
从演进式角度看消息队列
来源:大数据与机器学习文摘 本文约10000字,建议阅读15分钟 本文尝试通过技术演进的方式,以redis、kafka和 pulsar为例,逐步深入,讲讲它们架构和原理,帮助你更好地理解和学习消息队列。


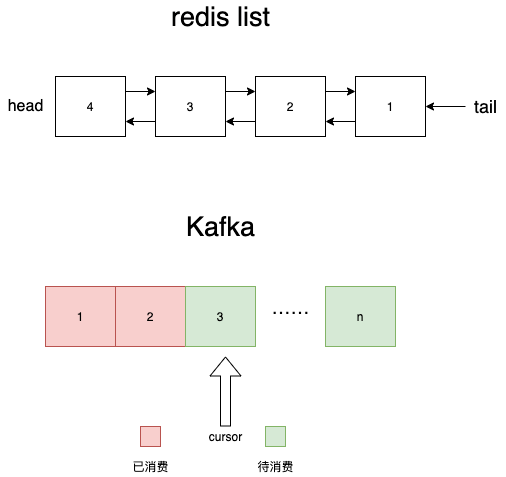
push_front:添加元素到队首; pop_tail:从队尾取出元素。
lpush:从队列左边插入数据; rpop:从队列右边取出数据。
消息持久化:redis是内存数据库,虽然有aof和rdb两种机制进行持久化,但这只是辅助手段,这两种手段都是不可靠的。当redis服务器宕机时一定会丢失一部分数据,这对于很多业务都是没法接受的。 热key性能问题:不论是用codis还是twemproxy这种集群方案,对某个队列的读写请求最终都会落到同一台redis实例上,并且无法通过扩容来解决问题。如果对某个list的并发读写非常高,就产生了无法解决的热key,严重可能导致系统崩溃。 没有确认机制:每当执行rpop消费一条数据,那条消息就被从list中永久删除了。如果消费者消费失败,这条消息也没法找回了。你可能说消费者可以在失败时把这条消息重新投递到进队列,但这太理想了,极端一点万一消费者进程直接崩了呢,比如被kill -9,panic,coredump… 不支持多订阅者:一条消息只能被一个消费者消费,rpop之后就没了。如果队列中存储的是应用的日志,对于同一条消息,监控系统需要消费它来进行可能的报警,BI系统需要消费它来绘制报表,链路追踪需要消费它来绘制调用关系……这种场景redis list就没办法支持了。 不支持二次消费:一条消息rpop之后就没了。如果消费者程序运行到一半发现代码有bug,修复之后想从头再消费一次就不行了。
