
HBase操作组件:Hive、Phoenix、Lealone
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多资源



1、Hive是什么
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
1.1、为什么使用 Hive
直接使用 MapReduce 所面临的问题:
1、人员学习成本太高
2、项目周期要求太短
3、MapReduce实现复杂查询逻辑开发难度太大
为什么要使用 Hive:
1、更友好的接口:操作接口采用类 SQL 的语法,提供快速开发的能力
2、更低的学习成本:避免了写 MapReduce,减少开发人员的学习成本
3、更好的扩展性:可自由扩展集群规模而无需重启服务,还支持用户自定义函数
1.2、Hive和HBase的通信意图
Hive与HBase整合的实现是利用两者本身对外的API接口互相通信来完成的,其具体工作交由Hive的lib目录中的hive-hbase-handler-*.jar工具类来实现,通信原理如图1所示。
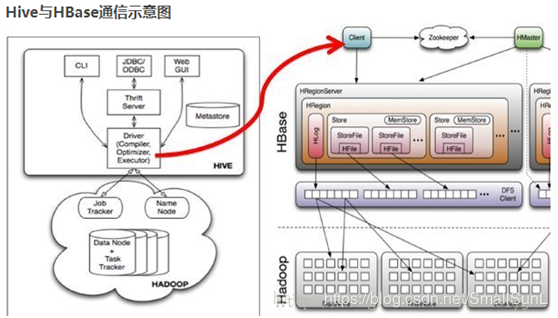
Hive整合HBase后的使用场景:
通过Hive把数据加载到HBase中,数据源可以是文件也可以是Hive中的表。
通过整合,让HBase支持JOIN、GROUP等SQL查询语法。
通过整合,不仅可完成HBase的数据实时查询,也可以使用Hive查询HBase中的数据完成复杂的数据分析。
1.3、hbase整合hive的优缺点
优点:
2、Phoenix的简介hbase 提供很方便的shell脚本以及java API等方式对Hbase进行操作,但是对于很对已经习惯了关系型数据库操作的开发来说,有一定的学习成本,如果可以像操作mysql等一样通过sql实现对Hbase的操作,那么很大程度降低了Hbase的使用成本。Apache Phoenix 组件就完成了这种需求,Phoenix是构建在HBase上的一个SQL层,能让我们用标准的JDBC APIs而不是HBase客户端APIs来创建表,插入数据和对HBase数据进行查询。Phoenix完全使用Java编写,作为HBase内嵌的JDBC驱动。Phoenix查询引擎会将SQL查询转换为一个或多个HBase扫描,并编排执行以生成标准的JDBC结果集。官方注解为 “Phoenix -we put the SQL back in NoSql”,通过官方说明,Phoenix 的性能很高,相对于 hbase 原生的scan 并不会差多少,而对于类似的组件 hive、Impala等,性能有着显著的提升Phoenix查询引擎支持使用SQL进行HBase数据的查询,会将SQL查询转换为一个或多个HBase API,协同处理器与自定义过滤器的实现,并编排执行。使用Phoenix进行简单查询,其性能量级是毫秒。2.1、Phoenix官网给出的性能测试在官网,做过一个性能测试,主要是将Phoenix和Hive作一个对比。测试的结果如图2:
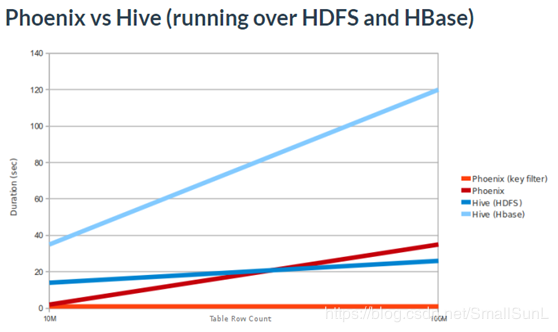 从图中可看出,带有Key过滤的Phoenix耗时最少,不带Key过滤的Phoenix和基于HDFS的Hive性能差不多,直接基于HBase的Hive性能最差。
从图中可看出,带有Key过滤的Phoenix耗时最少,不带Key过滤的Phoenix和基于HDFS的Hive性能差不多,直接基于HBase的Hive性能最差。2.2、目前使用Phoenix的公司及使用方向
阿里使用Phoenix:• 针对结果集相对较小的大型数据集,比如10万条左右的记录。选择在这种情况下使用Phoenix,因为它比HBase本机api更容易使用,同时支持orderby/ groupby语法• 具有大结果集的大型数据集,即使在PrimaryKey过滤器之后,结果集中也可能有数百万条记录,并且通常伴随着大量聚合/ orderby / groupby调用。在这种情况下使用Pheonix,可以在HBase中进行复杂的查询,并且它支持传统数据库(如oracle)中的越来越多的功能,这使更容易将BI查询迁移到HBase的数据库中。
搜狗使用Phoenix:• 商业智能:使用HBase + Phoenix存储广告交易平台的数十亿条记录,由于Phoenix的SQL抽象和二级索引,可以为广告客户提供多维统计和分析报告,使他们能够通过全面的洞察力做出明智的决策最大化他们的投资收入。• 技术基础设施:监控平台和分布式服务跟踪平台使用HBase +Phoenix连续收集各种指标和日志(目前每秒约10万条记录),凭借Phoenix的高性能,可以轻松生成系统运行健康测量的统计数据和服务依赖性分析。
3、Lealone是什么
阿里开源的一个兼具RDBMS、NoSQL优点的面向OLTP场景的异步化NewSQL单机与分布式关系数据库。其架构图如下。
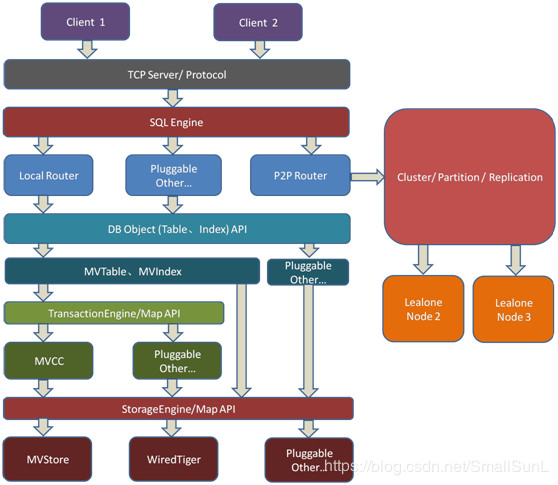 3.1、Lealone具有以下特点:
3.1、Lealone具有以下特点:开源版本(不支持分布式)• 完全异步化,使用少量线程就能处理大量并发 • 基于SQL优先级的抢占式调度,慢查询不会长期霸占CPU• 创建JDBC连接非常快速,占用资源少,不再需要JDBC连接池 • 插件化存储引擎架构,内置MVStore存储引擎• 插件化事务引擎架构,事务处理逻辑与存储分离 • 支持索引、视图、Join、子查询、触发器、自定义函数、Order By、GroupBy、聚合 • 从H2数据库借鉴了大量成熟的代码和思想企业版本(支持分布式)• 内置AOSE自适应优化存储引擎(Adaptive Optimization Storage Engine)• 高性能分布式事务,使用一种非常新颖的基于局部时间戳的多版本冲突与有效性检测的分布式事务模型 • 支持全局快照隔离 • 支持强一致性复制• 支持自动化分片(Sharding),用户不需要关心任何分片的规则,没有热点,能够进行范围查询
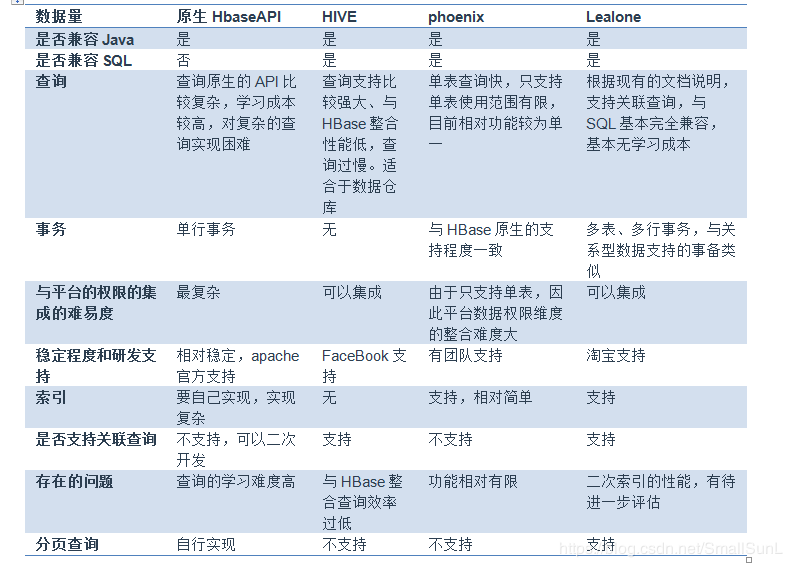
4、HBASE操作组件功能比较:
 欢迎点赞+收藏+转发朋友圈素质三连
欢迎点赞+收藏+转发朋友圈素质三连文章不错?点个【在看】吧! ?