
激光雷达和相机感知融合简介
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
来源:十点雨@知乎
https://zhuanlan.zhihu.com/p/446284775
仅供学术交流,侵删
本文介绍激光雷达和相机融合的两种方法:
前融合:融合原始数据(点云和像素/目标框)。
后融合:融合目标框。
1. 前融合
前融合一般指融合原始数据,最容易、最普遍的方式是将点云投影到图像。然后检查点云是否属于图像中检测的2D目标框。流程如下:
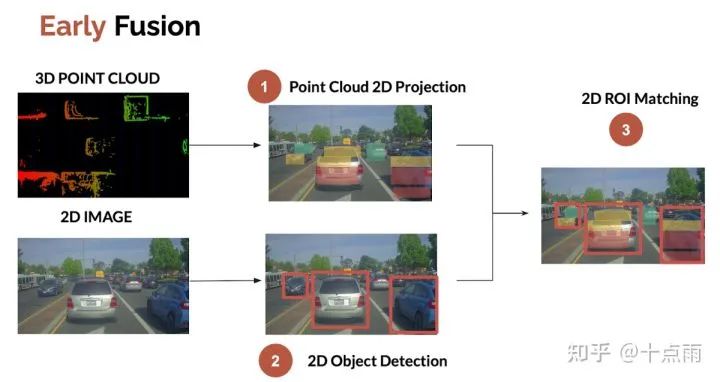
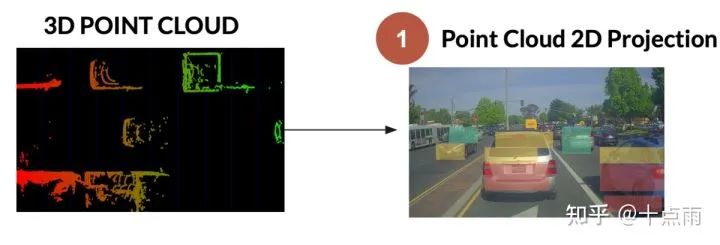
1.1 点云投影
三步:
将3D激光雷达点转换为齐次坐标
将点云变换到图像坐标系(LiDAR-Camera外参)
透视投影到图像平面 (相机内参)
1.2 图像目标检测
一般使用YOLO系列算法。可以参考:https://www.thinkautonomous.ai/blog/?p=introduction-to-yolov4-research-review
1.3 ROI匹配
ROI (Region Of Interest)匹配即融合目标边界框内的数据。这一步的输出:
对于每个2D边界框,图像检测提供类别。
对于每个LiDAR投影点,我们有准确的距离。
因此,融合目标语义类别和空间位置就完善了。这一步的重点是如何融合目标边界框内的投影点,作为目标位置:求平均,中值,中心点,最近点?
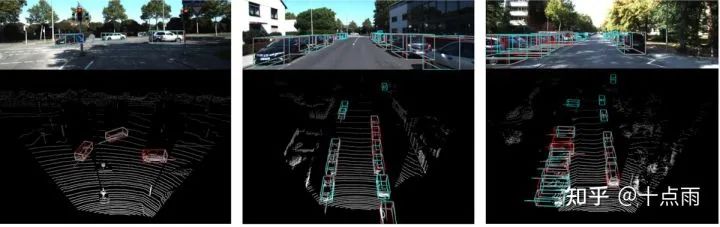
另外,图像目标框往往比真实目标大一些,目标边界框内投影点云可能不属于真实目标(比如可能属于背景,或附近目标)。针对这个问题,采用图像分割,可以更准确地匹配投影点和像素。
下图箭头处显示了投影点在目标框内,但不属于目标框对应的车辆,而是前方车辆的点云。

2. 后融合
后融合是融合各个传感器独立的检测结果,有两种融合思路:
2D融合:图像2D检测,点云3D检测投影到图像生成的2D检测。如下图:

3D融合:图像3D检测,点云3D检测。流程如下:

下文详细介绍下3D融合的思路。
2.1 点云3D目标检测
传统方法:聚类,L-shape fitting等
深度学习方法:centerpoint等
2.2 图像3D目标检测
单目3D目标检测,需要知道投影参数(相机内参,标定外参),并使用深度学习。知道目标的真实大小和朝向也有助于得到目标的准确边界框。
分享一篇单目3D检测论文:https://arxiv.org/pdf/1612.00496.pdf

2.3 IOU匹配
IOU即Intersection Over Union, 描述两个边界框的重合程度。
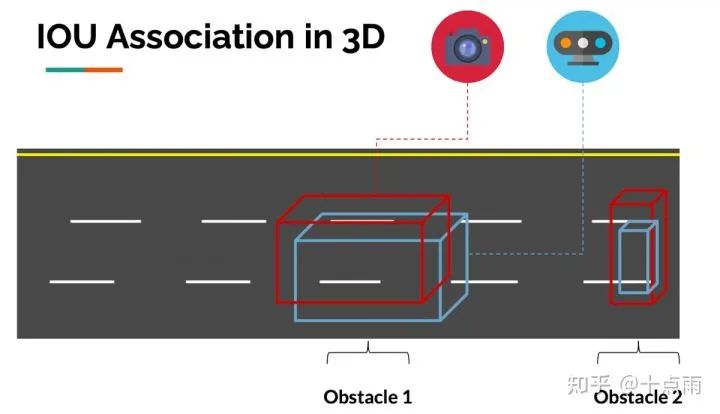
2.3.1 空域上的IOU匹配
匹配就是看图像3D边界框和点云3D边界框是否重合(用IOU衡量),重合度高则是同一个目标。3D Iou--Net (2020)中的示例图像:
因此,我们可以在空域上将不同传感器的检测目标进行关联。
这个过程在9 Types of Sensor Fusion Algorithms(https://www.thinkautonomous.ai/blog/?p=9-types-of-sensor-fusion-algorithms)中,被定义为中级(middle-level)传感器融合。中级传感器融合和高级传感器融合的区别是,高级传感器融合包括跟踪。
而为了时间跟踪,则需要时域上的数据关联。
2.3.2 时域上的IOU匹配
目标跟踪一般用卡尔曼滤波和匈牙利算法来关联时域上的目标,从而跨帧跟踪目标,甚至预测目标位置。

跟踪3D边界框位置时,一般用IOU作为度量进行数据关联。当然也可以使用深度卷积特征来确保目标一致。我们称该过程为SORT (Simple Online Realtime Tracking), 或Deep SORT,如果使用深度卷积特征。
时域上IOU匹配的原理与空域上类似:如果第一帧和第二帧的边界框重合,则说明两个目标是相同的。
既然我们可以在空域和时域上跟踪目标,那么也可以利用类似方法进行高级的传感器融合。
2.4 后融合总结
融合检测目标是中级的融合,需要空域上的IOU匹配;融合跟踪轨迹是高级的融合,需要时域上的IOU匹配(匹配度量),卡尔曼滤波(状态估计),匈牙利算法(数据关联)。
本文仅做学术分享,如有侵权,请联系删文。