
【Python】手把手教你用Python爬取某网小说数据,并进行可视化分析

网络文学是以互联网为展示平台和传播媒介,借助相关互联网手段来表现文学作品及含有一部分文字作品的网络技术产品,在当前成为一种新兴的文学现象,并快速兴起,各种网络小说也是层出不穷,今天我们使用selenium爬取红袖天香网站小说数据,并做简单数据可视化分析。
红袖添香建于1999年,是全球领先的女性文学数字版权运营商之一,日更新小说5000部,为超过240万注册用户提供涵盖小说、散文、杂文、诗歌、歌词、剧本、日记等体裁的高品质创作和阅读服务,在言情、职场小说等女性文学写作及出版领域独占高地。(百度百科)
网页初步分析
打开网页如图所示:
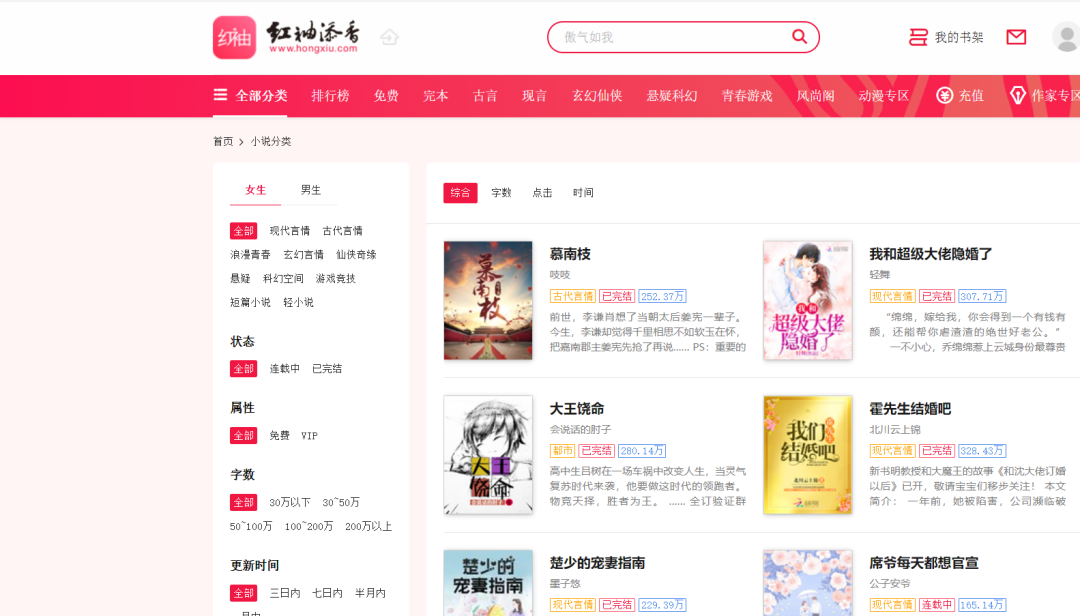
我们要把小说分类里面的所有小说数据全部抓取下来:总共有50个页面,每页20条数据,一共1000条数据。
首先使用requests第三方库请求数据,如下所示:
import requests
url = 'https://www.hongxiu.com/category/f1_f1_f1_f1_f1_f1_0_1' # 第一页url
headers = { 'xxx' : 'xxx'}
res = requests.get(url,headers=headers)
print(data.content.decode('utf-8'))
我们发现请求回来的数据并没有第一页的小说数据信息,很明显数据不在网页源码里面,然后通过查看network,发现了这样的请求字段:
_csrfToken: btXPBUerIB1DABWiVC7TspEYvekXtzMghhCMdN43
_: 1630664902028
这个是做了js加密,所以为了避免分析加密方式,使用selenium爬取数据可能更快一些。
selenium 爬取数据
01 初步测试
from selenium import webdriver
import time
url = 'https://y.qq.com/n/ryqq/songDetail/0006wgUu1hHP0N'
driver = webdriver.Chrome()
driver.get(url)
结果运行正常,没有问题。
02 小说数据
明确要爬取的小说数据信息
图片链接、名称、作者、类型、是否完结、人气、简介
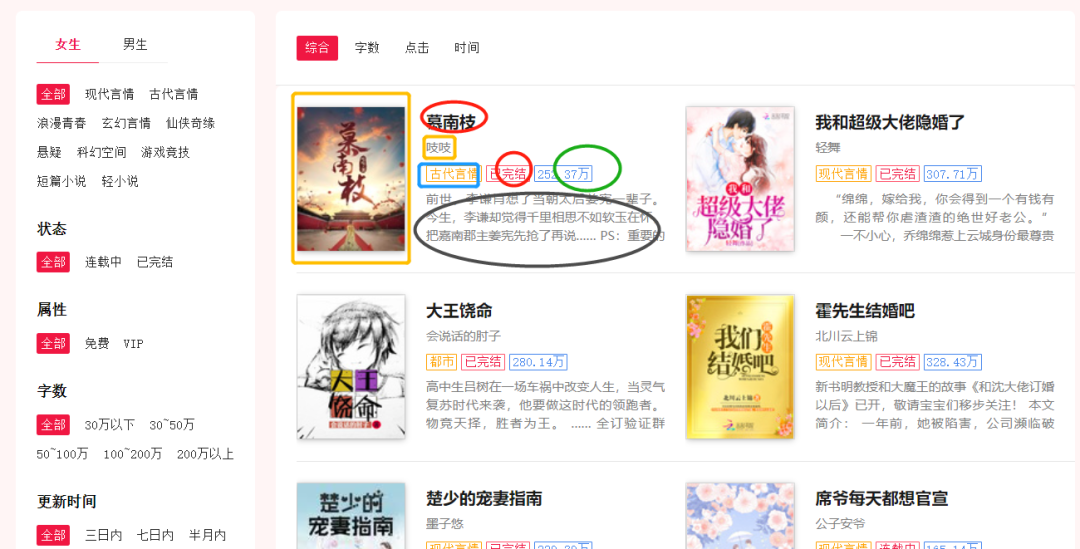
然后通过点击下一页的按钮观察是否是动态数据:发现不是;url规律如下所示:
'https://www.hongxiu.com/category/f1_f1_f1_f1_f1_f1_0_1' # 第一页的url
