这周我们会接着上周的话题,继续聊一聊Hudi的实现原理,主要关注Hudi的核心读写逻辑,数据的存储和处理逻辑,以及一些附属的功能。正在使用或是考虑使用Hudi的朋友,请不要错过,因为理解了实现原理以后可以避免很多使用上的坑,也能更好地发挥出Hudi的优势。
由于这篇文章会用到上一篇文章中讲到的知识,还没有读过的朋友,推荐先读完上一篇文章。Merge on Read(简称MOR表),是Hudi最初开源时尚处于“实验阶段”的新功能,在开源后的0.3.5版本开始才告完成。现在则是Hudi最常用的表类型。
之所以在COW表之后又增加了一种新的表类型,原因在上一篇文章中也有提到Merge on Read则是对Copy on Write的优化。优化了什么呢?主要是写入性能。
导致COW表写入慢的原因,是因为COW表每次在写入时,会把新写入的数据和老数据合并以后,再写成新的文件。单单是写入的过程(不包含前期的repartition和tagging过程),就包含至少三个步骤:- 读取老数据的parquet文件(涉及对parquet文件解码,不轻松)
- 将合并后的数据重新写成parquet文件(又涉及parquet文件编码,也不轻松)

种种原因导致COW表的写入速度始终快不起来,限制了其在时效性要求高,写入量巨大的场景下的应用。(关于parquet文件不轻松的原因,可以看这篇文章《详解Parquet文件格式》)为了解决COW表写入速度上的瓶颈,Hudi采用了另一种写入方式:upsert时把变更内容写入log文件,然后定期合并log文件和base文件。这样的好处是避免了写入时读取老数据,也就避免了parquet文件不轻松的编解码过程,只需要把变更记录写入一个文件即可(而且是顺序写入)。显然是轻松了不少。
warehouse├── .hoodie├── 20220101│ ├── fileId1_001.parquet│ ├── .fileId1_20220312163419285.log│ └── .fileId1_20220312172212361.log└── 20220102 ├── fileId2_001.parquet └── .fileId2_20220312163512913.log
典型的MOR表的目录,注意log文件包含写入的时间戳有些朋友这时或许会有疑问,“这样写入固然是轻松了,但怎么读到最新的数据呢?”是个好问题。为了解决读取最新数据的问题,Hudi提供了好几种机制,但从原理上来说只有两种:- 读取数据时,同时从base文件和log文件读取,并把两边的数据合并
- 定期地、异步地把log文件的数据合并到base文件(这个过程被称为compaction)
第一种机制也是Merge on Read这个名字的由来,因为Hudi的读取过程是实时地把base数据和log数据合并起来,并返回给用户。注意这两种机制不是非此即彼的,而是互为补充。Hudi的默认配置就是同时使用这两种机制,即:读取时merge,同时定期地compact。在读取时合并数据,听起来很影响效率。事实也是如此,因为实时合并的实现方式是把所有log文件读入内存,放在一个HashMap里,然后遍历base文件,把base数据和缓存在内存里的log数据进行join,最后才得到合并后的结果。难免会影响到读取效率。COW影响写入,MOR影响读取,那有没有什么办法可以兼顾读写,鱼与熊掌能不能得兼?目前来说不能,好在Hudi把选择权留给了用户,让用户可以根据自身的业务需求,选择不同的query类型。对于MOR表,Hudi支持3种query类型,分别是
其中1和3就是为了平衡读和写之间的取舍。这两者的区别是:Snapshot Query和上文所说的一样,读取时进行“实时合并”;Read Optimized Query则不同,只读取base文件,不读取log文件,因此读取效率和COW表相同,但读到的数据可能不是最新的。以上讲完了Hudi和upsert相关的主要功能,接下来讲讲Hudi另一大特色功能:Transactional,也就是事务功能。
Hudi的事务功能被称为Timeline,因为Hudi把所有对一张表的操作都保存在一个时间线对象里面。Hudi官方文档中对于Timeline功能的介绍稍微有点复杂,不是很清晰。其实从用户角度来看的话,Hudi提供的事务相关能力主要是这些:| 特性 | 功能
|
|---|
原子性
| 写入即使失败,也不会造成数据损坏 |
隔离性
| 读写分离,写入不影响读取,不会读到写入中途的数据 |
回滚
| 可以回滚变更,把数据恢复到旧版本 |
| 时间旅行 | 可以读取旧版本的数据(但太老的版本会被清理掉) |
存档