热key的问题无法解决,即:无法通过加机器解决性能问题; 数据会被删除:rpop之后就没了,因此无法满足多个订阅者,无法重新从头再消费,无法做ack。
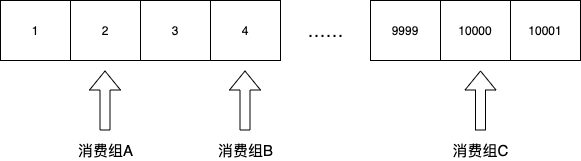
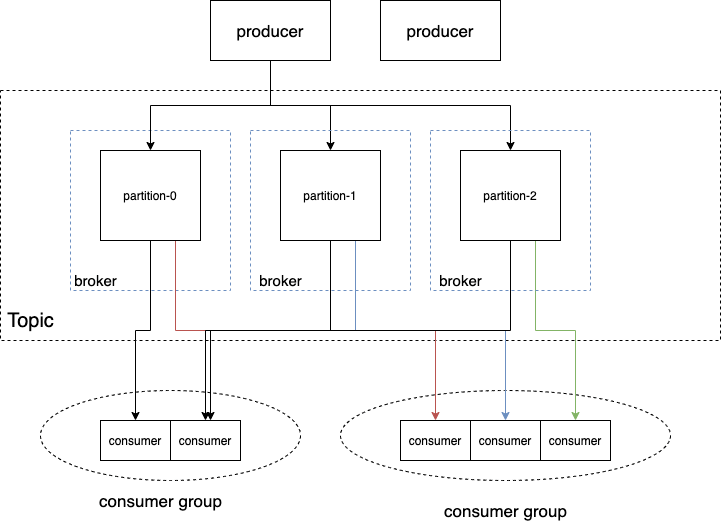
{ "topic-foo": { "groupA": { "partition-0": 0, "partition-1": 123, "partition-2": 78 }, "groupB": { "partition-0": 85, "partition-1": 9991, "partition-2": 772 }, }}br
1. Kafka中的数据查找
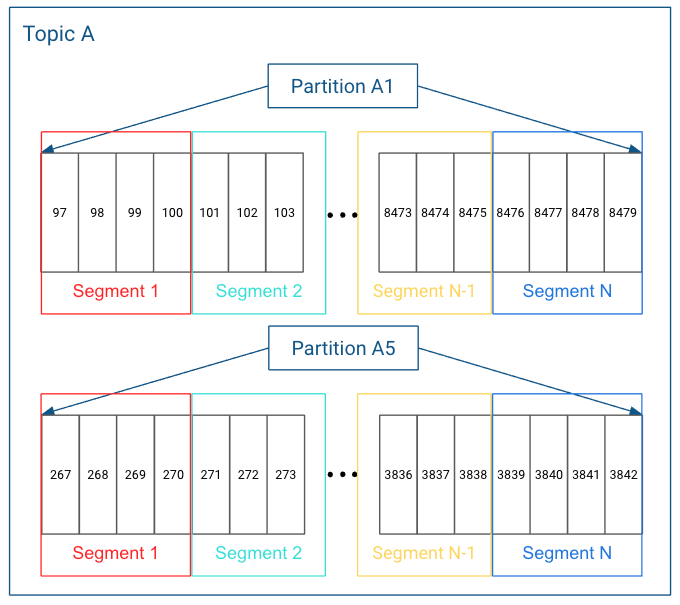
第2897条消息在哪个segment文件里; 第2897条消息在segment文件里的什么位置。
- /kafka/topic/order_create/partition-0 - 0.log - 18234.log #segment file - 39712.log - 54101.log br
- /kafka/topic/order_create/partition-0 - 0.log - 0.index - 18234.log #segment file - 18234.index #index file - 39712.log - 39712.index - 54101.log - 54101.index br
当要查询offset为x的消息 利用二分查找找到这条消息在y.log 读取y.index文件找到消息x的y.log中的位置 读取y.log的对应位置,获取数据
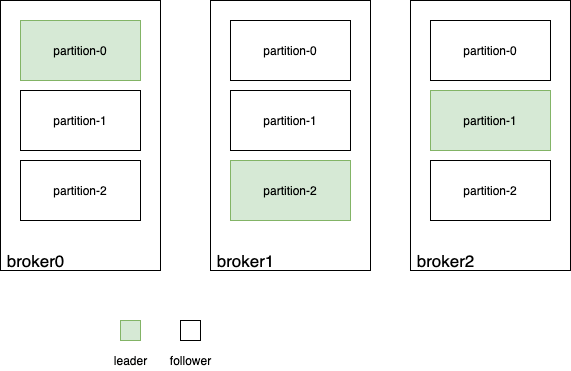
2. Kafka高可用
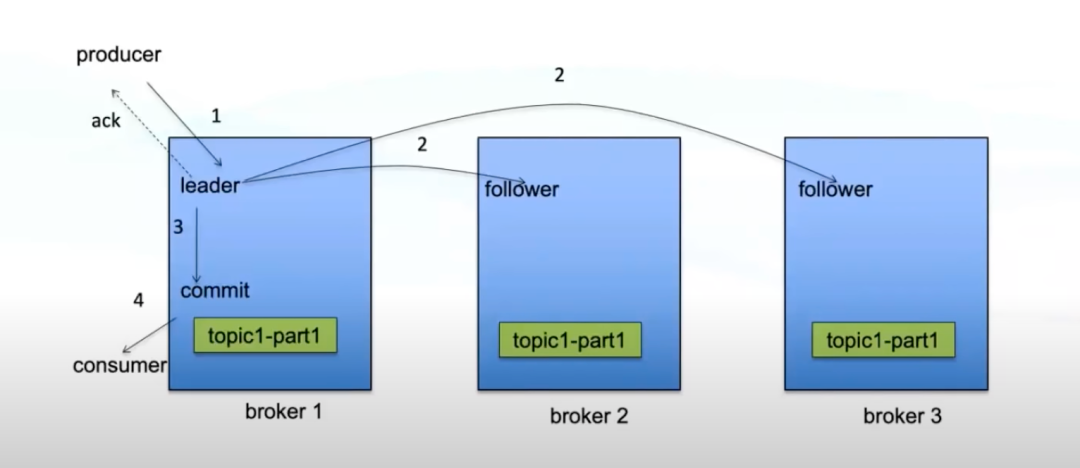
如果producer的数据到达leader并成功写入leader的log就进行ack 优点:不用等数据同步完成,速度快,吞吐率高,可用性高; 缺点:如果follower数据同步未完成时leader挂了,就会造成数据丢失,可靠性低。 如果等follower都同步完数据时进行ack 优点:当leader挂了之后follower中也有完备的数据,可靠性高; 缺点:等所有follower同步完成很慢,性能差,容易造成生产方超时,可用性低。
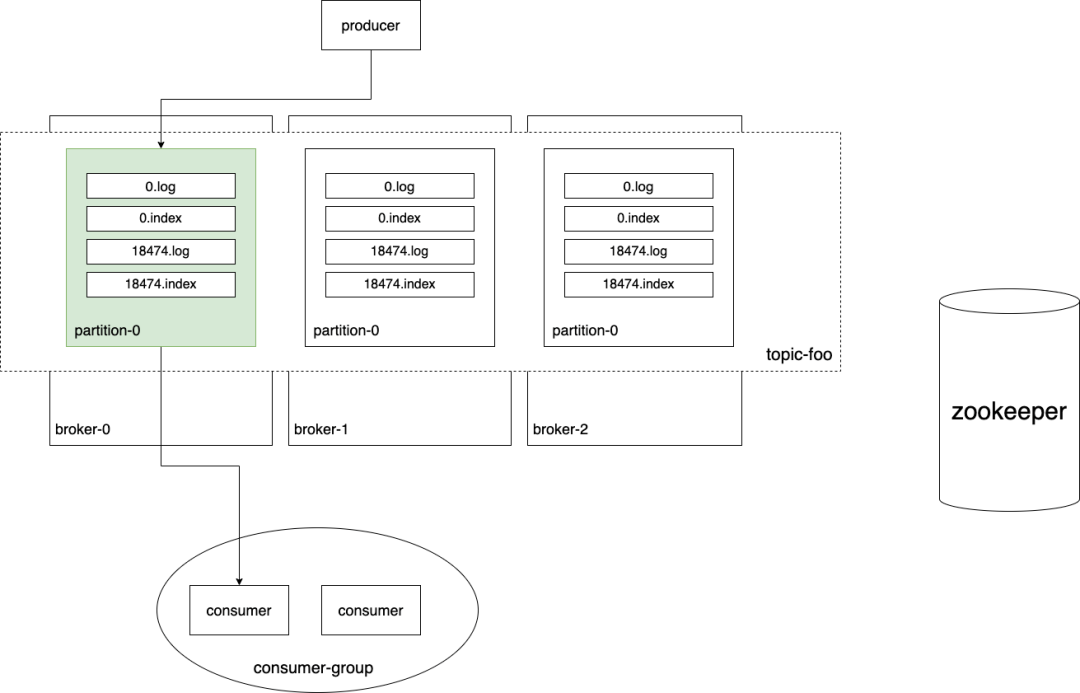
3. 优缺点
高性能:单机测试能达到 100w tps; 低延时:生产和消费的延时都很低,e2e的延时在正常的cluster中也很低; 可用性高:replicate + isr + 选举 机制保证; 工具链成熟:监控 运维 管理 方案齐全; 生态成熟:大数据场景必不可少 kafka stream.
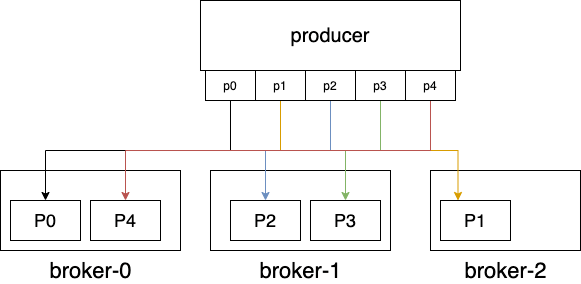
无法弹性扩容:对partition的读写都在partition leader所在的broker,如果该broker压力过大,也无法通过新增broker来解决问题; 扩容成本高:集群中新增的broker只会处理新topic,如果要分担老topic-partition的压力,需要手动迁移partition,这时会占用大量集群带宽; 消费者新加入和退出会造成整个消费组rebalance:导致数据重复消费,影响消费速度,增加e2e延迟; partition过多会使得性能显著下降:ZK压力大,broker上partition过多让磁盘顺序写几乎退化成随机写。
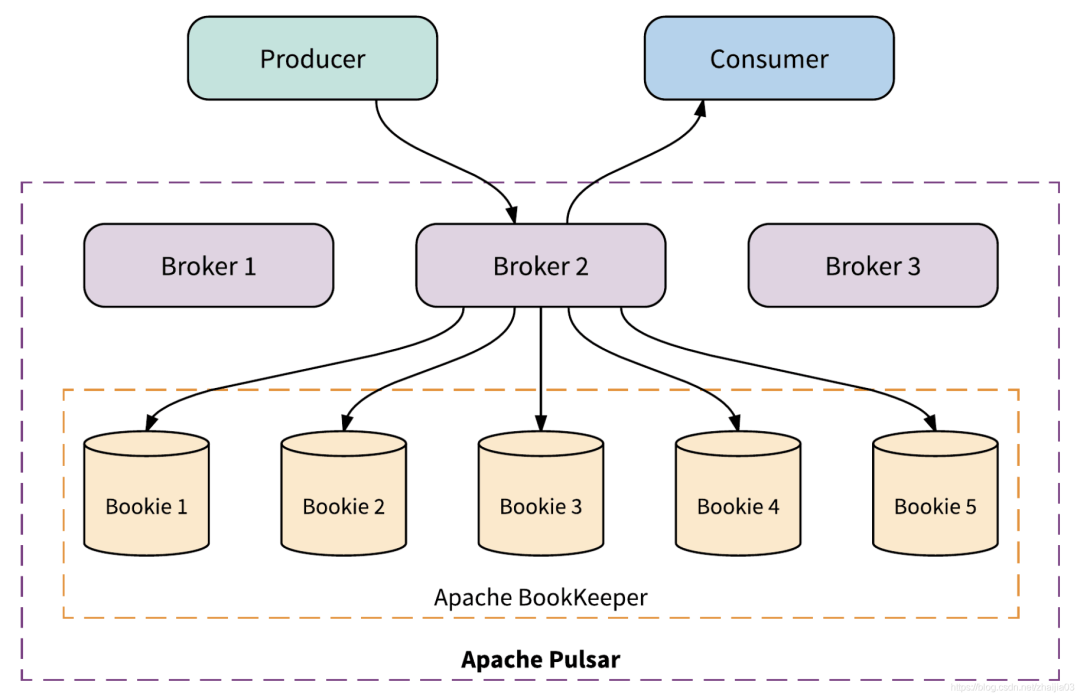
节点数n:bookeeper集群的bookie数; 副本数m:某一个ledger会写入到n个bookie中的m个里,也就是说所谓的m副本; 确认写入数t:每次向ledger写入数据时(并发写入到m个bookie),需要确保收到t个acks,才返回成功。
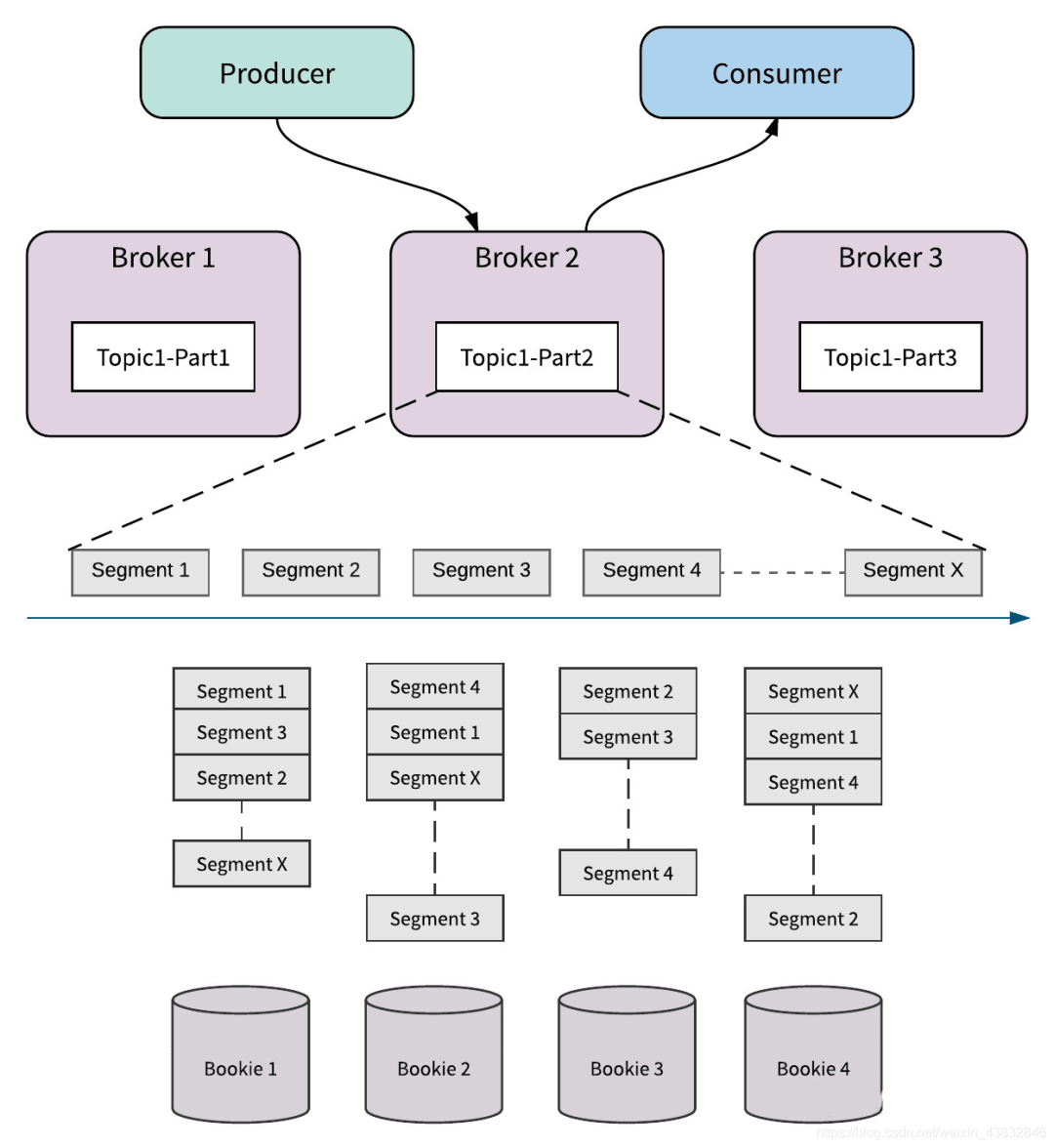
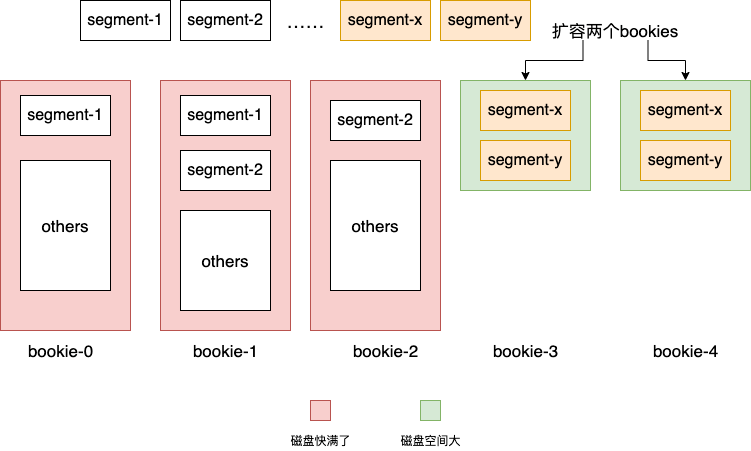
broker是无状态的,随便扩容; partition以segment为单位分散到整个bookeeper集群,没有单点,也可以轻易地扩容; 当某个bookie发生故障,由于多副本的存在,可以另外t-1个副本中随意选出一个来读取数据,不间断地对外提供服务,实现高可用。
消费模型
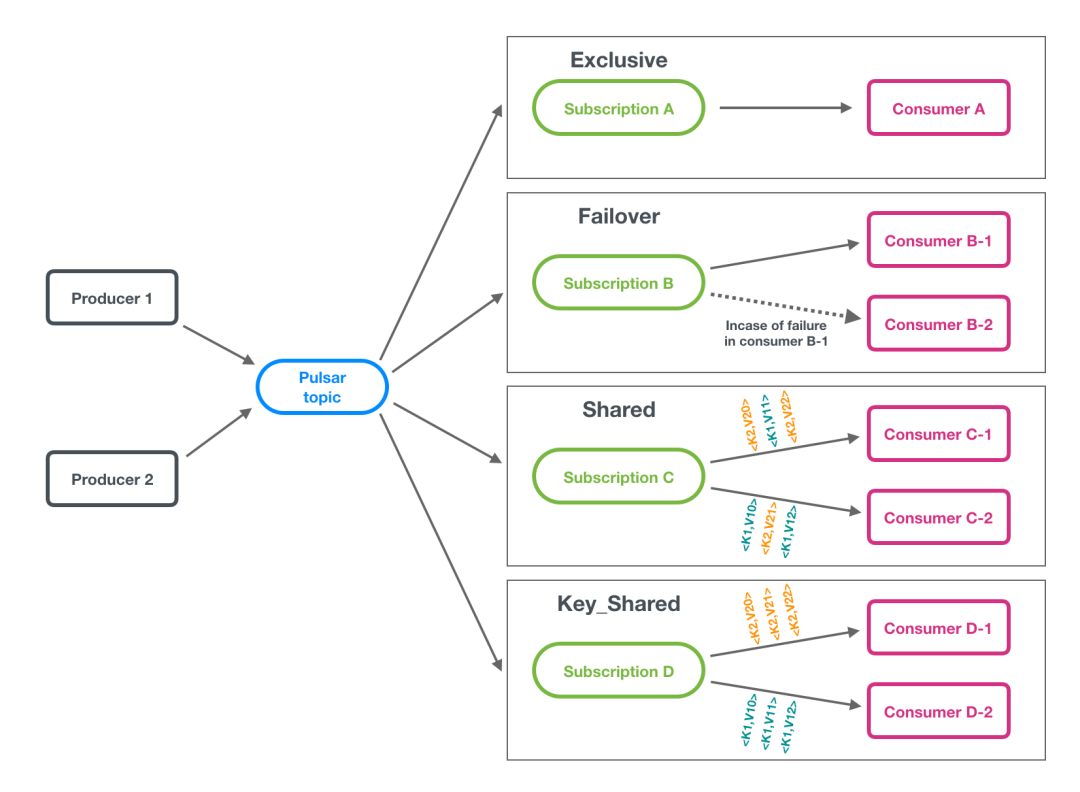
exclusive:消费组里有且仅有一个consumer能够进行消费,其它的根本连不上pulsar; failover:消费组里的每个消费者都能连上每个partition所在的broker,但有且仅有一个consumer能消费到数据。当这个消费者崩溃了,其它的消费者会被选出一个来接班; shared:消费组里所有消费者都能消费topic中的所有partition,消息以round-robin的方式来分发; key-shared:消费组里所有消费者都能消费到topic中所有partition,但是带有相同key的消息会保证发送给同一个消费者。
评论