
Redis 为什么用单线程模型?终于知道了!

Java技术栈
www.javastack.cn
关注阅读更多优质文章
Redis 作为广为人知的内存数据库,在玩具项目和复杂的工业级别项目中都看到它的身影,然而 Redis 却是使用单线程模型进行设计的,这与很多人固有的观念有所冲突,为什么单线程的程序能够抗住每秒几百万的请求量呢?
这也是我们今天要讨论的问题之一。
除此之外,Redis 4.0 之后的版本却抛弃了单线程模型这一设计,原本使用单线程运行的 Redis 也开始选择性使用多线程模型,这一看似有些矛盾的设计决策是今天需要讨论的另一个问题。
“However with Redis 4.0 we started to make Redis more threaded. For now this is limited to deleting objects in the background, and to blocking commands implemented via Redis modules. For the next releases, the plan is to make Redis more and more threaded.
概述
就像在介绍中说的,这一篇文章想要讨论的两个与 Redis 有关的问题就是:
为什么 Redis 在最初的版本中选择单线程模型?
为什么 Redis 在 4.0 之后的版本中加入了多线程的支持?
这两个看起来有些矛盾的问题实际上并不冲突,我们会分别阐述对这个看起来完全相反的设计决策作出分析和解释,不过在具体分析它们的设计之前,我们先来看一下不同版本 Redis 顶层的设计:
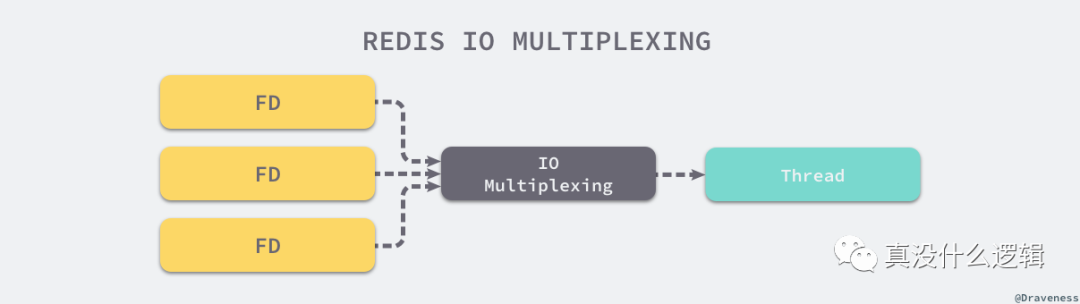
Redis 作为一个内存服务器,它需要处理很多来自外部的网络请求,它使用 I/O 多路复用机制同时监听多个文件描述符的可读和可写状态,一旦受到网络请求就会在内存中快速处理,由于绝大多数的操作都是纯内存的,所以处理的速度会非常地快。
在 Redis 4.0 之后的版本,情况就有了一些变动,新版的 Redis 服务在执行一些命令时就会使用『主处理线程』之外的其他线程,例如 UNLINK、FLUSHALL ASYNC、FLUSHDB ASYNC 等非阻塞的删除操作。
设计
无论是使用单线程模型还是多线程模型,这两个设计上的决定都是为了更好地提升 Redis 的开发效率、运行性能,想要理解两个看起来矛盾的设计决策,我们首先需要重新梳理做出决定的上下文和大前提,从下面的角度来看,使用单线程模型和多线程模型其实也并不矛盾。
虽然 Redis 在较新的版本中引入了多线程,不过是在部分命令上引入的,其中包括非阻塞的删除操作,在整体的架构设计上,主处理程序还是单线程模型的;由此看来,我们今天想要分析的两个问题可以简化成:
为什么 Redis 服务使用单线程模型处理绝大多数的网络请求?
为什么 Redis 服务增加了多个非阻塞的删除操作,例如:
UNLINK、FLUSHALL ASYNC和FLUSHDB ASYNC?
