
爬虫实战:基于spider-framework框架爬取某宝房产拍卖数据

引子
前几天基友找我想看看广州的房价信息,问我能不能爬点广州各个地区的房价数据来,分析了一波作为投资依据,市面上很多房产中介平台都可以爬,可是那些平台的数据水分比较大,能不能找到一个比较符合实际成交价的数据?没错,就找有实际成交记录的拍卖平台,最后选了数据量相对比较大的某宝拍卖,于是简单分析了下页面网络请求和DOM信息,没太多阻碍就发现了数据的来源,那么开干~
关于 spider-framework
需求明确了,那么就是撸码环节了,我们知道一个完整的爬虫程序应该是包含分析、爬取到入库等一系列流程的,为了直观我就画一个图来表示:
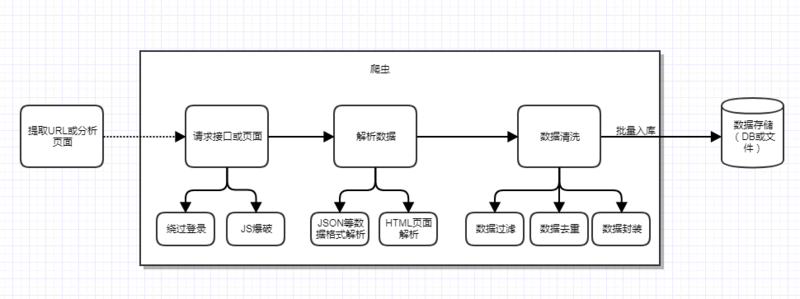
既然要编码实现这整个环节,我们是直接造轮子还是借用已有工具和框架呢?为了节省时间,我这边直接用了我去年开源的一个爬虫框架——spider-framework,它是基于SpringBoot实现的Java轻量级的web多线程爬虫框架,框架模块包含但不限于:
免费代理构建
基于HttpClient的HTTP请求封装
多线程并发爬取
任务调度
免费云数据库模块以及集成了Mybatis支持入库MySQL数据库
更多详情大家可移步我的Github对应的项目:spider-framework
既然已经有了合适的框架了,就没必要再去造轮子了。
爬取过程
1、页面URL提取
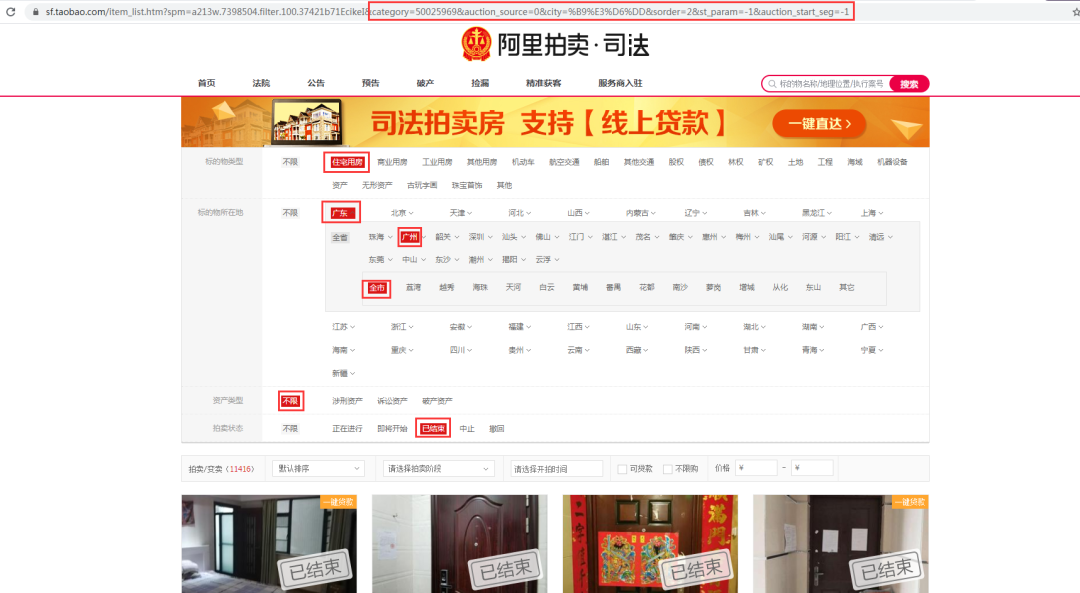
分析页面的网络请求之后,根据界面查询条件组合了一个我们需要的URL,如下图红框标记:
目标URL(为了社会和谐,这里url隐藏域名关键字,改为xxx):https://sf.xxx.com/item_list.htm?spm=a213w.7398504.filter.100.37421b71EcikeI&category=50025969&auction_source=0&city=%B9%E3%D6%DD&sorder=2&st_param=-1&auction_start_seg=-1
2、请求&解析&入库
拿到入口URL后,我们直接套用spider-framework框架,往里面填充解析类即可。新增两个list和item的Processor实现类,结构如下图:
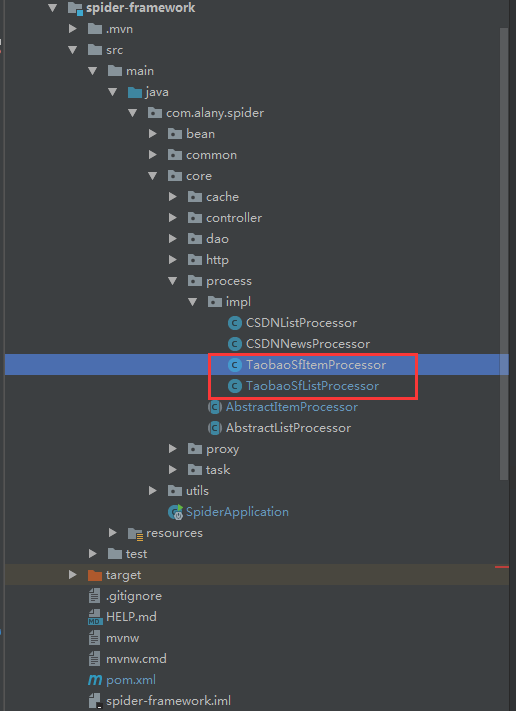
分解一下具体的实现类,TaobaoSfListProcessor类是为并发执行做准备的,根据页面解析的结果,我这里就直接将页面的pageSize=200,按框架的思路,就是开了10个线程去执行这200个任务,核心代码如下:
@Service
public class TaobaoSfListProcessor extends AbstractListProcessor {
public static final String API_NEWS_URL = "https://sf.xxx.com/item_list.htm?category=50025969&auction_source=0&city=%B9%E3%D6%DD&sorder=2&st_param=5&auction_start_seg=-1&page=";
private int maxPageNumber = 200; //最大的分页数
@Override
public List getItemProcessors() {
List list = new ArrayList<>();
for (int i = 1; i < maxPageNumber; i++) {
ExecuteContent executeContent = new ExecuteContent();
executeContent.setUrl(API_NEWS_URL + i);
executeContent.setBusiness(getBusiness());
Map params = new HashMap();
params.put("pageNumber", i);
executeContent.setParams(JSON.toJSONString(params));
TaobaoSfItemProcessor sfItemProcessor = new TaobaoSfItemProcessor();
sfItemProcessor.setExecuteContent(executeContent);
list.add(sfItemProcessor);
}
return list;
}
@Override
public String getBusiness() {
return BizEnum.tabobao.getName();
}
}
TaobaoSfItemProcessor类负责具体的请求,页面解析,以及入库,对于入库,一开始我选择入库到云数据库,可是平台限制了并发频率,请求太快直接不给写入,所以最后放弃了,改为通过mybatis写到mysql数据库,就这样,把框架又集成了下mybatis。先贴一下TaobaoSfItemProcessor类的核心代码:
@SpiderProcessor
@Service("taobaoSfItemProcessor")
public class TaobaoSfItemProcessor extends AbstractItemProcessor<HouseBean> {
private static Logger logger = LoggerFactory.getLogger(TaobaoSfItemProcessor.class);
private HttpRequest httpRequest = SpringContext.getBean(HttpRequest.class);
private HouseMapper houseMapper = SpringContext.getBean(HouseMapper.class);
private static int totalPage = 0;
@Override
public HttpResult request() {
Map<String, Object> headers = new HashMap<>();
if (userAgentList != null && !userAgentList.isEmpty()) {
int index = new Random().nextInt(userAgentList.size());
headers.put("User-Agent", userAgentList.get(index));
}
HttpResult result = httpRequest.setUrl(executeContent.getUrl()).setHeaders(headers).setUseProxy(false).doGet();
return result;
}
@Override
public List parse(HttpResult result) {
List list = new ArrayList<>();
if (result != null && StringUtils.isNotEmpty(result.getContent())) {
try {
Document document = Jsoup.parse(result.getContent());
Element element = document.select("script[id=sf-item-list-data]").first();
if (element == null) {
return null;
}
if (totalPage == 0) {
String totalPageStr = document.select(".page-total").first().ownText();
if (StringUtils.isNotBlank(totalPageStr)) {
totalPage = Integer.parseInt(totalPageStr);
}
}
String jsonText = element.html();
JSONObject root = JSON.parseObject(jsonText);
JSONArray dataArray = root.getJSONArray("data");
if (dataArray != null && !dataArray.isEmpty()) {
for (int i = 0, length = dataArray.size(); i < length; i++) {
JSONObject item = dataArray.getJSONObject(i);
HouseBean bean = new HouseBean();
bean.setSourceName(BizEnum.tabobao.getName());
bean.setItemId(item.getString("id"));
String title = item.getString("title");
bean.setAddress(title);
bean.setCity(AddressType.regexAddress(title, AddressType.city));
bean.setLocation(AddressType.regexAddress(title, AddressType.county));
bean.setSellTotalPrice(item.getFloatValue("currentPrice"));
bean.setMarketTotalPrice(item.getFloatValue("marketPrice"));
if (bean.getMarketTotalPrice() < 1) {
bean.setMarketTotalPrice(item.getFloatValue("consultPrice"));
}
bean.setSellStatus(item.getString("status"));
Date date = new Date(item.getTimestamp("end").getTime());
bean.setSellDate(date);
bean.setItemUrl("http:" + item.getString("itemUrl"));
if (StringUtils.isNotBlank(bean.getItemId())) {
list.add(bean);
}
}
}
} catch (Exception e) {
logger.error("parse json to bean meet error:", e);
}
}
return list;
}
@Override
public void store(List list) {
if (list != null && !list.isEmpty()) {
houseMapper.batchInsert(list);
}
}
@Override
protected boolean hasMore() {
return false;
}
}
在做页面解析的时候遇到一个很有意思的问题,拿到页面数据后,需要提取出市、区等地址信息,对于这个很多人可能想到用字符串截取来做,可是后面跑的过程中发现有不少不规范的地址出现,比如:位于广州天河区白云路xxx号xxx小区,省略了"市"\"区"这些标志性字,最后采用了正则表达式来匹配,给出匹配规则:
(?[^省]+自治区|.*?省|.*?行政区|.*?市)(?[^市]+自治州| .*?地区|.*?行政单位|.+盟|市辖区|.*?市|.*?县)(?[^县]+县| .+区|.+市|.+旗|.+海域|.+岛)?(?[^区]+区|.+镇)?(?.*)
前面说了本例是入库到MySQL数据库,这里需要涉及到SpringBoot中集成mybatis的相关配置,我直接在框架中已经引入配置好了,简单说下,SpringBoot对于引入这些第三方框架简化了很多操作,非常简单,pom文件中加入对应的starter就好了。
3、效果
前面工作都做好后,配上本地MySQL数据库信息,去启动类下面开始执行:
@ComponentScan(basePackages = {"com.alany.spider"}) //扫描该包路径下的所有spring组件
@SpringBootApplication
public class SpiderApplication {
public static void main(String[] args) throws InterruptedException {
SpringApplication.run(SpiderApplication.class, args);
AsyncProcessTask asyncProcessTask = SpringContext.getBean(AsyncProcessTask.class);
asyncProcessTask.initProxy();
Thread.sleep(1000 * 30);
asyncProcessTask.startProcessorsByBusiness(BizEnum.tabobao.getName());
}
}
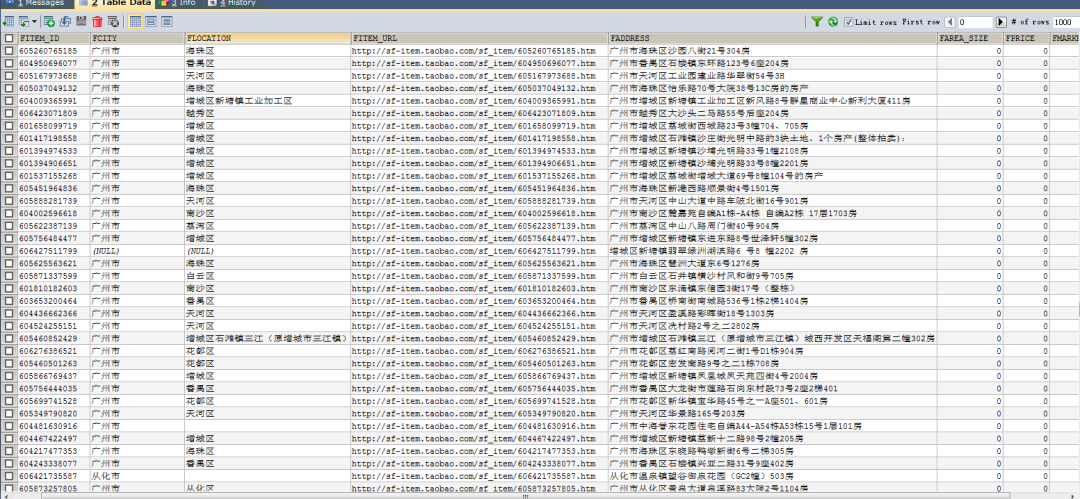
数据唰一下就入库的感觉很爽,上万条数据秒级入库,导出发送,基友很开心,社会很和谐。。。
有兴趣的童鞋,欢迎去我的Github体验~
测试开发栈
软件测试开发合并必将是趋势,不懂开发的测试、不懂测试的开发都将可能被逐渐替代,因此前瞻的技术储备和知识积累是我们以后在职场和行业脱颖而出的法宝,期望我们的经验和技术分享能让你每天都成长和进步,早日成为测试开发栈上的技术大牛~~
长按二维码/微信扫描关注
互联网测试开发一站式全栈分享平台