是免费的,德国语料库需要收费。英语语料取自路透社收集的共享任务数据集。数据集中标注了 4 种实体类型:PER,LOC,ORG,MISC。
② CoNLL 2002 数据集是从西班牙 EFE 新闻机构收集的西班牙共享任务数据集。数据集标注了 4 种实体类型:PER,LOC,ORG,MISC。
③ ACE 2004 多语种训练语料库版权属于语言数据联盟(Linguistic Data Consortium,LDC),ACE2004多语言培训语料库包含用于2004年自动内容提取(ACE)技术评估的全套英语、阿拉伯语和中文培训数据。语言集由为实体和关系标注的各种类型的数据组成。
④ ACE2005多语种训练语料库版权属于LDC,包含完整的英语、阿拉伯语和汉语训练数据,数据来源包括:微博、广播新闻、新闻组、广播对话等,可以用来做实体、关系、事件抽取等任务。
⑤ OntoNotes5.0数据集版权属于LDC,由1745K英语、900K中文和300 K阿拉伯语文本数据组成,OntoNotes5.0的数据来源也多种多样,来自电话对话、新闻通讯社、广播新闻、广播对话和博客等。实体被标注为PERSON,ORGANIZATION,LOCATION 等18个类型。
⑥ MUC 7 数据集是发布的可以用于命名实体识别任务,版权属于LDC,下载需要支付一定费用。数据取自北美新闻文本语料库的新闻标题,其中包含190K训练集、64K测试集。
⑦ Twitter 数据集是由 Zhang 等提供,数据收集于 Twitter,训练集包含了 4 000 推特文章,3 257 条推特用户测试。该数据集不仅包含文本信息还包含了图片信息。
大部分数据集的发布官方都直接给出了训练集、验证集和测试集的划分。同时不同的数据集可能采用不同的标注方法,最常见的标注方法有 IOB,BIOES,Markup,IO,BMEWO 等,下面详细介绍几种常用的标注方法(如图5所示):
(1)IOB 标注法,是 CoNLL 2003 采用的标注法,I 表示内部,O 表示外部,B 表示开始。如若语料中某个词标注 B/I-XXX,B/I 表示这个词属于命名实体的开始或内部,即该词是命名实体的一部分,XXX表示命名实体的类型。当词标注 O 则表示属于命名实体的外部,即它不是一个命名实体。
(2)BIOES 标注法,是在 IOB 方法上的扩展,具有更完备的标注规则。其中 B 表示这个词处于一个命名实体的开始,I 表示内部,O 表示外部,E 表示这个词处于一个实体的结束,S 表示这个词是单独形成一个命名实体。BIOES 是目前最通用的命名实体标注方法。
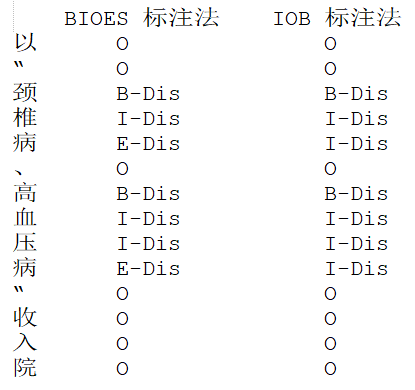
图5
评价指标
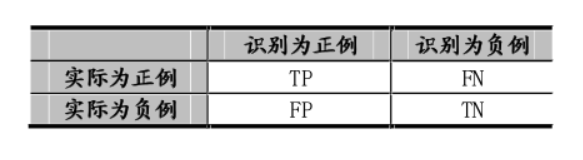
对命名实体识别系统的发展来说,对系统的全面评估是必不可少的,许多系统被要求根据它们标注文本的能力来对系统进行排序。目前,通常采用的评估指标主要有查准率(Precision,亦称准确率)、查全率(Recall,亦称召回率)和 F1值,它们的定义如下:
表1
查准率P和查全率R分别定义为
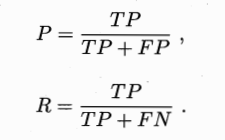
查准率和查全率是一对矛盾的度量,一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。通常只有在一些简单的任务中,才可能使查全率和查准率都很高。为了综合考虑查全率和查准率,引入它们的调和平均F1值,F1值的定义如下:
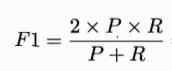
注:本文旨在学习和分享,如内容上有不到之处,欢迎后台批评指正。
参考文献:
[1]陈曙东,欧阳小叶.命名实体识别技术综述[J].无线电通信技术,2020,46(03):251-260.
[2]刘浏,王东波.命名实体识别研究综述[J].情报学报,2018,37(03):329-340.
[3]孙镇,王惠临.命名实体识别研究进展综述[J].现代图书情报技术,2010(06):42-47.
[4]周志华.机器学习[M].北京:清华大学出版社,2016:30-32.
往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群请扫码进群(如果是博士或者准备读博士请说明):