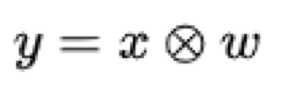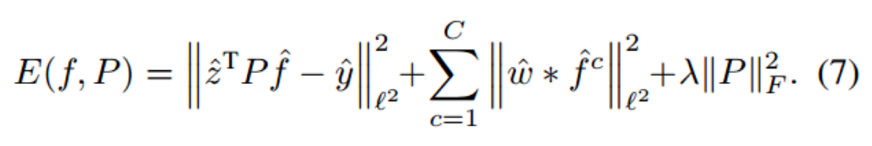简单来说,目标跟踪就是在连续的视频序列中,建立所要跟踪物体的位置关系,得到物体完整的运动轨迹。给定图像第一帧的目标坐标位置,计算在下一帧图像中目标的确切位置。目标跟踪是计算机视觉领域的一个重要问题,目前广泛应用在体育赛事转播、安防监控和无人机、无人车、机器人等领域。在运动的过程中,目标可能会呈现一些图像上的变化,比如姿态或形状的变化、尺度的变化、背景遮挡或光线亮度的变化等。目标跟踪算法的研究也围绕着解决这些变化和具体的应用展开。- 形态变化 - 姿态变化是目标跟踪中常见的干扰问题。运动目标发生姿态变化时, 会导致它的特征以及外观模型发生改变, 容易导致跟踪失败。例如:体育比赛中的运动员、马路上的行人。
- 尺度变化 - 尺度的自适应也是目标跟踪中的关键问题。当目标尺度缩小时, 由于跟踪框不能自适应跟踪, 会将很多背景信息包含在内, 导致目标模型的更新错误;当目标尺度增大时, 由于跟踪框不能将目标完全包括在内, 跟踪框内目标信息不全, 也会导致目标模型的更新错误。因此, 实现尺度自适应跟踪是十分必要的。
- 遮挡与消失 - 目标在运动过程中可能出现被遮挡或者短暂的消失情况。当这种情况发生时, 跟踪框容易将遮挡物以及背景信息包含在跟踪框内, 会导致后续帧中的跟踪目标漂移到遮挡物上面。若目标被完全遮挡时, 由于找不到目标的对应模型, 会导致跟踪失败。
- 图像模糊 - 光照强度变化, 目标快速运动, 低分辨率等情况会导致图像模型, 尤其是在运动目标与背景相似的情况下更为明显。因此, 选择有效的特征对目标和背景进行区分非常必要。
目标跟踪算法发展
跟踪算法主要从经典算法到基于核相关滤波算法,再到基于深度学习的跟踪算法。早期经典的跟踪方法比如 Meanshift、Particle Filter 和 Kalman Filter。Meanshift 方法是一种基于概率密度分布的跟踪方法,使目标的搜索一直沿着概率梯度上升的方向,迭代收敛到概率密度分布的局部峰值上。首先 Meanshift 会对目标进行建模,比如利用目标的颜色分布来描述目标,然后计算目标在下一帧图像上的概率分布,从而迭代得到局部最密集的区域。Meanshift 适用于目标的色彩模型和背景差异比较大的情形,早期也用于人脸跟踪。由于 Meanshift 方法的快速计算,它的很多改进方法也一直适用至今。粒子滤波(Particle Filter)方法是一种基于粒子分布统计的方法。以跟踪为例,首先对跟踪目标进行建模,并定义一种相似度度量确定粒子与目标的匹配程度。在目标搜索的过程中,它会按照一定的分布(比如均匀分布或高斯分布)撒一些粒子,统计这些粒子的相似度,确定目标可能的位置。在这些位置上,下一帧加入更多新的粒子,确保在更大概率上跟踪上目标。Kalman Filter 常被用于描述目标的运动模型,它不对目标的特征建模,而是对目标的运动模型进行了建模,常用于估计目标在下一帧的位置。另外,经典的跟踪方法还有基于特征点的光流跟踪,在目标上提取一些特征点,然后在下一帧计算这些特征点的光流匹配点,统计得到目标的位置。在跟踪的过程中,需要不断补充新的特征点,删除置信度不佳的特征点,以此来适应目标在运动中的形状变化。本质上可以认为光流跟踪属于用特征点的集合来表征目标模型的方法。基于核相关滤波的跟踪算法如MOSSE、CSK、KCF、BACF、SAMF将通信领域的相关滤波(衡量两个信号的相似程度)引入到了目标跟踪中,相关滤波的跟踪算法始于 2012 年 P.Martins 提出的 CSK 方法,作者提出了一种基于循环矩阵的核跟踪方法,并且从数学上完美解决了密集采样(Dense Sampling)的问题,利用傅立叶变换快速实现了检测的过程。在训练分类器时,一般认为离目标位置较近的是正样本,而离目标较远的认为是负样本。利用快速傅立叶变换,CSK 方法的跟踪帧率能达到 100~400fps,奠定了相关滤波系列方法在实时性应用中的基石。利用深度学习训练网络模型,得到的卷积特征输出表达能力更强,在目标跟踪上,初期的应用方式是把网络学习到的特征,直接应用到相关滤波或 Struck 的跟踪框架里面,从而得到更好的跟踪结果,网络不同层的卷积输出都可以作为跟踪的特征。
- 相比于光流法、Kalman、Meanshift等传统算法,相关滤波类算法跟踪速度更快,深度学习类方法精度高。
- 具有多特征融合以及深度特征的追踪器在跟踪精度方面的效果更好。
- 尺度的自适应以及模型的更新机制也影响着跟踪的精度。
相关滤波器思想
相关滤波跟踪的基本思想就是,设计一个滤波模板,利用该模板与目标候选区域做相关运算,最大输出响应的位置即为当前帧的目标位置。
其中 y 表示响应输出, x 表示输入图像, w 表示滤波模板。利用相关定理,将相关转换为计算量更小的点积。 分别是y,x,w 的傅里叶变换。相关滤波的任务,就是寻找最优的滤波模板w。一般的相关滤波都是固定学习率的线性加权更新模型,不需要显式保存训练样本,每帧样本训练的模型与已有目标模型,以固定权值加权来更新目标模型,这样以往的样本信息都会逐渐失效,而最近几帧的样本信息占模型的比重很大。如果出现目标定位不准确、遮挡、背景扰动等情况,固定学习率方式会平等对待这些“有问题”的样本,目标模型就会被污染导致跟踪失败。另外相关滤波模板类特征(HOG)对快速变形和快速运动效果不好,但对运动模糊光照变化等情况比较好。
相关滤波器发展
相关滤波跟踪的开篇之作,利用目标的多个样本作为训练样本,以生成更优的滤波器。MOSSE 以最小化平方和误差为目标函数,用m个样本求最小二乘解。
CSK针对MOSSE算法中采用稀疏采样造成样本冗余的问题,扩展了岭回归、基于循环移位的近似密集采样方法、以及核方法。MOSSE与CSK处理的都是单通道灰度图像,引入了循环移位和快速傅里叶变换,极大地提高了算法的计算效率。但是离散傅里叶变换也带来了一个副作用:边界效应。 针对边界效应,有2个典型处理方法:在图像上叠加余弦窗调制;增加搜索区域的面积。加余弦窗的方法,使搜索区域边界的像素值接近0,消除边界的不连续性。余弦窗的引入也带来了缺陷: 减小了有效搜索区域。例如在检测阶段,如果目标不在搜索区域中心,部分目标像素会被过滤掉。如果目标的一部分已经移出了这个区域,很可能就过滤掉仅存的目标像素。其作用表现为算法难以跟踪快速运动的目标。扩大搜索区域能缓解边界效应,并提高跟踪快速移动目标的能力。但缺陷是会引入更多的背景信息,可能造成跟踪漂移。
CN在CSK的基础上扩展了多通道颜色。将RGB的3通道图像投影到11个颜色通道,分别对应英语中常用的语言颜色分类,分别是black, blue, brown, grey, green, orange, pink, purple, red, white, yellow,并归一化得到10通道颜色特征。也可以利用PCA方法,将CN降维到2维。
从DCF到KCF多了Gaussian-kernel,performance上升0.21%,fps下降46.46%,kernel-trick虽然有用但影响较小,如果注重速度可以摒弃,如果追求极限性能可以用。KCF可以说是对CSK的完善。论文中对岭回归、循环矩阵、核技巧、快速检测等做了完整的数学推导。KCF在CSK的基础上扩展了多通道特征。KCF采用的HoG特征,核函数有三种高斯核、线性核和多项式核,高斯核的精确度最高,线性核略低于高斯核,但速度上远快于高斯核。
SAMF基于KCF,特征是HoG+CN。SAMF实现多尺度目标跟踪的方法比较直接,类似检测算法里的多尺度检测方法。由平移滤波器在多尺度缩放的图像块上进行目标检测,取响应最大的那个平移位置及所在尺度。因此这种方法可以同时检测目标中心变化和尺度变化。
从DSST到fDSST做了特征压缩和scale filter加速即特征降维和插值,performance上升6.13%,fps上升83.37%。 DSST将目标跟踪看成目标中心平移和目标尺度变化两个独立问题。首先用HoG特征的DCF训练平移相关滤波,负责检测目标中心平移。然后用HoG特征的MOSSE(这里与DCF的区别是不加padding)训练另一个尺度相关滤波,负责检测目标尺度变化。2017年发表的文章又提出了加速版本fDSST。 尺度滤波器仅需要检测出最佳匹配尺度而无须关心平移情况,其计算原理如图。DSST将尺度检测图像块全部缩小到同一个尺寸计算特征(CN+HoG),再将特征表示成一维(没有循环移位),尺度检测的响应图也是一维的高斯函数。 DSST本来就是对尺度自适应问题的快速解决方案(支持33个尺度还比SAMF快很多),在fDSST中MD大神又对DSST进行加速:
- 平移滤波器:PCA方法将平移滤波器的HOG特征从31通道降维到18通道,这一步骤与上面的CN特征类似,直接用PCA进行降维,作者提到由于这里用了线性核,所以不需要CN中所用的平滑子空间约束,更加简单粗暴。由于HOG特征天然会降低响应分辨率(cell_size=4),这里也采用简单粗暴的方法,将响应图的分辨率上采样到原始图像分辨率,也就是响应图插值以提高检测精度,方法是三角插值,等价于频谱添0,方法更加简单粗暴,但这一步会增加算法复杂度,而且方法太简单也必然效果较差。
- 尺度滤波器:QR方法将尺度滤波器的HOG特征(二特征,没有循环移位)~1000*17降维到17*17,由于自相关矩阵维度较大影响速度,为了效率这里没有用PCA而是QR分解。多尺度数量是17(DSST中的一半),响应图是1*17,这里也通过插值方法将尺度数量从17插值到33以获得更精确的尺度定位。
SRDCF与CFLB的思路都是扩大搜索区域,同时约束滤波模板的有效作用域解决边界效应。给滤波模板增加一个约束,对接近边界的区域惩罚更大,或者说让边界附近滤波模板系数接近0,速度比较慢。
使搜索区域内,目标区域以外的像素为0,CFLB仅使用单通道灰度特征,最新BACF将特征扩展为多通道HOG特征。CFLB和BACF采用Alternating Direction Method of Multipliers(ADMM)快速求解。
不是一种相关滤波方法,而是一种基于颜色统计特征方法。DAT统计前景目标和背景区域的颜色直方图,这就是前景和背景的颜色概率模型,检测阶段,利用贝叶斯方法判别每个像素属于前景的概率,得到像素级颜色概率图
从Staple到STAPLE+CA加入Context-Aware约束项,performance上升3.28%,fps下降43.18%,说明约束项有效,但牺牲了大量fps。STAPLE结合了模板特征方法DSST和颜色统计特征方法DAT。 相关滤波模板类特征(HOG)对快速变形和快速运动效果不好,但对运动模糊光照变化等情况比较好;而颜色统计特征(DAT)对变形不敏感,而且不属于相关滤波框架没有边界效应,但对光照变化和背景相似颜色不好。因此,这两类方法可以互补。
图像特征的表达能力在目标跟踪中起着至关重要的作用。以HoG+CN为代表的图像特征,性能优秀而且速度优势非常突出,但也成为性能进一步提升的瓶颈。以卷积神经网络(CNN)为代表的深度特征,具有更强大特征表达能力、泛化能力和迁移能力。将深度特征引入相关滤波也就水到渠成。
LMCF提出了两个方法,多峰目标检测和高置信度更新。多峰目标检测对平移检测的响应图做多峰检测,如果其他峰峰值与主峰峰值的比例大于某个阈值,说明响应图是多峰模式,以这些多峰为中心重新检测,并取这些响应图的最大值作为最终目标位置。 高置信度更新:只有在跟踪置信度比较高的时候才更新跟踪模型,避免目标模型被污染。一个置信度指标是最大响应。另一个置信度指标是平均峰值相关能量(average peak-to correlation energy, APCE),反应响应图的波动程度和检测目标的置信水平。
提出了空域可靠性和通道可靠性方法。空域可靠性利用图像分割方法,通过前背景颜色直方图概率和中心先验计算空域二值约束掩膜。这里的二值掩膜就类似于CFLB中的掩膜矩阵P。CSR-DCF利用图像分割方法更准确地选择有效的跟踪目标区域。通道可靠性用于区分检测时每个通道的权重。
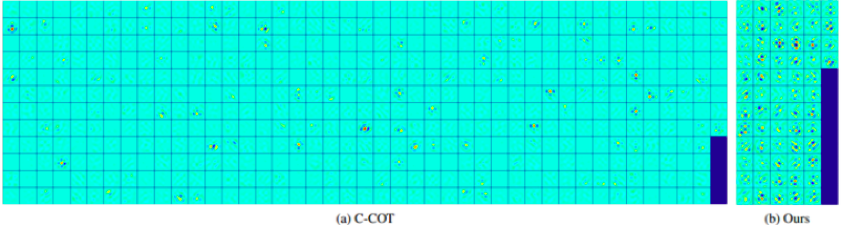
ECO是C-COT的加速版,从模型大小、样本集大小和更新策略三个方便加速,速度比C-COT提升了20倍,加量还减价,在VOT2016数据库上EAO提升了13.3%,当然最厉害的还是hand-crafted features版本的ECO-HC有60FPS,接下来分别看看这三步。 第一减少模型参数,既然CN特征和HOG特征都能降维,那卷积特征是不是也可以试试?这就是ECO中的加速第一步,也是最关键的一步,Factorized Convolution Operator分解卷积操作,效果类似PCA,但Conv. Feat.与前面的CN和HOG又不一样:
- CNN特征维度过于庞大,在C-COT中是96+512=608通道,需要降很多很多维才能保证速度,而无监督降维如果太多会直接影响效果(对比通用方法 - 取特征值的95%以上的维度,保留信息量);
- 虽然CNN特征迁移能力比较强,但这并不是针对跟踪问题专门训练的特征,对跟踪问题有用的信息隐藏在大量CNN激活值中,如果简单的无监督降维,可能会过滤掉那些虽然不显著,但对跟踪问题有效的特征信息。当然HOG和CN特征也有同样的问题。
P就是那个降维矩阵,放在目标函数中优化得到,具体求解比较复杂看论文吧,用PCA作为P的初始值去迭代优化,采用Gauss-Newton和Conjugate Gradient方法。但每帧都迭代优化降维矩阵速度反而会更慢,大神告诉我们仅在第一帧优化这个降维矩阵就可以了,第一帧优化完成后这个降维矩阵就是固定的,后续帧都直接用。Factorized Convolution Operator减少了80%的卷积特征还能略微提升性能,HC版本从31+11降维到10+3速度提升非常明显。至于为什么降维了还能提升效果,论文中说参数太多容易过拟合,也可能是判别力较低或者无用的通道响应图会成为噪声,淹没较高判别力的通道响应图。
第二减少样本数量,这个是针对Adaptive decontamination of the training set的加速,C-COT中要保存400个样本,但视频相邻帧之间的相似性非常高,存在大量相似的冗余样本,而且每次更新都要用样本集中所有样本做优化,速度非常慢。ECO中改为紧凑的生成样本空间模型compact generative mode,采用Gaussian Mixture Model (GMM)合并相似样本,建立更具代表性和多样性的样本集,需要保存和优化的样本集数量降到C-COT的1/8。用特征距离衡量两个样本的相似程度,样本合并方法是两个样本特征的权值相加,样本特征按照权值加权合并。 第三改变更新策略,以前CF方法都是每帧更新,这种过更新不仅慢,而且会导致模型对最近几帧严重过拟合,对遮挡、变形和平面外旋转等突然变化过度敏感,但对大多数方法都是无可奈何的,因为如KCF等方法不保存样本,这一帧不更新就再也没机会了。 但ECO保存了所有样本的代表性样本集,所以完全没有必要每帧都更新,这里采用了sparser updating scheme(稀疏更新策略),即每隔5帧更新一次模型参数,这不但提高了算法速度,而且提高了对突变,遮挡等情况的稳定性,三步优化中稀疏更新对效果提升最大。由于ECO的样本集是每帧都更新的,稀疏更新并不会错过间隔期的样本变化信息,但这种方法可能不适合没有样本集的方法,如KCF,因为没有保存样本集。---END---
双一流大学研究生团队创建,一个专注于目标检测与深度学习的组织,希望可以将分享变成一种习惯。
将「目标检测与深度学习」设为星标★,并点击右下角“在看“,解锁推送限制,第一时间收到我们的分享。
整理不易,点赞三连↓