接下来的两个小节将从多个角度分析这两个问题。
单线程模型
Redis 从一开始就选择使用单线程模型处理来自客户端的绝大多数网络请求,这种考虑其实是多方面的,作者分析了相关的资料,发现其中最重要的几个原因如下:
使用单线程模型能带来更好的可维护性,方便开发和调试;
使用单线程模型也能并发的处理客户端的请求;
Redis 服务中运行的绝大多数操作的性能瓶颈都不是 CPU;
上述三个原因中的最后一个是最终使用单线程模型的决定性因素,其他的两个原因都是使用单线程模型额外带来的好处,在这里我们会按顺序介绍上述的几个原因。
可维护性
可维护性对于一个项目来说非常重要,如果代码难以调试和测试,问题也经常难以复现,这对于任何一个项目来说都会严重地影响项目的可维护性。多线程模型虽然在某些方面表现优异,但是它却引入了程序执行顺序的不确定性,代码的执行过程不再是串行的,多个线程同时访问的变量如果没有谨慎处理就会带来诡异的问题。
在网络上有一个调侃多线程模型的段子,就很好地展示了多线程模型带来的潜在问题:竞争条件 (race condition) —— 如果计算机中的两个进程(线程同理)同时尝试修改一个共享内存的内容,在没有并发控制的情况下,最终的结果依赖于两个进程的执行顺序和时机,如果发生了并发访问冲突,最后的结果就会是不正确的。
“Some people, when confronted with a problem, think, “I know, I’ll use threads,” and then two they hav erpoblesms.
引入了多线程,我们就必须要同时引入并发控制来保证在多个线程同时访问数据时程序行为的正确性,这就需要工程师额外维护并发控制的相关代码,例如,我们会需要在可能被并发读写的变量上增加互斥锁:
var (
mu Mutex // cost
data int
)
// thread 1
func() {
mu.Lock()
data += 1
mu.Unlock()
}
// thread 2
func() {
mu.Lock()
data -= 1
mu.Unlock()
}
在访问这些变量或者内存之前也需要先对获取互斥锁,一旦忘记获取锁或者忘记释放锁就可能会导致各种诡异的问题,管理相关的并发控制机制也需要付出额外的研发成本和负担。
并发处理
使用单线程模型也并不意味着程序不能并发的处理任务,Redis 虽然使用单线程模型处理用户的请求,但是它却使用 I/O 多路复用机制并发处理来自客户端的多个连接,同时等待多个连接发送的请求。
在 I/O 多路复用模型中,最重要的函数调用就是 select 以及类似函数,该方法的能够同时监控多个文件描述符(也就是客户端的连接)的可读可写情况,当其中的某些文件描述符可读或者可写时,select 方法就会返回可读以及可写的文件描述符个数。
使用 I/O 多路复用技术能够极大地减少系统的开销,系统不再需要额外创建和维护进程和线程来监听来自客户端的大量连接,减少了服务器的开发成本和维护成本。
性能瓶颈
最后要介绍的其实就是 Redis 选择单线程模型的决定性原因 —— 多线程技术的能够帮助我们充分利用 CPU 的计算资源来并发的执行不同的任务,但是 CPU 资源往往都不是 Redis 服务器的性能瓶颈。哪怕我们在一个普通的 Linux 服务器上启动 Redis 服务,它也能在 1s 的时间内处理 1,000,000 个用户请求。
“It's not very frequent that CPU becomes your bottleneck with Redis, as usually Redis is either memory or network bound. For instance, using pipelining Redis running on an average Linux system can deliver even 1 million requests per second, so if your application mainly uses O(N) or O(log(N)) commands, it is hardly going to use too much CPU.