'https://www.hongxiu.com/category/f1_f1_f1_f1_f1_f1_0_2' # 第二页的url
03 解析数据
下面是解析页面数据的代码:
def get_data():
ficList = [] # 存储每一页的数据
items = driver.find_elements_by_xpath("//div[@class="right-book-list"]/ul/li")
for item in items:
dic = {}
imgLink = item.find_element_by_xpath("./div[1]/a/img").get_attribute('src')
# 1.图片链接 2.小说名称(name) 3.小说类型(types) ....
dic['img'] = imgLink
# ......
ficList.append(dic)
这里有几个需要注意的点:
注意xpath语句书写,注意细节,不要出错; 对于小说简介,有的简介比较长,有换行符,为了便于存储,需要使用字符串的replace方法把'\n'替换为空字符串
04 翻页爬取
下面是翻页爬取数据的代码:
try:
time.sleep(3)
js = "window.scrollTo(0,100000)"
driver.execute_script(js)
while driver.find_element_by_xpath( "//div[@class='lbf-pagination']/ul/li[last()]/a"):
driver.find_element_by_xpath("//div[@class='lbf-pagination']/ul/li[last()]/a").click()
time.sleep(3)
getFiction()
print(count, "*" * 20)
count += 1
if count >= 50:
return None
except Exception as e:
print(e)
代码说明:
使用
try语句,进行异常处理,防止有什么特殊页面的元素无法匹配或者其它问题。driver执行js代码,操作滚轮,滑动到页面底部。
js = "window.scrollTo(0,100000)"
driver.execute_script(js)time.sleep(n)因为循环里面添加了解析函数(driver定位)需要等待数据加载完全。while循环语句,while后面的是‘下一页’按钮定位,保证循环的爬取下一页的数据。使用
if语句作为判断条件,作为while循环推出的条件,然后要使用return退出函数,break不行。
05 数据保存
titles = ['imgLink', 'name', 'author', 'types', 'pink','popu','intro']
with open('hx.csv',mode='w',encoding='utf-8',newline='') as f:
writer = csv.DictWriter(f, titles)
writer.writeheader()
writer.writerows(data)
print('写入成功')
06 程序运行
结果如下,显示的1000条数据:

使用selenium爬取数据的一些注意点:
① 点击下一页之后,数据不可能瞬间加载完全,一旦数据没有加载完全,那么使用webdriver的find_Element_by_xpath语句就会定位不到dom文档上的元素,进而抛出一个错误:
selenium.StaleElementReferenceException:
stale element reference: element is not
attached to the page document
大概意思:所引用的元素已过时,不再依附于当前页面。产生原因:通常情况下,这是因为页面进行了刷新或跳转。
解决方法:
1.重新使用 findElement 或 findElements 方法进行元素定位即可。
2.或者只需要使用webdriver.Chrome().refresh刷新一下网页就可以,还要在前面等待几秒钟再刷新,time.sleep(5)。关于这个报错的解决方法,参考下面博客:
https://www.cnblogs.com/qiu-hua/p/12603675.html
② 在动态点击下一页按钮时,需要精准定位到下一页的按钮,其次很重要的一共问题,selenium打开浏览器页面时,需要窗口最大化。
由于窗口右侧有一个绝对定位的二维码小窗口,如果不窗口最大化,那个该窗口就会挡住下一页按钮导致无法点击,这个需要注意。
数据分析与可视化
打开文件
import pandas as pd
data = pd.read_csv('./hx.csv')
data.head()
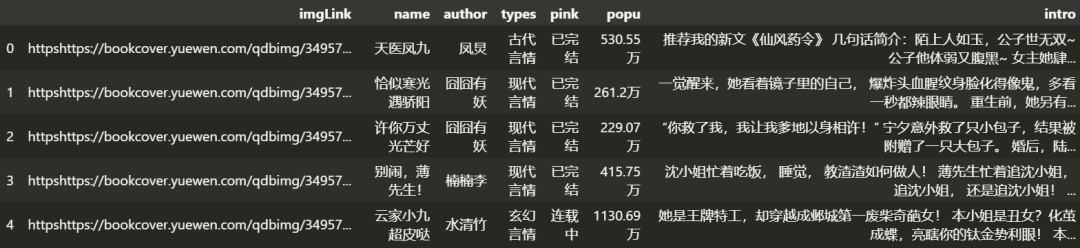
根据我们的数据信息可以做如下的可视化展示:
01 不同类型小说占比
types = ['现代言情', '古代言情', '玄幻', '玄幻言情', '科幻空间', '仙侠', '都市', '历史', '科幻', '仙侠奇缘', '浪漫青春', '其它']
