
Vision Transformers 大有可为!
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
Vision Transformers 相关的研究最近非常的火,这篇文章是最近看到的,个人觉得相对讲解的比较通俗,以及很多图解帮助理解。
因此,我也花了很多时间去翻译(文章内容 6700字左右),如果对你有所帮助,欢迎给个三连。周末愉快!
视频讲解:https://www.bilibili.com/video/BV1sA41157Fk#reply4390470040

Transformers 简介
Transformers 是一个非常强大的深度学习模型,已经能够成为许多自然语言处理任务的标准,并准备彻底改变计算机视觉领域。
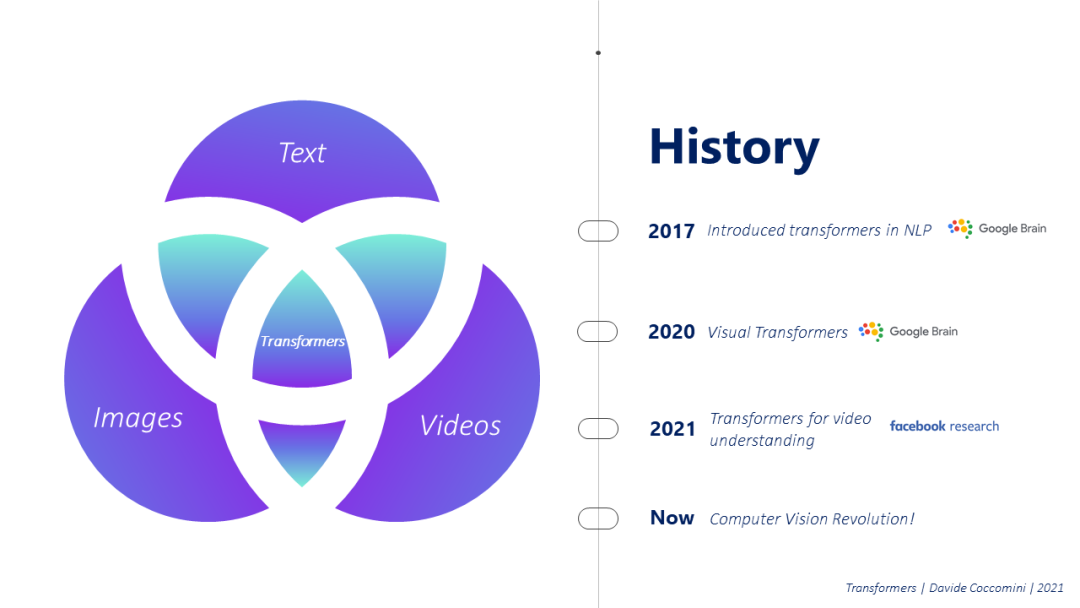
这一切都始于2017年,谷歌大脑发表了一篇注定要改变一切的论文,Attention Is All You Need[4]。研究人员将这种新的体系结构应用于几个自然语言处理问题,很快就可以看出,这种体系结构在多大程度上可以克服困扰RNN的一些限制,RNN通常用于从一种语言翻译到另一种语言等任务。
这些年来,Transformers 已经成为自然语言处理领域的一个学派,谷歌大脑在2020年问道,变Transformers 在图像上会同样有效吗?答案是肯定的,视觉 Transformers诞生了,经过对图像的一些初步修改,他们成功地开发了Transformers的经典结构,并很快在这个领域的许多问题上达到了 state of the art 。
激动人心的是,几个月后,在2021年初,Facebook的研究人员发布了一个新版本的Transformers,但是这次,特别是视频,TimeSformers。显然,即使在这种情况下,经过一些微小的结构变化,这种架构很快就成为视频领域的赢家,Facebook在2021年2月宣布,它将把它与社交网站的视频结合起来,为各种目的创建新的模型。
Why do we need transformers?
但是,让我们退一步,探究促使谷歌研究人员寻找新的替代体系结构来解决自然语言处理任务的动机。

传统上,像翻译这样的任务是使用递归神经网络(Recurrent Neural Networks)来完成的,众所周知,递归神经网络有很多问题。主要问题之一是它的顺序操作。例如,要将一个句子从英语翻译成意大利语,使用这种类型的网络,将要翻译的句子的第一个单词与初始状态一起传递到编码器,然后将下一个状态与该句子的第二个单词一起传递到第二个编码器,依此类推直到最后一个单词。最后一个编码器的结果状态随后被传递给解码器,解码器作为输出返回第一个翻译的字和随后的状态,该状态被传递给另一个解码器,依此类推。
很明显这里的问题,要完成下一步,我必须有上一步的结果。这是一个很大的缺陷,因为你没有利用现代gpu的并行化功能,因此在性能方面会有所损失。还有其他问题,如梯度爆炸,无法检测同一句话中远隔词之间的依赖关系,等等。
Attention is all you need?
