
用20篇论文走完知识蒸馏在 2014-2020 年的技术进展
新智元推荐
新智元推荐
来源:知乎
作者:傅斯年Walton
【新智元导读】本文是一篇知识蒸馏方面的论文回顾总结,总共涉及了20篇相关的paper。作者介绍了知识蒸馏的三种主要方法Logits(Response)-based 、Feature-based、Relation-based以及知识蒸馏的相关应用。
最近给公司里面的同学做了一个KD的survey,趁热把我回顾研究的一些东西记录下来,算是回馈知乎社区,一直以来,从里面汲取了很多营养,但没有怎么输出优质内容。
概要
Intro & Roadmap
KD主要方法
Applications(NLP-BERT)
QA
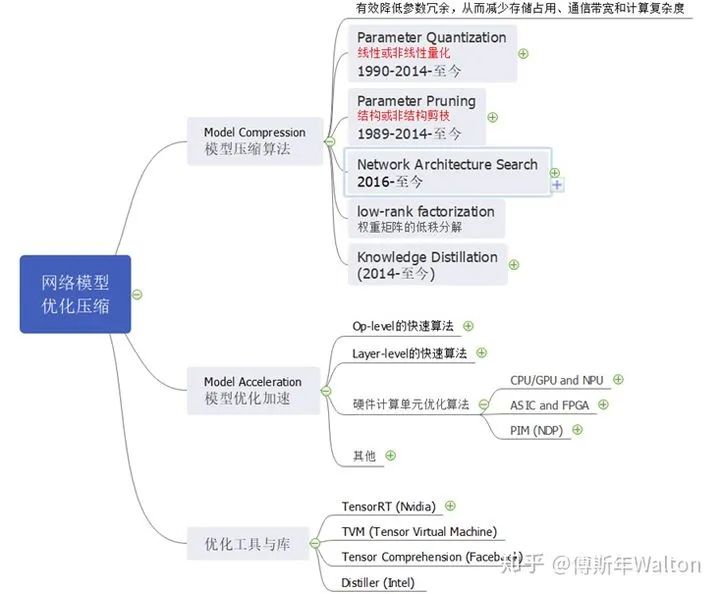
Intro & Roadmap整个模型压缩优化知识结构如下所示,KD属于模型压缩算法的一种,从2014年发展至今。
Bucilua et al. (2006) 首次提出通过知识蒸馏压缩模型的思想,但是没有实际的工作阐述。之后Hilton et al. (2014)第一次正式定义Distillation,并提出相应的训练方法。

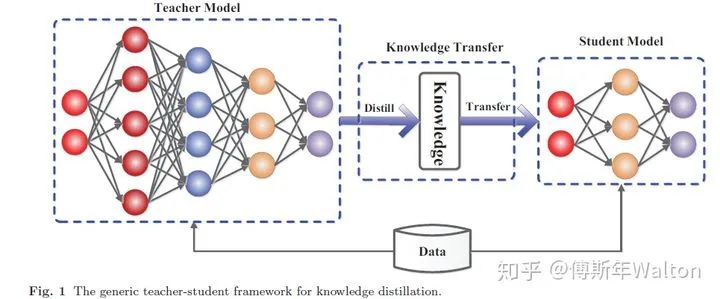
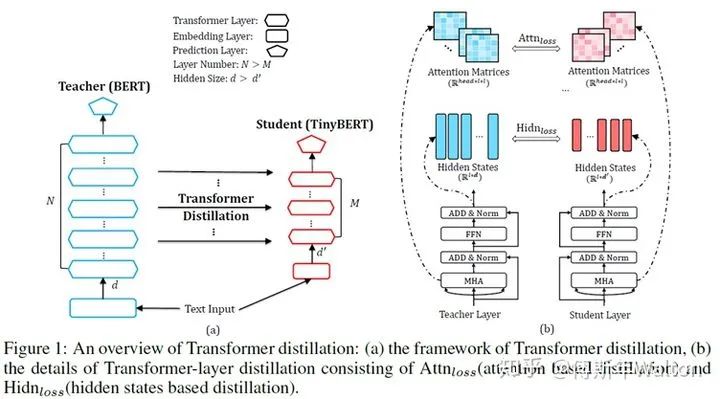
一个典型的KD框架如下图所示,由三个part组成,Teacher model,student model 和Knowledge transfer,整个过程是在有监督的data数据集上训练完成。
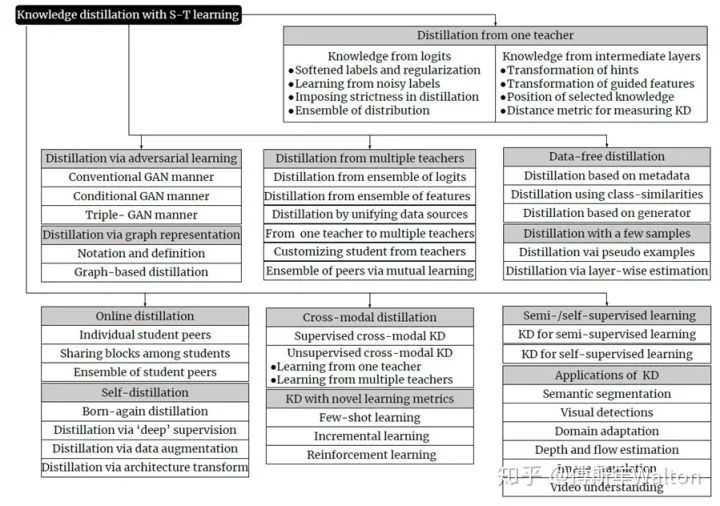
下面介绍今年的两篇survey文章,引用他们的Roadmap图,回顾下过去6年,研究者主要在哪些方向参与KD的研究和推进工作。
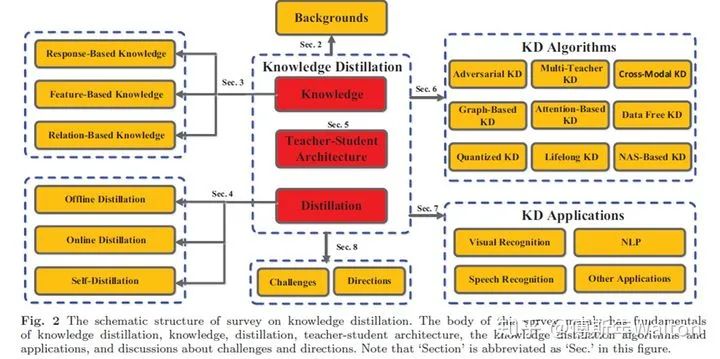
KD主要方法
作者参考这篇文章,从Logits(Response)-based, Feature-based, 和Relation-based knowledge三种维度去介绍KD在过去6年的一些高引用paper。
Logits(Response)-based knowledge从下图直观感受到,knowledge从teacher model的output layer学习得到;
Feature-based 是从一些中间hidden layers学习knowledge;Relation-based则是学习input-hidden-output之间的关系。
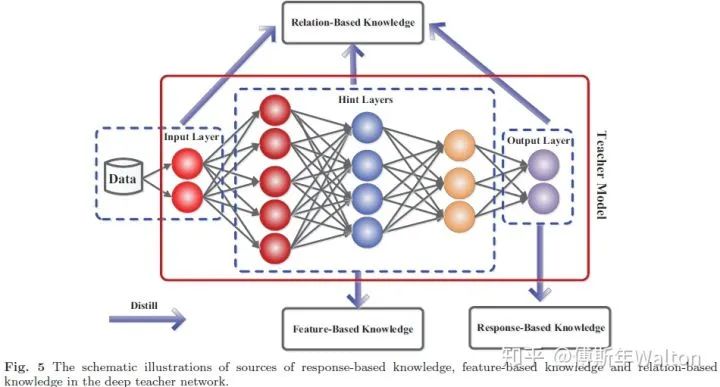
为了大家方便阅读,先列出来三种方法主要代表paper:
1.Logits(Response)-based
Distilling the Knowledge in a Neural Network Hilton NIPS 2014
Deep mutual learning CVPR 2018
On the efficacy of knowledge distillation, ICCV 2019
Self-training with noisy student improves imagenet classification 2019
Training deep neural networks in generations: A more tolerant teacher educates better students AAAI 2019
Distillation-based training for multi-exit architectures ICCV 2019
2. Feature-based
Fitnets: Hints for thin deep nets. ICLR 2015
Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. ICLR 2017
3. Relation-based
A gift from knowledge distillation: Fast optimization, network minimization and transfer learning CVPR 2017
Similarity-preserving knowledge distillation ICCV 2019
Logits(Response)-based Knowledge
Distilling the Knowledge in a Neural Network Hilton NIPS 2014
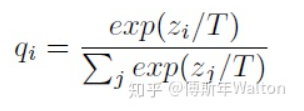

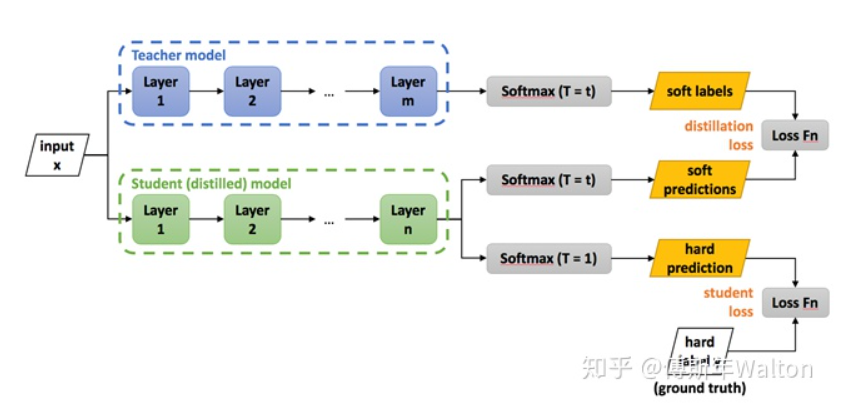
损失函数如下:
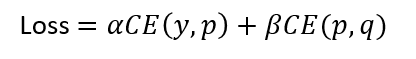
T通常设置为1,在paper中,ranging from 1 to 20。根据经验,student比teacher模型小很多时,T设置小一点。
如果T接近于0,则最大的值会越近1,其它值会接近0,近似于onehot编码。如果T越大,则输出的结果的分布越平缓,相当于平滑的一个作用,起到保留相似信息的作用。
如果T等于无穷,就是一个均匀分布。默认α +β=1 , 初始设置 α = β = 0.5,但是实验中 α << β ,结果较好。试验结果如下:
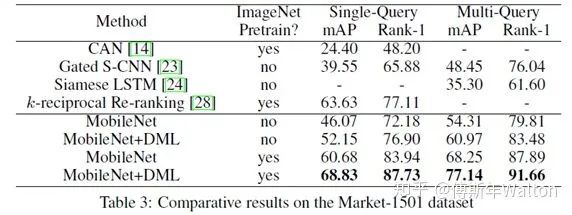
Deep mutual learning CVPR 2018
传统蒸馏模型是从功能强大的大型网络或集成网络转移到结构简单,运行快速的小型网络。
本文打破这种预先定义好的“强弱关系”,提出DML,即让一组学生网络在训练过程中相互学习、相互指导,而不是静态的预先定义好教师和学生之间的单向转换通路。
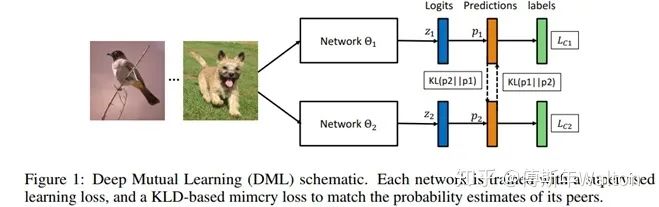
作者引入KL散度的概念来度量两个学生网络的输出概率p1和p2。
相信了解过GAN网络的小伙伴对KL应该不会陌生,KL 散度是一种衡量两个概率分布的匹配程度的指标,两个分布差异越大,KL散度越大。作者采用KL散度,衡量这两个网络的预测p1和p2是否匹配。
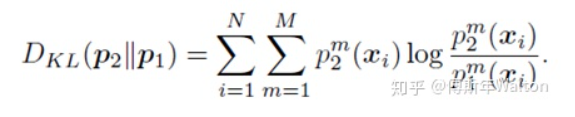
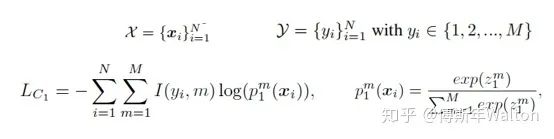

最后训练的loss函数是两个学生网络分别训练,各自的cross-entropy Loss和KL散度Loss之和。
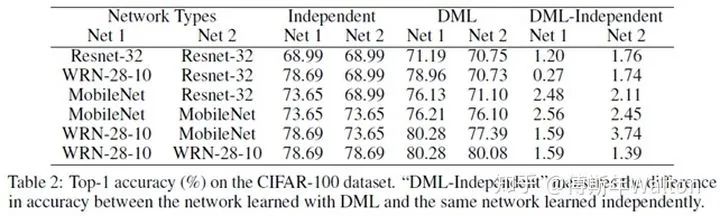
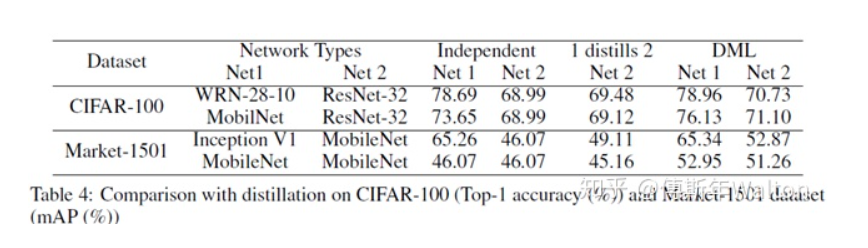
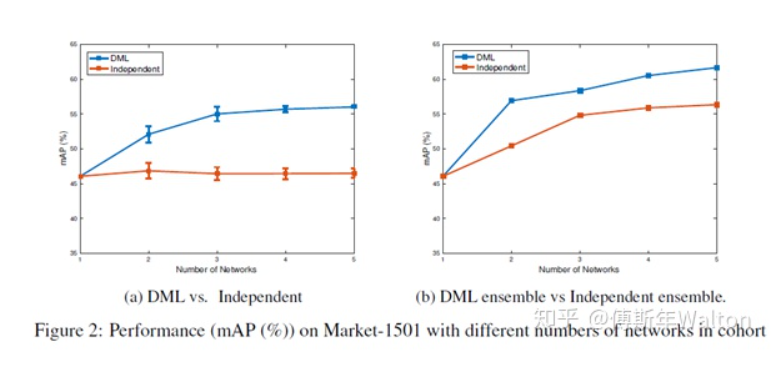
试验结果,效果很明显,增幅很稳定,并且学生网络越多,效果也是线性上升。
On the efficacy of knowledge distillation, ICCV 2019
继续使用KD softed labels, 但是聚焦regularization。作者实验观察到,并不是性能越好的teacher就能蒸馏出更好的student;
推测是容量不匹配的原因,导致student模型不能够mimic teacher,反而带偏了主要的loss;提出一种early-stop teacher regularization进行蒸馏,接近收敛时要提前停止蒸馏。
如下图,teacher网络越深,student蒸馏效果并一定提升。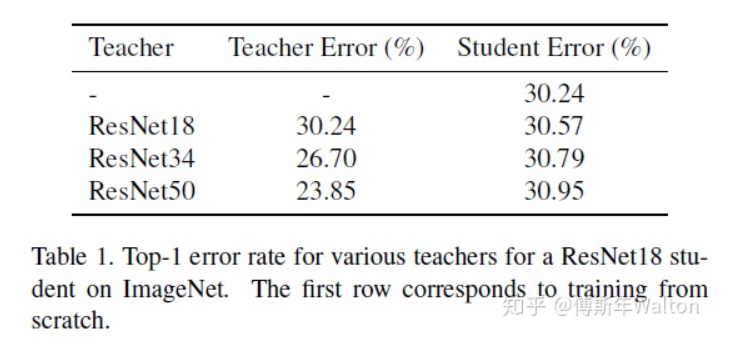
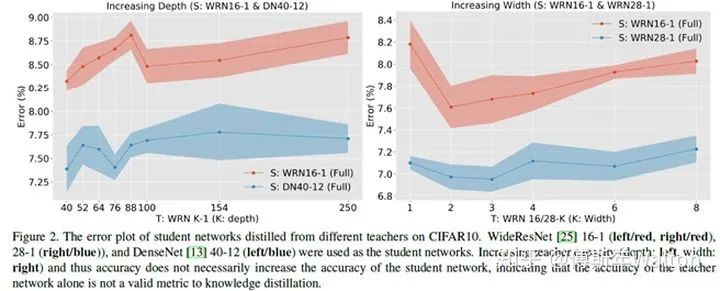
具体early-stop teacher regularization的策略作者没有写出来,但是可以推测到就是根据训练loss曲线,看是否接近收敛,如果接近收敛,则停止蒸馏。
实验结果如下:
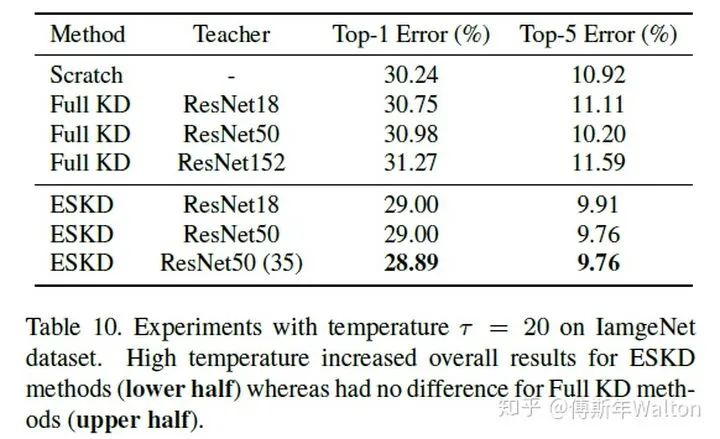
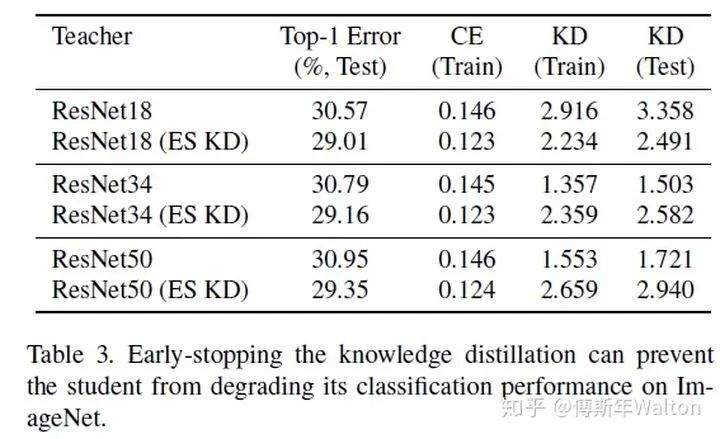
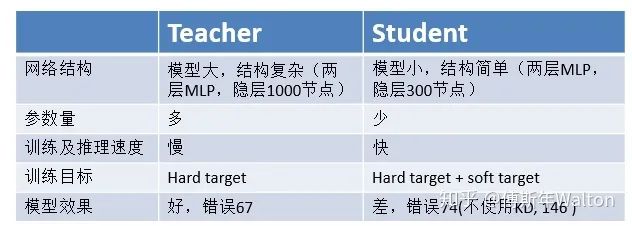
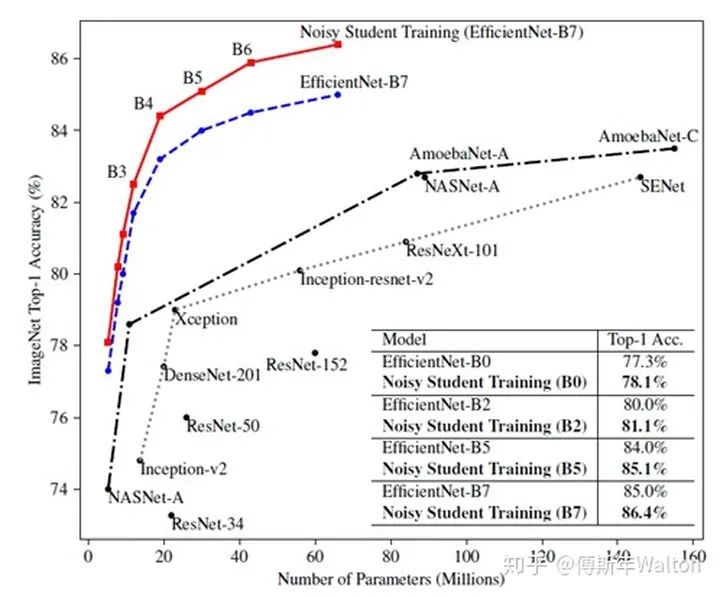
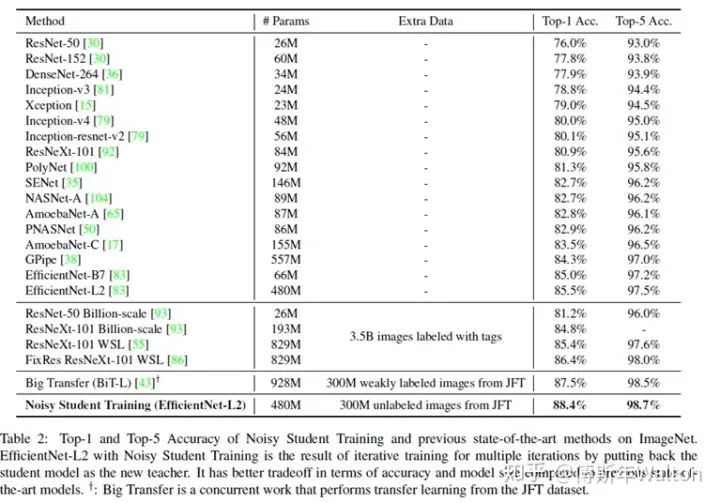
Self-training with noisy student improves imagenet classification 2019
继续使用KD softed labels, 但是聚焦data issue,通过使用更大的噪声数据集来训练student模型。
大致思路:
首先在ImageNet上训练Teacher Network 再使用训练好的T网络(无噪音)来对另一个数据集JFT dataset生成尽可能准确的伪标签 之后使用生成伪标签的数据集JFT dataset和ImageNet一起训练Student Network
除此之外,作者还提到一些tricks:
在Student Network训练中,增加了模型噪音(DropOut 0.5、随机深度 0.8、随机增强 震级27 ),提高鲁棒性和泛化能力 数据过滤,将教师模型中置信度不高的图片过滤,因为这通常代表着域外图像 数据平衡,平衡不同类别的图片数量 教师模型输出的标签使用软标签
Training deep neural networks in generations: A more tolerant teacher educates better students AAAI 2019
继续使用KD softed labels, 但是在蒸馏过程中通过增加约束来达到优化目标,通常约束加在teacher或者student network。
大致思路:作者发现除了ground Truth class, secondary class可以有效学习类间相似度,并且防止student network过拟合,取得好的效果。
作者挑选了几个具有最高置信度分数的类,并假设这些类在语义上更可能与输入图像相似。
设置了一个固定的整数K,代表每个图像语义上合理的类的数量,包括ground Truth类。
然后计算ground Truth类与其他得分最高的K-1类之间的差距。损失函数推导:
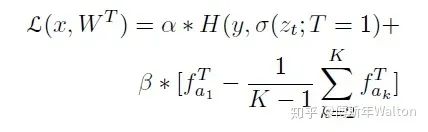
实验结果,K越大,效果越明显。

Distillation-based training for multi-exit architectures ICCV 2019
通常KD在student和teacher network网络模型容量相差较大时,表现较差。
Ensemble distribution KD方法可以很好的保证分布diversity,同时多个模型融合的结构较好。
大致思路:作者借鉴muti-exit architectures去做ensemble distribution KD,扩展提出新的损失函数。
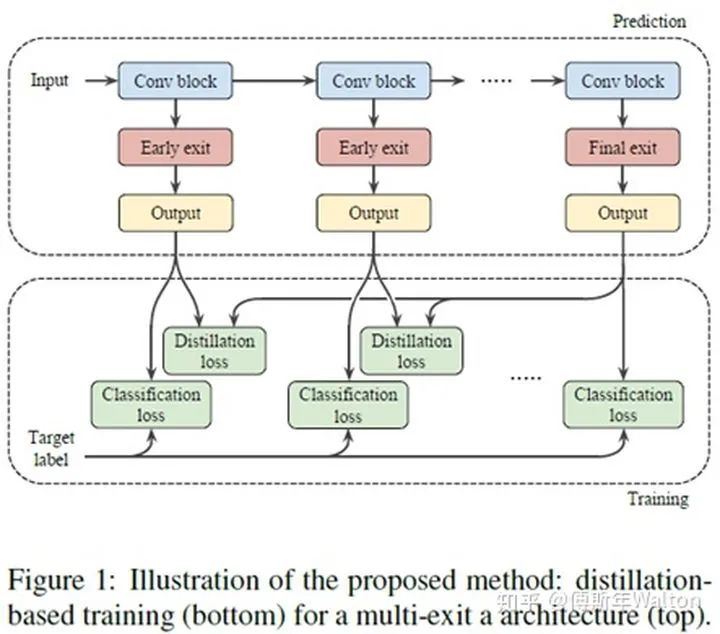
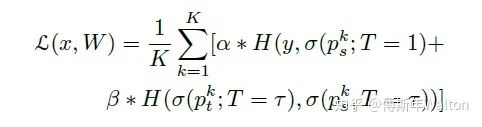
优点:
1.简单易于理解,student模型学teacher模型输出的概率分布,相当于给出了类别之间的相似性信息,提供了额外的监督信号,学起来更容易。
2.对于输出层,实现简单方便