| 可以长期保存旧版本数据(存档的版本不会被自动清理) |
| 增量读取 | 可以读取任意两个版本之间的差分数据 |
讲完了功能清单,接下来就讲一讲事务的实现原理。内容以COW表为主,但MOR表也可以由此类推,因为MOR表本质上是对COW表的优化。
这里沿用上一篇文章中的例子,假设初始我们有5条数据,内容如下| txn_id | user_id
| item_id
| amount
| date
|
|---|
| 1 | 1
| 1
| 2 | 20220101
|
| 2 | 2 | 1 | 1 | 20220101 |
| 3 | 1
| 2
| 3
| 20220101 |
4
| 1 | 3 | 1 | 20220102 |
5
| 2
| 3 | 2 | 20220102 |
实际存储的目录结构是这样的(文件名做了简化)
warehouse├── .hoodie├── 20220101│ ├── fileId1_001.parquet│ └── fileId1_002.parquet├── 20220102│ └── fileId2_001.parquet└── 20220103 └── fileId3_001.parquet
它的数据保存在fileId1_001和fileId2_001两个文件里。我们称呼这个版本为v1。接下来我们写入3条新的数据,其中1条是更新,2条是新增。
| txn_id | user_id
| item_id | amount | date |
|---|
3
| 1 | 2 | 5
| 20220101
|
6
| 1 | 4
| 1 | 20220103 |
7
| 2 | 3 | 2
| 20220103 |
写入后的目录结构如下
warehouse├── .hoodie├── 20220101│ ├── fileId1_001.parquet│ └── fileId1_002.parquet├── 20220102│ └── fileId2_001.parquet└── 20220103 └── fileId3_001.parquet
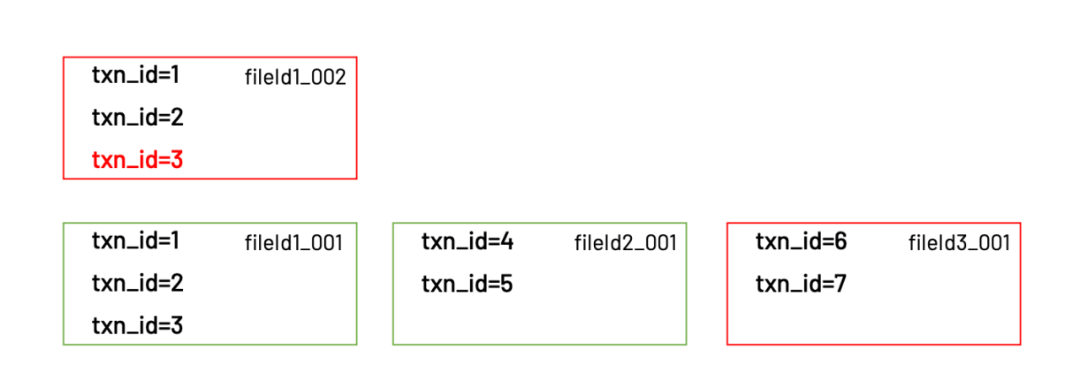
更新的1条数据(txn_id=3)保存在fileId1_002这个文件里,而新增的2条数据(txn_id=6和txn_id=7)则被保存在fileId3_001。
Hudi在这张表的timeline里(实际存放在.hoodie目录下)会记录下v1和v2对应的文件列表。当client读取数据时,首先会查看timeline里最新的commit是哪个,从最新的commit里获得对应的文件列表,再去这些文件读取真正的数据。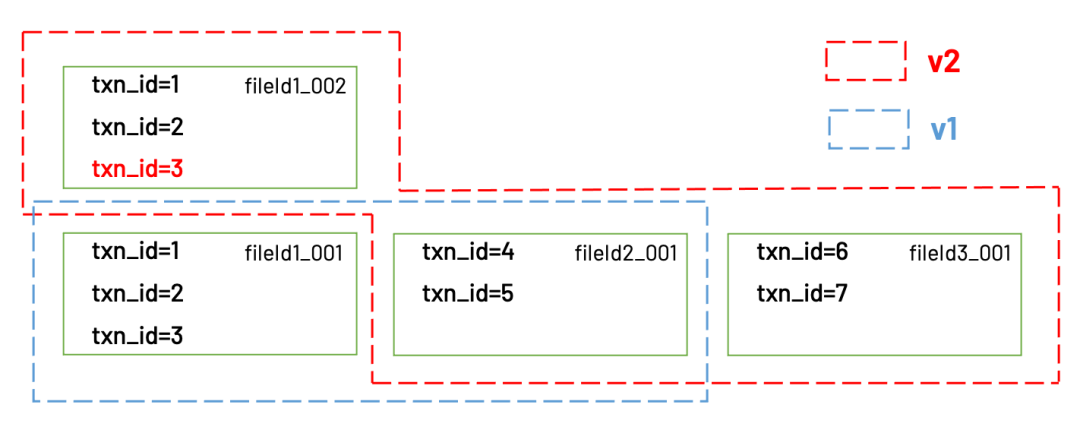
v1和v2对应的文件
Hudi通过这种方式实现了多版本隔离的能力。当一个client正在读取v1的数据时,另一个client可以同时写入新的数据,新的数据会被写入新的文件里,不影响v1用到的数据文件。只有当数据全部写完以后,v2才会被commit到timeline里面。后续的client再读取时,读到的就是v2的数据。顺带一提的是,尽管Hudi具备多版本数据管理的能力,但旧版本的数据不会无限制地保留下去。Hudi会在新的commit完成时开始清理旧的数据,默认的策略是“清理早于10个commit前的数据”。最后再讲讲Hudi的另一个特色功能:Incremental Query(增量查询)。这个功能提供给用户“读取任意两个commit之间差分数据”的能力。这个功能也是基于上述的“多版本数据管理”实现的,下面就来讲讲。还是以上文的例子,假设我们想要读取v1 → v2之间的差分数据Hudi会计算出v2到v1之间的差异是两个文件:fileId01_002和fileId03_001,然后client从这两个文件中读到的就是增量数据。有些朋友或许会发现,fileId01_002里面包含了两条老数据txn_id=1和txn_id=2,不属于v2到v1的差分数据,不应该被读取。确实如此。其实Hudi对每一条数据,都有一个隐藏字段_hoodie_commit_time用于记录commit时间,这个字段会和其他数据字段一起保存在parquet文件里。Hudi在读取parquet文件时,会同时用这个字段对结果进行过滤,把不属于时间范围内的记录都过滤掉。关于Hudi原理的讲解,写到这里就差不多告一段落了。接下来可能会继续介绍”数据湖三剑客“的其他两个——Iceberg和Delta,以及它们之间的对比。如果朋友们对接下来想看到什么内容有好的建议,欢迎在公众号后台留言。