
EDA和数据挖掘实战:漫威与 DC电影收视率和票房分析

来源:DeepHub IMBA 本文约2200字,建议阅读8分钟
本文我们将根据一些数据来对比Marvel与DC, 数据总能说出真相。
MCU 与 DC
代码和分析
import pandas as pdimport scipy.stats as statsimport matplotlib.pyplot as pltfrom matplotlib.pyplot import figureimport plotlyimport plotly.express as px% matplotlib inline
df = pd.read_csv("/content/mdc.csv", encoding='latin-1')df.head()
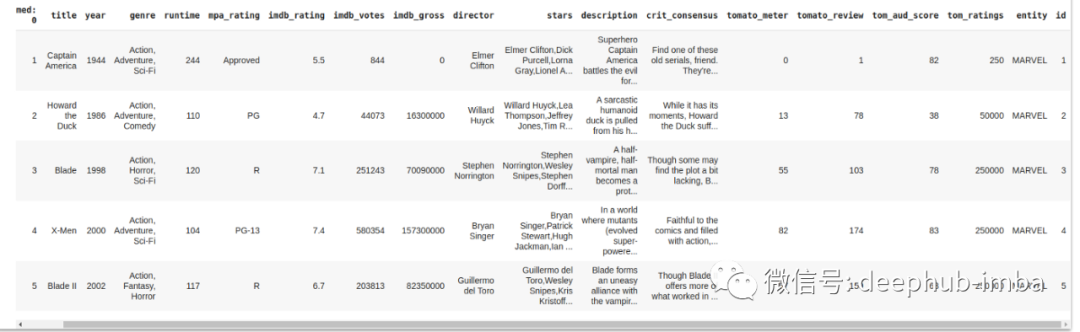
df.describe()df.info()
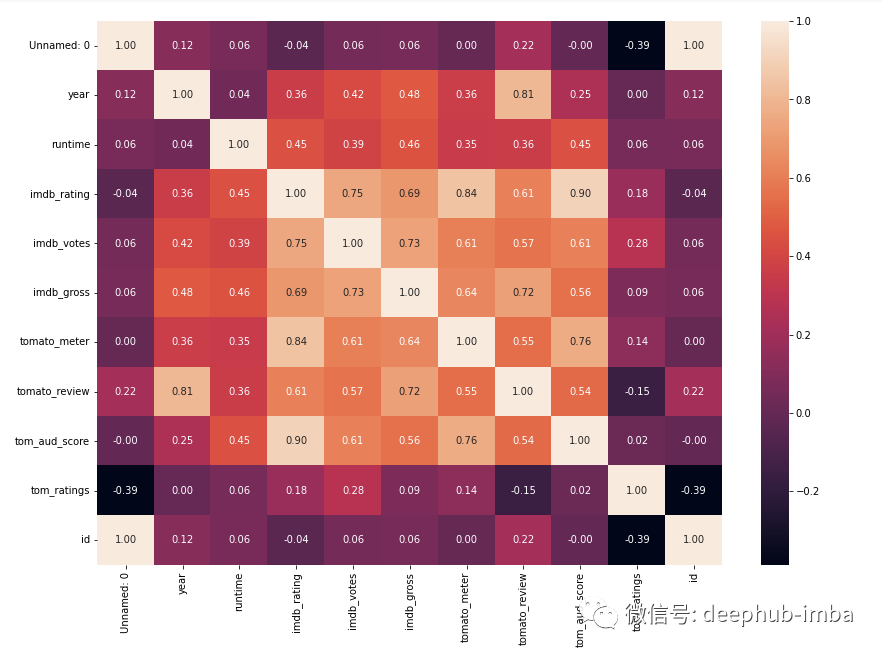
f,ax = plt.subplots(figsize=(14,10))sns.heatmap(df.corr(), annot=True, fmt=".2f", ax=ax)plt.show()
df[df.entity == 'MARVEL'].tail(5)df[df.entity == 'DC'].tail(5)
fig = plt.figure(figsize = (10,10))ax = fig.subplots()df.entity.value_counts().plot(ax=ax, kind='pie')ax.set_ylabel("")ax.set_title("MARVEL VS DC (No. of Movies)")plt.show()
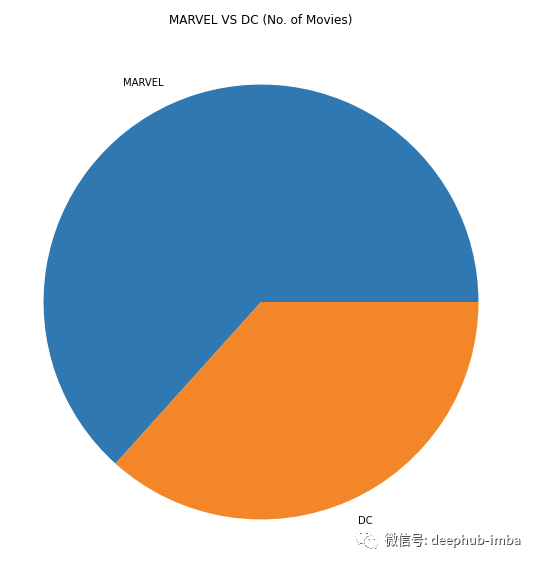
fig = plt.figure(figsize = (10,10))ax = fig.subplots()df[df.entity == 'MARVEL'].genre.value_counts().plot(ax=ax, kind='pie')ax.set_ylabel("")ax.set_title("Marvel Movie Genre Type")plt.show()
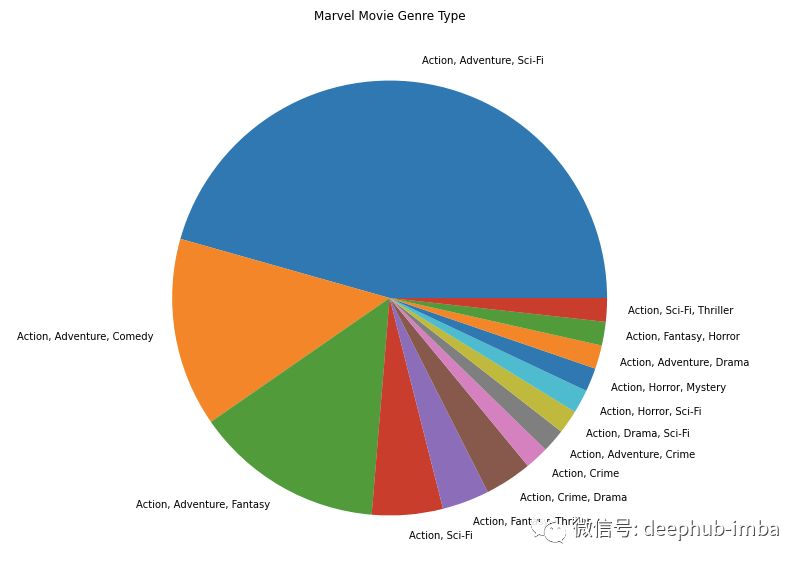
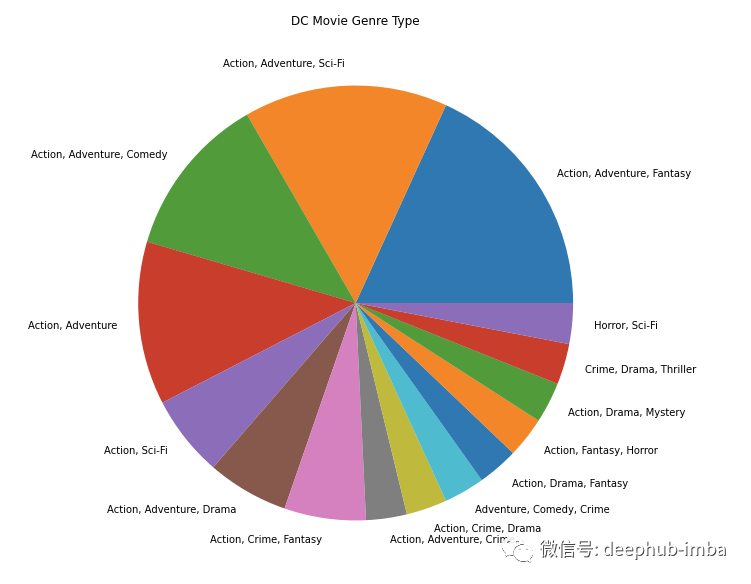
fig = plt.figure(figsize = (10,10))ax = fig.subplots()df[df.entity == 'DC'].genre.value_counts().plot(ax=ax, kind='pie')ax.set_ylabel("")ax.set_title("DC Movie Genre Type")plt.show()
dc_movies = df[df.entity == 'DC']marvel_movies = df[df.entity == 'MARVEL']#Average and highest rated of dc moviesavrg_dc_imdb = dc_movies['imdb_rating'].mean()avrg_dc_imdb = dc_movies['imdb_rating'].mean()highest_dc_imdb = dc_movies['imdb_rating'].max()print("Average: ",avrg_dc_imdb, "\n Highest: ",highest_dc_imdb)#Average and highest rated of marvel moviesavrg_marvel_imdb = marvel_movies['imdb_rating'].mean()highest_marvel_imdb = marvel_movies['imdb_rating'].max()print("Average: ",avrg_marvel_imdb, "\n Highest: ",highest_marvel_imdb)
结果是这样:
###DC###Average: 6.133333333333335Highest: 9.0###MARVEL####Average: 6.794736842105261Highest: 8.4
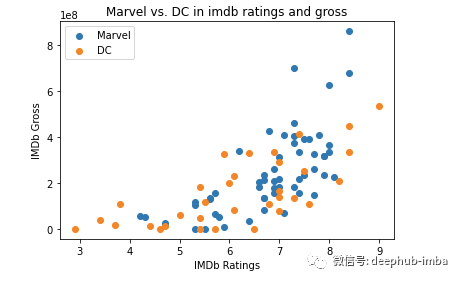
plt.scatter(data = marvel_movies, x = 'imdb_rating', y = 'imdb_gross')plt.scatter(data = dc_movies, x = 'imdb_rating', y = 'imdb_gross')plt.title('Marvel vs. DC in imdb ratings and gross')plt.xlabel('IMDb Ratings')plt.ylabel('IMDb Gross')plt.legend(['Marvel', 'DC'])
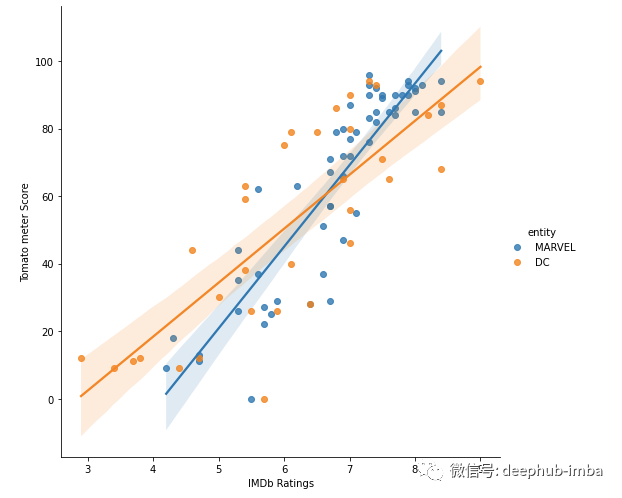
imdb_vs_tm = sns.lmplot(data=df, x="imdb_rating", y="tomato_meter", hue="entity", height=7)imdb_vs_tm.set_axis_labels("IMDb Ratings", "Tomato meter Score")
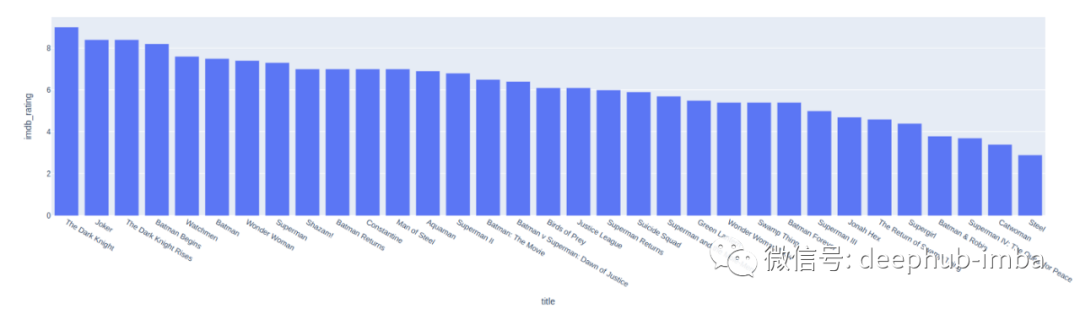
top_dc_movie = dc_movies.groupby('title').sum().sort_values('imdb_rating', ascending=False)top_dc_movie = top_dc_movie.reset_index()px.bar(x='title', y ="imdb_rating", data_frame=top_dc_movie)
top_marvel_movie = marvel_movies.groupby('title').sum().sort_values('imdb_rating', ascending=False)top_marvel_movie = top_marvel_movie.reset_index()px.bar(x='title', y ="imdb_rating", data_frame=top_marvel_movie)
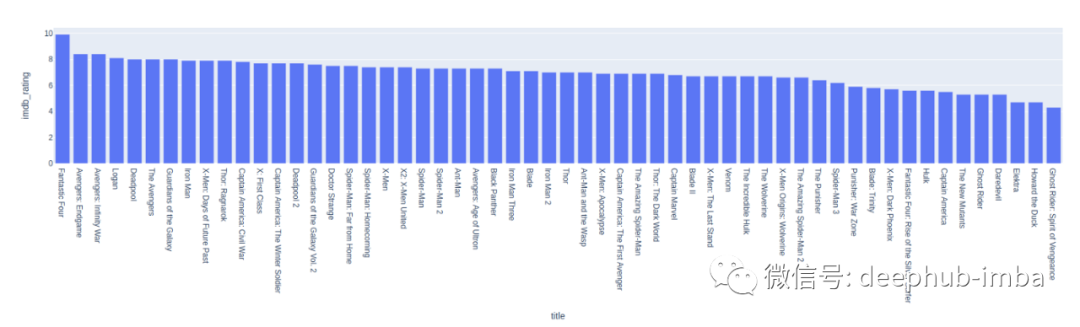
###Marvel###avrg_marvel_runtime = marvel_movies['runtime'].mean()highest_marvel_runtime = marvel_movies['runtime'].max()###DC###avrg_dc_runtime = dc_movies['runtime'].mean()highest_dc_runtime = dc_movies['runtime'].max()print("Marvel\nAverage: ",avrg_marvel_runtime, "\n Highest: ",highest_marvel_runtime)print("DC\nAverage: ",avrg_dc_runtime, "\n Highest: ",highest_dc_runtime)
输出如下:
MarvelAverage: 124.54385964912281Highest: 244DCAverage: 123.45454545454545Highest: 164
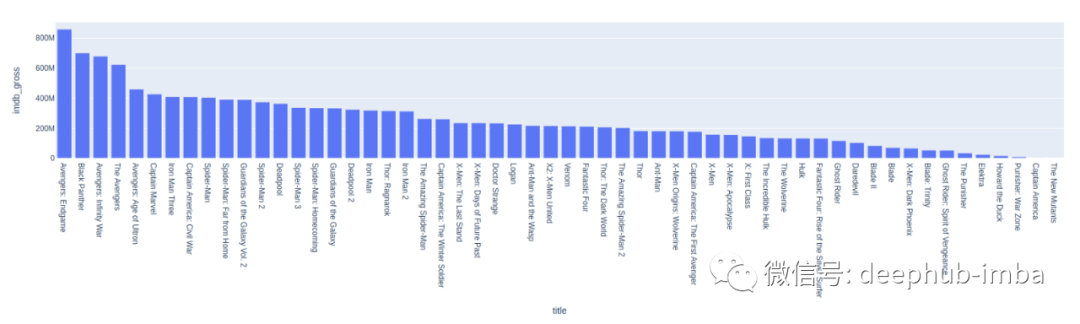
top_marvel_movie_gross = marvel_movies.groupby('title').sum().sort_values('imdb_gross', ascending=False)top_marvel_movie_gross = top_marvel_movie_gross.reset_index()px.bar(x='title', y ="imdb_gross", data_frame=top_marvel_movie_gross)
top_dc_movie_gross = dc_movies.groupby('title').sum().sort_values('imdb_gross', ascending=False)top_dc_movie_gross = top_dc_movie_gross.reset_index()px.bar(x='title', y ="imdb_gross", data_frame=top_dc_movie_gross)
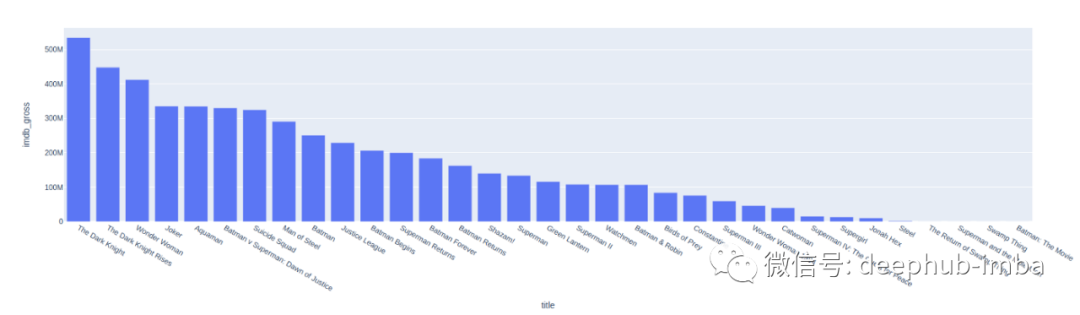
fig = px.line(df, x="year", y="imdb_gross", color='entity')fig.show()
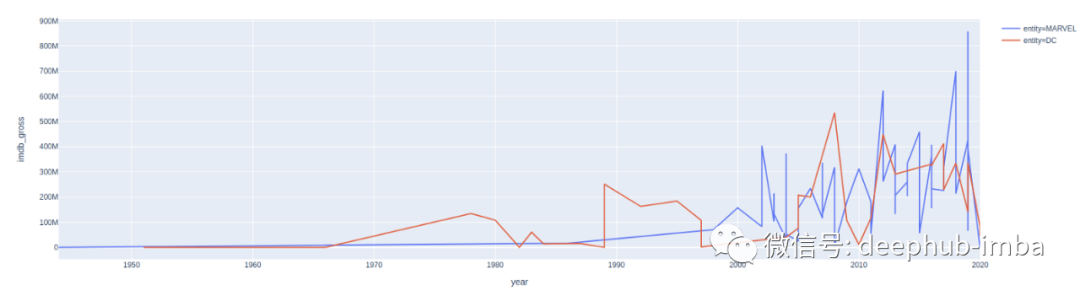
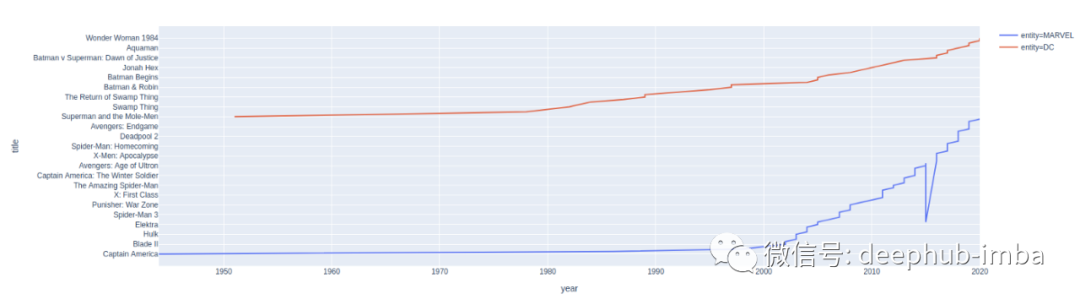
fig2 = px.line(df, x='year', y='title', color='entity')fig2.show()
总结
评论