
集成电路行业观察(下)
集成电路行业观察(下)
01
关键设备层——光刻机
在上期集成电路行业观察(上)中说过了栅极长度被称为关键工艺节点,而光刻出的最细线条宽度决定了栅极的极限长度,因此,可以说光刻机是在半导体领域最重要的一台超精细设备了。关于光刻机的详细介绍参见卡住中国芯片发展脖子的设备——EUV;左图为光刻机的关键系统及组件。如此精细化的结构造成了极高的制成技术设备壁垒,国际上最先进的极紫外光刻机厂商是荷兰的阿斯麦。而目前我国在低端光刻机国产化进程上,虽然取得了一定的成果,但是在极紫外光刻机EUV方面还和荷兰存在极大差距。据悉,华为已参与到14nm光刻机的自研中,这样复杂的光学、材料学、模组学、机械制动学的机械我们拭目以待。

02
关键器件层——3D传感芯片
在 2015 年,一张“鸽子为什么这么大”的照片火遍全网,其本质原因就 是单图像传感器难以体现深度(物体远近)信息,显得图中的鸽子格外巨大。“近大远小”这个事实,在肉眼视角中不值一提,是一个常识;然而仅仅凭 借一张照片,在失去深度信息的前提下,“远”和“近”便难以分辨了,因此出现了这个笑话。在 AIoT 时代,机器学习、图像识别等技术开始广泛应用, 如果在输入端没有深度的信息,AI 对世界的认知就会失真,进而输出错误的 判断。在精细化遇到瓶颈的情况下,为了更好地还原、接近人眼感受到的世界,图像传感器的发展趋势是三维化。

那么3D传感有哪些应用场景呢?在消费电子中以手机为主,在医疗、工业、军事、智能家居领域也开始渗透。全球消费电子用 3D 传感市场空间已超过 50 亿元,预计 2025 年可达150 亿元。AR 生态是 3D 传感从可选走向必选、市场空间从百亿迈向千亿的关键。若 不搭载该技术,则 AR 无法体现近大远小特征,虚拟与现实的 3D 交互将失 真。目前各大终端厂商正积极探索 AR 生态,并应用 3D 传感技术于其中。这个技术也是元宇宙的一个底层基础性硬件。
双目视觉的深度信息识别原理是利用相差。如下图所示,一个物体在两 台相机中成像的位置是不一样的(此处使用小孔成像近似)。通过位置差信息、两台相机之间的距离(基线长度)即可计算出物体距离相机的距离。在 实际应用中,还有各种相差修正等参数;同时,比对两幅图像,并识别出“一 个物体”。是其中最难、算力消耗最大的一步。整体应用较少。