number = [343, 285, 83, 56, 45, 41, 41, 25, 14, 14, 13,40]
pyecharts饼图
from pyecharts import options as opts
from pyecharts.charts import Page, Pie
pie=(
Pie()
.add(
"",
[list(z) for z in zip(types, number)],
radius=["40%", "75%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="不同类型小说占比"),
legend_opts=opts.LegendOpts(
orient="vertical", pos_top="15%", pos_left="2%"
),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
pie.render('pie.html')
结果如图
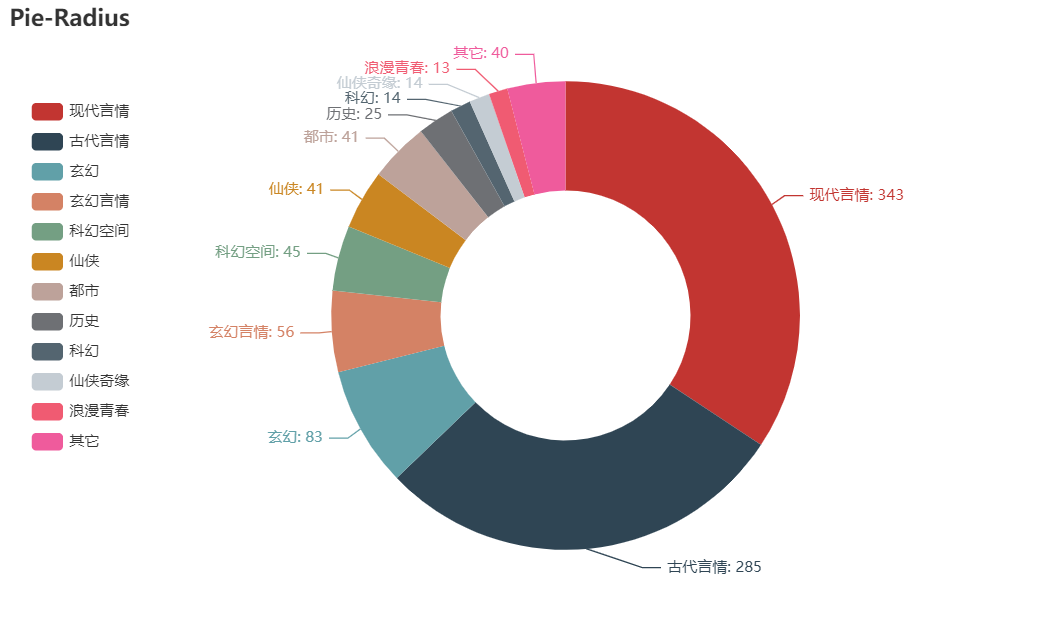
由图可知,言情小说占据所有小说半壁江山。
02 完结小说占比
from pyecharts import options as opts
from pyecharts.charts import Page, Pie
ty = ['已完结','连载中']
num = [723,269]
pie=(
Pie()
.add("", [list(z) for z in zip(ty,num)])
.set_global_opts(title_opts=opts.TitleOpts(title="完结小说占比"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
pie.render('pie1.html')
结果如图:
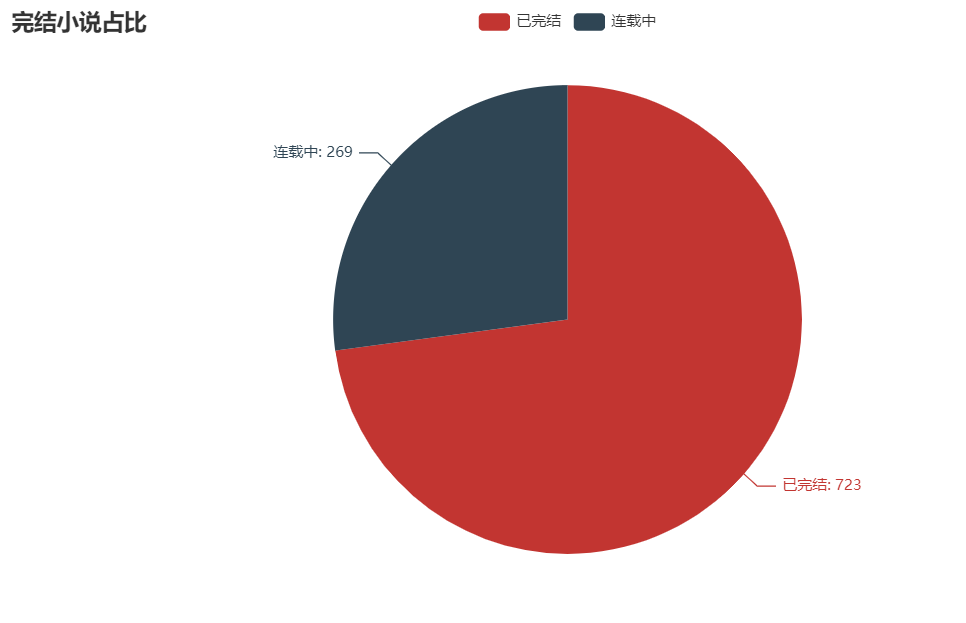
由图可知,仍有超1/4的小说正在连载中。
03 小说简介词云图展示
生成.txt文件
with open('hx.txt','a',encoding='utf-8') as f:
for s in data['intro']:
f.write(s + '\n')
初始化设置
# 导入相应的库
import jieba
from PIL import Image
import numpy as np
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 导入文本数据并进行简单的文本处理