缺点:
1.蒸馏效率依赖于softmax loss计算和number of class
2.对于没有label(low-level vision)的问题,无法去做
3.当student network模型太小时,很难从teacher network distilled成功
Feature-based Knowledge
Fitnets: Hints for thin deep nets. ICLR 2015
首次提出通过intermediate feature layers学习knowledge。
大致思路:
1. 选择teacher模型特征提取器的第N层输出作为hint,从第一层到第N层的参数对应图中的Whint;
2.选择student模型特征提取器的第M层输出作为guided,从第一层到第M层的参数对应图中的WGuided,student和teacher特征图维度可能不匹配,因此在student引入卷积层调整器,记为r,对guided的维度进行调整;
3. 阶段一训练,最小化特征损失函数,uh表示teacher模型从第一层到第N层对应的函数,vg表示student模型从第一层到第M层对应的函数,r表示卷积层调整器,对应的参数记为Wr。
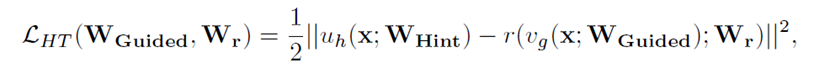
4.阶段二训练,因为阶段一没有label信息,蒸馏粒度不够细,因此论文引入阶段二的训练,利用hinton提出的knowledge distillation对student模型进行蒸馏
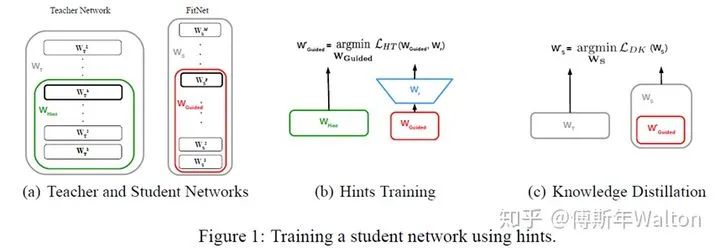
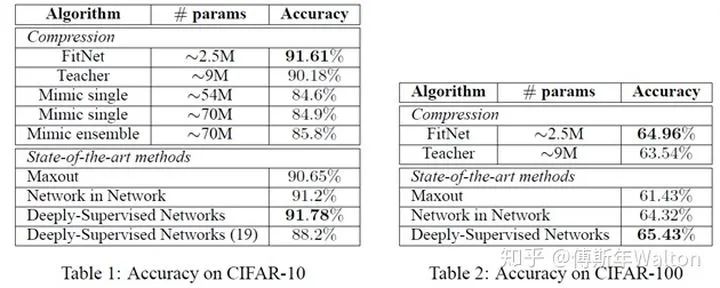
实验结果:
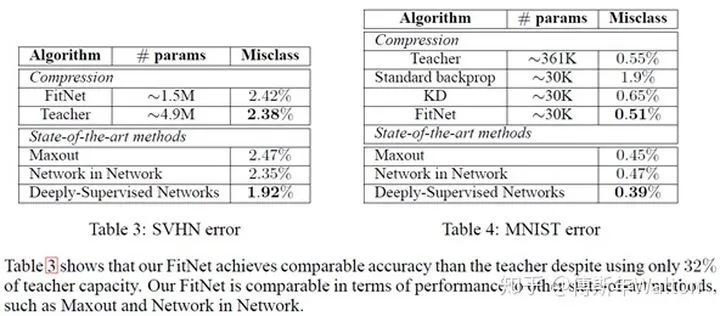

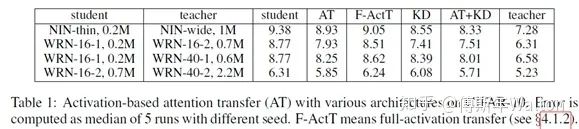
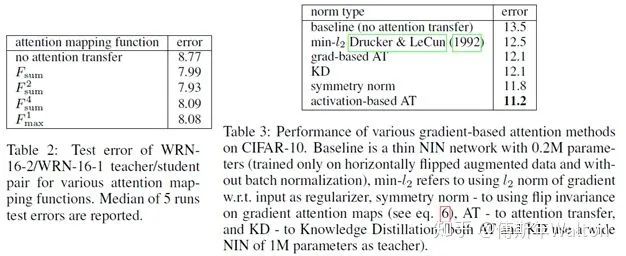
Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. ICLR 2017
通过提取Teacher模型生成的注意力图来指导Student模型,使Student模型生成的注意力图与Teacher模型相似。
这样简单模型不仅可以学到特征信息,还能够了解如何提炼特征信息。使得Student模型生成的特征更加灵活,不局限于Teacher模型。

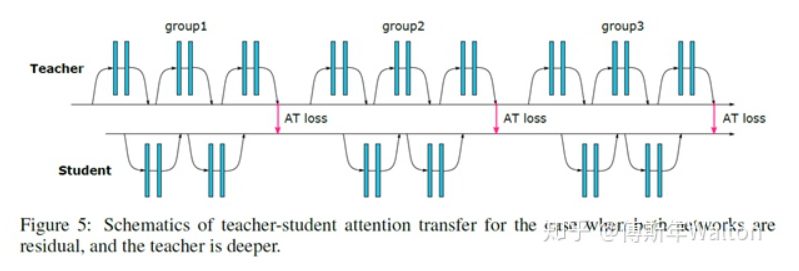
作者论文中提出两种attention的计算方式:
思路1:Activation-based attention transfer, 对卷积网络隐藏层输出的特征图——feature map(特征 & 知识)进行迁移(Attention transfer),让学生网络的feature map与教师网络的feature map尽可能相似,步骤如下:
1. 将Teacher网络和Student网络都分成n个part(两者分part的数量相同),保证学生网络和教师网络每个part的最后一个卷积层得到的feature map的size大小相同,都是W * H(数量可以不同)
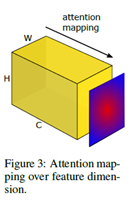
2. 为了计算loss,每个part的最后一个卷积层C个W * H的特征图变换为1个W* H的的二维张量,为了定义这个空间注意力映射函数,一个潜在假设是,隐层神经元激活(网络在预测时的结果)的绝对值可以用于指示这个神经元的重要性,这样我们可以计算通道维度的统计量, 具体而言,我们考虑如下如下三种空间注意力图:

3.Loss函数,paper中p=2,所以是L2 loss
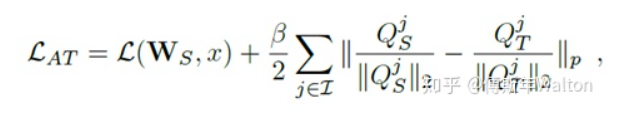
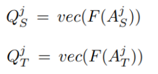
思路2:Gradient-based attention transfer,Loss对输入X求导,判断损失函数对于输入X的敏感性,pay more attnetion to值得注意的像素(梯度大的像素)
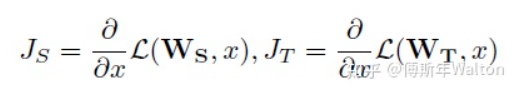
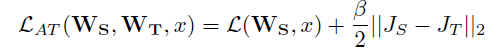
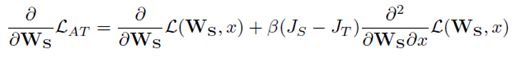
实验结果如下:

Relation-based Knowledge
A gift from knowledge distillation: Fast optimization, network minimization and transfer learning CVPR 2017
不拟合Teacher模型的输出,而是去拟合Teacher模型层与层之间的关系,类似于老师教学生做题,中间的结果并不重要,更应该学习解题流程。
关系通过层与层之间的内积(点乘)来定义。
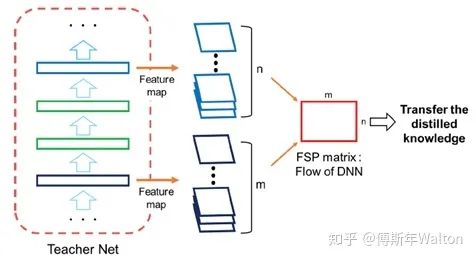
假如说甲层有 M 个输出通道,乙层有 N 个输出通道,就构建一个 M*N 的矩阵来表示这两层间的关系,其中 (i, j) 元是甲层第 i 个通道 和 乙层第 j 个通道的内积(因此此方法需要甲乙两层 feature map 的形状相同)。
作者使用residual module,从而避免spatial size的相同计算。如果为了保证feature map spatial size相等,可以使用zero padding。
文中把这个矩阵叫 FSP (flow of solution procedure) 矩阵,其实这也是一种 Gram 矩阵,之前一篇很有名的文章 Neural Style 里也有成功的应用:用 Gram 矩阵来描述图像纹理,从而实现风格转换。Gram矩阵是计算每个通道i与通道j的feature map的内积。
Gram matrix的每个值都可以说是代表i通道的feature map与通道j的feature map互相关的程度。x代表输入图像,W代表FSP weights,F1/F2是产生的feature map,h*w代表feature map的height, width;m/n代表channel。
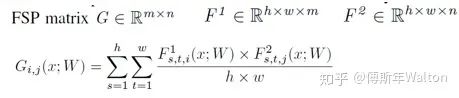
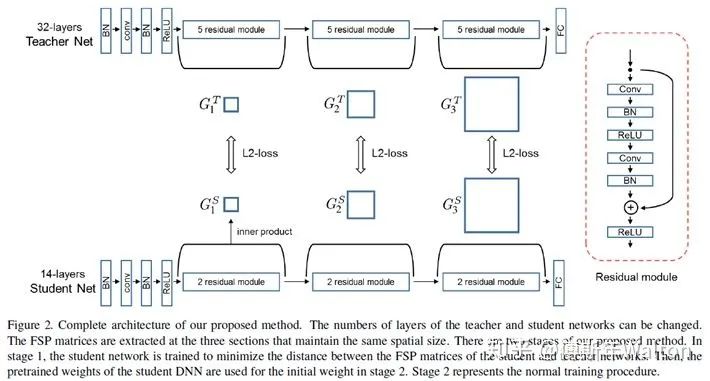
具体步骤:
1.最小化teacher模型FSP矩阵与student模型FSP矩阵之间的L2 Loss,用来初始化student模型的可训练参数。
lamda代表不同层/点的权重系数,paper里面设置为相同权重。
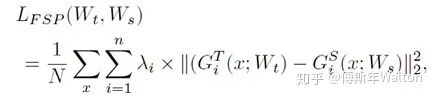
2. 在目标任务的数据集上fine-tunestudent模型实验结果:

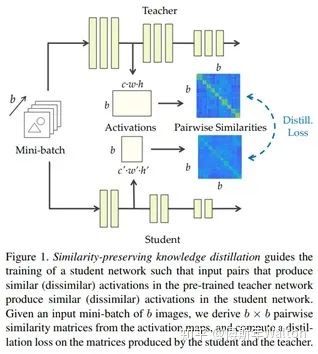
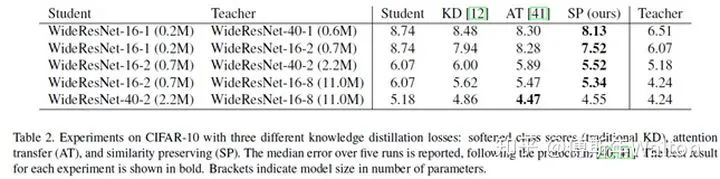
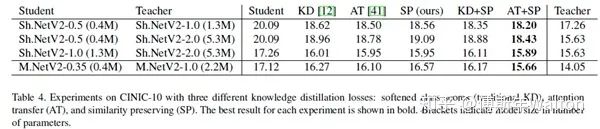
Similarity-preserving knowledge distillation ICCV 2019
如果两个输入在老\师网络中有着高度相似的激活,那么引导学生网络趋向于对该输入同样产生高的相似激活(反之亦然)的参数组合,那将是有利的(对于学生更好的学老\师网络的能力与知识)。
基于这个观察和假设,本文主要思路提出了一个保留相似性损失,来促使学生网络学老\师网络在对于数据内部的关系表达的知识。