于是问题就出现了,有没有一种机制可以让我们以并行的方式计算,让我们从句子中提取我们需要的信息?答案是肯定的,这种机制就是注意力(attention)。

如果我们将注意力遗忘定义为任何技术和实现方面,我们将如何着手这样做?
让我们举一个例句问问自己,把注意力集中在“gave”这个词上,我应该把注意力放在这个句子中的哪些词上,来增加这个词的意思?我可能会问自己一系列问题,例如,谁给的?在这种情况下,我会把注意力集中在“I”这个词上,然后我可能会问给谁了?把我的注意力放在查理这个词上,最后,我可能会问,你给了我什么?最后集中在食物这个词上。
通过问我自己这些问题,也许对句子中的每个单词都这样做,我也许能够理解其中的含义和方面。现在的问题是,如何在实践中实现这个概念?
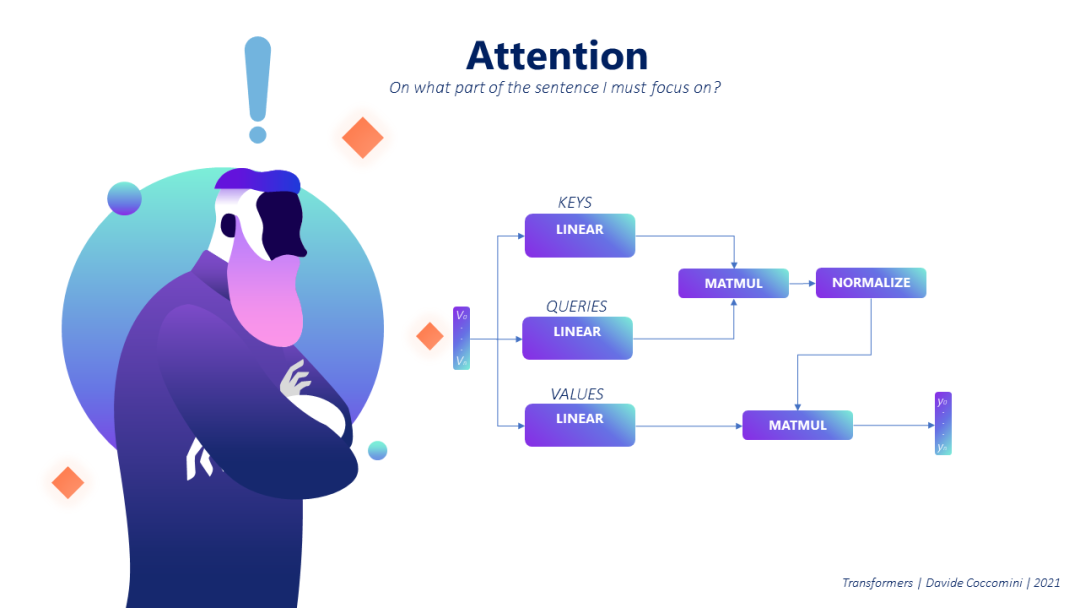
为了理解注意力的计算,我们可以将注意力的计算与数据库世界进行比较。当我们在数据库中进行搜索时,我们提交一个查询(Q),并在可用数据中搜索一个或多个满足查询的键。输出是与查询最相关的键关联的值。

注意力计算的情况非常相似。我们首先把要计算注意力的句子看作一组向量。每个单词,通过一个单词嵌入机制,被编码成一个向量。我们认为这些向量是搜索的关键,关于我们正在搜索的查询,它可以是来自同一个句子(自我注意)或来自另一个句子的单词。在这一点上,我们需要计算查询和每个可用键之间的相似性,通过缩放点积进行数学计算。这个过程将返回一系列实际值,可能彼此非常不同,但是由于我们希望获得0和1之间的权重,其和等于1,因此我们对结果应用SoftMax。一旦获得了权重,我们就必须将每个单词的权重以及它与查询的相关性乘以表示它的向量。我们最终返回这些产品的组合作为注意向量。
为了建立这种机制,我们使用 linear layers,从输入向量开始,通过矩阵乘法生成键、查询和值。键和查询的组合将允许在这两个集合之间获得最正确的匹配,其结果将与值组合以获得最相关的组合。
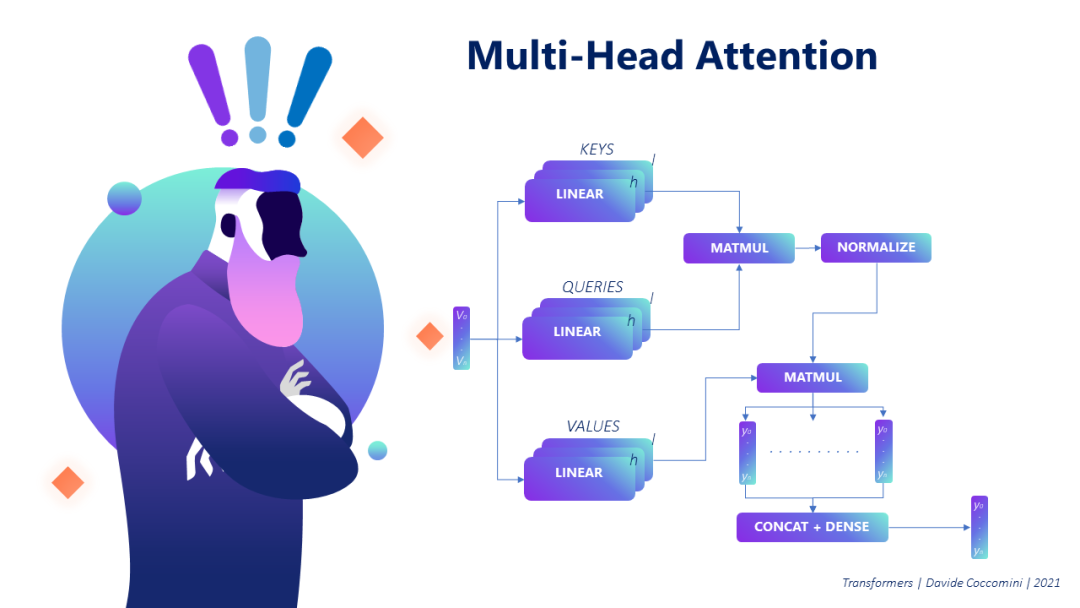
但是,如果我们想把注意力集中在一个单词上,这个机制就足够了,但是如果我们想从几个角度看这个句子,然后并行计算几次注意力,会怎么样?我们使用所谓的多头注意力,其结构类似,其结果在最后简单地组合,以返回所有计算出的注意力的单一汇总向量。
既然我们已经了解了应该使用哪种机制并确定了它的可并行性,那么让我们分析一下多头部注意力embedded的结构以及构成transformer.的结构。

考虑到总是一个翻译任务,让我们首先关注图像的左边部分,编码部分,它将整个句子作为输入从英语翻译成意大利语。在这里我们已经看到,与RNN方法相比有一个巨大的革命,因为它不是逐字处理句子,而是完全提交。在进行注意力计算之前,表示单词的向量与基于正弦和余弦的位置编码机制相结合,该机制将单词在句子中的位置信息嵌入向量中。这一点非常重要,因为我们知道,在任何语言中,单词在句子中的位置都是非常相关的,如果我们想做出正确的评价,这是绝对不能丢失的信息。所有这些信息都被传递到一个多头注意机制中,其结果被标准化并传递给一个前馈。编码可以进行N次以获得更有意义的信息。
但是要翻译的句子不是唯一输入transformer的,我们有第二块,解码器,它接收到transformer先前执行的输出。例如,如果我们假设我们已经翻译了前两个单词,并且我们想用意大利语预测句子的第三个单词,我们将把前两个翻译的单词传给解码器。将对这些单词执行位置编码和多头部注意,结果将与编码器结果相结合。对组合重新计算注意,结果通过linear layer和softmax,将成为潜在候选词的向量,作为新翻译词,并且每个词都有关联的概率。在下一次迭代中,解码器除了前面的单词之外,还将接收这个单词。
因此,这种结构被证明是非常有效和高性能的,这是因为它处理整个句子,而不是逐字逐句,保留有关单词在句子中位置的信息,并利用注意力这一能够有效表达句子内容的机制。
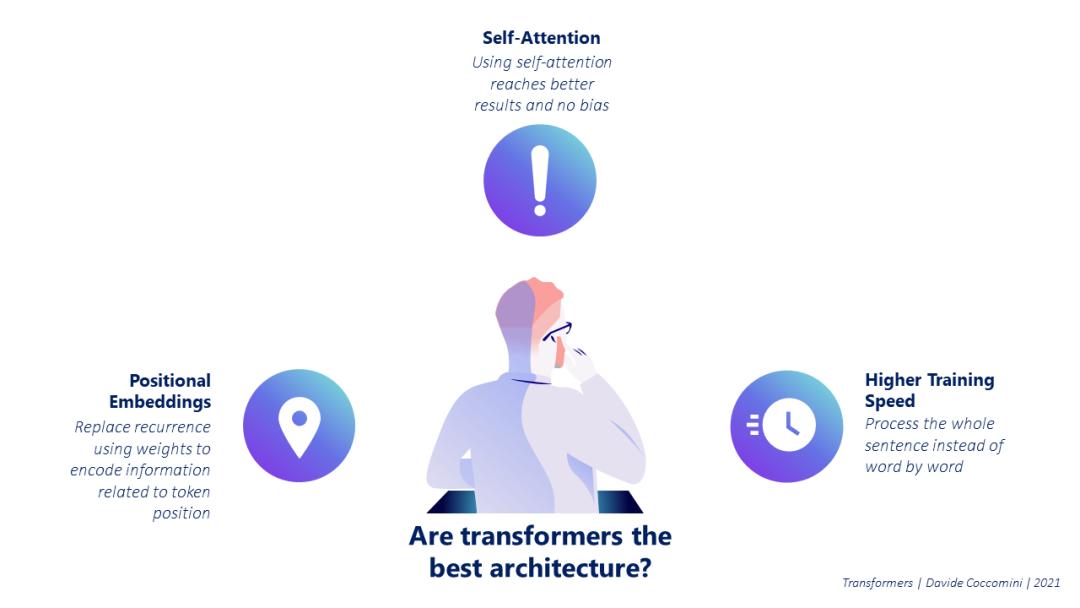