# 去掉换行符和空格
text = open("./hx.txt",encoding='utf-8').read()
text = text.replace('\n',"").replace("\u3000","")
# 分词,返回结果为词的列表
text_cut = jieba.lcut(text)
# 将分好的词用某个符号分割开连成字符串
text_cut = ' '.join(text_cut)
词云展示
word_list = jieba.cut(text)
space_word_list = ' '.join(word_list)
# print(space_word_list) 打印文字 可以省略
# 调用包PIL中的open方法,读取图片文件,通过numpy中的array方法生成数组
mask_pic = np.array(Image.open("./xin.png"))
word = WordCloud(
font_path='C:/Windows/Fonts/simfang.ttf', # 设置字体,本机的字体
mask=mask_pic, # 设置背景图片
background_color='white', # 设置背景颜色
max_font_size=150, # 设置字体最大值
max_words=2000, # 设置最大显示字数
stopwords={'的'} # 设置停用词,停用词则不在词云途中表示
).generate(space_word_list)
image = word.to_image()
word.to_file('h.png') # 保存图片
image.show()
结果如图

这里不能从图中看出特别的内容,我们可以考虑其他的一些更加有效的自然语言分析与处理方法,此处留给读者朋友们一起思考。
04 根据类型分析小说热度排行
from pyecharts.charts import Bar
from pyecharts import options as opts
bar = Bar()
bar.add_xaxis(list(c['types'].values))
bar.add_yaxis('小说热度排行',numList)
bar.set_global_opts(xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45)))
bar.render()
结果如图
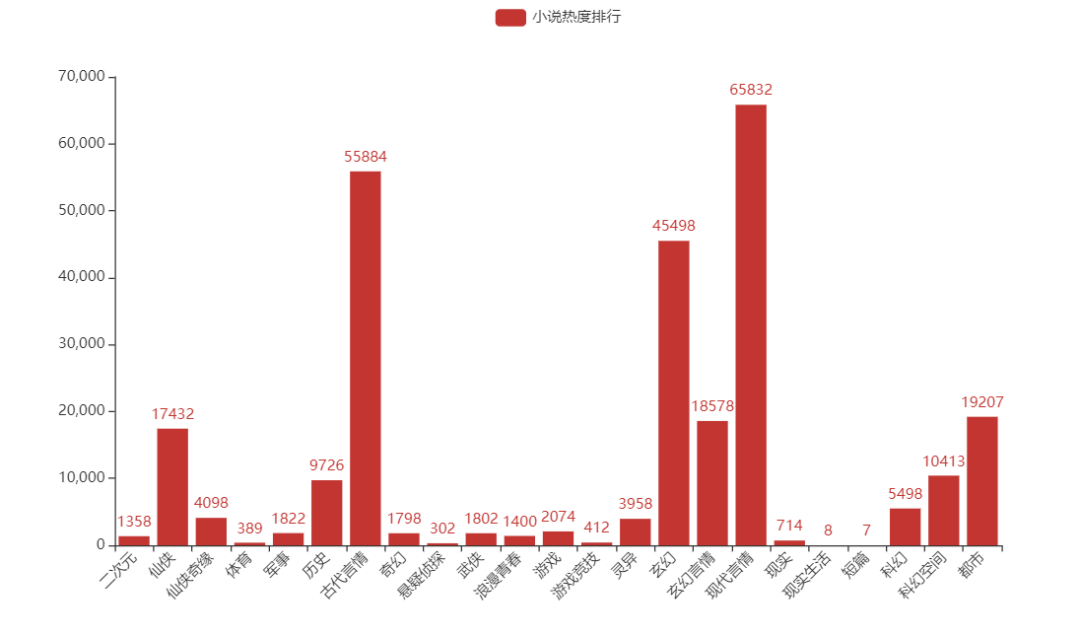
可以看出来,言情小说从古至今都是永恒的话题...
言情小说是中国旧体小说的一种,又称才子佳人小说。以讲述异性相爱为中心,通过完整的故事情节和具体的环境描写来反映爱情的心理、状态、事物等社会生活的一种文学体裁。
言情小说类型很多主要分为古代,现代等题材。其中又有重生文、穿越文、反穿越文、科幻文、宅斗文、宫斗文、玄幻文、公路文等不同题材。(百度百科)
05 不同作者热点小说占比
我们通过查看作家写的小说数量,得到以下结果:
data['author'].value_counts()
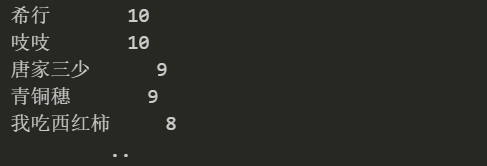
根据写作数量最多的前三位作家,他们只写了言情小说,后两位写了多种小说。接下来分别分析这些小说家中言情小说家及其他小说家的热度。
言情小说家热度
from pyecharts import options as opts
from pyecharts.charts import Page, Pie
attr = ["希行", "吱吱", "青铜穗"]
v1 = [1383,1315,1074]
pie=(
Pie()
.add("", [list(z) for z in zip(attr,v1)])
.set_global_opts(title_opts=opts.TitleOpts(title="言情小说作家热度"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
pie.render('pie.html')
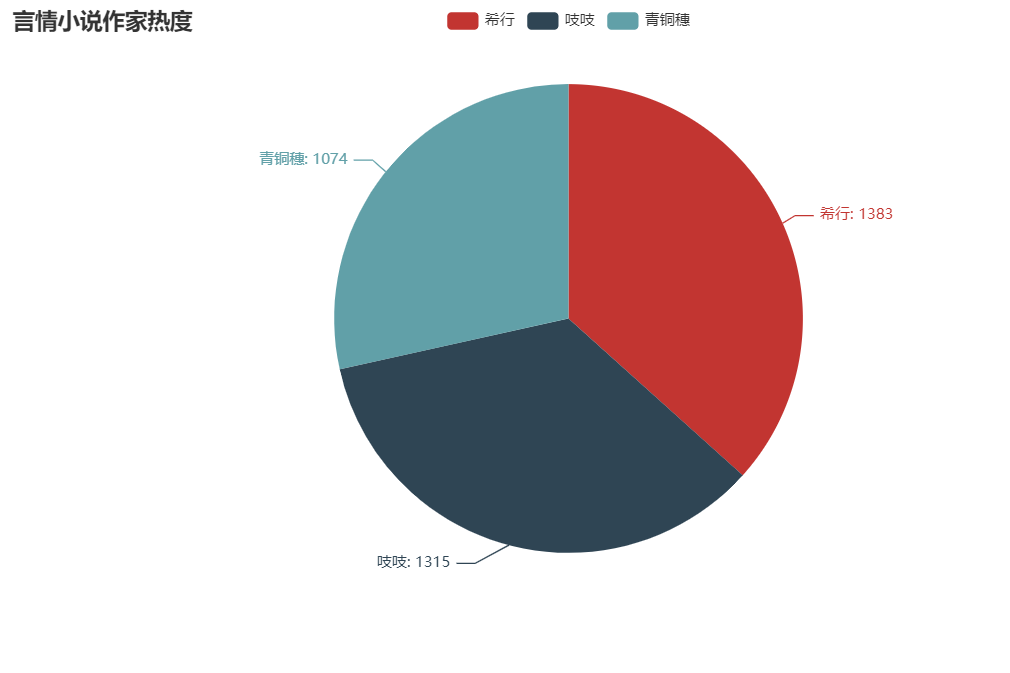
这三个小说家热度伯仲之间,当然,热度最高的当属希行。
希行,为笔名,原名裴云, 女, 起点中文网古言代表作家之一,女性网络文学超人气作者。中国作家协会会员。橙瓜见证·网络文学20年百强大神作家。2009年创作至今,希行已完结作品已有11部,创作1000多万字,作品大多简繁出版,其中《娇娘医经》、《君九龄》已出售影视权。(百度百科)
两大小说家热度排行
from pyecharts.charts import Bar
from pyecharts import options as opts
