
一文搞懂Python库中的5种贝叶斯算法
在scikit-learn库,根据特征数据的先验分布不同,给我们提供了5种不同的朴素贝叶斯分类算法(sklearn.naive_bayes: Naive Bayes模块),分别是伯努利朴素贝叶斯(BernoulliNB),类朴素贝叶斯(CategoricalNB),高斯朴素贝叶斯(GaussianNB)、多项式朴素贝叶斯(MultinomialNB)、补充朴素贝叶斯(ComplementNB) 。
naive_bayes.BernoulliNB | Naive Bayes classifier for multivariate Bernoulli models. |
naive_bayes.CategoricalNB | Naive Bayes classifier for categorical features |
naive_bayes.ComplementNB | The Complement Naive Bayes classifier described in Rennie et al. |
naive_bayes.GaussianNB | Gaussian Naive Bayes (GaussianNB) |
naive_bayes.MultinomialNB | Naive Bayes classifier for multinomial models |
这5种算法适合应用在不同的数据场景下,我们应该根据特征变量的不同选择不同的算法,下面是一些常规的区别和介绍。
GaussianNB
高斯朴素贝叶斯,特征变量是连续变量,符合高斯分布,比如说人的身高,物体的长度。
这种模型假设特征符合高斯分布。
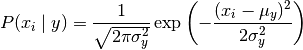
MultinomialNB
特征变量是离散变量,符合多项分布,在文档分类中特征变量体现在一个单词出现的次数,或者是单词的 TF-IDF 值等。不支持负数,所以输入变量特征的时候,别用StandardScaler进行标准化数据,可以使用MinMaxScaler进行归一化。
这个模型假设特征复合多项式分布,是一种非常典型的文本分类模型,模型内部带有平滑参数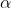 。
。
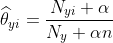
ComplementNB
是MultinomialNB模型的一个变种,实现了补码朴素贝叶斯(CNB)算法。CNB是标准多项式朴素贝叶斯(MNB)算法的一种改进,比较适用于不平衡的数据集,在文本分类上的结果通常比MultinomialNB模型好,具体来说,CNB使用来自每个类的补数的统计数据来计算模型的权重。CNB的发明者的研究表明,CNB的参数估计比MNB的参数估计更稳定。
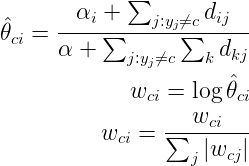
BernoulliNB
模型适用于多元伯努利分布,即每个特征都是二值变量,如果不是二值变量,该模型可以先对变量进行二值化,在文档分类中特征是单词是否出现,如果该单词在某文件中出现了即为1,否则为0。在文本分类的示例中,统计词语是否出现的向量(word occurrence vectors)(而非统计词语出现次数的向量(word count vectors))可以用于训练和使用这个分类器。BernoulliNB 可能在一些数据集上表现得更好,特别是那些更短的文档。如果时间允许,建议对两个模型都进行评估。
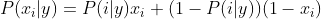
CategoricalNB
对分类分布的数据实施分类朴素贝叶斯算法,专用于离散数据集, 它假定由索引描述的每个特征都有其自己的分类分布。对于训练集中的每个特征 X,CategoricalNB估计以类y为条件的X的每个特征i的分类分布。样本的索引集定义为J=1,…,m,m作为样本数。
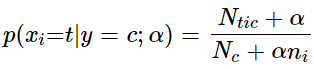

案例测试
from sklearn.naive_bayes import MultinomialNB,GaussianNB,BernoulliNB,ComplementNBfrom sklearn.datasets import load_breast_cancerfrom sklearn.model_selection import cross_val_scoreX,y = load_breast_cancer().data,load_breast_cancer().targetnb1= GaussianNB()nb2= MultinomialNB()nb3= BernoulliNB()nb4= ComplementNB()for model in [nb1,nb2,nb3,nb4]:scores=cross_val_score(model,X,y,cv=10,scoring='accuracy')print("Accuracy:{:.4f}".format(scores.mean()))Accuracy:0.9368Accuracy:0.8928Accuracy:0.6274Accuracy:0.8928
from sklearn.naive_bayes import MultinomialNB,GaussianNB,BernoulliNB,ComplementNB ,CategoricalNBfrom sklearn.datasets import load_irisfrom sklearn.model_selection import cross_val_scoreX,y = load_iris().data,load_iris().targetgn1 = GaussianNB()gn2 = MultinomialNB()gn3 = BernoulliNB()gn4 = ComplementNB()gn5 = CategoricalNB(alpha=1)for model in [gn1,gn2,gn3,gn4,gn5]:scores = cross_val_score(model,X,y,cv=10,scoring='accuracy')print("Accuracy:{:.4f}".format(scores.mean()))Accuracy:0.9533Accuracy:0.9533Accuracy:0.3333Accuracy:0.6667Accuracy:0.9267
进行one-hot变化,可以发现BernoulliNB分类准确率还是很高的
from sklearn import preprocessingenc = preprocessing.OneHotEncoder() # 创建对象from sklearn.datasets import load_irisX,y = load_iris().data,load_iris().targetenc.fit(X)array = enc.transform(X).toarray()from sklearn.naive_bayes import MultinomialNB,GaussianNB,BernoulliNB,ComplementNB ,CategoricalNBfrom sklearn.datasets import load_irisfrom sklearn.model_selection import cross_val_scoreX,y = load_iris().data,load_iris().targetgn1 = GaussianNB()gn2 = MultinomialNB()gn3 = BernoulliNB()gn4 = ComplementNB()for model in [gn1,gn2,gn3,gn4]:scores=cross_val_score(model,array,y,cv=10,scoring='accuracy')print("Accuracy:{:.4f}".format(scores.mean()))Accuracy:0.8933Accuracy:0.9333Accuracy:0.9333Accuracy:0.9400