在所有这些很好的解释之后,你可能会认为transformer是完美的,没有任何缺陷。很显然,它不是这样的,它的优点之一也是它的缺点,计算注意!

为了计算每个单词相对于所有其他单词的注意力,我必须执行N²计算,即使部分可并行,仍然非常昂贵。有了这样的复杂性,让我们想象一下,在一段几百字的文字上,多次计算注意力意味着什么。
从图形上你可以想象一个矩阵,它必须填充每个单词相对于其他单词的注意力值,这显然是有昂贵的成本。必须指出的是,通常在解码器上,可以计算隐藏的注意,避免计算查询词和所有后续词之间的注意。

有些人可能会争论,但如果transformer带来的许多好处都与注意力机制有关,那么我们真的需要上面提到的所有结构吗?但2017年的第一份谷歌大脑论文不是说“注意力就是你所需要的一切”吗?[4] 当然是合法的,但在2021年3月,谷歌研究人员再次发表了一篇题为“注意力不是你所需要的全部”的论文[6]。那是什么意思?研究人员进行了实验,分析了在没有transformer任何其他组件的情况下进行的自我注意机制的行为,发现它以双指数速率收敛到秩1矩阵。这意味着这种机制本身实际上是无用的。那么为什么transformer如此强大呢?这是由于减少矩阵秩的自我注意机制与transformer的另外两个组成部分跳跃连接和MLP之间的拉锯战。
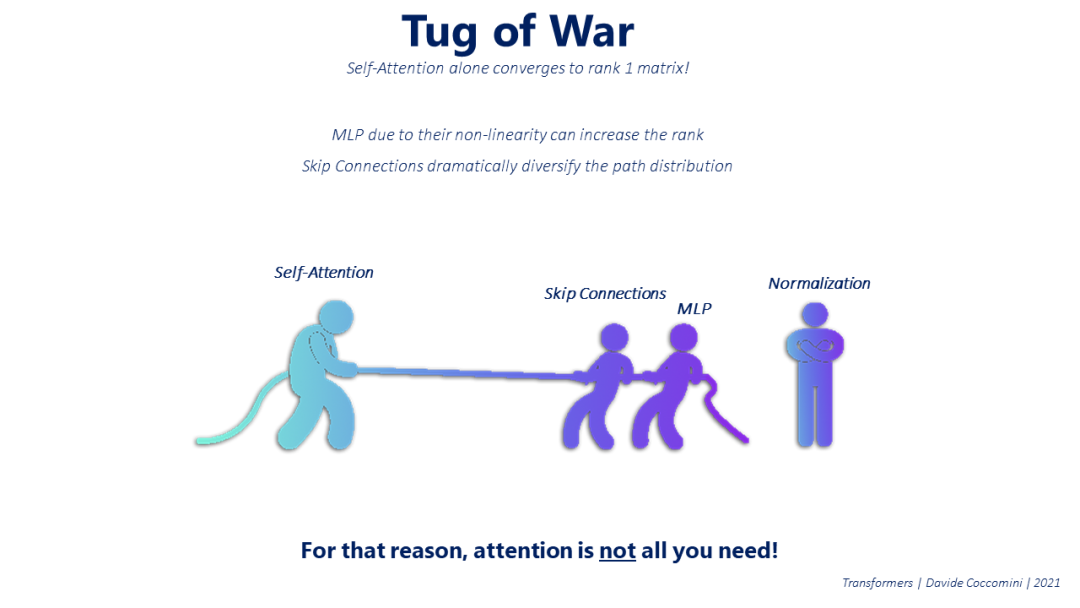
第一种方法允许路径的分布多样化,避免获得所有相同的路径,这大大降低了矩阵被降为秩1的概率。MLP由于其非线性,因此能够提高生成矩阵的秩。相反,有人表明,规范化在避免这种自我注意机制的行为方面没有作用。因此,注意力不是你所需要的全部,而是transformer架构设法利用它的优势来取得令人印象深刻的结果。
Vision Transformers
到了2020年,谷歌的研究人员又一次想到了这一点,“但是,如果人们发现Transformers在自然语言处理领域如此有效,它们将如何处理图像呢?”. 有点像NLP,我们从注意力的概念开始,但这一次适用于图像。让我们试着通过一个例子来理解它。

Image from “An Image Is Worth 16x16 words” (Dosovitskiy et al)
如果我们考虑一张狗站在墙前的照片,我们中的任何人都会说这是一张“picture of a dog”,而不是一张“picture of a wall”,这是因为我们把注意力集中在图像的主要和有区别的主体上,而这正是应用于图像的注意力机制所做的。
既然我们理解了注意力的概念也可以扩展到图像上,我们只需要找到一种方法,将图像输入到一个经典的transformer中。
我们知道 transformer把文字作为输入向量,那么我们怎样才能把图像转换成向量呢?当然,第一种解决方案是使用图像的所有像素并将它们“内联”以获得向量。但是让我们停一下,看看如果我们选择这个选项会发生什么。

我们之前说过,注意力的计算复杂度等于O(N²),这意味着如果我们必须计算每个像素相对于所有其他像素的复杂度,那么在像256x256像素这样的低分辨率图像中,我们的计算量会非常大,用现在的资源绝对无法克服。所以这种方法肯定是不可行的。
解决方案非常简单,在“一幅图像值16x16个字”[2]一文中,提出将图像分割成块,然后使用线性投影将每个块转化为向量,将块映射到向量空间中。

现在我们只需要去看看Vision Transformer的架构。

然后将图像划分为多个小块(patches),这些patches通过线性投影获得向量,这些向量与关于patches在图像中的位置的信息耦合,并提交给经典transformer。在图像中添加关于patches原始位置的信息是基本的,因为在线性投影过程中,即使充分理解图像的内容非常重要,这些信息也会丢失。插入另一个向量,该向量独立于所分析的图像,用于获得关于整个图像的全局信息,实际上,与该面片对应的输出是唯一被考虑并传递到MLP的输出,MLP将返回预测类。
然而,在这个过程中,有一点是信息损失非常严重的。实际上,在从patch到矢量的转换过程中,任何关于像素在patch中位置的信息都会丢失。(Transformer-in-Transformer,TnT)[3]的作者指出,这当然是一件很严重的事情,因为要进行质量预测,我们不希望丢失待分析图像一部分中像素的排列。
TnT的作者接着问自己,有没有可能找到一种更好的方法让向量提交给Transformer?他们的建议是将图像的每一个单独的patch(pxp),它们本身就是3个RGB通道上的图像,并将其转换成一个c通道张量。然后将这个张量分成p'部分,其中p'<p,在示例p'=4中。这就产生了c维中的p'向量。这些向量现在包含关于面片内像素排列的信息。

然后将它们串联并线性投影,以便使它们与从原始面片的线性投影获得并与之结合的向量大小相同。

通过这样做,transformer的输入向量也会受到patch内像素排列的影响,通过这样做,作者设法进一步提高了各种计算机视觉任务的性能。
TimeSformers
鉴于transformers在NLP中取得了巨大的成功,然后又将其应用于图像,2021年,Facebook的研究人员试图将这种架构应用于视频。
直观地说,很明显这是可能的,因为我们都知道,视频不过是一组帧一个接一个,帧不过是图像。

只有一个小细节,使他们不同于 Vision Transformers,你必须考虑到不仅是空间,而且时间。事实上,在这种情况下,当我们去计算注意力时,我们不能把这些帧看作孤立的图像,但我们应该找到某种形式的注意力,考虑到连续帧之间发生的变化,因为它是视频评估的中心。
为了解决这个问题,作者提出了几种新的注意机制,从那些只关注空间的,主要用作参考点的,到那些在空间和时间之间轴向、分散或联合计算注意的机制。
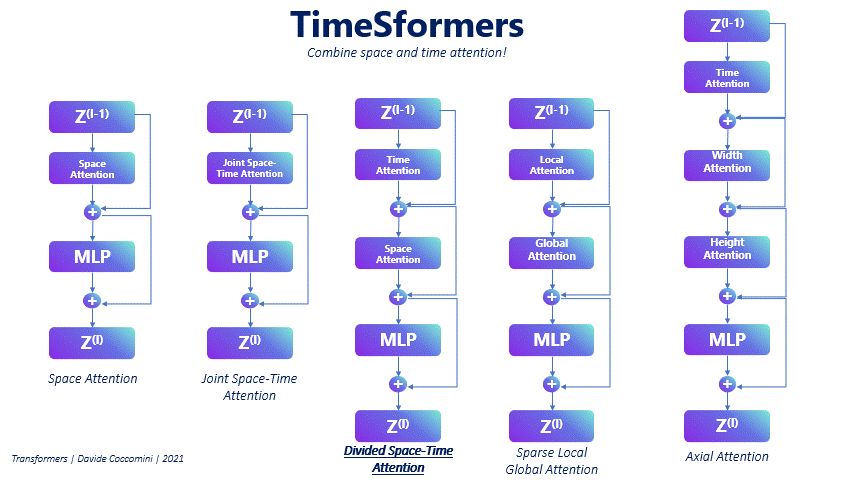
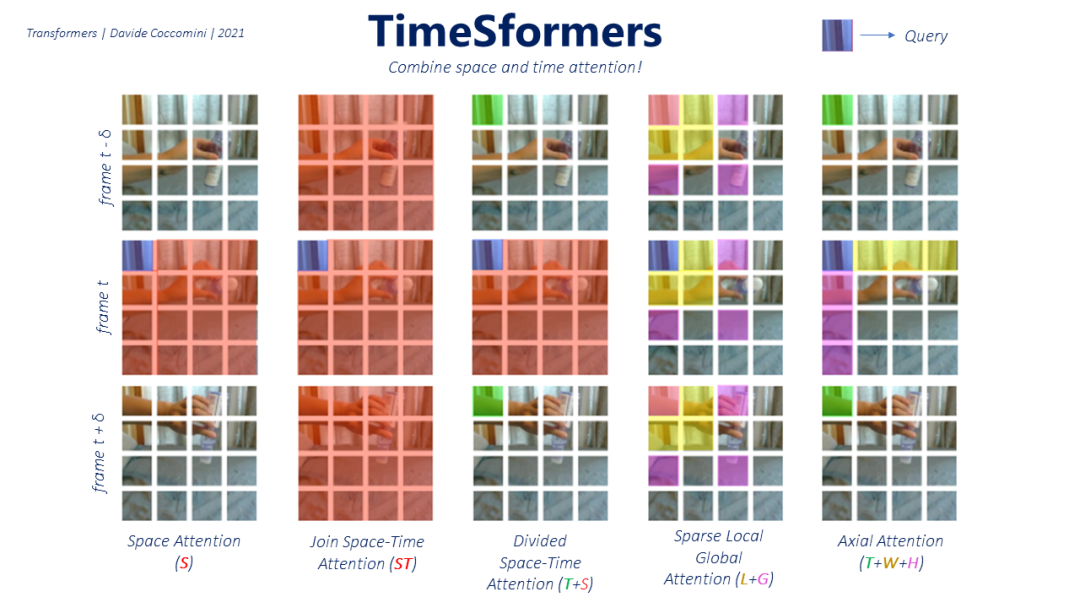
Image from “An Image Is Worth 16x16 words” (Dosovitskiy et al)
然而,取得最佳效果的方法是 Divided Space-Time Attention。它包括,给定一帧在瞬间t和它的一个patches作为一个查询,计算整个帧上的空间注意,然后在查询的同一patches中,但在前一帧和下一帧上的时间注意。
但为什么这种方法如此有效呢?原因是它比其他方法学习更多独立的特征,因此能够更好地理解不同类别的视频。我们可以在下面的可视化中看到这一点,其中每个视频都由空间中的一个点表示,其颜色表示它所属的类别。
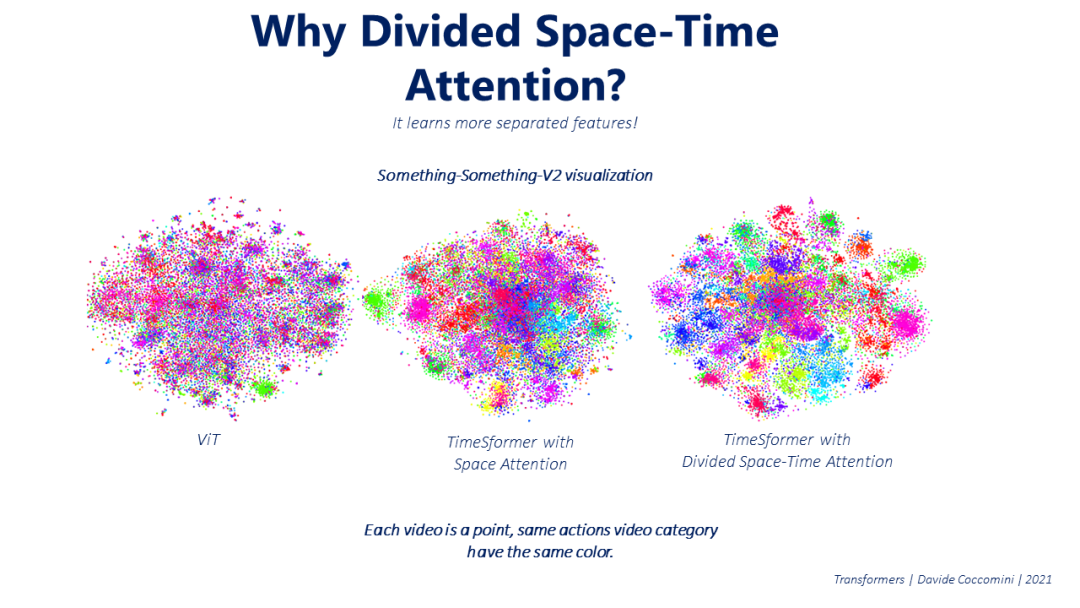
Image from “An Image Is Worth 16x16 words” (Dosovitskiy et al)
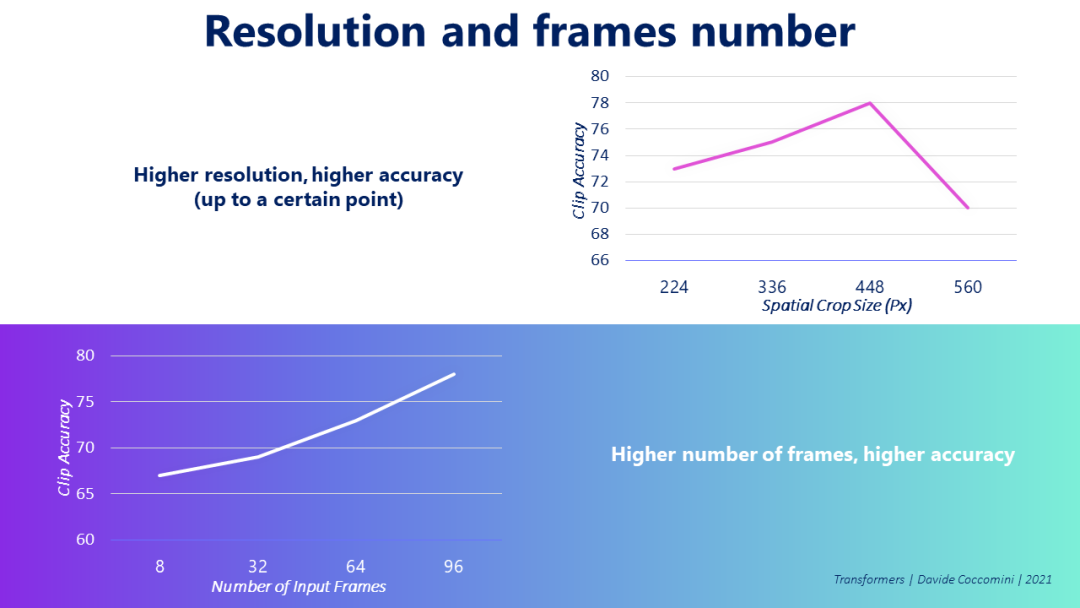
作者还质疑了视频分辨率和视频帧数的相关性,发现分辨率越高,模型的准确性就越好。至于帧数,同样随着帧数的增加,精确度也会增加。有趣的是,不可能用比图中显示的帧数更多的帧数进行测试,因此潜在的精确度仍然可以提高,我们还没有找到这种提高的上限。
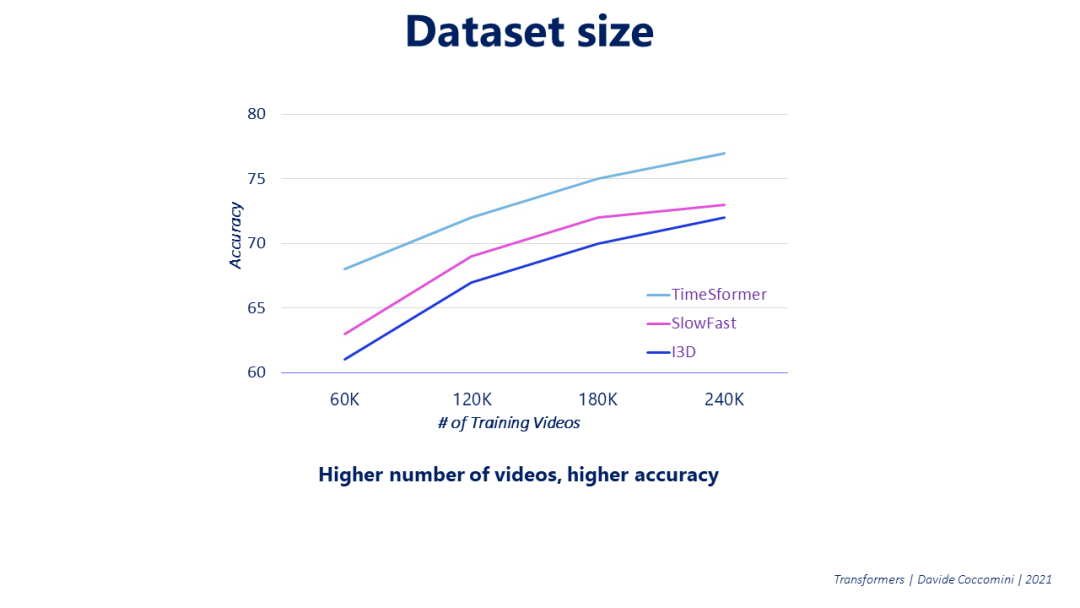
在Vision Transformers中,一个较大的训练数据集通常会导致更好的精确度。作者也在TimeSformers上检查了这一点,而且随着所考虑的训练视频数量的增加,准确率也会增加。
Conclusions
现在该怎么办?Transformers刚刚登陆计算机视觉领域,似乎下定决心要取代传统的卷积网络,或者至少在这一领域为自己开辟一个重要的角色。因此,科学界正处于混乱之中,试图进一步改进Transformers,将其与各种技术结合起来,并将其应用于实际问题,最终能够做一些直到最近才可能做到的事情。像Facebook和Google这样的大公司正在积极开发和应用Transformers,我们可能还只是触及了表面。
References and insights
[1] ”Gedas Bertasius, Heng Wang, and Lorenzo Torresani”. ”Is Space-Time Attention All You Need for Video Understanding?”.
[2] ”Alexey Dosovitskiy et al.”. ”An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale”.
[3] ”Kai Han et al.”. ”Transformer in Transformer”.
[4] ”Ashish Vaswani et al.”. ”Attention Is All You Need”.
[5] ”Qizhe Xie et al.”. ”Self-training with Noisy Student improves ImageNet classification”.
[6] “Yihe Dong et al.”, “Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth”
[7] “Nicola Messina et al.”, “Transformer Reasoning Network for Image-Text Matching and Retrieval”
[8] “Nicola Messina et al.”, “Fine-grained Visual Textual Alignment for Cross-Modal Retrieval using Transformer Encoders”
[9] “Davide Coccomini”, “TimeSformer for video classification with training code”
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看