量子计算新里程碑登Nature封面!100+量子比特无需纠错,超越经典计算

新智元报道
新智元报道
【新智元导读】今天,IBM首次验证100+量子比特,无需纠错,依然可取得精确结果,甚至超越经典计算机。最新研究登上Nature封面。
今天的Nature封面,属于IBM。

IBM、加州大学伯克利分校最新研究展示了「一条通往有用量子计算的道路」。
首次证明,100+量子比特的量子处理器,可以取得精确结果,并超越领先的经典方法。
最重要的是,无需纠错就可超越经典计算机。

IBM的首席执行官表示,这是里程碑的证明,标志着量子计算可实际应用!
四年前,谷歌声称自家量子计算机已经实现了「量子霸权」,但只是在没有实际应用的小众计算方面取得突破。
最新Nature论文称,量子计算机很快将在有用任务上击败普通计算机。

论文地址:https://www.nature.com/articles/s41586-023-06096-3
论文中,研究人员在IBM 127量子比特鹰(Eagle)量子处理器上模拟了磁性材料的行为。
至关重要的是,他们设法绕过了「量子噪声」,取得了可靠结果。要知道,量子噪声会引入计算误差,是这项技术的主要障碍。
敲开「量子优势」大门
一直以来,量子优势是量子计算的一个关键里程碑。IBM将量子优势定义为,实际案例中量子算法运行时间显著改进。
到目前为止,还没有有用的应用证明量子优势,原因很简单:
量子计算机噪声大,容易出错,而且太小,无法解决现实世界的大问题。

然而,大多数关于量子优势的论文通常基于随机电路采样或高斯玻色子采样,这两种都不是有用应用的方法。
在IBM看来,量子计算机必须解决3个主要问题,才能执行有用任务:
- 需要一种处理量子噪声的方法。
- 量子比特必须可扩展到大量数字。
- 量子处理器必须具有足够的速度(以每秒电路层操作或CLOPS衡量)。
其中,量子计算噪声与可以解决的问题规模之间有直接关系。
噪声大了便会导致错误,而未纠正的错误就会限制电路中加入的量子比特数量,这反过来又限制了算法的复杂性。
显然,量子计算的「错误控制」很重要,即需要量子纠错(QEC)。

而IBM偏偏逆行其道,无需进行纠错,就超越了经典计算机,甚至还实现了100+量子比特有用性。
论文中,研究人员转而使用一种方法,有意放大噪声,然后测量不同级别的处理器噪声。
对此,物理学家对每个量子比特中的噪声进行了精确测量。
研究人员使用127个量子比特的Eagle R3处理器,模拟了127个相互作用的自旋状态。
在模拟中,每个量子比特都扮演了自旋的角色,使用深度为60的两个量子比特gates。
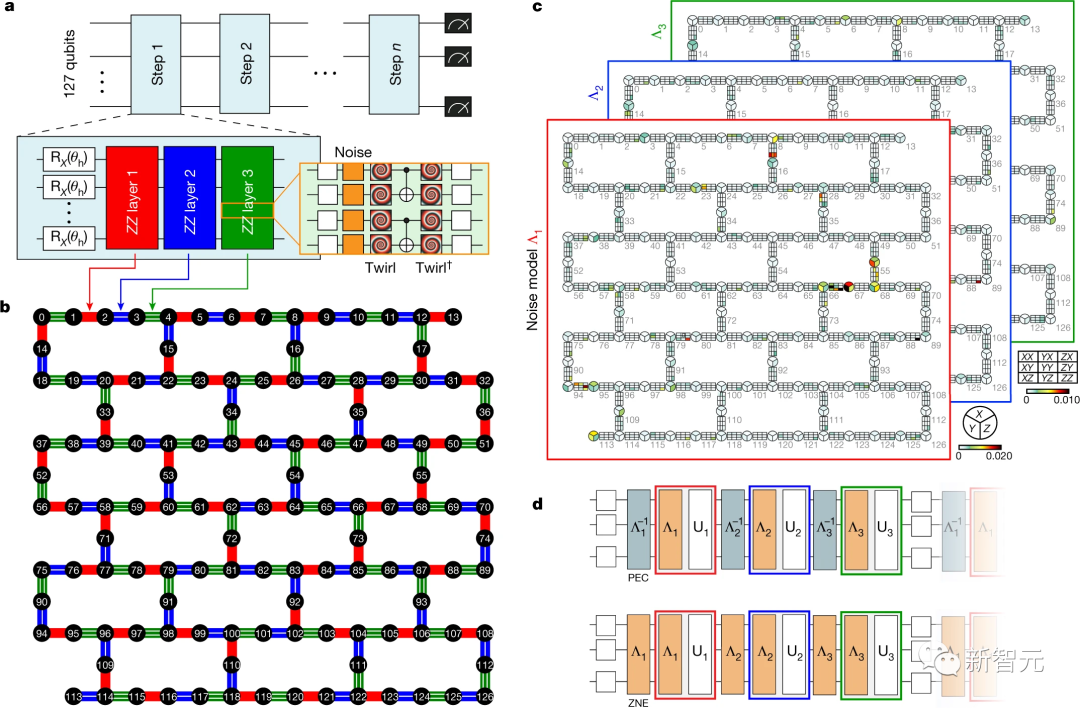
实验显示,他们能够运行涉及所有「鹰」的127个量子比特和多达60个处理步骤的计算,比任何其他报道的量子计算实验都要多。
这些结果验证了IBM的短期战略,该战略旨在通过缓解错误(而非纠正)来提供有用计算。
研究人员采用「错误缓解」技术使得团队能够进行「经典计算机难以达到的规模」的量子计算。
加州大学圣巴巴拉分校物理学家Santa Barbara(带领谷歌团队创下2019年里程碑)称,
尽管他们所攻克的问题使用的是一种简单化、不现实的材料模型,但让人们对它将适用于其他系统和更复杂的算法的未来更加乐观。
有噪声,不怕
IBM量子能力和演示部门的经理Abhinav Kandala表示,关键部分在于,能在脉冲展宽(pulse stretching)之外控制噪声。
「一旦开始工作,我们就可以进行更复杂的推断,从而抑制噪声产生的偏差。这在以前是实现不了的。」
这种噪声放大正是IBM所需的最后一块拼图。
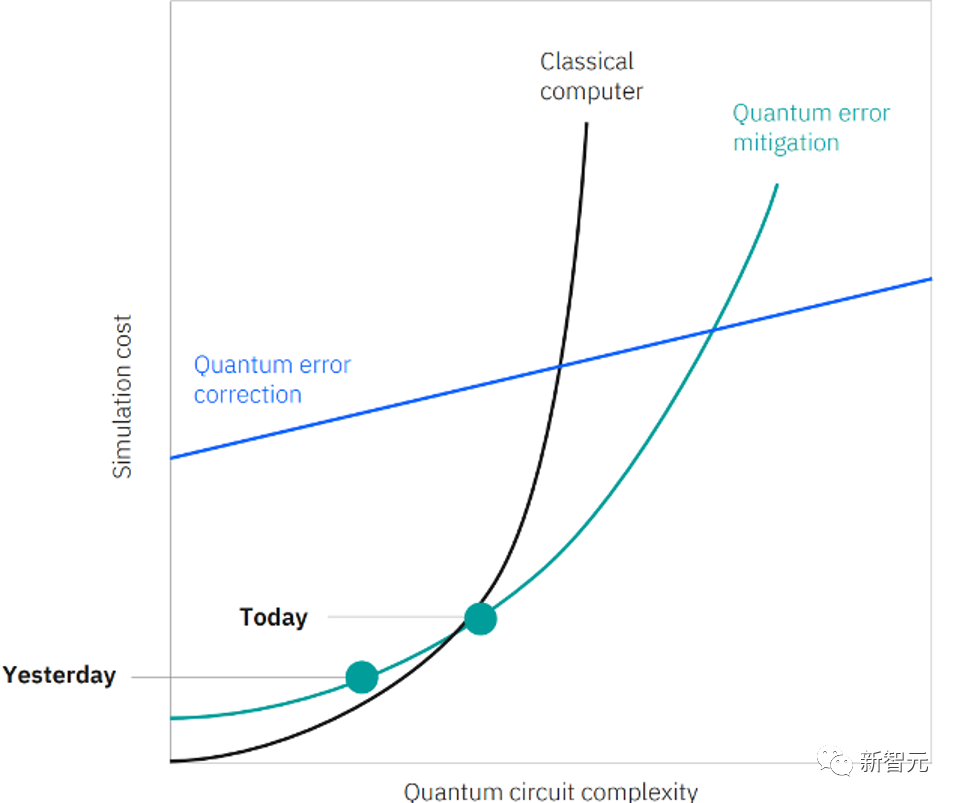
有了有代表性的噪声模型,人们就可以更准确地控制并放大噪声。然后,就可以应用经典的后处理方法来推断出没有噪声的计算结果,使用的方法叫做「零噪声推断」(Zero Noise Extrapolation,ZNE)。
同时,错误缓解(Error mitigation)需要高性能的硬件。IBM必须在规模、质量和速度上不断推进。
有了127比特的IBM量子鹰处理器,IBM终于有了能够运行足够大的电路的系统。
现在是时候来使用ZNE测试IBM SOTA级别的处理器了。
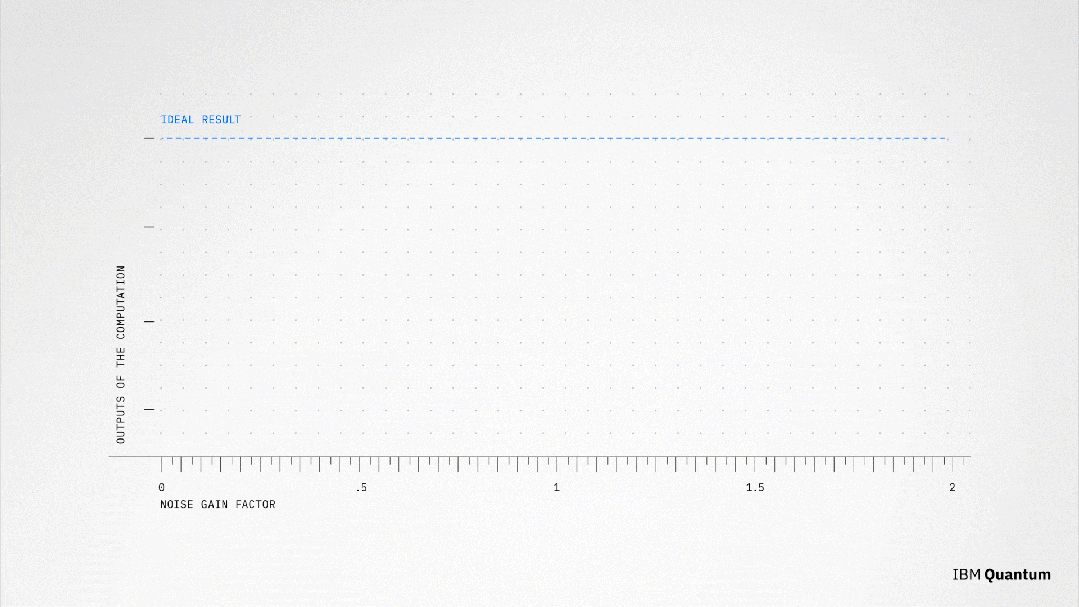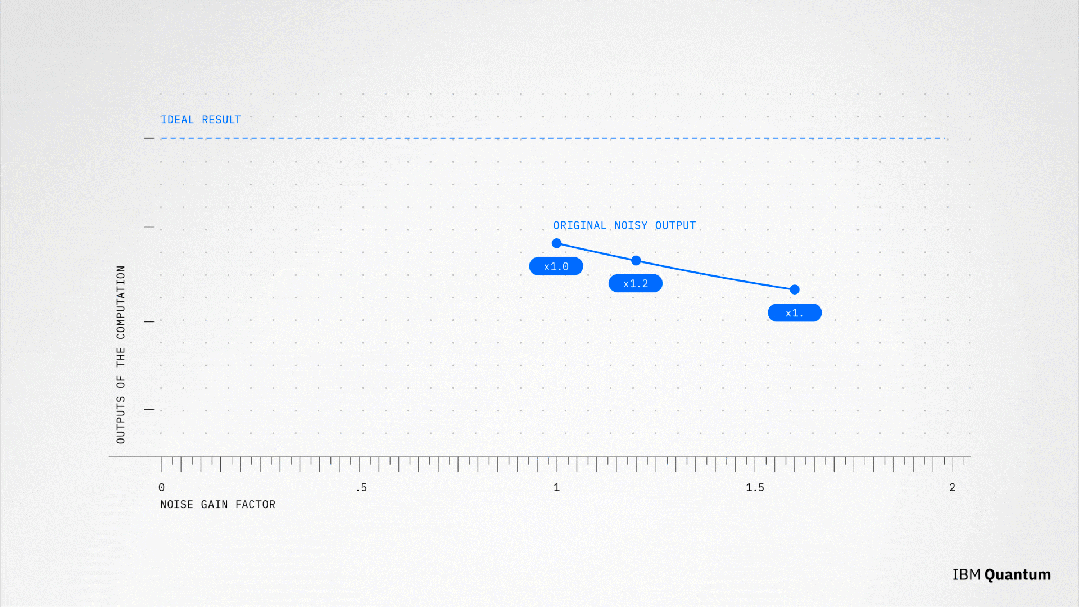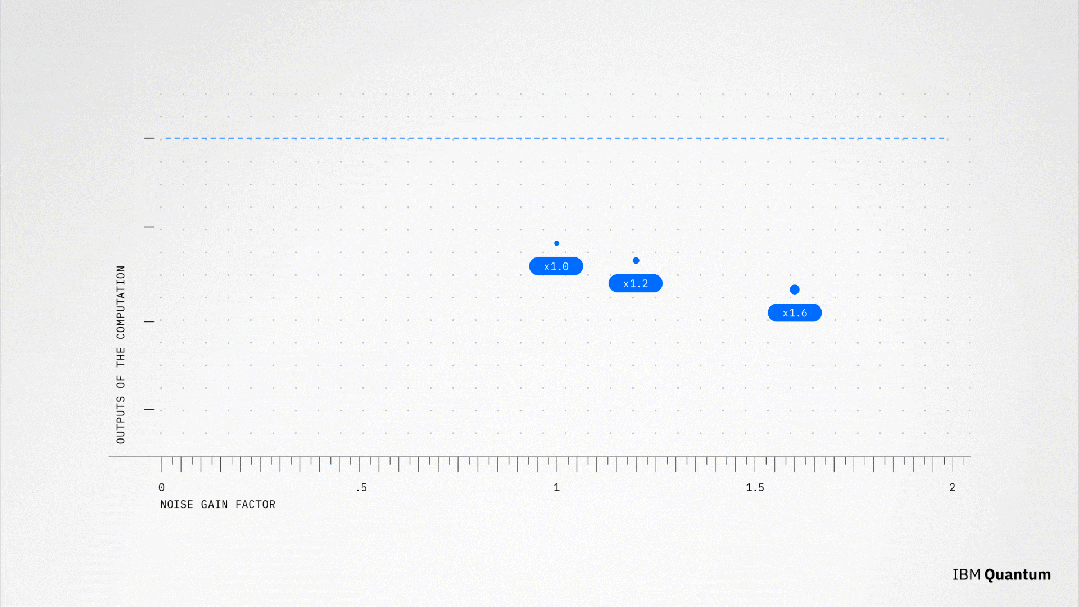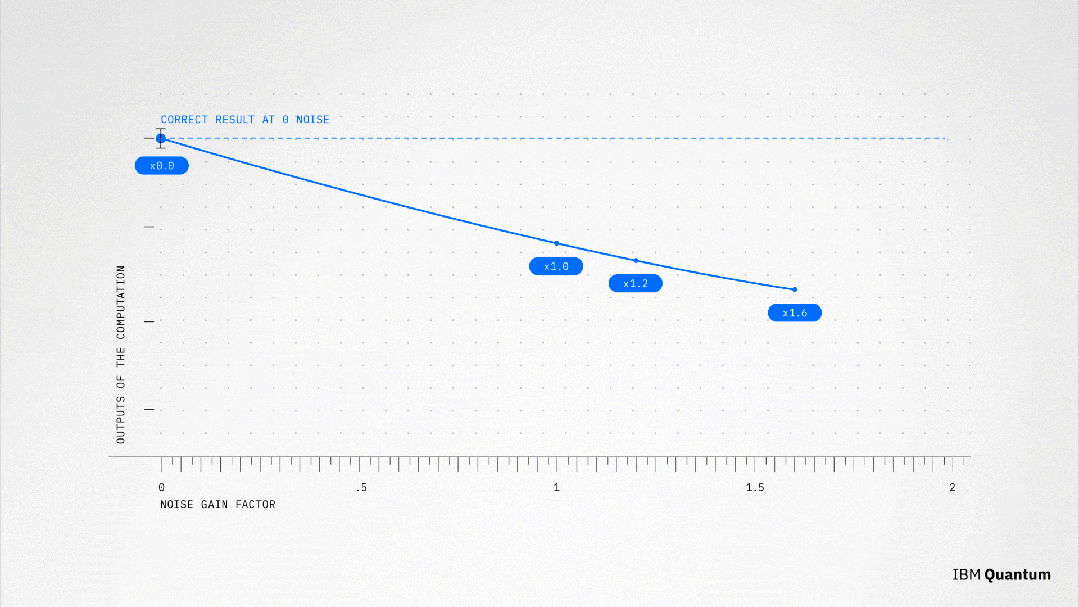
当然,像ZNE这样的「错误缓解」技术并不是万能的。
想要实现量子计算的全部潜力,IBM需要在系统中建立冗余,并允许多个量子比特一起工作,相互纠正,即:纠错。
然而,通过错误缓解,IBM意识到在全面纠错的时代到来之前,能够找到了一种方法来生成某些种类下的精确计算,即使是有噪声的量子计算机也能如此。
而这些计算可能会派上大用场。
IBM只是需要测试他们的错误缓解技术是否真的有效。
首先,研究人员尝试了在IMB的云服务上运行越来越复杂的量子计算,然后和传统计算机做对比。
同时,IBM也需要一些外部专家来验证这些计算的正确性。于是他们借助了研究员Sajant Anand、Yantao Wu和来自加州大学伯克利分校的副教授Michael Zaletel的帮助。
有几种方法可以用经典计算机运行量子电路。
第一种是靠蛮力——计算期望值,类似于物理学系的学生手算期望值的方法。这需要首先将关于波函数的所有信息写进一个列表,然后创建一个矩阵来进行计算。

每增加一个量子比特这些方法的难度也会随之增加一倍,因此,研究人员最终无法捕捉到足够大的电路的复杂性。
但是对于量子电路的一个小子集来说,有一些技巧可以让研究人员使用粗暴的计算方法来得出精确的答案,即使电路使用了IBM量子鹰的全部127个量子比特也能做到。
IBM从这些电路和方法开始,对经典和量子方法分别进行了相应的基准测试。
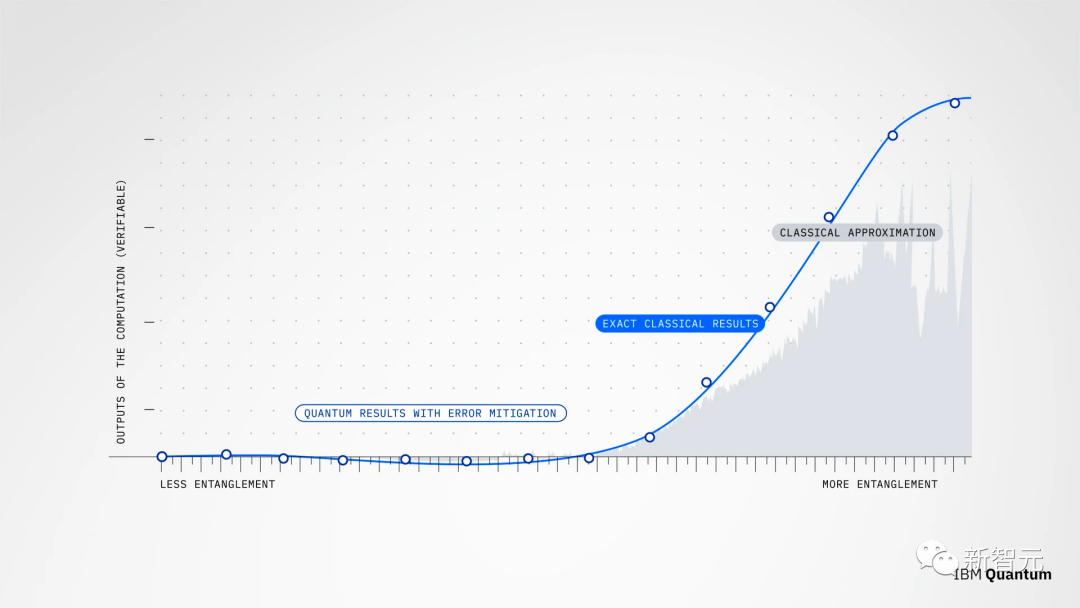
为了处理更复杂的电路,伯克利团队使用了使用两种不同的张量网络状态(TNS)方法,用更少的数字近似波函数。
这种经典的近似方法试图将许多量子比特的量子状态表示为张量的网络。TNS带有一套指令,说明如何用这些数据进行计算,以及如何用这些数据并恢复出有关量子状态的特定信息,如期望值等等。
这种方法有点像图像压缩,在计算能力和空间有限的情况下,为了只保留获得准确答案所需的信息,甩掉不太重要的信息。
实验将按如下方式进行:IBM将使用量子鹰处理器的所有127个量子比特来模拟一个系统的变化行为,该系统将自然映射到量子计算机中,称为量子伊辛模型(Ising model)。

伊辛模型是对自然界的简化,它将相互作用的原子表示为一个能量场中的量子系统的晶格。
IBM将使用ZNE来尝试并准确计算系统的一个属性,即平均磁化。该期望值基本上就是电路可能出现的结果的加权平均值。
同时,加州大学伯克利分校的团队将在劳伦斯伯克利国家实验室的国家能源研究科学计算中心(NERSC)和普渡大学的先进超级计算机的帮助下,尝试使用张量网络方法模拟同一系统。
具体来说,IBM的计算一部分将在NERSC的「Cori」超级计算机上运行,一部分在劳伦斯伯克利国家实验室的内部 「Lawrencium」集群上运行,一部分在普渡大学由国家科学基金会资助的「Anvil」超级计算机上运行。
然后,IBM将把这两者与精确的方法进行比较,看看两者的表现如何。

从结果来看,量子方法与精确方法保持一致。但是随着难度的增加,经典的近似方法开始出问题了。
最后,IBM要求这两台计算机运行超出可以精确计算的计算结果,他们对这个结果充满了信心。
为世界带来有用量子计算
近来,关于量子计算机是否能在完全实现纠错之前为有用任务提供计算优势存在争论。
容错是最终目标,「错误缓解」是让量子计算变得有用性的途径。
IBM最新论文让人们看到,有噪声的量子计算机,也能够提供价值。
这项工作的关键是,现在可以使用「鹰」全部127个量子比特来运行一个相当大的深度电路,并且数字是正确的。

这篇论文是一个节点,表明IBM正在进入量子优势时代。他们此前说过量子优势是一条持续的道路,需要做到两件事:
首先,我们必须证明量子计算机可以超越经典计算机。其次,我们必须找到加速有用问题,并弄清楚如何将它们映射到量子比特上。
最新论文已经实现了第一点。对量子领域来说,这是一个重要时刻。
而IBM这一步还只是起点,网友称他们会在今年年底实现在1000+量子比特取得精确结果。