bar = Bar()
#指定柱状图的横坐标
bar.add_xaxis(['玄幻','奇幻','仙侠'])
#指定柱状图的纵坐标,而且可以指定多个纵坐标
bar.add_yaxis("唐家三少", [2315,279,192])
bar.add_yaxis("我吃西红柿", [552,814,900])
#指定柱状图的标题
bar.set_global_opts(title_opts=opts.TitleOpts(title="热度小说排行"))
#参数指定生成的html名称
bar.render('tw.html')
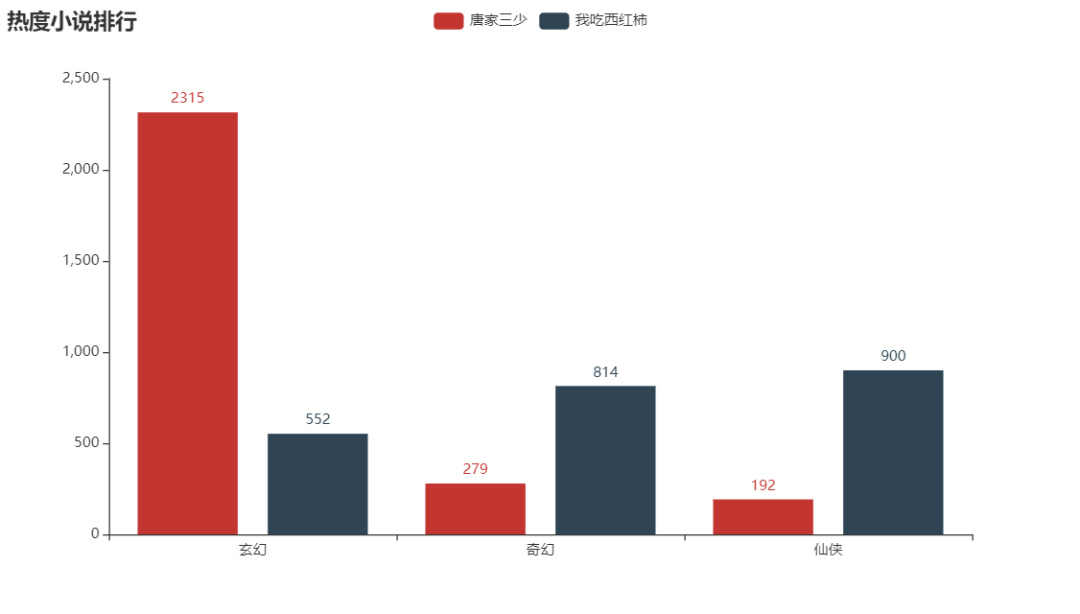
如图所示,唐家三少的玄幻小说更加突出,而 我吃西红柿 三种小说热度更加平均。
写在最后
这个爬取红袖添香网站小说页面数据,我们使用到selenium进行数据抓取,由于页面的js加密,所以使用到selenium,然后对于注意点进行总结:
① selenium爬取数据需要注意几点:
各种元素的定位需要精确; 由于使用selenium需要加载js代码,元素需要全部加载完全,才能进行定位,所以打开网页需要设置time.sleep(n); 然后对于很多网站都有个绝对定位的元素,可能是二维码...,固定在电脑屏幕的位置,不会随着页面滚轮的滚动而移动,所以需要页面最大化,防止该窗口挡住页面元素,导致无法点击或者其它操作。
② 在数据可视化展示的时候要进行数据清洗,因为有的数据是不规范的,比如会出现这样的错误:
'utf-8' codec can't decode byte 0xcb in
position 2: invalid continuation byte
这是由于编码方式的不同导致,一般通过查看页面meta标签的charset属性得到编码方式,设置pandas打开文件时的encoding的属性值;如果还是报错,可以把属性值修改成 'gb18030'
<meta charset="UTF-8">备注,本文仅以学习交流,对于爬虫浅尝辄止,以免对服务器增加负担。
往期精彩回顾 本站qq群851320808,加入微信群请扫码: