
Python私活5000元,复杂CSV文件处理需求
一个月前在蚂蚁老师的学习群中,接到一个5000元的大项目,陆陆续续肝了一个月,今天收到项目最后一笔款项,代表项目正式完成。发篇小作文总结一下心得,废话不多说了,先上图:^_^
项目简介
鉴于项目保密的需要,不便透露太多项目的信息,因此,简单介绍一下项目存在的难点:
海量数据:项目是对CSV文件中的数据进行处理,而特点是数据量大...真的大!!!拿到的第一个CSV示例文件是110多万行(小CASE),而第二个文件就到了4500万行,等到第三个文件......好吧,一直没见到第三个完整示例文件,因为太大了,据说是第二个示例文件的40多倍,大概二十亿行...... 业务逻辑复杂:项目是需要对CSV文件的每一行数据的各种组合可能性进行判断,而判断的业务逻辑较为复杂,如何在解决复杂逻辑的同时保证较高的处理效率是难点之一。
项目笔记与心得
一、分批处理与多进程、多线程加速
因为数据量太大,肯定是要分批对数据进行处理,否则,效率低不谈,大概率也没有足够的内存能够支撑,需要用到chunksize,此外,为了节约内存,以及提高处理效率,可以将文本类的数据存储为“category”格式: 项目整体是计算密集型的任务,因此,需要用到多进程,充分利用CPU的多核性能; 多线程进行读取与写入,其中,写入使用to_csv的增量写入方法,mode参数设置为'a'; 多进程与多线程开启一般为死循环,需要在合适的位置,放入结束循环的信号,以便处理完毕后退出多进程或多线程
"""鉴于项目保密需要,以下代码仅为示例"""
import time
import pathlib as pl
import pandas as pd
from threading import Thread
from multiprocessing import Queue, Process, cpu_count
# 导入多线程Thread,多进程的队列Queue,多进程Process,CPU核数cpu_count
# 存放分段读取的数据队列,注:maxsize控制队列的最大数量,避免一次性读取到内存中的数据量太大
data_queue = Queue(maxsize=cpu_count() * 2)
# 存放等待写入磁盘的数据队列
write_queue = Queue()
def read_data(path: pl.Path, data_queue: Queue, size: int = 10000):
"""
读取数据放入队列的方法
:return:
"""
data_obj = pd.read_csv(path, sep=',', header=0, chunksize=size, dtype='category')
for idx, df in enumerate(data_obj):
while data_queue.full(): # 如果队列满了,那就等待
time.sleep(1)
data_queue.put((idx + 1, df))
data_queue.put((None, None)) # 放入结束信号
def write_data(out_path: pl.Path, write_queue: Queue):
"""
将数据增量写入CSV的方法
:return:
"""
while True:
while write_queue.empty():
time.sleep(1)
idx, df = write_queue.get()
if df is None:
return # 结束退出
df.to_csv(out_path, mode='a', header=None, index=False, encoding='ansi') # 输出CSV
def parse_data(data_queue: Queue, write_queue: Queue):
"""
从队列中取出数据,并加工的方法
:return:
"""
while True:
while write_queue.empty():
time.sleep(1)
idx, df = data_queue.get()
if df is None: # 如果是空的结束信号,则结束退出进程,
# 特别注意结束前把结束信号放回队列,以便其他进程也能接收到结束信号!!!
data_queue.put((idx, df))
return
"""处理数据的业务逻辑略过"""
write_queue.put((idx, df)) # 将处理后的数据放入写队列
# 创建一个读取数据的线程
read_pool = Thread(target=read_data, args=(read_data_queue, *args))
read_pool.start() # 开启读取线程
# 创建一个增量写入CSV数据的线程
write_pool = Thread(target=write_data, args=(write_data_queue, *args))
write_pool.start() # 开启写进程
pools = [] # 存放解析进程的队列
for i in range(cpu_count()): # 循环开启多进程,不确定开多少个进程合适的情况下,那么按CPU的核数开比较合理
pool = Process(target=parse_data, args=(read_data_queue, write_data_queue, *args))
pool.start() # 启动进程
pools.append(pool) # 加入队列
for pool in pools:
pool.join() # 等待所有解析进程完成
# 所有解析进程完成后,在写队列放入结束写线程的信号
write_data_queue.put((None, None))
write_pool.join() # 等待写线程结束
print('任务完成')
二、优化算法,提高效率
将类对象存入dataframe列
在尝试了n种方案之后,最终使用了将类对象存到dataframe的列中,使用map方法,运行类方法,最后,将运行结果展开到多列中的方式。该方案本项目中取得了最佳的处理效率。
"""鉴于保密需要,以下代码仅为示例"""
class Obj:
def __init__(self, ser: pd.Series):
"""
初始化类对象
:param ser: 传入series
"""
self.ser = ser # 行数据
self.attrs1 = [] # 属性1
self.attrs2 = [] # 属性2
self.attrs3 = [] # 属性3
def __repr__(self):
"""
自定义输出
"""
attrs1 = '_'.join([str(a) for a in self.attrs1])
attrs2 = '_'.join([str(a) for a in self.attrs2])
attrs3 = '_'.join([str(a) for a in self.attrs3])
return '_'.join([attrs1, attrs2, attrs3])
def run(self):
"""运行业务逻辑"""
# 创建obj列,存入类对象
data['obj'] = data.apply(lambda x: Obj(x), axis=1)
# 运行obj列中的类方法获得判断结果
data['obj'] = data['obj'].map(lambda x: x.run())
# 链式调用,1将类对象文本化->2拆分到多列->3删除空列->4转换为category格式
data[['col1', 'col2', 'col3', ...省略]] = data['obj'].map(str).str.split('_', expand=True).dropna(axis=1).astype('category')
# 删除obj列
data.drop(columns='obj', inplace=True)
减少计算次数以提高运行效率
在整个优化过程中,对运行效率产生最大优化效果的有两项:
一是改变遍历算法,采用直接对整行数据进行综合判断的方法,使原需要遍历22个组合的计算与判断大大减少 二是提前计算特征组合,制作成字典,后续直接查询结果,而不再进行重复计算
使用numpy加速计算
numpy还是数据处理上的神器,使用numpy的方法,比自己实现的方法效率要高非常多,本项目中就用到了:bincount、argsort,argmax、flipud、in1d、all等,即提高了运行效率,又解决了逻辑判断的问题:
"""numpy方法使用示例"""
import numpy as np
# 计算数字的个数组合bincount
np.bincount([9, 2, 13, 12, 9, 10, 11])
# 输出结果:array([0, 0, 1, 0, 0, 0, 0, 0, 0, 2, 1, 1, 1, 1], dtype=int64)
# 取得个数最多的数字argmax
np.argmax(np.bincount([9, 2, 13, 12, 9, 10, 11]))
# 输出结果: 9
# 将数字按照个数优先,其次大小进行排序argsort
np.argsort(np.bincount([9, 2, 13, 12, 9, 10, 11]))
# 输出结果:array([ 0, 1, 3, 4, 5, 6, 7, 8, 2, 10, 11, 12, 13, 9], dtype=int64)
# 翻转列表flipud
np.flipud(np.argsort(np.bincount([9, 2, 13, 12, 9, 10, 11])))
# 输出结果: array([ 9, 13, 12, 11, 10, 2, 8, 7, 6, 5, 4, 3, 1, 0], dtype=int64)
# 查找相同值in1d
np.in1d([2, 3, 4], [2, 9, 3])
# 输出结果: array([ True, True, False]) 注:指2,3True,4False
np.all(np.in1d([2, 3], [2, 9, 3]))
# 输出结果: array([ True, True])
# 是否全是all
np.all(np.in1d([2, 3, 4], [2, 9, 3])) # 判断组合1是否包含在组合2中
# 输出结果: False
np.all(np.in1d([2, 3], [2, 9, 3]))
# 输出结果: True
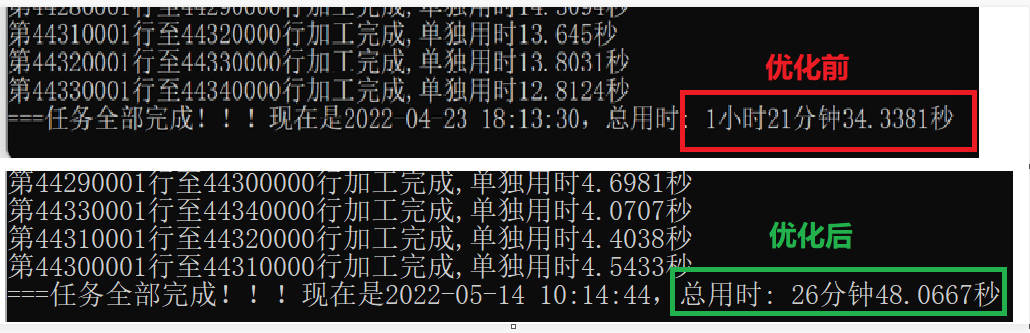
优化前后的效率对比
总结
优化算法是在这个项目上时间花费最多的工作(没有之一)。4月12日接单,10天左右出了第1稿,虽能运行,但回头看存在两个问题:一是有bug需要修正,二是运行效率不高(4500万行数据,执行需要1小时21分钟,如果只是在这个版本上debug需要增加判断条件,效率只会更低);后20多天是在不断的优化算法的同时对bug进行修正,最后版本执行相同数据只需要不足30分钟,效率提高了一倍多。回顾来看,虽然调优花费的时间多,但是每一个尝试不论成功还是失败都是一次宝贵的经验积累。 调优过程中,重温了蚂蚁老师的并发编程、pandas、numpy等课程,将其中的知识点真正用到实际项目中,学以致用了才真正理解了知识点。 最后感慨一下,蚂蚁老师的课买的真是值,学到知识不说,还能赚点零花钱~~~^_^
最后,推荐蚂蚁老师的《Python入门到副业就业》系列套餐。
包含14门课程,涵盖爬虫、数据分析、web开发、人工智能多个领域
购买课程,加蚂蚁老师微信:ant_learn_python 加答疑群、提供私聊答疑
请注意:需要在抖音扫码购买,才能享受此优惠

评论