
贝叶斯网络的因果关系检测(Python)
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
在机器学任务中,确定变量间的因果关系(causality)可能是一个具有挑战性的步骤,但它对于建模工作非常重要。本文将总结有关贝叶斯概率(Bayesian probabilistic)因果模型(causal models)的概念,然后提供一个Python实践教程,演示如何使用贝叶斯结构学习来检测因果关系。
1. 背景
在许多领域,如预测、推荐系统、自然语言处理等,使用机器学习技术已成为获取有用观察和进行预测的标准工具。

1.1. 相关性
-
正相关:两个变量之间存在一种关系,即两个变量同时朝同一方向移动。
-
负相关:两个变量之间存在一种关系,即一个变量增加与另一个变量减少相关联。
-
无相关性:当两个变量之间没有关系时。
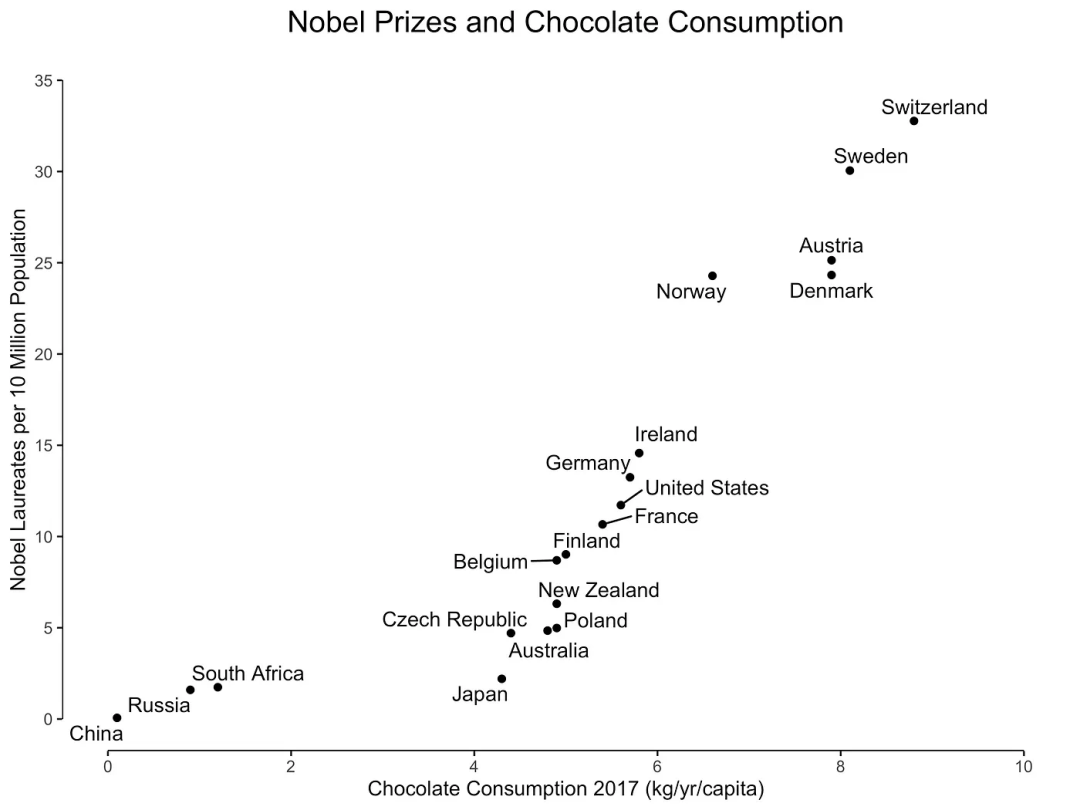
1.1.2. 关联性
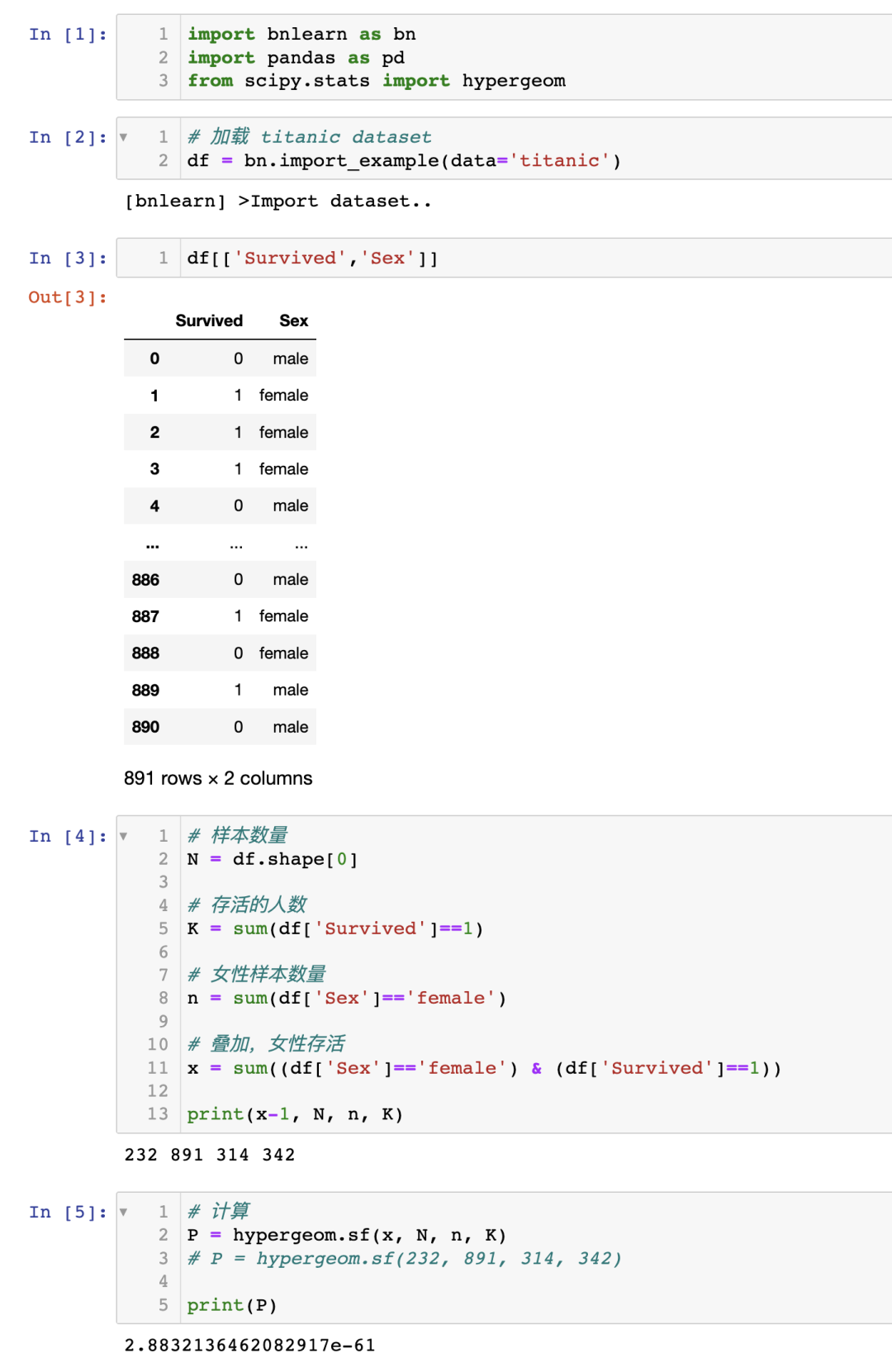

方程 1:使用超几何检验测试幸存与女性之间的关联性
2. 因果关系
如果两个随机变量 和
在统计上相关(
),那么要么(a)
导致
,(b)
导致
,或者(c)存在一个第三个变量
同时导致
和
。此外,给定
的条件下,
和
变得独立,即
。
贝叶斯图模型又称贝叶斯网络、贝叶斯信念网络、Bayes Net、因果概率网络和影响图。都是同一技术,不同的叫法。

可以创建四个图:(a、b)级联,(c)共同父节点和(d)V 结构,这些图构成了贝叶斯网络的基础。
需要注意的是,贝叶斯网络是有向无环图(Directed Acyclic Graph, DAG),而 DAG 是具有因果性的。这意味着图中的边是有向的,并且没有(反馈)循环(无环)。
2.1. 概率论
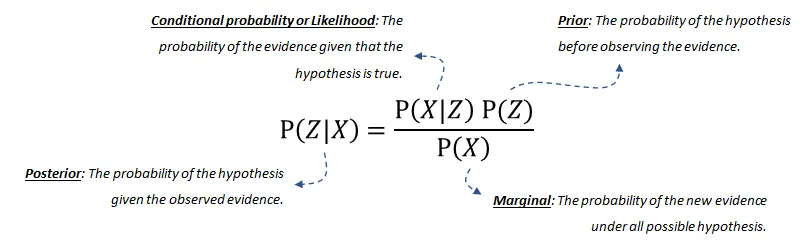
-
后验概率(posterior probability)是给定
-
条件概率(conditional probability)或似然是在假设成立的情况下,证据发生的概率。这可以从数据中推导出来。
-
我们的先验(prior)信念是在观察到证据之前,假设的概率。这也可以从数据或领域知识中推导出来。
-
最后,边际(marginal)概率描述了在所有可能的假设下新证据发生的概率,需要计算。如果您想了解更多关于(分解的)概率分布或贝叶斯网络的联合分布的详细信息,请阅读这篇博客[6]。
3. 贝叶斯结构学习用于估计 DAG
BIC是贝叶斯信息准则(Bayesian Information Criterion)的缩写。它是一种用于模型选择的统计量,可以用于比较不同模型的拟合能力。BIC值越小,表示模型越好。在贝叶斯网络中,BIC是一种常用的评分函数之一,用于评估贝叶斯网络与数据的拟合程度。
BDeu是贝叶斯-狄利克雷等价一致先验(Bayesian-Dirichlet equivalent uniform prior)的缩写。它是一种常用的评分函数之一,用于评估贝叶斯网络与数据的拟合程度。BDeu评分函数基于贝叶斯-狄利克雷等价一致先验,该先验假设每个变量的每个可能状态都是等可能的。
基于评分的结构学习
-
基于约束的结构学习
3.1. 基于评分的结构学习
-
搜索算法用于优化所有可能的 DAG 搜索空间;例如 ExhaustiveSearch、Hillclimbsearch、Chow-Liu 等。
-
评分函数指示贝叶斯网络与数据的匹配程度。常用的评分函数是贝叶斯狄利克雷分数,如 BDeu 或 K2,以及贝叶斯信息准则(BIC,也称为 MDL)。
-
ExhaustiveSearch,顾名思义,对每个可能的 DAG 进行评分并返回得分最高的 DAG。这种搜索方法仅适用于非常小的网络,并且阻止高效的局部优化算法始终找到最佳结构。因此,通常无法找到理想的结构。然而,如果只涉及少数节点(即少于 5 个左右),启发式搜索策略通常会产生良好的结果。
-
Hillclimbsearch 是一种启发式搜索方法,可用于使用更多节点的情况。HillClimbSearch 实施了一种贪婪的局部搜索,从 DAG“start”(默认为断开的 DAG)开始,通过迭代执行最大化增加评分的单边操作。搜索在找到局部最大值后终止。
-
Chow-Liu 算法是一种特定类型的基于树的方法。Chow-Liu 算法找到最大似然树结构,其中每个节点最多只有一个父节点。通过限制为树结构,可以限制复杂性。
-
Tree-augmented Naive Bayes(TAN)算法也是一种基于树的方法,可用于建模涉及许多不确定性的庞大数据集的各种相互依赖特征集。
3.2. 基于约束的结构学习
4. 实践:基于bnlearn 库
结构学习:给定数据:估计捕捉变量之间依赖关系的 DAG。
参数学习:给定数据和 DAG:估计各个变量的(条件)概率分布。
-
推断:给定学习的模型:确定查询的精确概率值。
基于 pgmpy 库构建
包含最常用的贝叶斯管道
简单直观
开源
详细文档
4.1. 在洒水器数据集中进行结构学习
使用 bnlearn 库,用几行代码就能确定因果关系。
请注意,洒水器数据集已经过处理,没有缺失值,所有值都处于 1 或 0 的状态。

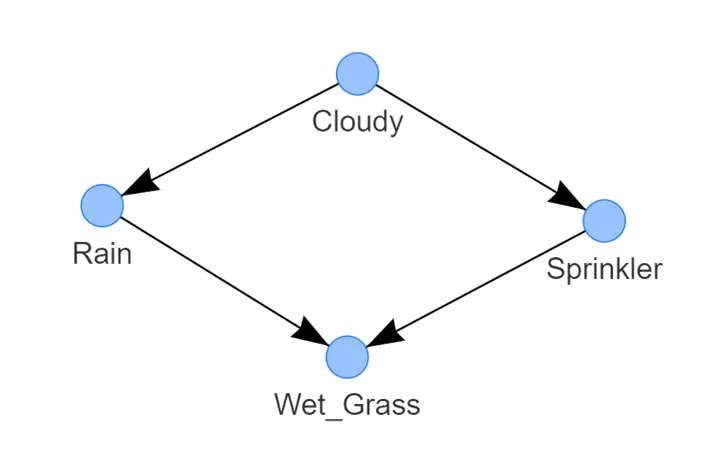
湿草的状态取决于两个节点,即雨水和洒水器;
雨水的状态由多云的状态决定;
-
而洒水器的状态也由多云的状态决定。
# 'hc' or 'hillclimbsearch'model_hc_bic = bn.structure_learning.fit(df, methodtype='hc', scoretype='bic')model_hc_k2 = bn.structure_learning.fit(df, methodtype='hc', scoretype='k2')model_hc_bdeu = bn.structure_learning.fit(df, methodtype='hc', scoretype='bdeu')# 'ex' or 'exhaustivesearch'model_ex_bic = bn.structure_learning.fit(df, methodtype='ex', scoretype='bic')model_ex_k2 = bn.structure_learning.fit(df, methodtype='ex', scoretype='k2')model_ex_bdeu = bn.structure_learning.fit(df, methodtype='ex', scoretype='bdeu')# 'cs' or 'constraintsearch'model_cs_k2 = bn.structure_learning.fit(df, methodtype='cs', scoretype='k2')model_cs_bdeu = bn.structure_learning.fit(df, methodtype='cs', scoretype='bdeu')model_cs_bic = bn.structure_learning.fit(df, methodtype='cs', scoretype='bic')# 'cl' or 'chow-liu' (requires setting root_node parameter)model_cl = bn.structure_learning.fit(df, methodtype='cl', root_node='Wet_Grass')
如果洒水器关闭,草地湿润的概率有多大?
如果洒水器关闭且多云,下雨的概率有多大?
4.2. 如何进行推断?
4.2.1. 参数学习
-
最大似然估计是使用变量状态出现的相对频率进行的自然估计。在对贝叶斯网络进行参数估计时,数据不足是一个常见问题,最大似然估计器存在对数据过拟合的问题。换句话说,如果观察到的数据对于基础分布来说不具有代表性(或者太少),最大似然估计可能会相差甚远。例如,如果一个变量有 3 个可以取 10 个状态的父节点,那么状态计数将分别针对
-
贝叶斯估计从已存在的先验 CPTs 开始,这些 CPTs 表示在观察到数据之前我们对变量的信念。然后,使用观察数据的状态计数来更新这些“先验”。可以将先验视为伪状态计数,在归一化之前将其添加到实际计数中。一个非常简单的先验是所谓的 K2 先验,它只是将“1”添加到每个单独状态的计数中。一个更明智的先验选择是 BDeu(贝叶斯狄利克雷等效均匀先验)。


# Examples to illustrate how to manually compute MLE for the node Cloudy and Rain:# Compute CPT for the Cloudy Node:# This node has no conditional dependencies and can easily be computed as following:# P(Cloudy=0)sum(df['Cloudy']==0) / df.shape[0] # 0.488# P(Cloudy=1)sum(df['Cloudy']==1) / df.shape[0] # 0.512# Compute CPT for the Rain Node:# This node has a conditional dependency from Cloudy and can be computed as following:# P(Rain=0 | Cloudy=0)sum( (df['Cloudy']==0) & (df['Rain']==0) ) / sum(df['Cloudy']==0) # 394/488 = 0.807377049# P(Rain=1 | Cloudy=0)sum( (df['Cloudy']==0) & (df['Rain']==1) ) / sum(df['Cloudy']==0) # 94/488 = 0.192622950# P(Rain=0 | Cloudy=1)sum( (df['Cloudy']==1) & (df['Rain']==0) ) / sum(df['Cloudy']==1) # 91/512 = 0.177734375# P(Rain=1 | Cloudy=1)sum( (df['Cloudy']==1) & (df['Rain']==1) ) / sum(df['Cloudy']==1) # 421/512 = 0.822265625
4.2.2. 在 Sprinkler 数据集上进行推理


如果喷灌系统关闭,草坪潮湿的可能性有多大?P(Wet_grass=1 | Sprinkler=0) = 0.51
如果喷灌系统关闭并且天阴,有下雨的可能性有多大?P(Rain=1 | Sprinkler=0, Cloudy=1) = 0.663
4.3. 我如何知道我的因果模型是正确的?
5. 讨论
后验概率分布的结果或图形使用户能够对模型预测做出判断,而不仅仅是获得单个值作为结果。
可以将领域/专家知识纳入到 DAG 中,并在不完整信息和缺失数据的情况下进行推理。这是可能的,因为贝叶斯定理基于用证据更新先验项。
具有模块化的概念。
通过组合较简单的部分来构建复杂系统。
图论提供了直观的高度交互的变量集。
-
概率论提供了将这些部分组合在一起的方法。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论