结构光是通过点阵投影器投射预先编码好的红外点阵,通过摄像头拍摄后与标定的参数进行比对,计算变形的比例后即可还原出物体深度。其本质 与双目视觉相似,也是通过投射光和接受光的光路视差,对基线长度也有要求。由于每个点阵投影器投出的点数是恒定的,因此距离越远单位面积的点 密度越低,算法的还原效果越差。因此结构光技术不适用于远距离场景。
I-ToF 传感器使用积分的方式将光信号转为电信号,通过编码脉冲并 对返回电荷积分的方式间接求得飞行的时间(如下图),其精度会受到脉冲 周期的限制;D-ToF 则可通过单光子雪崩二极管(SPAD)精确地记录光子发 射和返回的时刻,因此其精度不随距离增长而下降。而dToF方案相对iToF来说,标定相对简单,功耗低,理论精度更高且精度不随距离下降,成像质量更高,同时更适用于户外场景。但在具体实现上,dToF相较于iToF来说难度要大许多,其难点在于要检测的光信号是一个脉冲信号,在低功耗、高时间精准度要求下检测微弱光学回波信号,因此对探测器性能要求非常高。dToF常见检测器是单光子雪崩二极管SPAD,也就是说SPAD直接决定了dToF的性能。
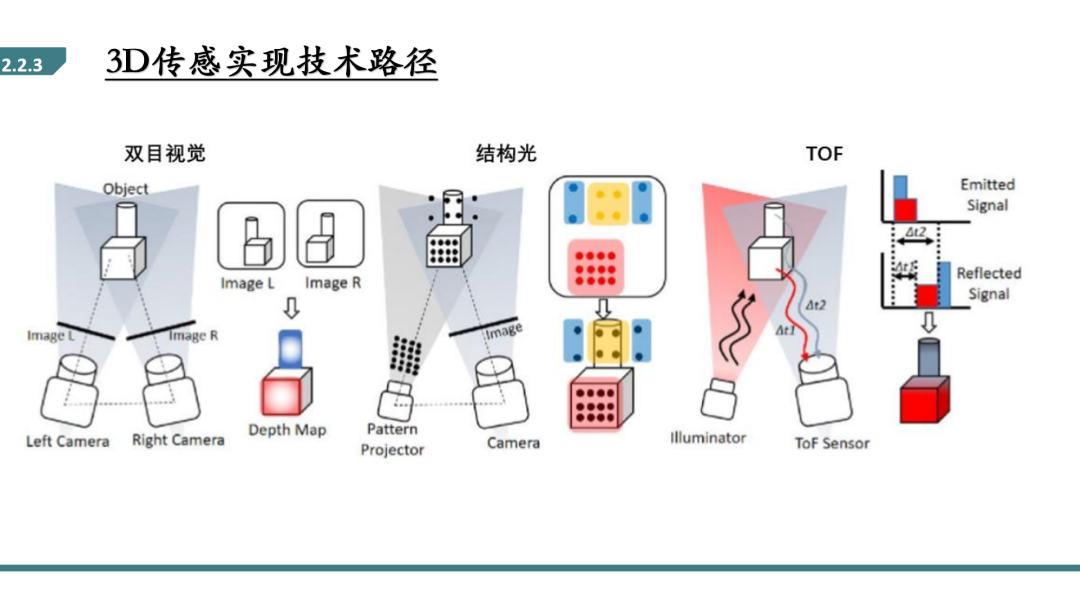
不同技术路线决定不同距离下的精度,进而决定应用场景。双目视觉精度取决于基线长度,消费电子要求小模组,其精度低、应用少;结构光的精度取决于点阵密度,适用于对安全性要求高而测量距离较低的场景,例如人脸识别、AOI 检测等;ToF 的精度取决于其单位测量时间,D-ToF 精度不随距离增长而降低,是远距离应用的关键技术,应用场景例如 3D 建模、游戏、导航、汽车避障、自动驾驶、手势捕捉、导航、AR 等各个方面。
单从技术方面看,dToF取代iToF存在很强的逻辑必然性。现在iToF实际应用中暴露出三个自身难以解决的问题:一是全系统能耗太大(因为采用连续波或宽脉冲激光),二是准度易受干扰(如透明物体干扰、多光路干扰、反射率对比度干扰),三是抗环境光能力差限制了户外应用。这三个问题显著限制了iToF的应用。而dToF则从根本上解决了以上三个问题,实际应用的性能天花板要远高于iToF。然而任何一项新技术的发展都不只取决于技术原理,产业链的成熟度、全产业链成本、可靠性等因素以及市场的宏观局势都会影响技术演进。当前的dToF产业链成熟度尚不如iToF,因此未来dToF是否取代iToF会取决于很多因素。3D ToF的应用场景非常多,对于某些特定应用场景,iToF跟dToF也会各自有一些优势。

2020年10月发布的新款iPhone机型中有两款(iPhone12 pro和iPhone 12 pro max)都搭载了激光雷达扫描仪,以拓展智能手机实现增强现实(AR)场景和自动对焦的能力。这对于智能手机未来作为视频内容创作平台和AR应用平台的大趋势来说有着关键性的推进作用。
据悉,安卓手机阵营正在积极跟进这一潮流,华米OV明确表示了自己在3D感知以及AR领域的布局。然而,当前安卓手机厂商能够获得的3D传感器仍仅限于iToF传感器或有限点距离传感器,均与iPhone搭载的基于单光子探测器(SPAD)阵列的dToF传感器存在代差。
据悉,苹果在该项技术上存在巨大技术优势,目前手机市场能提供关键芯片的供应商我了解到只有灵明光子和南京芯世界两家初创公司。但其余苹果的供应商在供应链能力方面还是小巫见大巫了。与此同时,苹果的dToF 3D传感技术也使服务型机器人、AR头显等其它需要3D传感方案的行业看到了一种更新、更先进的技术,全科技行业对于dToF 3D传感器的需求正在蓄势,极有可能在未来一两年内出现爆发性的需求增长。
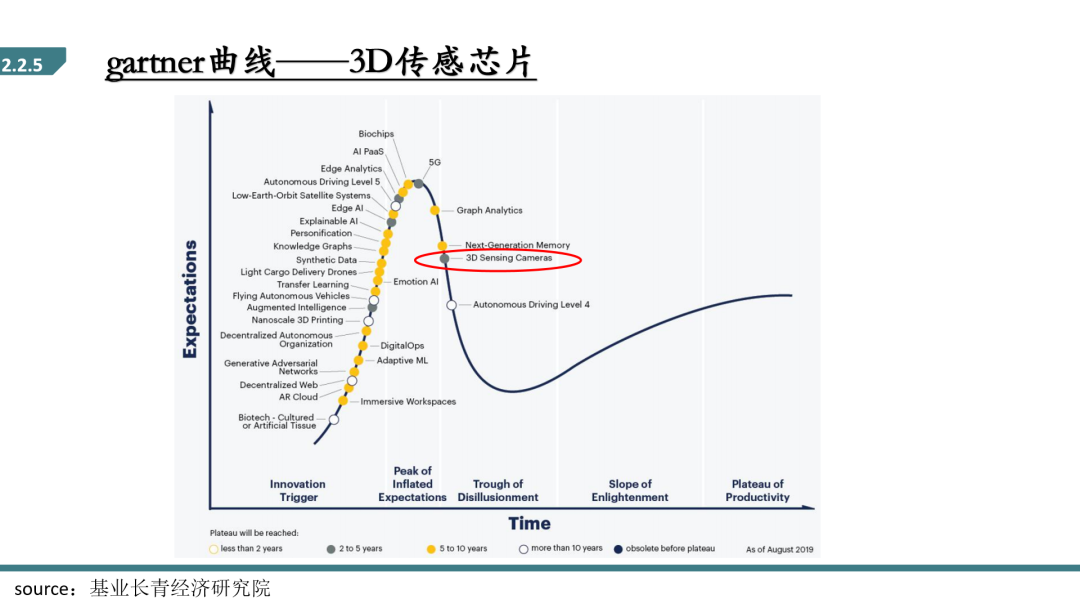
在Gartner曲线当中,3D传感这个技术已经越过了第一轮投资过热阶段,预计2~5年将会逐步进入成熟期走向市场,所以是一个非常适合创业或者是投资的一个关键领域。
03
关键器件+电路层——存算一体化
由于摩尔定律发展极度放缓甚至停止,传统通过做小来提高算力、降低成本的方式不再有效。另一方面,现有手机、个人电脑以及近年火热的云计算服务器,它们内部芯片都采用了1946年由冯诺伊曼提出的经典计算体系结构,其性能提升也达到了一个极限。但是在未来AIOT的世代,数据呈现爆发时增长,除了在软件侧通过量化、剪枝、稀疏化等方法提高运算速度外,如何从硬件及电路协同设计方面提出新的架构,来提高算力也是十分刚需的。
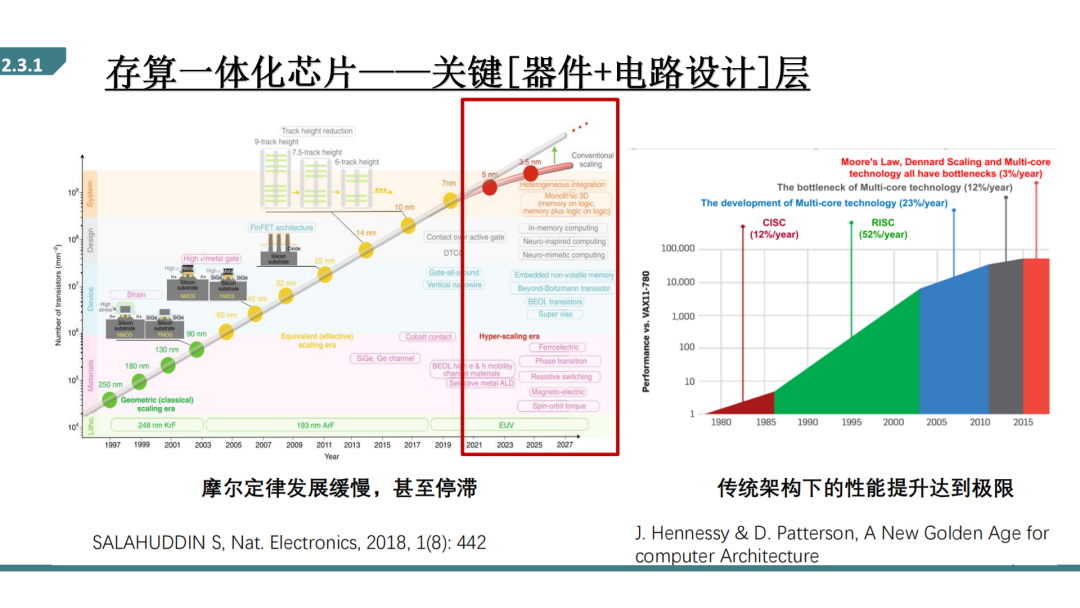
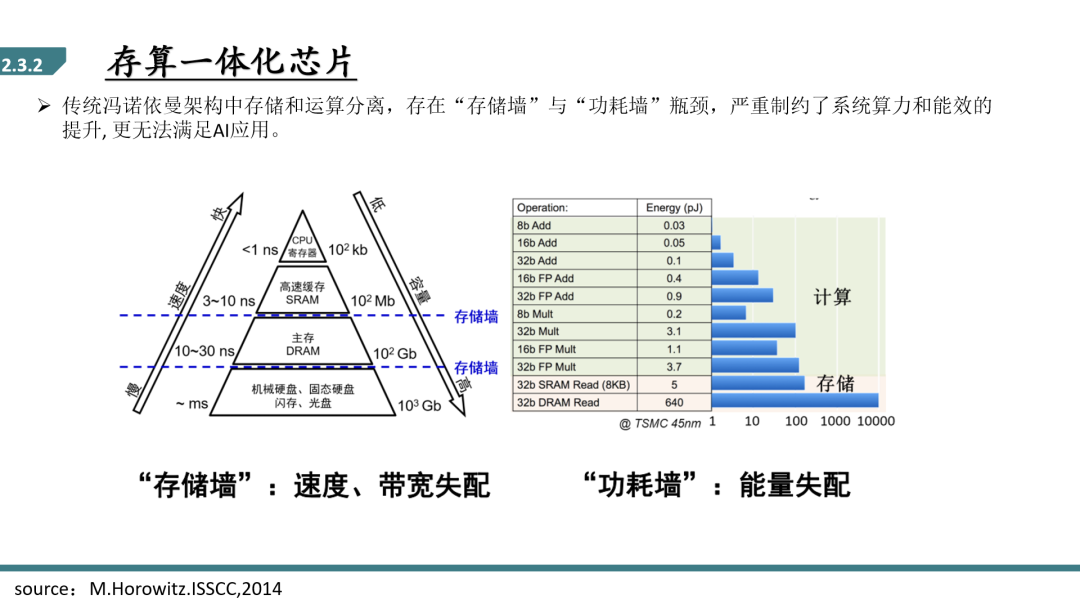
所谓冯诺依曼架构就是处理器和数据存储器是分开的,比如电脑中的CPU和内存硬盘,从硬盘中读取数据,运输到CPU中计算处理,把处理后的数据放回缓存区或硬盘中。这样运算速度受到存储器带宽的影响,没法再进一步提升,不管处理器多快,存储器的速度没法再进一步提升。这也就是经典的存储墙的问题。
另外一方面,数据搬运的功耗过大。存储器容量越来越大,从中间取出一个数的功耗也越来越大,基本是运算的百倍。这就是典型的“功耗墙”问题。
而所谓“存算一体”是直接把存储单元变成了运算单元,利用了存储器中的模拟计算。存算一体可以理解为一种计算器,一个类似于CPU的计算芯片,实际上是用存储器去完成计算。即将庞大的参数矩阵固定在存储器中,使乘加运算通过模拟或数字的方式发生在存储器中。有可能带来理论千倍的能效比。这对于时延要求较高、功耗(能效比)要求较高、短时间内需要有大量数据进行处理的端侧场景是天然适用的。
据统计,在全球训练芯片应用上,2017年99%为云端市场,边缘市场仅1%,而预计2023年边缘市场占比24%,云端市场占比76%;在推理芯片应用上,2017年云端市场占94%,边缘市场占6%,2022年75%的边缘设备将配有AI功能,边缘市场将增长至43%,预计2025年边缘侧芯片将超过云端芯片,份额达到200亿-300亿美元。是一个相对很大的市场了。
目前,存算一体芯片主要用来做基于人工智能的运算。人工智能的特点是向量和矩阵的计算量占比非常大,像可穿戴设备、手机、VR眼镜、智能驾驶以及数据中心,不同的场景需要算力不一样。
一般一个2M的存储就可以提供足够多的算法一定算力完成向量矩阵运算,比当前的芯片效率要高出50~100倍左右,用于可穿戴设备功耗可以很低,长待机。PC和移动终端需要大概32M、64M的存储空间存储算法,算力可以到16Tops~32Tops,实时性可以很高,另外在移动终端功耗限制下,可以很低功耗的去完成视觉信号处理这些AI算法。
智能眼镜对低功耗需求很强,它的电池很小散热很差,但又需要很多人工智能方法进行交互,包括手势识别、语音识别、肌肉肌电的识别、眼动识别等,对AI的算力需求很高,基本需要到100多兆存储空间,同时算力也很大。而自动驾驶对存算一体的要求是一个很高的场景,它除了算力要达标外,可靠性也要达标,稳定程度也是要达标,算力也很大,实时性对容错率也很低,我认为可能需要4~5年左右才能把存算一体芯片开发到可以满足智能驾驶的使用。而对于数据中心的成本,一个是在芯片采购方面,另一半儿的成本实际是在降温上,如果存算一体能够在提供同样大小算力情况下,把芯片的成本降低,功耗降低,实际上在数据中心有很大的优势。
另外,存算一体化减小了数据搬运的能耗,提升里运算效率。通过性能功耗的总结可以发现,斯坦福团队提出的基于开关电容的数模混合的存算一体架构能够实现86%的识别准确率和3.8微焦的单次识别能耗。

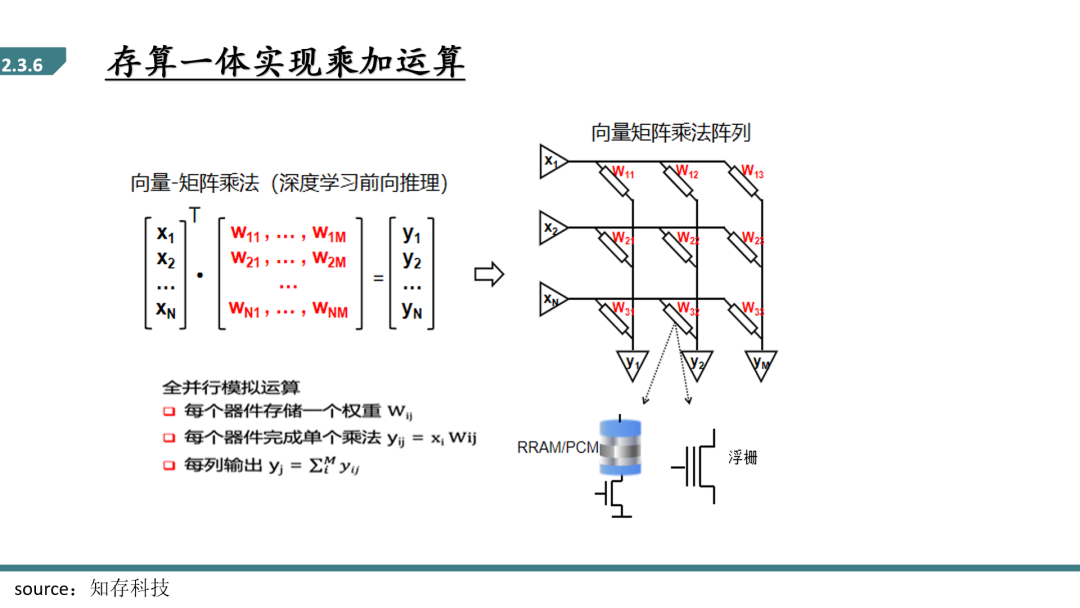
常见的实现存算一体化的硬件载体有浮栅晶体管和新型相变存储器RRAM。其中浮栅晶体管,优点是电流变化范围大(pA~uA),使存算空间大、密度高、电流小、功耗低,而且已有30年的发展历史,工艺成熟,可以与CMOS兼容。缺点是编程速度慢(微秒级), 可擦写次数少;忆阻器是一种有记忆功能的非线性电阻,电阻可变范围大,不需要反复移动数据,可以并行处理大量信号,编程时间为10-1000ns,可擦写次数达106-1012,适合机器学习系统,但工艺未成熟,目前未能量产。
目前产业界最多的存算一体发展方向是把存储单元变成一个做乘法加法运算的东西,相当于有多少个存储单元就可以做多少个乘法加法运算。如图所示,以典型的存算一体化架构为例,向量以电压形式驱动阵列字线(行),利用电压乘以电导等于电流,并且电流在位线(列)自然汇聚相加的电流定律,一次读操作即可完成向量与矩阵的乘加操作。这种方法不但提高了矩阵乘法的并行度,而且避免了反复读取权重,进一步提高了架构的能效比。
