
线程池最佳线程数量到底要如何配置?
一、前言
二、从实战开始
public class MyCallable implements Callable<String> {public String call() throws Exception {System.out.println("MyCallable call");return "success";}public static void main(String[] args) {ExecutorService threadPool = Executors.newSingleThreadExecutor();try {Futurefuture = threadPool.submit(new MyCallable()); System.out.println(future.get());} catch (Exception e) {System.out.println(e);} finally {threadPool.shutdown();}}}
三、创建线程池的方法
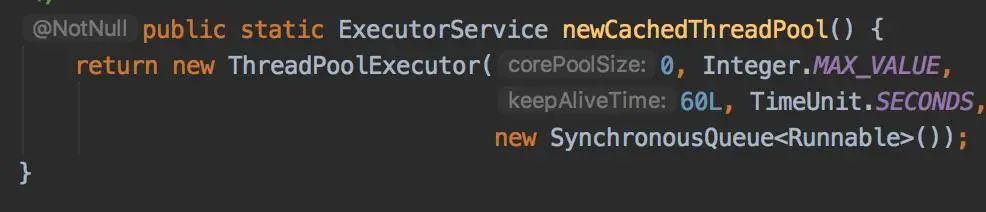


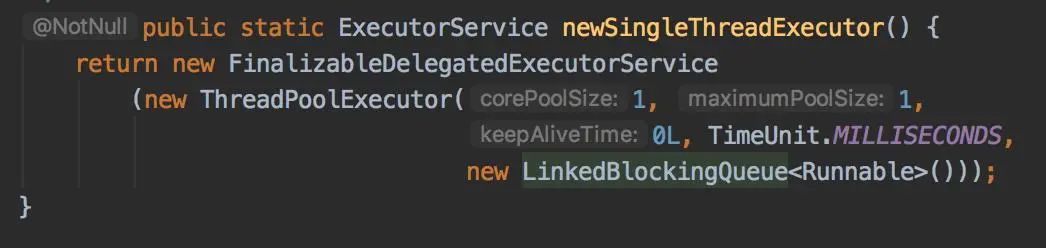

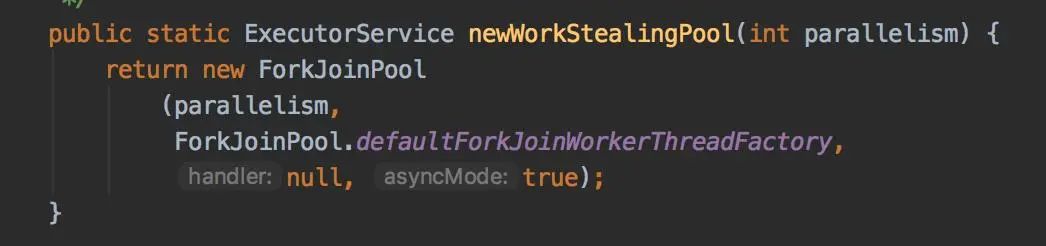
public class MyWorker implements Runnable {public void run() {System.out.println("MyWorker run");}public static void main(String[] args) {ExecutorService threadPool = Executors.newFixedThreadPool(8);try {threadPool.execute(new MyWorker());} catch (Exception e) {System.out.println(e);} finally {threadPool.shutdown();}}}
public class MyTask implements Runnable {public void run() {System.out.println("MyTask call");}public static void main(String[] args) {ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(8);try {scheduledExecutorService.schedule(new MyRunnable(), 60, TimeUnit.SECONDS);} finally {scheduledExecutorService.shutdown();}}}
四、自定义线程池

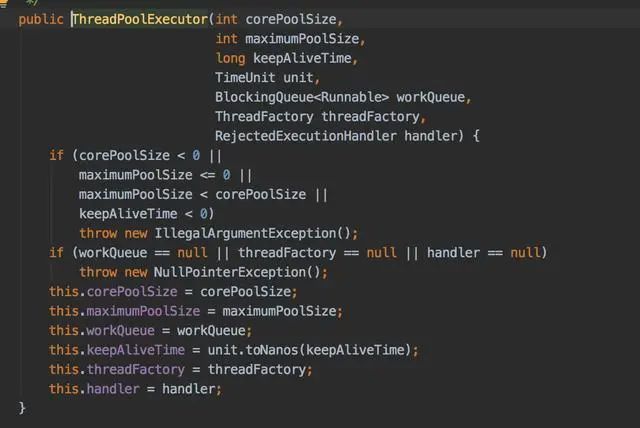
corePoolSize:核心线程数maximumPoolSize:最大线程数keepAliveTime:空闲线程回收时间间隔unit:空闲线程回收时间间隔单位workQueue:提交任务的队列,当线程数量超过核心线程数时,可以将任务提交到任务队列中。比较常用的有:ArrayBlockingQueue; LinkedBlockingQueue; SynchronousQueue;threadFactory:线程工厂,可以自定义线程的一些属性,比如:名称或者守护线程等handler:表示当拒绝处理任务时的策略
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
public class MyThreadPool implements Runnable {private static final ExecutorService executorService = new ThreadPoolExecutor(8,10,30,TimeUnit.SECONDS,new ArrayBlockingQueue<>(500),new ThreadPoolExecutor.AbortPolicy());public void run() {System.out.println("MyThreadPool run");}public static void main(String[] args) {int availableProcessors = Runtime.getRuntime().availableProcessors();try {executorService.execute(new MyThreadPool());} catch (Exception e) {System.out.println(e);} finally {executorService.shutdown();}}}
五、最佳线程数
什么是IO密集型? 比如:频繁读取磁盘上的数据,或者需要通过网络远程调用接口。 什么是CPU密集型? 比如:非常复杂的调用,循环次数很多,或者递归调用层次很深等。
int availableProcessors = Runtime.getRuntime().availableProcessors();最佳线程数目 = ((线程等待时间+线程CPU时间)/线程CPU时间 )* CPU数目有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️
评论