如果这种吞吐量不能满足我们的需求,更推荐的做法是使用分片的方式将不同的请求交给不同的 Redis 服务器来处理,而不是在同一个 Redis 服务中引入大量的多线程操作。
简单总结一下,Redis 并不是 CPU 密集型的服务,如果不开启 AOF 备份,所有 Redis 的操作都会在内存中完成不会涉及任何的 I/O 操作,这些数据的读写由于只发生在内存中,所以处理速度是非常快的;整个服务的瓶颈在于网络传输带来的延迟和等待客户端的数据传输,也就是网络 I/O,所以使用多线程模型处理全部的外部请求可能不是一个好的方案。
“AOF 是 Redis 的一种持久化机制,它会在每次收到来自客户端的写请求时,将其记录到日志中,每次 Redis 服务器启动时都会重放 AOF 日志构建原始的数据集,保证数据的持久性。
多线程虽然会帮助我们更充分地利用 CPU 资源,但是操作系统上线程的切换也不是免费的,线程切换其实会带来额外的开销,其中包括:
保存线程 1 的执行上下文;
加载线程 2 的执行上下文;
频繁的对线程的上下文进行切换可能还会导致性能地急剧下降,这可能会导致我们不仅没有提升请求处理的平均速度,反而进行了负优化,所以这也是为什么 Redis 对于使用多线程技术非常谨慎。
引入多线程
Redis 在最新的几个版本中加入了一些可以被其他线程异步处理的删除操作,也就是我们在上面提到的 UNLINK、FLUSHALL ASYNC 和 FLUSHDB ASYNC,我们为什么会需要这些删除操作,而它们为什么需要通过多线程的方式异步处理?
删除操作
我们可以在 Redis 在中使用 DEL 命令来删除一个键对应的值,如果待删除的键值对占用了较小的内存空间,那么哪怕是同步地删除这些键值对也不会消耗太多的时间。
但是对于 Redis 中的一些超大键值对,几十 MB 或者几百 MB 的数据并不能在几毫秒的时间内处理完,Redis 可能会需要在释放内存空间上消耗较多的时间,这些操作就会阻塞待处理的任务,影响 Redis 服务处理请求的 PCT99 和可用性。
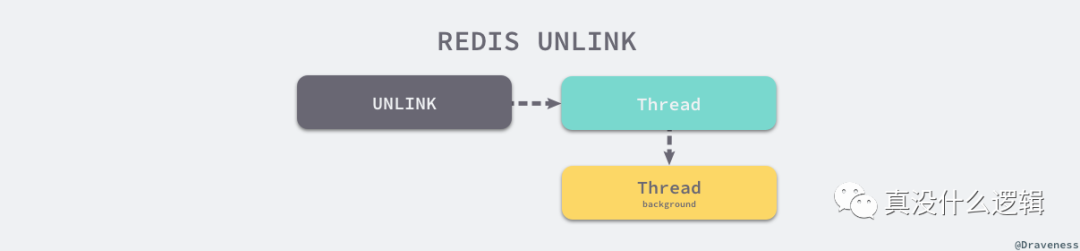
然而释放内存空间的工作其实可以由后台线程异步进行处理,这也就是 UNLINK 命令的实现原理,它只会将键从元数据中删除,真正的删除操作会在后台异步执行。
总结
Redis 选择使用单线程模型处理客户端的请求主要还是因为 CPU 不是 Redis 服务器的瓶颈,所以使用多线程模型带来的性能提升并不能抵消它带来的开发成本和维护成本,系统的性能瓶颈也主要在网络 I/O 操作上;而 Redis 引入多线程操作也是出于性能上的考虑,对于一些大键值对的删除操作,通过多线程非阻塞地释放内存空间也能减少对 Redis 主线程阻塞的时间,提高执行的效率。
“如果对文章中的内容有疑问或者想要了解更多软件工程上一些设计决策背后的原因,可以在博客下面留言,作者会及时回复本文相关的疑问并选择其中合适的主题作为后续的内容。
Reference
Redis is single threaded. How can I exploit multiple CPU / cores?
Redis is single-threaded, then how does it do concurrent I/O?
Why isn't Redis designed to benefit from multi-threading?
Concurrency is not parallelism
The little-known feature of Redis 4.0 that will speed up your applications
Redis 和 I/O 多路复用
CPU Scheduling
点击「阅读原文」获取面试题大全~