
bibliometrix: 从千万篇论文中挖掘出最值得读的那一篇!
机器学习初学者
共 892字,需浏览 2分钟
·
2022-07-26 09:07
为了解决这个问题,本次推荐一个R语言工具:bibliometrix,
如果你喜欢写代码,直接用bibliometrix包 如果你喜欢界面操作,请用bibliometrix的界面版biblioshiny, 下文详细介绍biblioshiny使用。
bibliometrix安装
install.packages("bibliometrix") #安装
library('bibliometrix') #导入
biblioshiny启动
bibliometrix安装时直接包含了biblioshiny,直接在R终端启动即可。
biblioshiny()
直接打开下面的界面,
biblioshiny使用
支持PubMed,Web of Science,Google scholar等搜索引擎的存储结果bibtex
文献数据导入 
 详细介绍方法2,以covid-19检索为例,
详细介绍方法2,以covid-19检索为例,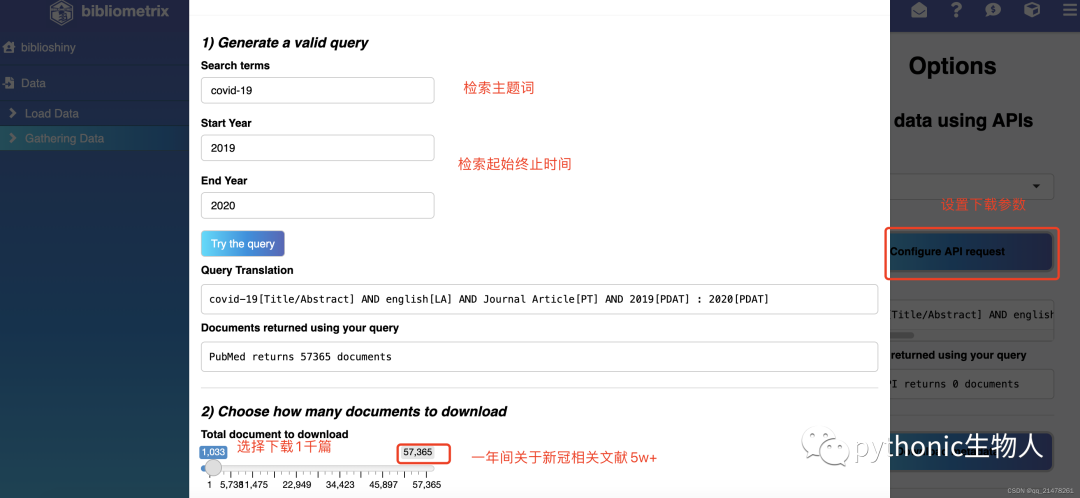 R终端显示数据下载进度,下载需要一些时间,
R终端显示数据下载进度,下载需要一些时间, 几分钟后,数据下载完毕,
几分钟后,数据下载完毕, 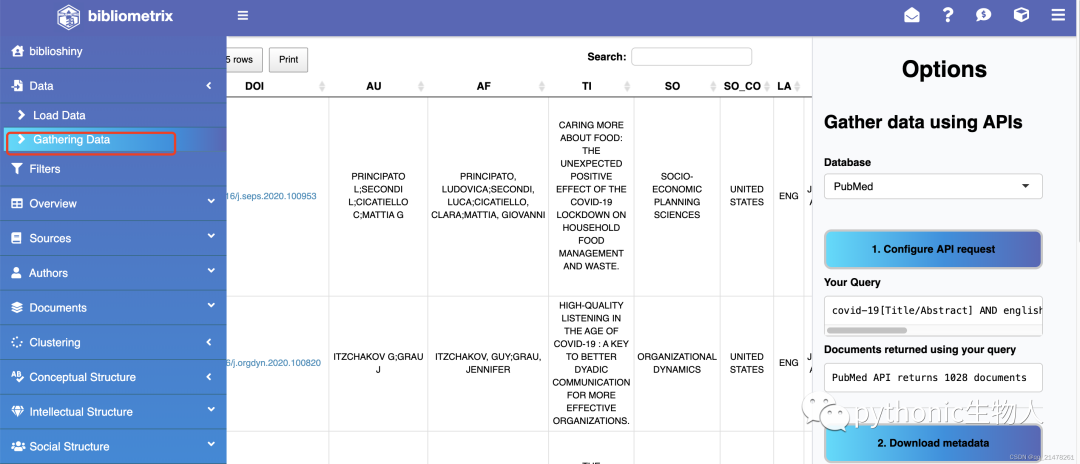 下面,简要看看能通过数据得到那些有价值信息(由于只选取了1000篇文章,后面数据可能失真,仅当演示):
下面,简要看看能通过数据得到那些有价值信息(由于只选取了1000篇文章,后面数据可能失真,仅当演示):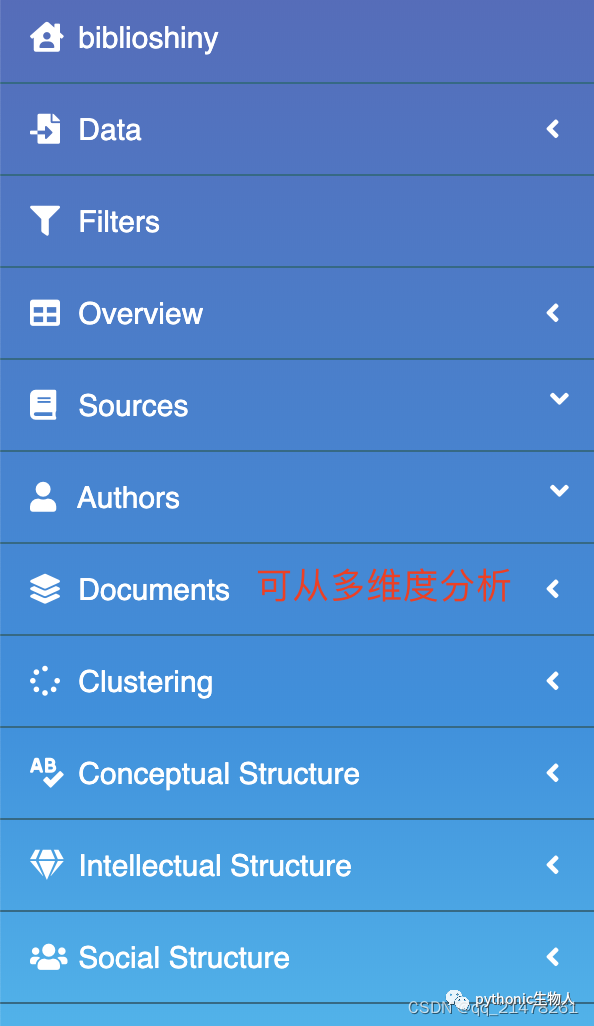
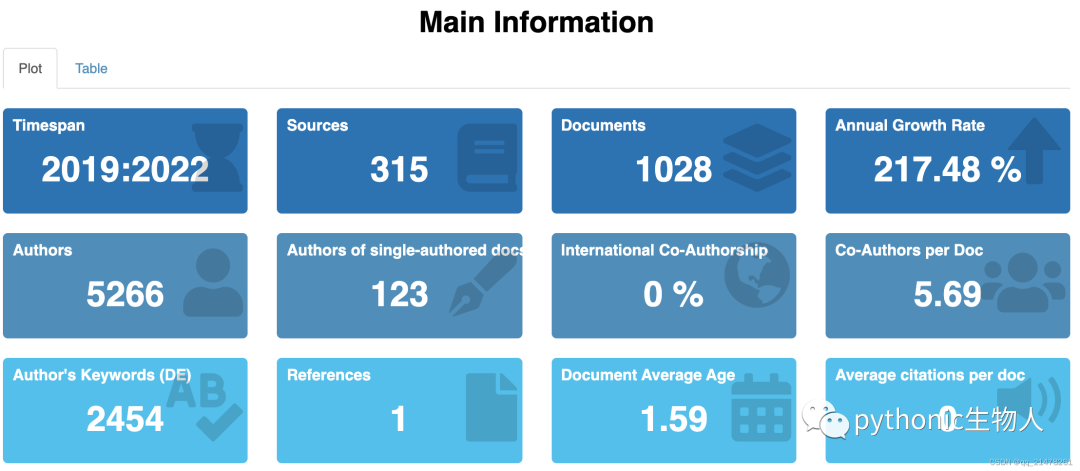
数据总体指标统计 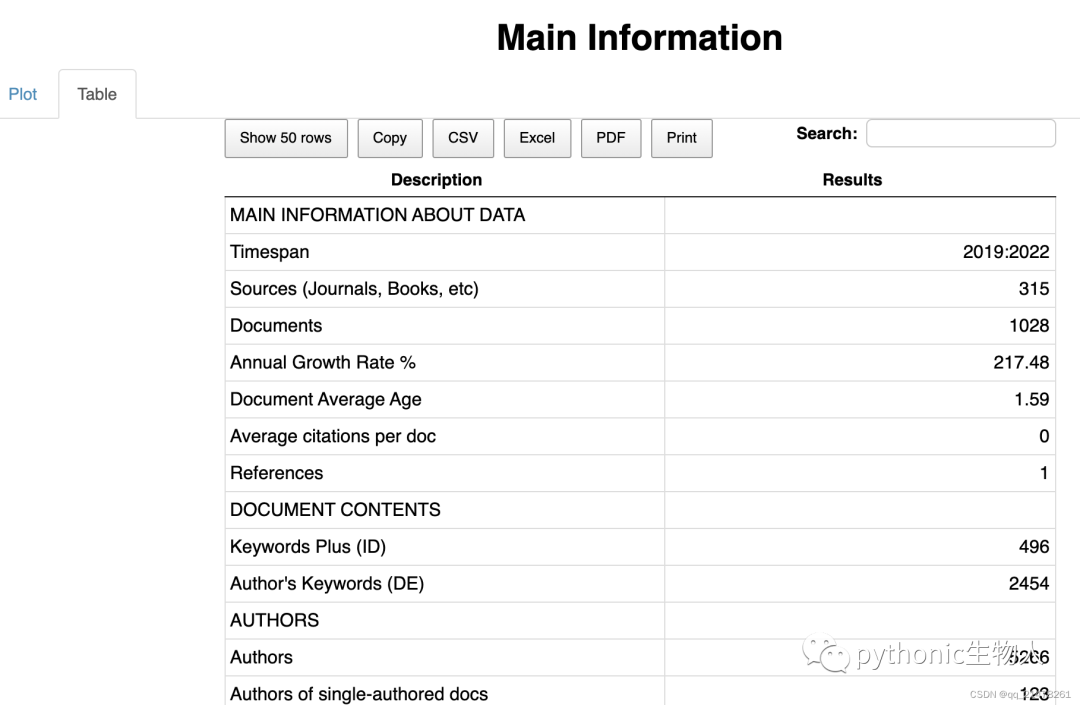
相关文章的发表趋势 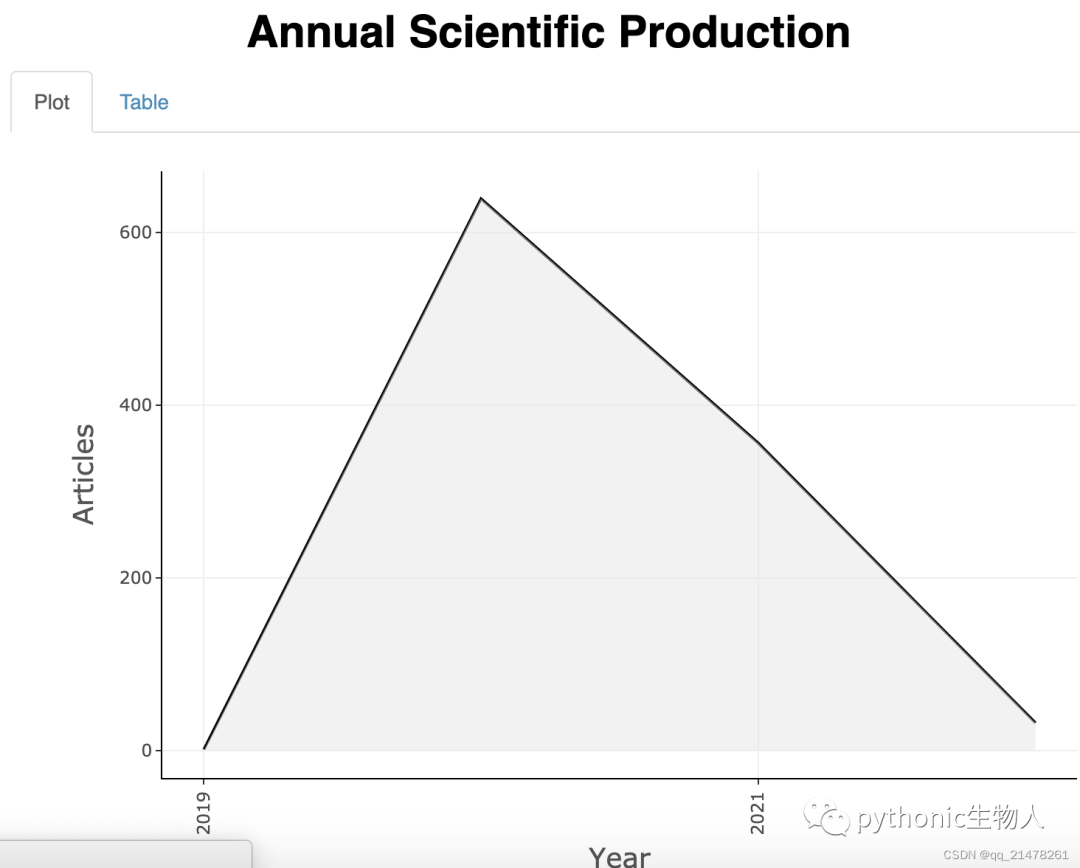 2019年新冠大爆发,2021文章井喷发表。
2019年新冠大爆发,2021文章井喷发表。哪些杂志贡献最多成果 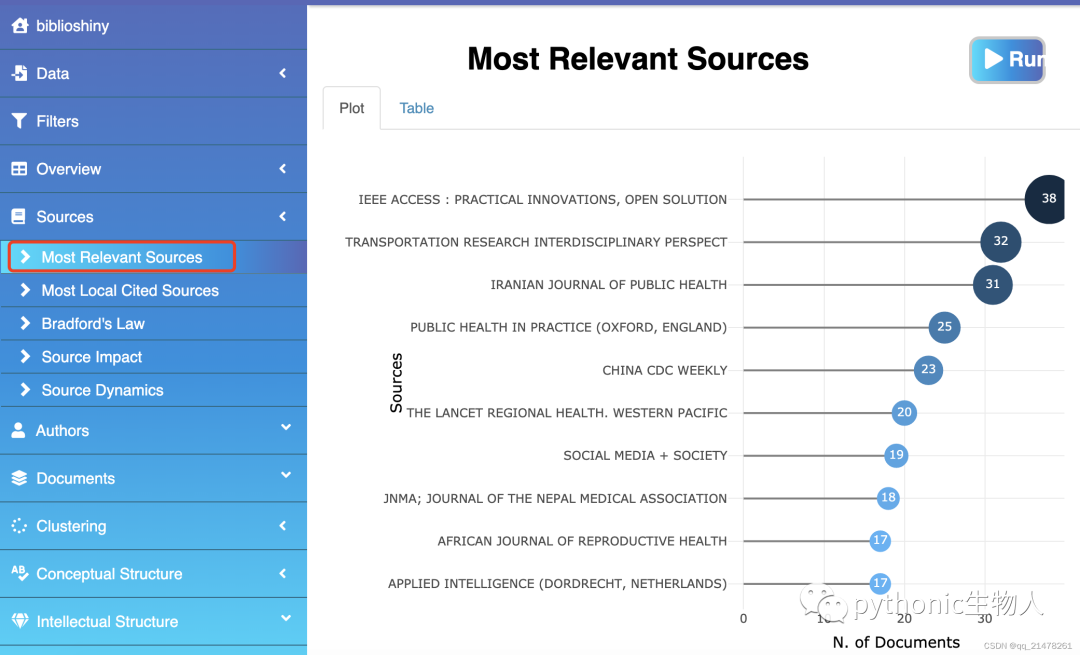
哪些大牛贡献最多成果 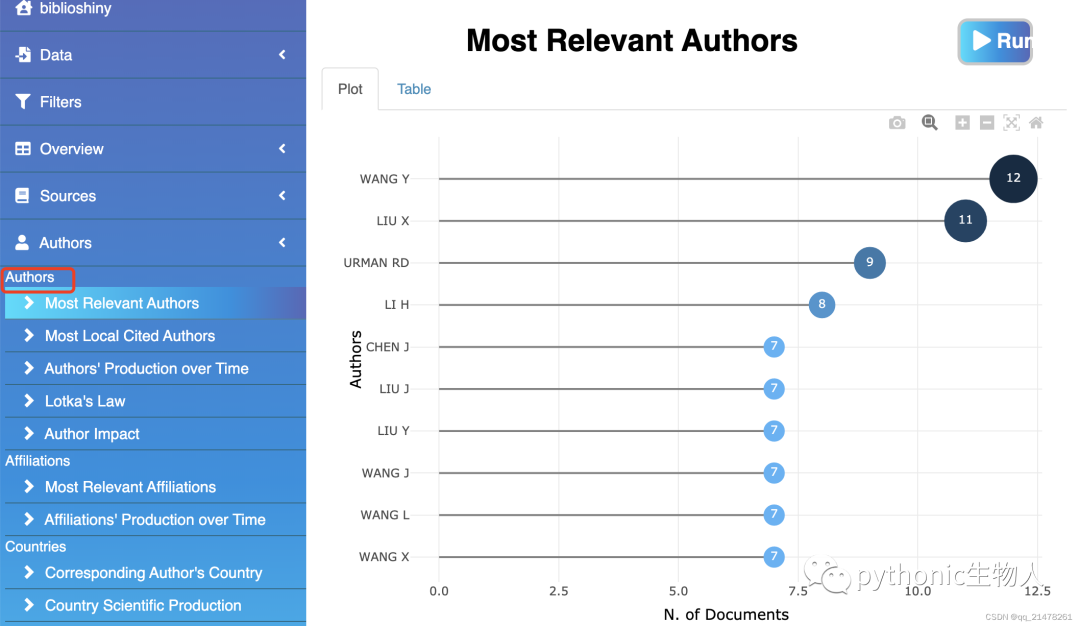 详细文章链接列表
详细文章链接列表
哪些机构贡献最多成果 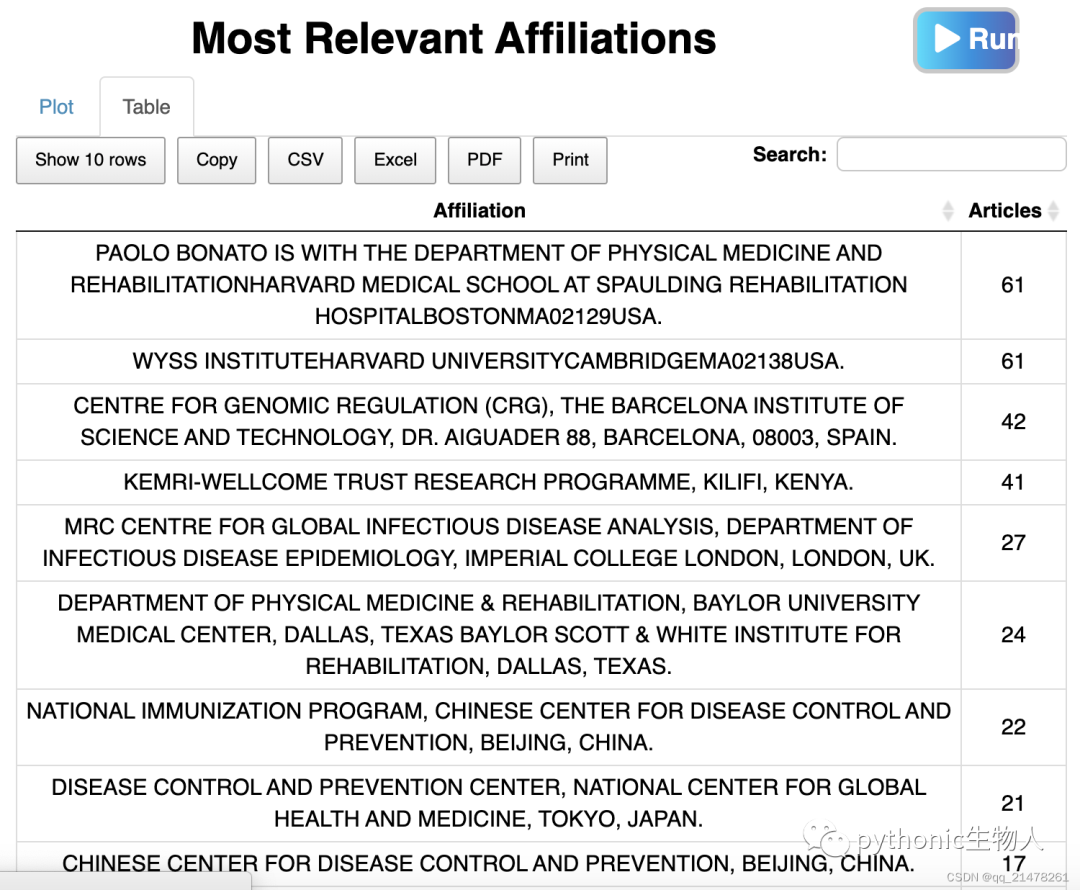 看到了CHINA~
看到了CHINA~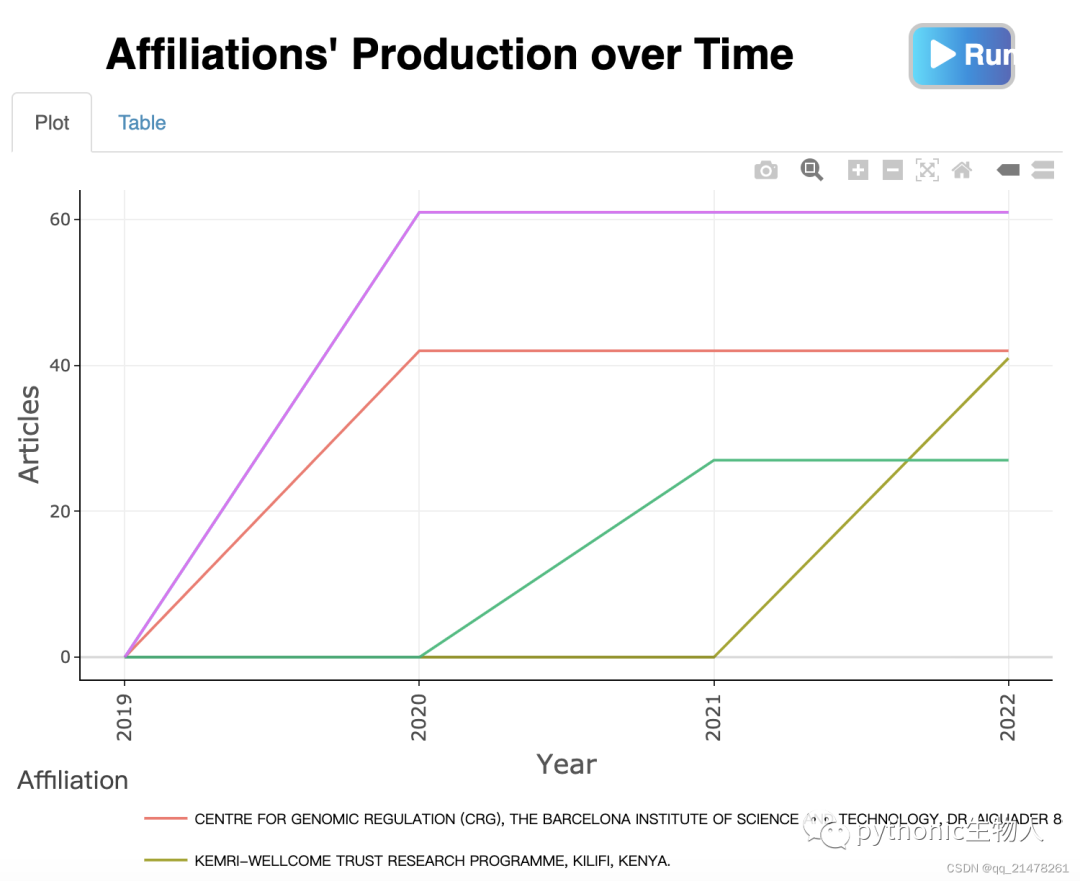
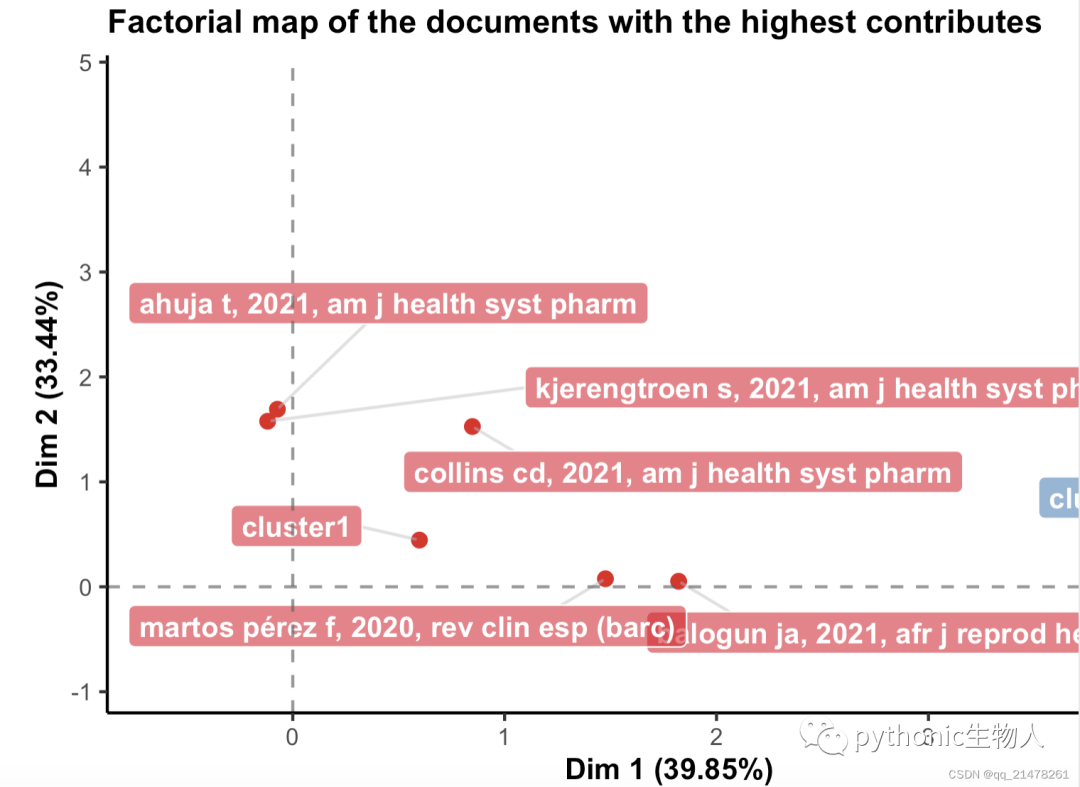
最多被引用文献 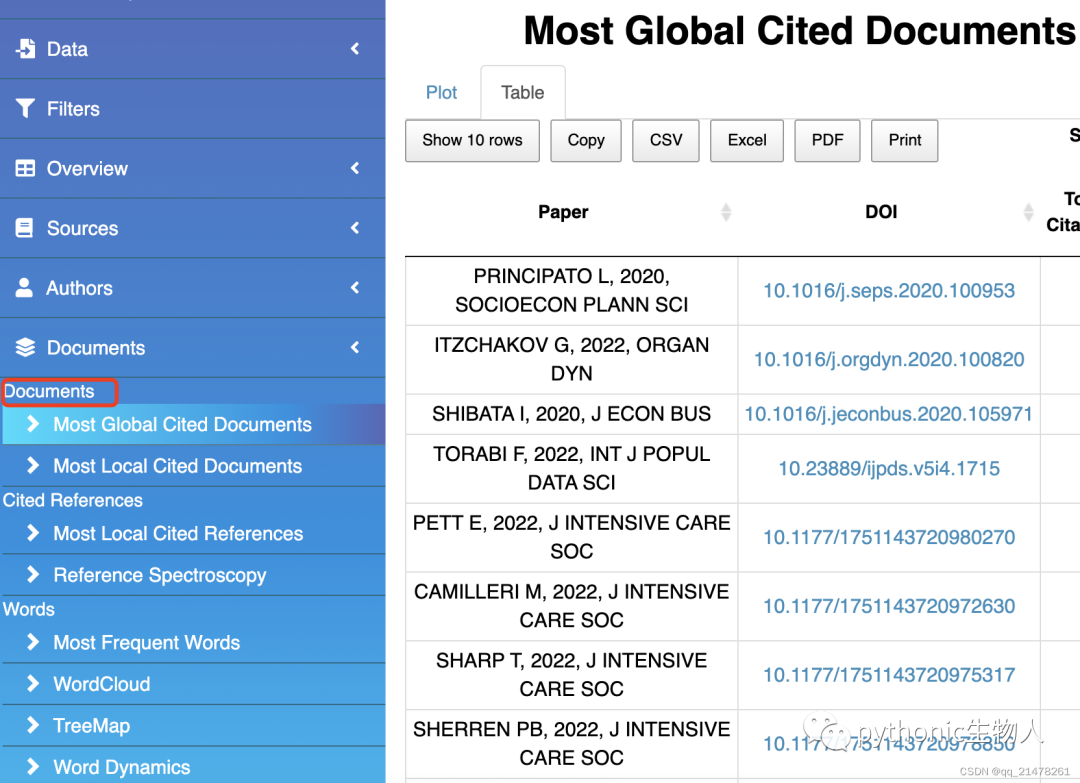
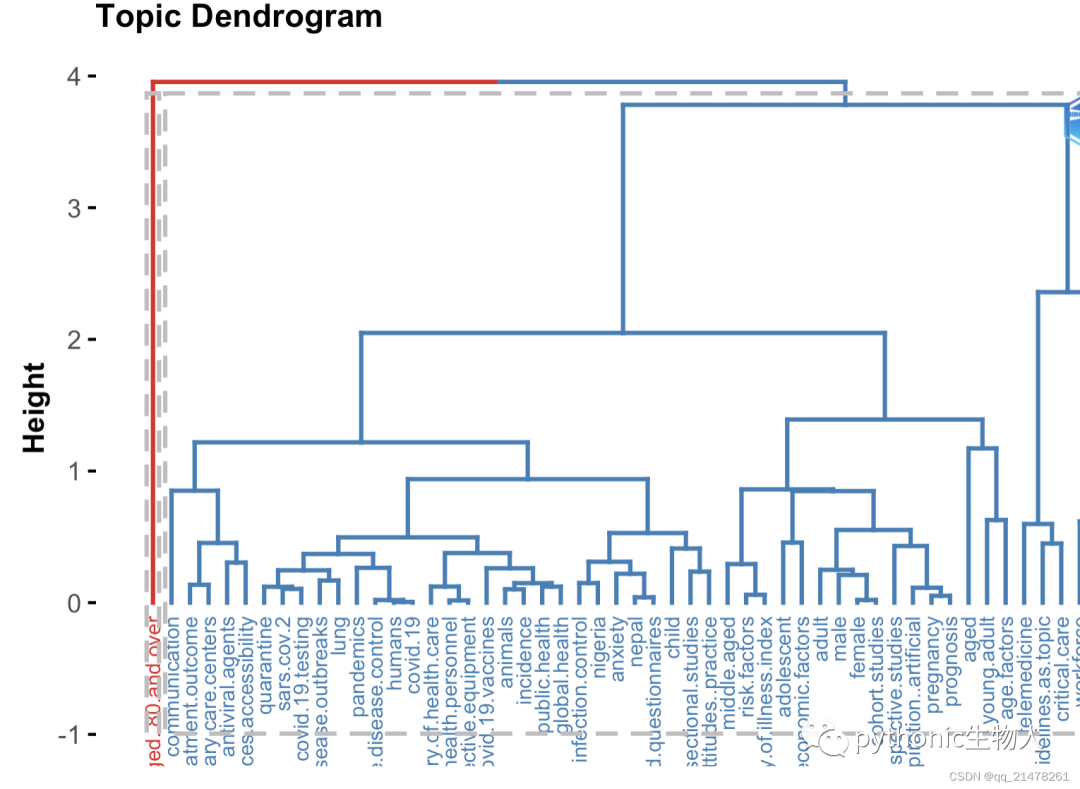
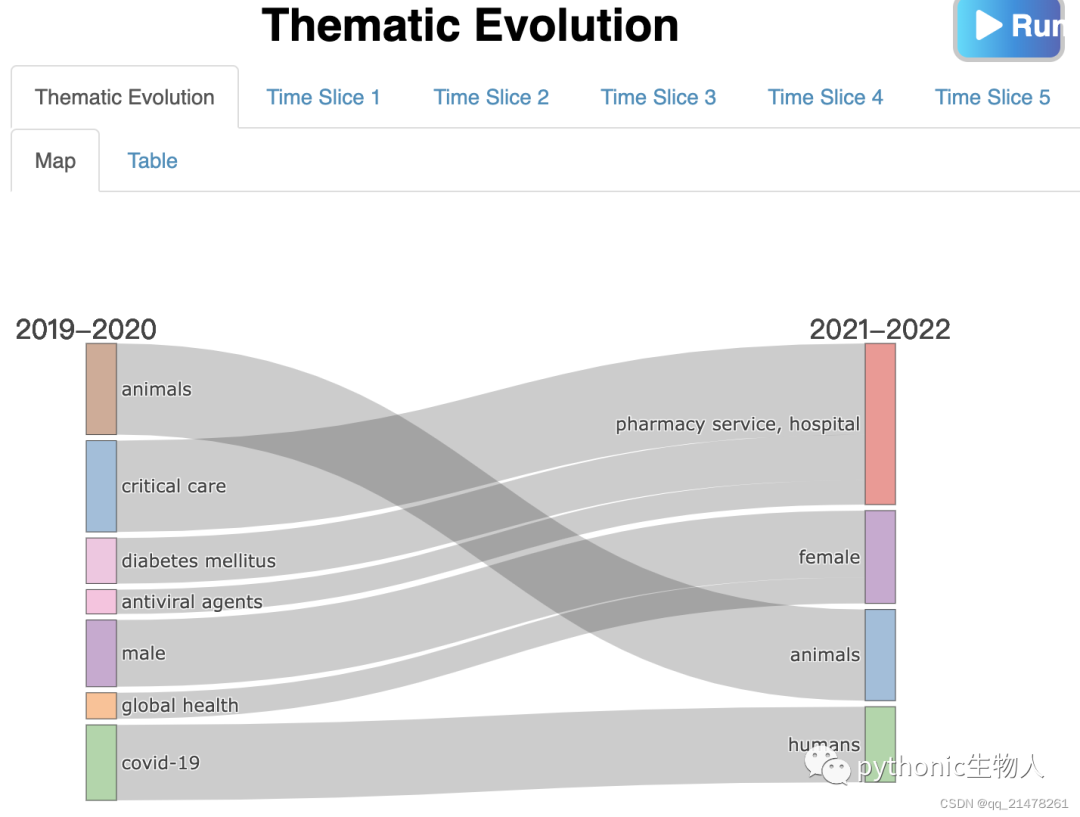
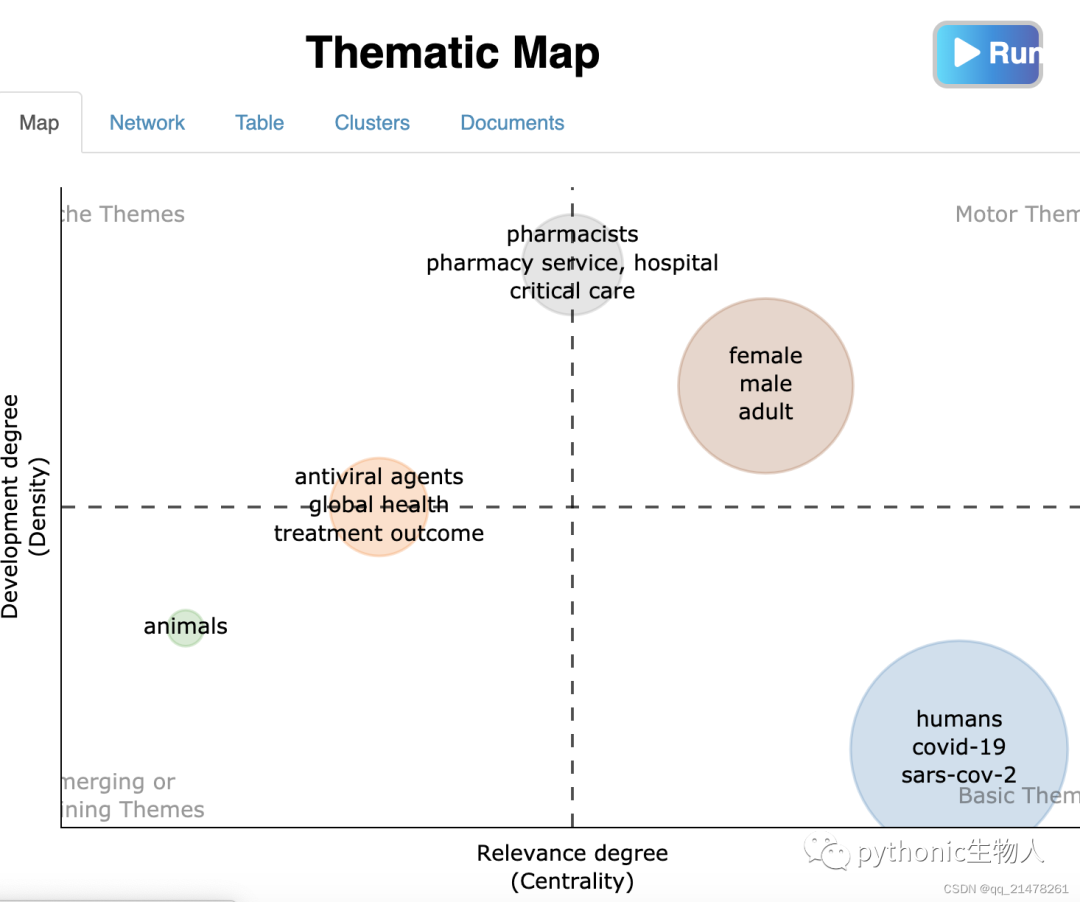
哪些主题被关注 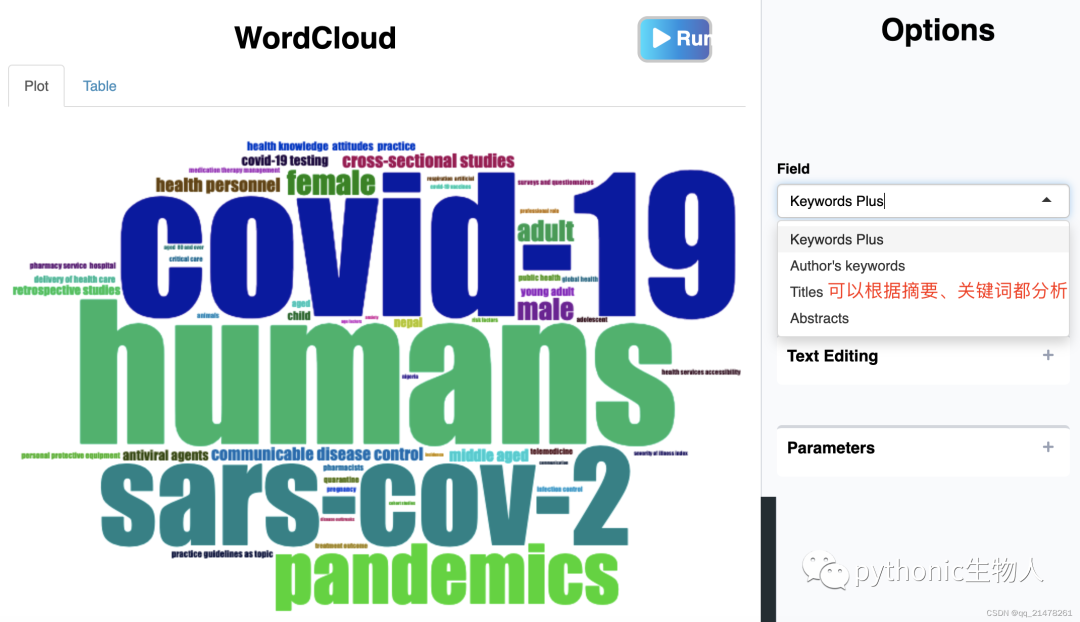
**主题进一步聚类 ** 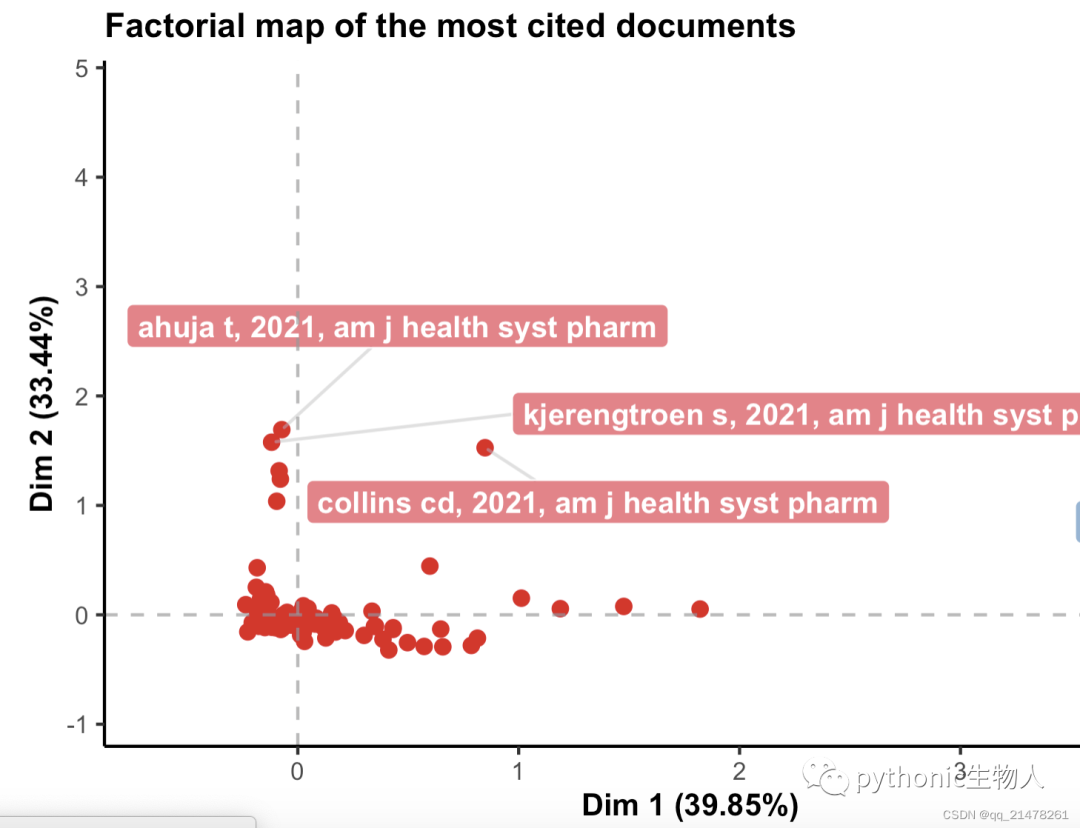
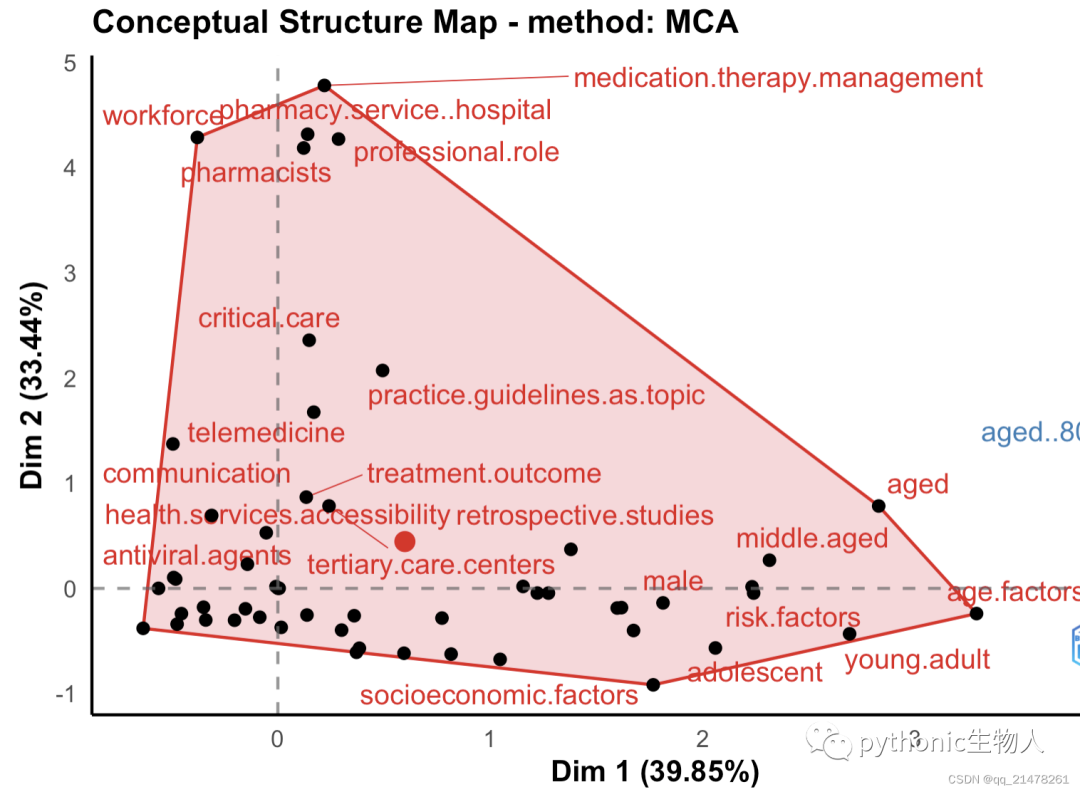
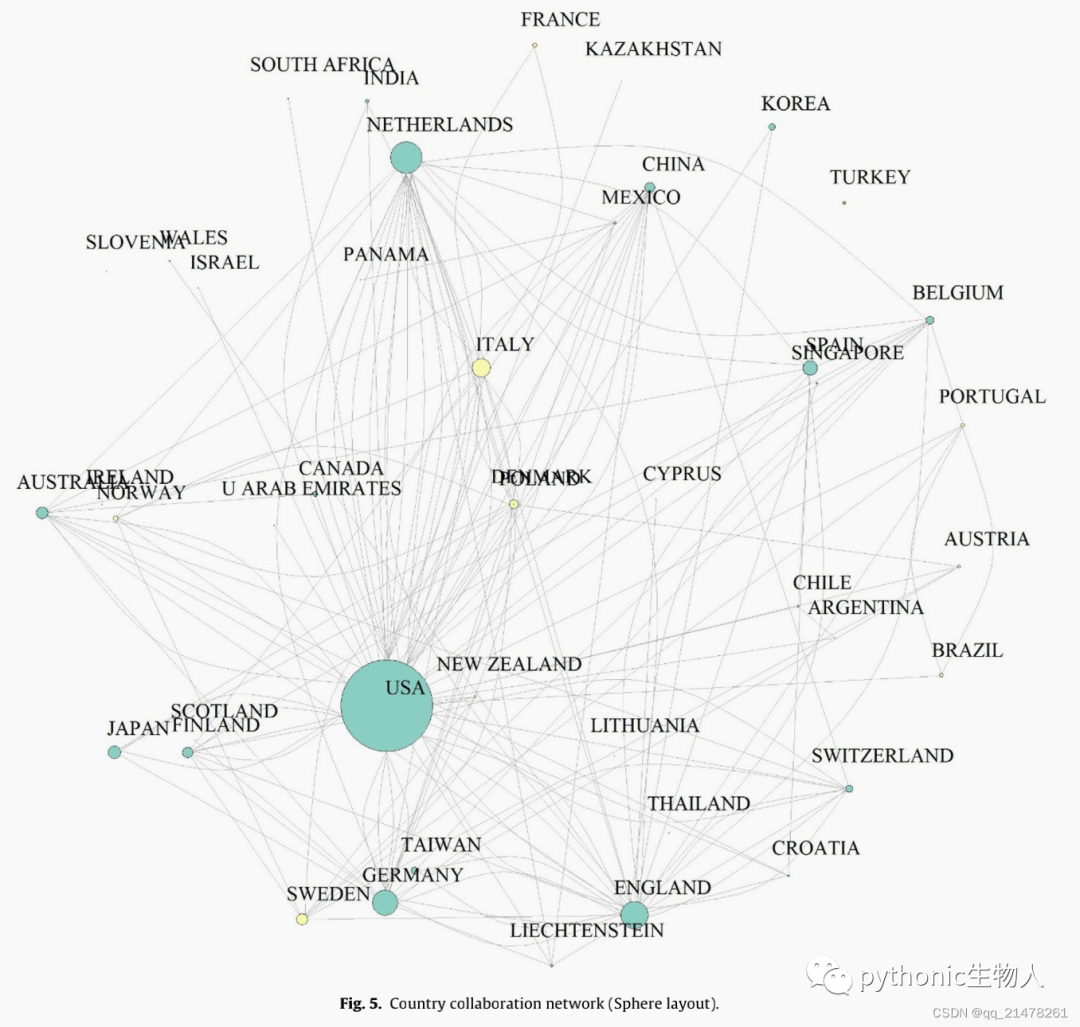
各种Network分析 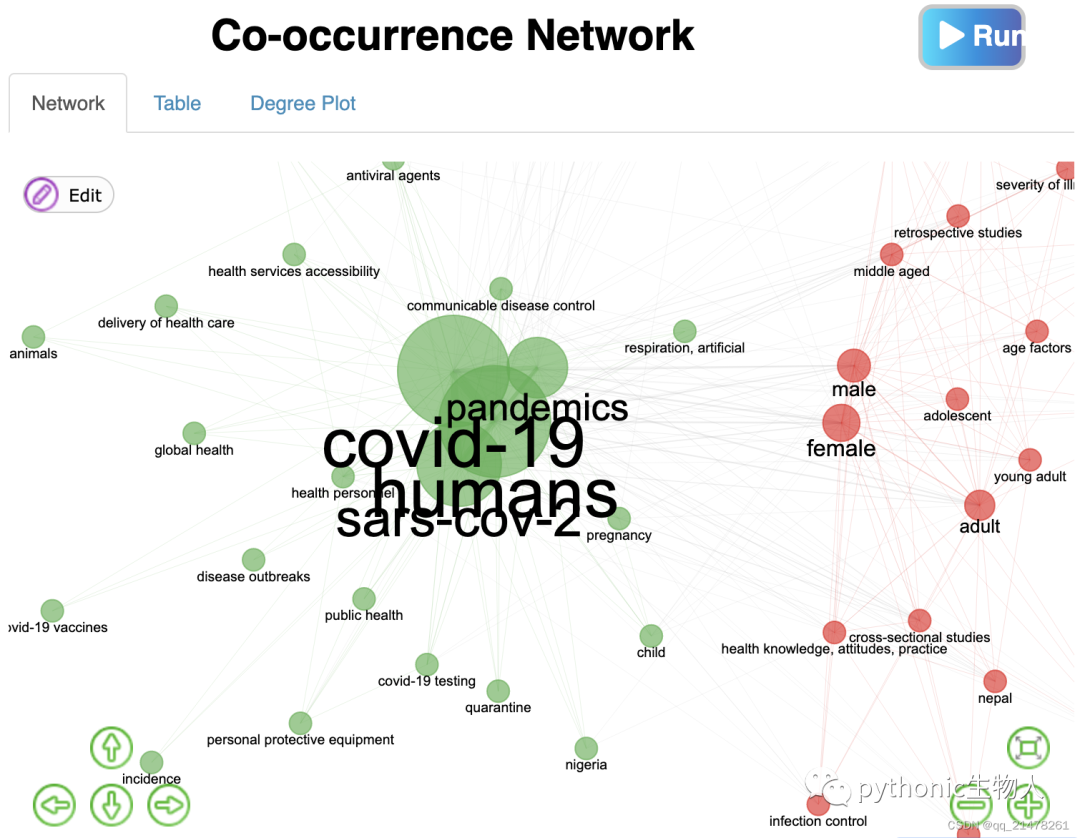
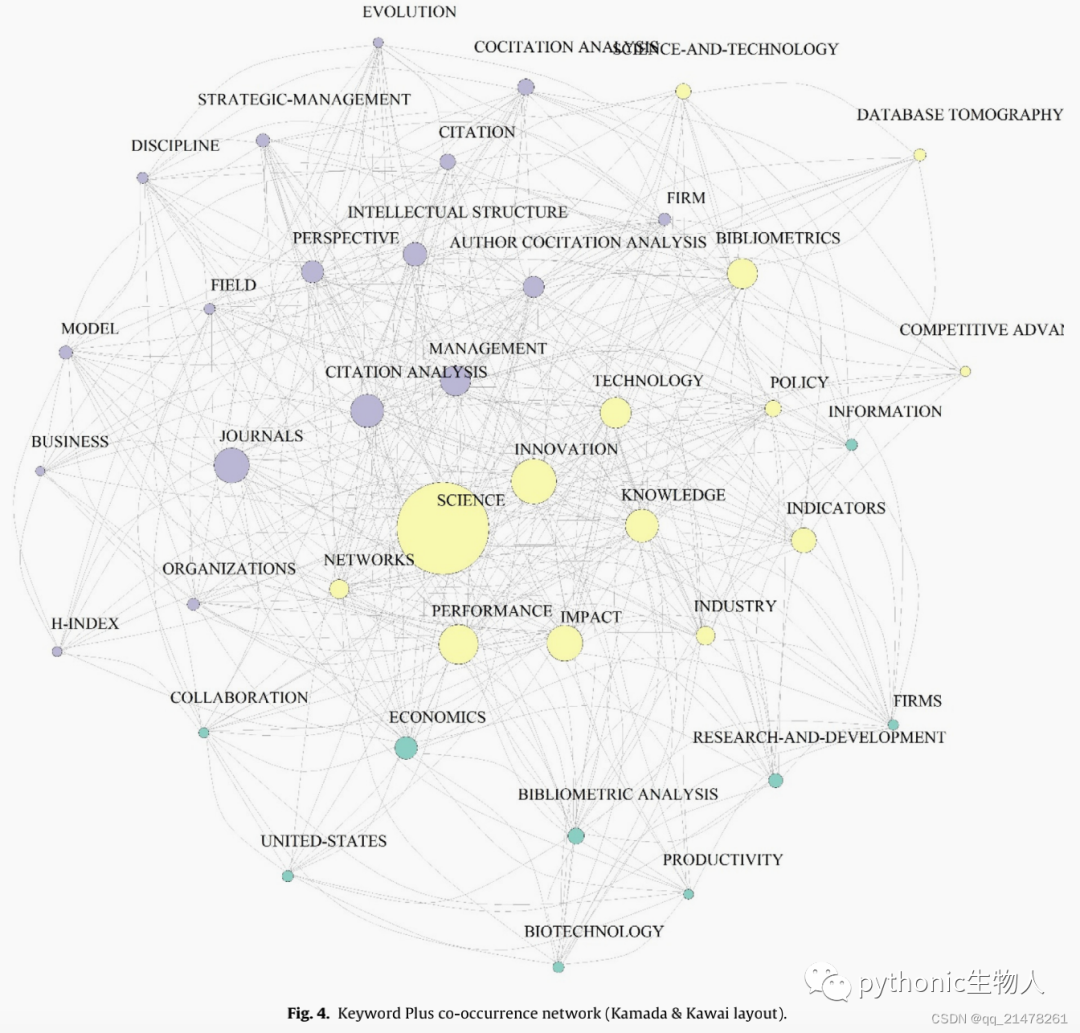 本次简单介绍到这里,更多请参考:https://www.sciencedirect.com/science/article/abs/pii/S1751157717300500
本次简单介绍到这里,更多请参考:https://www.sciencedirect.com/science/article/abs/pii/S1751157717300500
-END-
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码
评论