CVPR2021:单目实时全身动作捕捉(清华大学)

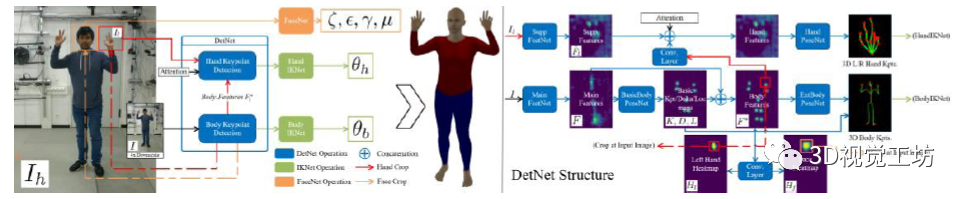
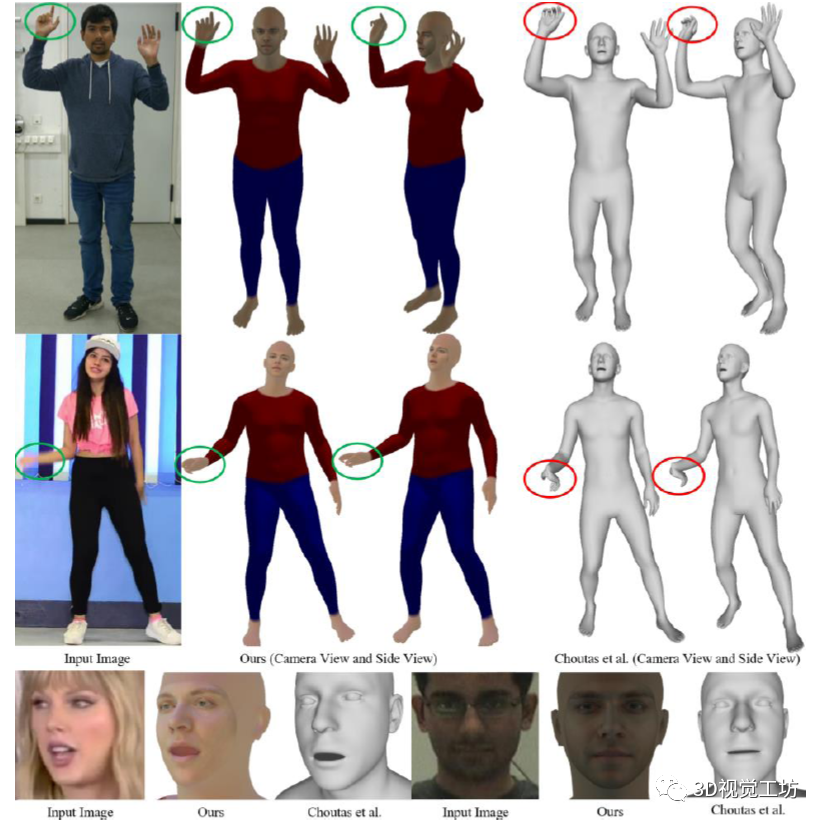
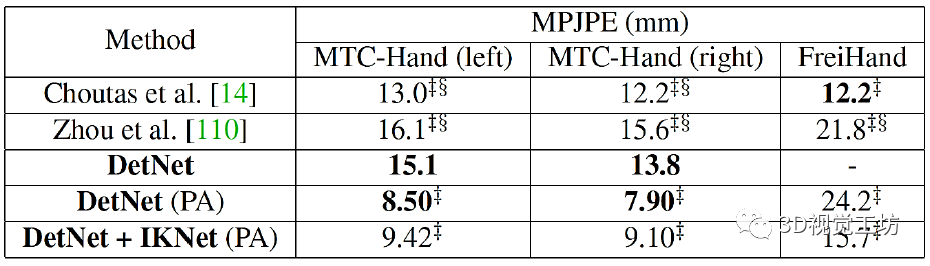
Monocular Real-time Full Body Capture with Inter-part Correlations


双一流高校研究生团队创建 ↓
专注于计算机视觉原创并分享相关知识 ☞
整理不易,点赞三连!
评论
 下载APP
下载APPMonocular Real-time Full Body Capture with Inter-part Correlations
双一流高校研究生团队创建 ↓
专注于计算机视觉原创并分享相关知识 ☞
整理不易,点赞三连!