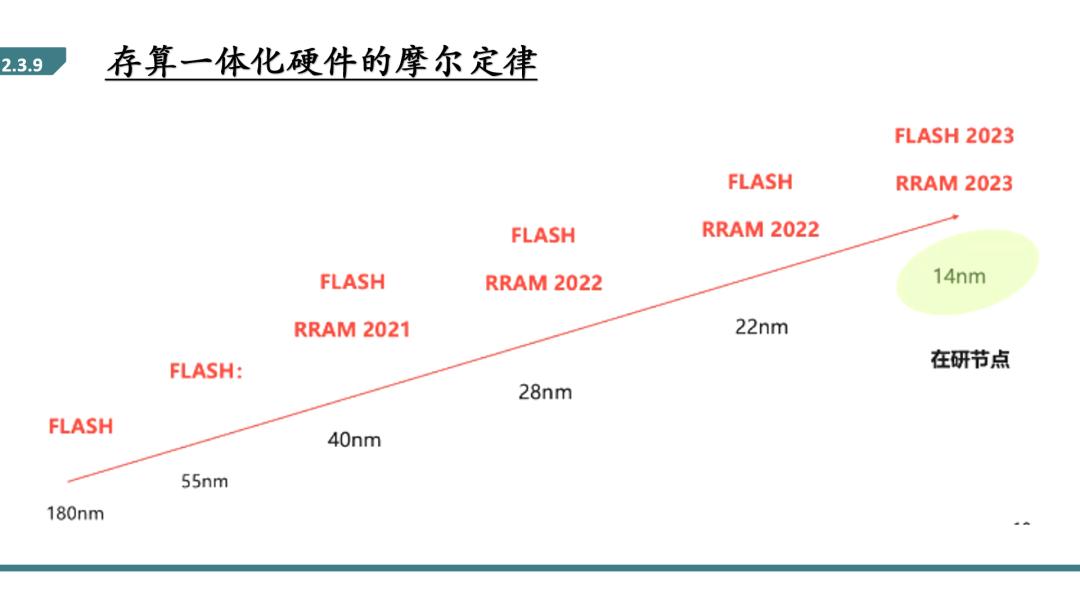
另一方面,存算一体硬件FLASH和RRAM的摩尔定律还没有像MOSFET那样卷,还有一定的节点缩减空间。这对于Fab厂是一个很好的价值空间点。
在更高精度方向有一个方向是做工艺优化,过去存算一体都是直接拿存储器的加工工艺实现,并没有针对存算一体去优化精度。近几年尤其近一年有非常多的存储公司成立,资本也投入了很大,我相信未来几年会有工艺上的优化,尤其在代工厂层面会针对存算一体做优化。另外一个是数模混合运算是一种提高计算精度的架构,它的问题是通用性。
在实现更高算力的方向先进封装是更好的一种方式,比如现在非常火的2.5D封装,可以把多个不同工艺的芯片放在一个大的硅基或者其他有机物基板上,可以理解成一个大芯片上承载了很多小芯片,并且这些不同的小芯片都采用不同的工艺。采用不同工艺的意义非常大,如果没有这种先进的2.5D封装,意味着做一个大芯片时,所有的东西都要采用同一个工艺,像逻辑工艺必须在10纳米以下才能跑的非常快,成本很高,良率相对降低,收益不是那么大。最新AMD的芯片也都大量采用2.5D封装,它的逻辑芯片以及缓存、其他模拟单元都采用不同的工艺,预计两年后在很多小公司或者消费电子产品上也可以采用这种技术。它的挑战是未来两三年内要解决怎么形成一个标准的测试方法,尤其形成测试工具,现在没有很好的一个产业链,没有封装、测试,也没有标准化接口。
3D堆叠也是过去十年主要发展的一种先进封装,可以提升多层的存储。目前3D堆叠在存储器上用的最多,比如显卡、固态硬盘,也有堆叠两三个不同存储器的。它的挑战是如果标准品像存储器用这种方案是一个比较标准的,成本不会增高,但像一些非标准的场景下,采用这种方式,有可能会增加很多研发成本及生产成本。
刚刚也说过了新型存储器在电阻可变范围、编程时间、可擦写次数等方面都比现在的SRAM、FLASH更有优势。因此加大对于RRAM的材料、工艺、器件研究也是硬件端的一个很好的方向。
小贝壳的浅安时光
科技前沿
求职就业
荐书荐影
旅行攻略