假设证明试验:
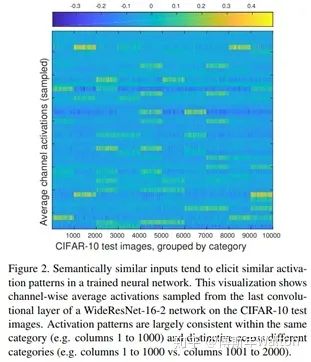
图2这个图指示了CIFAR-10中10000张图片分别对应于教师网络最后一个卷积层的激活值中所有通道内计算均值得到的矢量,整体绘制出来得到的结果。
这里分成了十类,每一类对应相邻的1000张图片,可见,相邻的1000张图片的激活情况是类似的,而不同类别之间有明显差异。
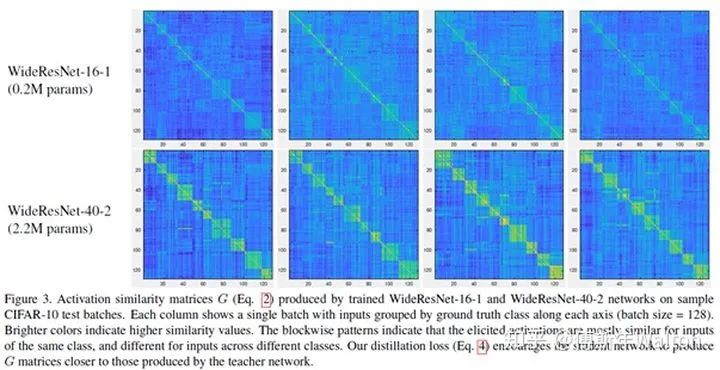
图3中展示了对于CIFAR-10测试集上的数个batch的G矩阵可视化结果,这里的激活是从最后一个卷积层收集而来的。
• 每一列表示一个单独的batch,两个网络都是一致的。
• 每个batch的图像中,对于样本的顺序已经通过其真值类别分组。一个batch包含128张图片样本。在两行的G矩阵中,显示了独特的块状模式,这指示了者系网络的最后一层的激活,在相同类别的时候有着相似的结果,而不同类别也有着不同的结果,也就是前者有着更大的相似性,后者相似性较小。
• 图中每个块大小不同,这主要是因为不同类别在每个batch中包含的样本数不同。
• 上下对比也可以看出来,对于复杂模型(下面),块状模式更加明显突出,这也反映出来,其对于捕获数据集的语义信息有着更强的能力。
• 这样的现象也在一定程度上支撑了本文的假设,也反映出前面提出的相似性损失的意义与价值所在,就是促使学生网络可以更好的模仿学老师模型对于数据特征中的关联信息的学习。
保留相似性损失函数推导:
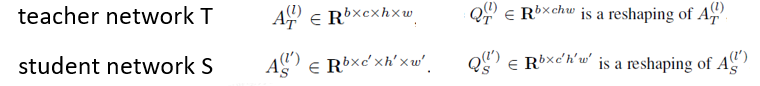

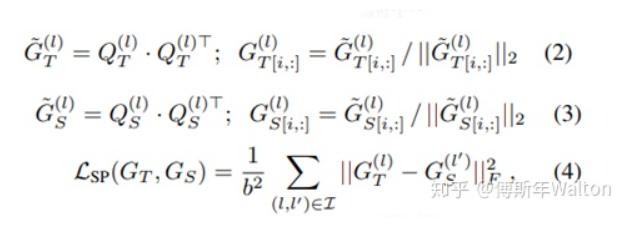
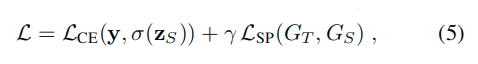
实验结果:
Feature/Relation-based Knowledge优缺点总结:
优点
泛化性更好,目前SOTA的方法都是基于feature/Relation 可以处理cross domain transfer and low-level vision问题
对于信息损失很难度量,因此很难选择最好的方法。 大多数方法随机选择intermediate layers,可解释性不够 特征的蒸馏位置手动选择或基于任务选择
Applications-NLP-BERT
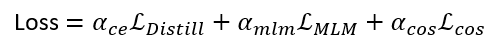
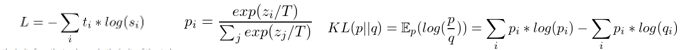
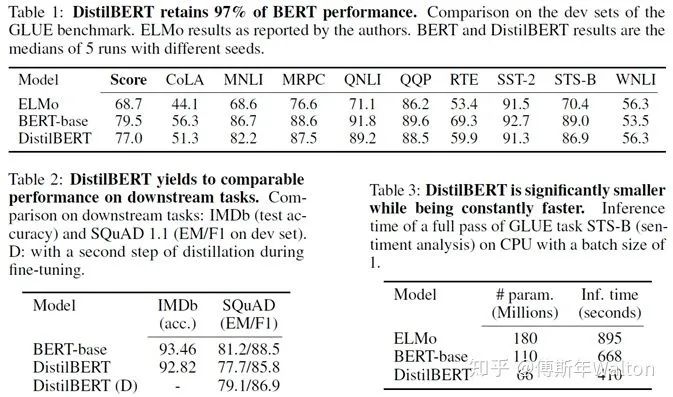
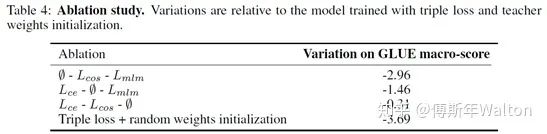

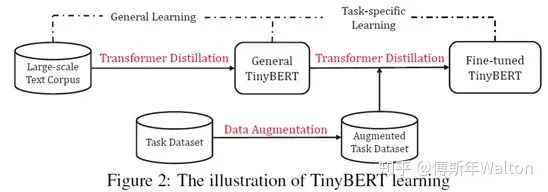
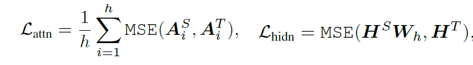
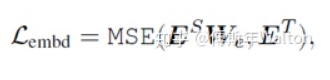
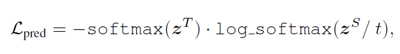
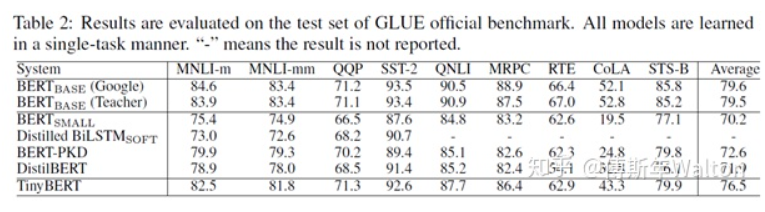
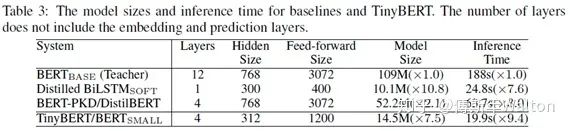
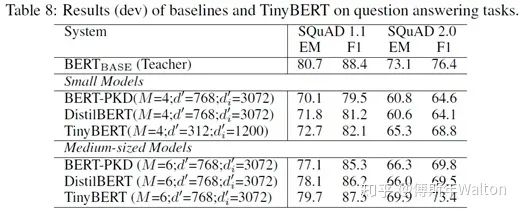
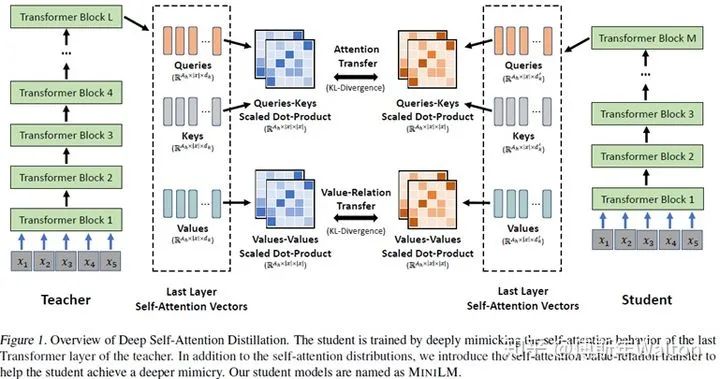
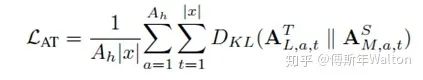
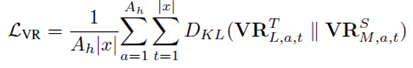
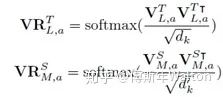

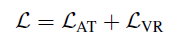
实验结果:
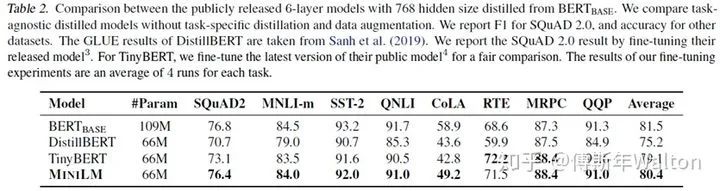
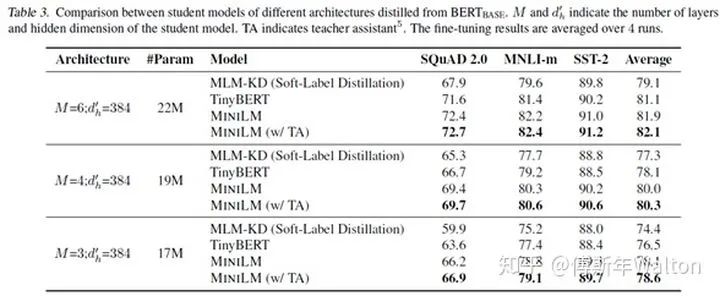
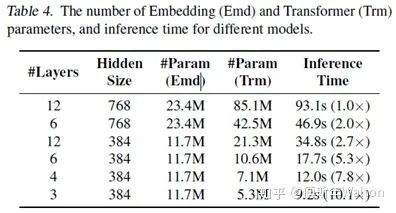
QA
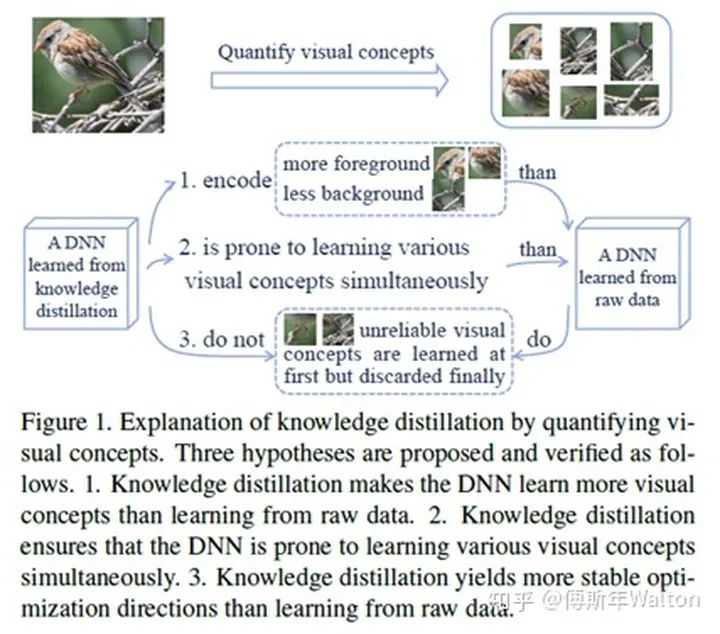
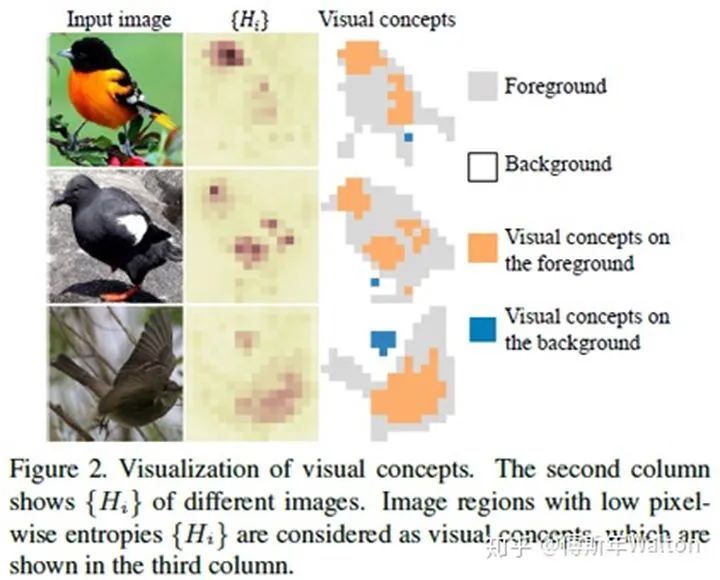
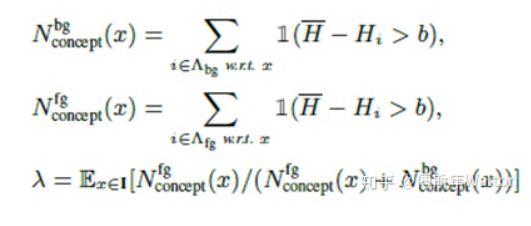
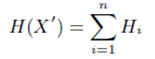
H(x) 是整张图的information entropy,它由每个像素点的entropy组成,  和
和  分别代表背景和前景上的number of visual concepts。x 是输入图像, 函数I代表is the indicator function。
分别代表背景和前景上的number of visual concepts。x 是输入图像, 函数I代表is the indicator function。
括号里面的条件满足时,返回1;否则返回0。 代表 整个背景的平均熵值,用来测量信息的重要性。 as a baseline entropy. b是一个正实数。
代表 整个背景的平均熵值,用来测量信息的重要性。 as a baseline entropy. b是一个正实数。  该指标用于衡量 特征的判别力。
该指标用于衡量 特征的判别力。
所以在训练结束后,如果 , 越大, 越小,证明假设一ok。具体请看最后试验结果汇总表3。
假设二证明:
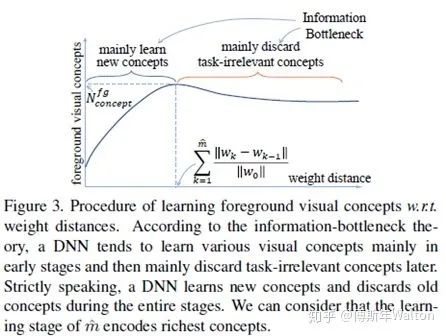
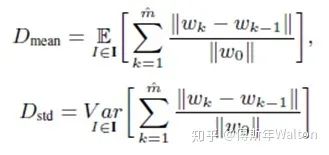
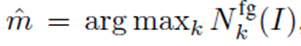
其实思路很直观,是否前景 随着训练epoch number增加而快速增加;是否不同input images的前景 增加。因此作者提出两个参数去度量不同visual concepts的学习速度。
Dmean平均值和Dstd标准差。作者首先定义了一个参数叫weight distance ,weight distance是定义 to measure the learning effect at 第几个epoch,k代表不同的epoch number 。w0 代表初始参数wk 代表在k个epoch之后的参数。  代表 达到最大时的epoch number。
代表 达到最大时的epoch number。
Dmean 代表平均的weight distance,即DNN获得的前景forground visual concepts数量,Dmean反应了DNN学习visual concepts的速度是否快,越小越好;Dstd代表不同图片之间的weight distance标准差,它意味着DNNs是否同时学到这些visual concepts。也是越小越好。
总结下,就是越小的Dmean 和 Dstd意味着DNN学习visual concepts越快越同时。具体请看最后试验结果汇总表3。
假设三证明:
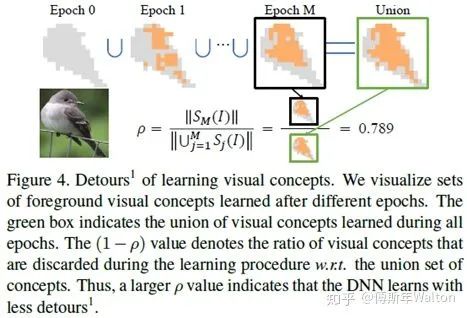
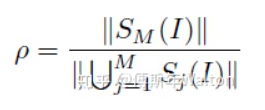
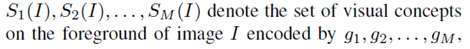
 表示DNN少走弯路,更稳定地优化;反之亦然。具体请看最后试验结果汇总表3。
表示DNN少走弯路,更稳定地优化;反之亦然。具体请看最后试验结果汇总表3。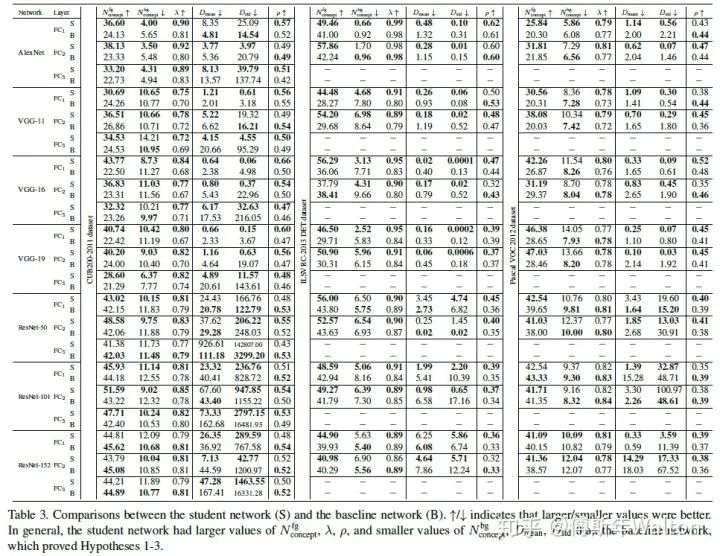
Variational information distillation for knowledge transfer. CVPR 2019
作者总结到,KD其实是最大化teacher network 和student network之间的mutual information(互信息)。
通过大量的数学推导,得出下面的公式。具体推导过程,读者可以看原paper。

t代表教师网络的中间层,s代表相对应的student网络的中间层,c,h,w分别对应channel,height,width;q(t|s)是variational distribution变异分布,公式如图所示,是一个高斯均方差分布和标准差之和。
有了这个公式,可以画出它学习过程中的variational distribution的heat map热度图(红色像素代表概率越高),我们直接看图。
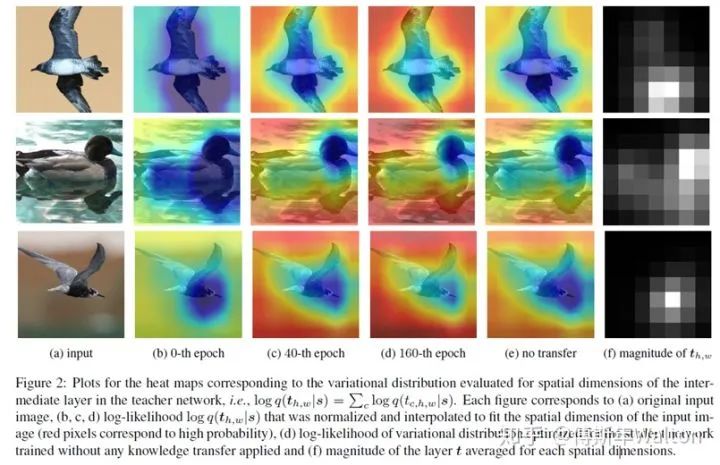
图a是输入图像,图(b,c和d)是不同训练epoch下的student网络和teacher网络variational distribution的密度heat map变化,观察到学生网络通过训练,根据教师网络去估计中间层的密度分布;
同时作为比较,作者也画出了未经KD训练的学生网络和老师网络的variational distribution的密度heat map变化(图e所示)。
通过e和b/c/d的相互比较,我们观察到e无法获得较高的variational distribution对数似然概率,这表明教师与学生网络之间的相互信息较少。
即作者的推断和理论推导work,KD其实是最大化teacher network 和student network之间的mutual information(互信息)。
2. QA-Are bigger models better teachers?
On the efficacy of knowledge distillation. ICCV 2019

模型容量不匹配,导致student模型不能够mimic teacher,反而带偏了主要的loss;
KD losses 和accuracy不匹配,导致student虽然可以follow teacher, 但是并不能吸收teacher知识。
3. QA-Is a pretrained teacher important?
Deep mutual learning. CVPR 2018
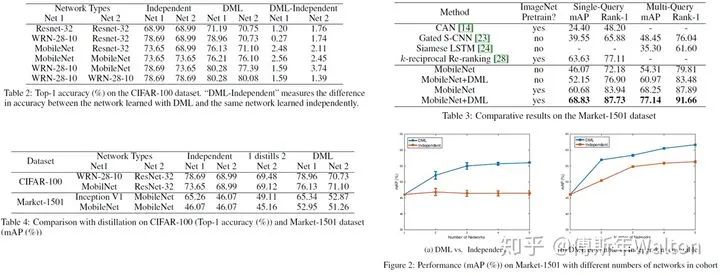
这篇paper其实两方面辩证来看,
1.假设没有一个pretrained的teacher模型,那KD在不同的peer students中间学习,也是可以获得不错的提高,所以pretrained的teacher其实没有那么重要,就拿bert这种大模型来说,如果pretrain一次大模型,需要很多数据,机器,时间成本去训练,那我们完全可以换几个小模型去训练,去做蒸馏;
2.如果在有pretrain的teacher前提下,那我们肯定让teacher更好的含有知识,就拿图像分类来说,它在imagnet上pre-train,再去fine tune其他模型,效果很明显。
4. QA-Single teacher vs multiple teachers
Learning from multiple teacher networks. SIGKDD 2017
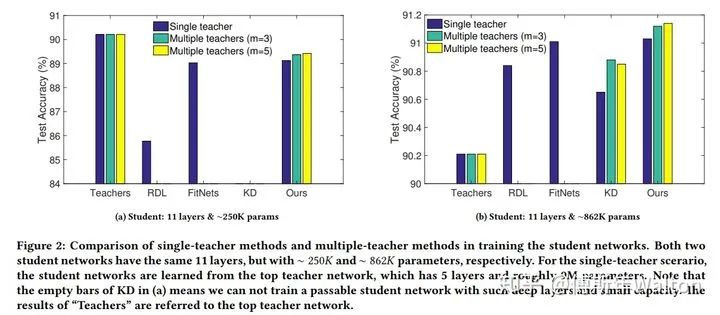
后记:20篇paper简单回顾下KD在过去6年的发展,可以看到一些令人激动或者眼前一亮的工作。欢迎大家和我继续交流,我们一起探索KD更多的可能性。
在part2/3/4的陈述中,我没有加paper的引用和下载链接,但是都列出每一篇paper的title和发表年份,读者们感兴趣自行搜索即可
参考:
