
时序预测的三种方式:统计学模型、机器学习、循环神经网络
导读
时序预测是一类经典的问题,在学术界和工业界都有着广泛的研究和应用。甚至说,世间万物加上时间维度后都可抽象为时间序列问题,例如股票价格、天气变化等等。关于时序预测问题的相关理论也极为广泛,除了经典的各种统计学模型外,当下火热的机器学习以及深度学习中的循环神经网络也都可以用于时序预测问题的建模。今天,本文就来介绍三种方式的简单应用,并在一个真实的时序数据集上加以验证。
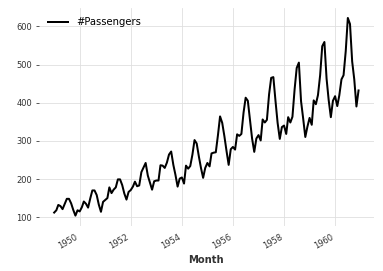
时间序列预测,其主要任务是基于某一指标的历史数据来预测其在未来的取值,例如上图中的曲线记录了1949年至1960年共12年144个月份的每月航班乘客数(具体单位未经考证),那么时序预测要解决的问题就是:给定前9年的历史数据,例如1949-1957,那么能否预测出1958-1960两年间的乘客数量的问题。
为了解决这一问题,大概当前主流的解决方式有4种:
统计学模型,较为经典的AR系列,包括AR、MA、ARMA以及ARIMA等,另外Facebook(准确的讲,现在应该叫Meta了)推出的Prophet模型,其实本质上也是一种统计学模型,只不过是传统的趋势、周期性成分的基础上,进一步细化考虑了节假日、时序拐点等因素的影响,以期带来更为精准的时序规律刻画;
机器学习模型,在有监督机器学习中,回归问题主要解决的是基于一系列Feature来预测某一Label的可能取值的问题,那么当以历史数据作为Feature时其实自然也就可以将时序预测问题抽象为回归问题,从这一角度讲,所有回归模型都可用于解决时序预测。关于用机器学习抽象时序预测,推荐查看这篇论文《Machine Learning Strategies for Time Series Forecasting》;
深度学习模型,深度学习主流的应用场景当属CV和NLP两大领域,其中后者就是专门用于解决序列问题建模的问题,而时间序列当然属于序列数据的一种特殊形式,所以自然可以运用循环神经网络来建模时序预测;
隐马尔科夫模型,马尔科夫模型是用于刻画相邻状态转换间的经典抽象,而隐马尔科夫模型则在其基础上进一步增加了隐藏状态,来以此丰富模型的表达能力。但其一大假设条件是未来状态仅与当前状态有关,而不利于利用多个历史状态来共同参与预测,较为常用的可能就是天气预报的例子了。
本文主要考虑前三种时序预测建模方法,并分别选取:1)Prophet模型,2)RandomForest回归模型,3)LSTM三种方案加以测试。
df = pd.read_csv("AirPassengers.csv", parse_dates=["date"]).rename(columns={"date":"ds", "value":"y"})X_train = df[df.ds<"19580101"]X_test = df[df.ds>="19580101"]plt.plot(X_train['ds'], X_train['y'])plt.plot(X_test['ds'], X_test['y'])
1.Prophet模型预测。Prophet是一个高度封装好的时序预测模型,接受一个DataFrame作为训练集(要求有ds和y两个字段列),在预测时也接受一个DataFrame,但此时只需有ds列即可,关于模型的详细介绍可参考其官方文档:https://facebook.github.io/prophet/。模型训练及预测部分核心代码如下:
from prophet import Prophetpro = Prophet()pro.fit(X_train)pred = pro.predict(X_test)pro.plot(pred)
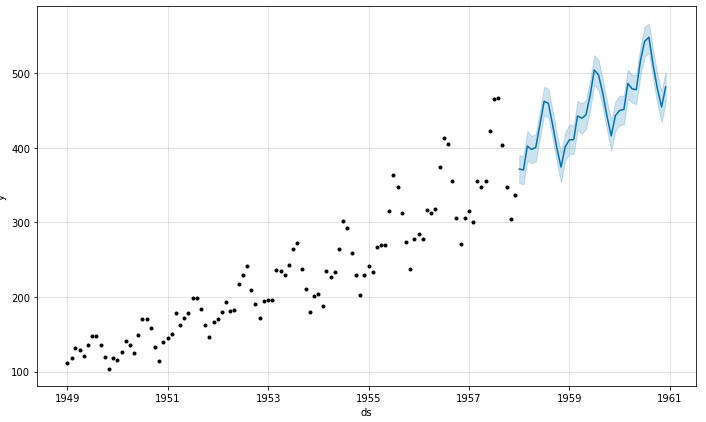
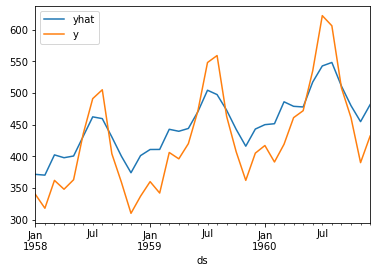
易见,虽然序列的整体走势上具有良好的拟合结果,但在具体取值上其实差距还是比较大的。
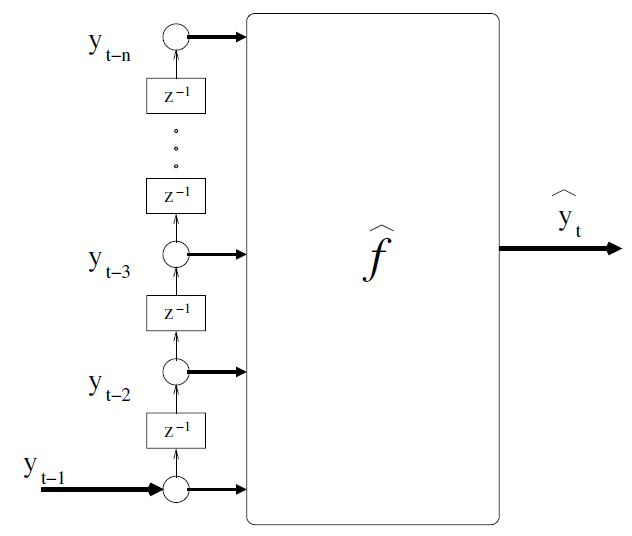
据此,设置特征提取窗口长度为12,构建训练集和测试集的方式如下:
data = df.copy()n = 12for i in range(1, n+1):data['ypre_'+str(i)] = data['y'].shift(i)data = data[['ds']+['ypre_'+str(i) for i in range(n, 0, -1)]+['y']]# 提取训练集和测试集X_train = data[data['ds']<"19580101"].dropna()[['ypre_'+str(i) for i in range(n, 0, -1)]]y_train = data[data['ds']<"19580101"].dropna()[['y']]X_test = data[data['ds']>="19580101"].dropna()[['ypre_'+str(i) for i in range(n, 0, -1)]]y_test = data[data['ds']>="19580101"].dropna()[['y']]# 模型训练和预测rf = RandomForestRegressor(n_estimators=10, max_depth=5)rf.fit(X_train, y_train)y_pred = rf.predict(X_test)# 结果对比绘图y_test.assign(yhat=y_pred).plot()
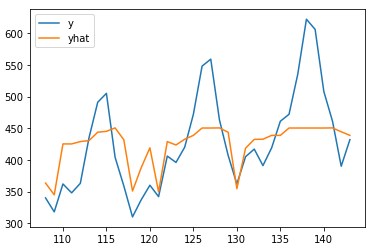
可见,预测效果也较为一般,尤其是对于最后两年的预测结果,与真实值差距还是比较大的。用机器学习模型的思维很容易解释这一现象:随机森林模型实际上是在根据训练数据集来学习曲线之间的规律,由于该时序整体呈现随时间增长的趋势,所以历史数据中的最高点也不足以cover住未来的较大值,因而在测试集中超过历史数据的所有标签其实都是无法拟合的。
class Model(nn.Module):def __init__(self):super().__init__()self.rnn = nn.LSTM(input_size=1, hidden_size=10, batch_first=True)self.linear = nn.Linear(10, 1)def forward(self, x):x, _ = self.rnn(x)x = x[:, -1, :]x = self.linear(x)return x
数据集构建思路整体同前述的机器学习部分,而后,按照进行模型训练炼丹,部分结果如下:
# 数据集转化为3DX_train_3d = torch.Tensor(X_train.values).reshape(*X_train.shape, 1)y_train_2d = torch.Tensor(y_train.values).reshape(*y_train.shape, 1)X_test_3d = torch.Tensor(X_test.values).reshape(*X_test.shape, 1)y_test_2d = torch.Tensor(y_test.values).reshape(*y_test.shape, 1)# 模型、优化器、评估准则model = Model()creterion = nn.MSELoss()optimizer = optim.Adam(model.parameters())# 训练过程for i in range(1000):out = model(X_train_3d)loss = creterion(out, y_train_2d)optimizer.zero_grad()loss.backward()optimizer.step()if (i+1)%100 == 0:y_pred = model(X_test_3d)loss_test = creterion(y_pred, y_test_2d)print(i, loss.item(), loss_test.item())# 训练结果99 65492.08984375 188633.796875199 64814.4375 187436.4375299 64462.09765625 186815.5399 64142.70703125 186251.125499 63835.5 185707.46875599 63535.15234375 185175.1875699 63239.39453125 184650.46875799 62947.08203125 184131.21875899 62657.484375 183616.203125999 62370.171875 183104.671875
通过上述1000个epoch,大体可以推断该模型不会很好的拟合了,所以果断放弃吧!
当然必须指出的是,上述测试效果只能说明3种方案在该数据集上的表现,而不能代表这一类模型在用于时序预测问题时的性能。实际上,时序预测问题本身就是一个需要具体问题具体分析的场景,没有放之四海而皆准的好模型,就像“No Free Lunch”一样!
本文仅是作为时序预测系列推文的一个牛刀小试,后续将不定期更新其他相关心得和总结。
相关阅读: