
数据倾斜了怎么办?以应届生 20K Offer 为例

数据倾斜,技术黑话中最成功的的一个词。发明这个词儿的人,一定是天才,它在数据量和复杂度上,一箭双雕。
早期,我在看《Oracle Concepts》及各类 Oracle Performance Tunning 相关的技术书时,书中提到最多的术语是“数据分布”,比如用 statistics 统计每列的散值。这里的散值,又称单值,或“唯一值”,代表每列的基数 (Cardinality).
比如全世界就两种性别,男和女。无论男女数量多么不平衡,就性别来说,只有“男”,“女”两个单值,用数据库行话说,Cardinality 为 2.
那么知道每列的基数,有什么用呢,研究数据倾斜又有啥用?这种凡事先问有啥用的精致利己的心态,从求学时代,就与我纠缠不清。
所以,到底为什么要研究数据倾斜这个话题呢,我先放几张图,做个引子:
第一张图,为艾瑞咨询绘制的中国 IT服务行业,毕业生薪资流向的分布图。这张图的实际薪资曲线,符合正态分布
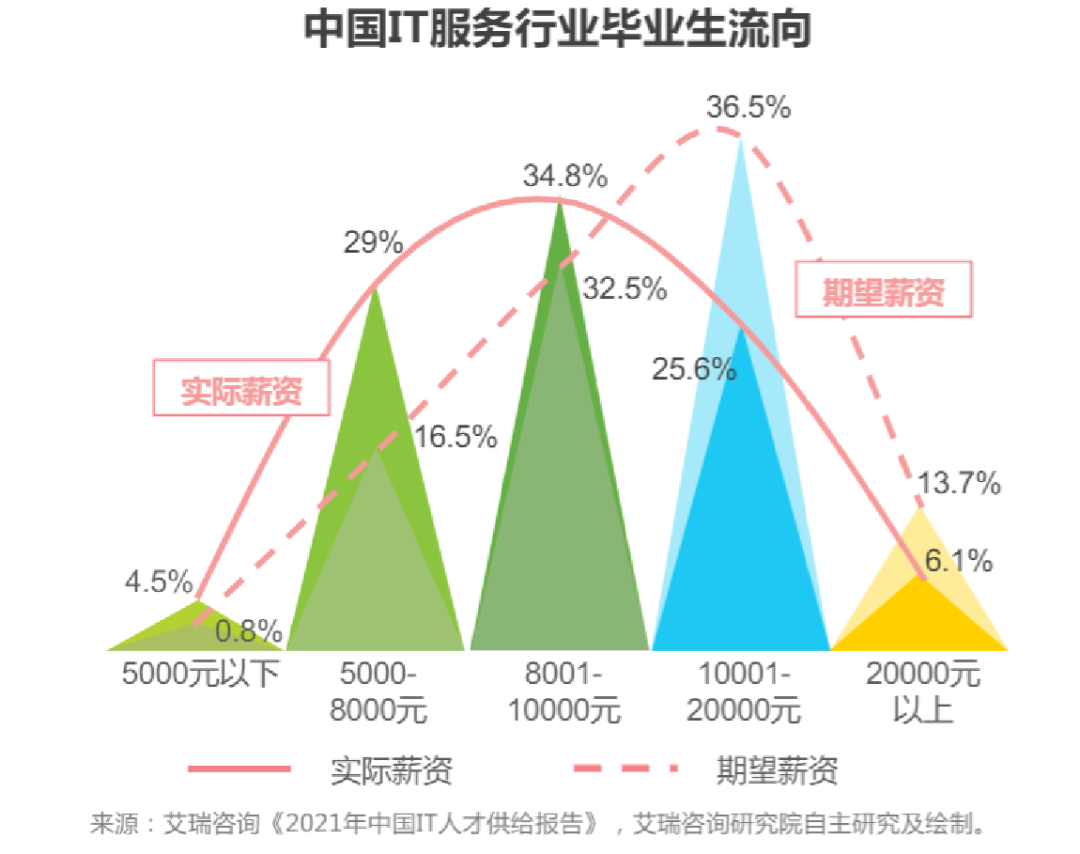
薪资区间,分别从左往右以 4.5%, 29%, 34.8%,25.6%,6.1% 的占比存在,可见大多数毕业生(29% + 34.8% + 25.6% =89.4%),初次入职时,薪资在 5K - 20K 之间。
假设,有 1000人参与了这次调查,那么你作为老板,要招个有 1 年经验,还能出活的劳动力,而且预算不能超过 5K,只要去 45 个人里面招,就能快速招到你要的人。
如果作为老板的你,愿意开出有竞争力的工资,比如 20K,你可以从 894 个人里面招,但如此巨大的规模,也增加了面试的时间成本。
考虑到社会的毒打,人的潜能被充分发挥,经过一定时间沉淀,社会人的薪酬,就不像应届生排列得那么符合正态分布了
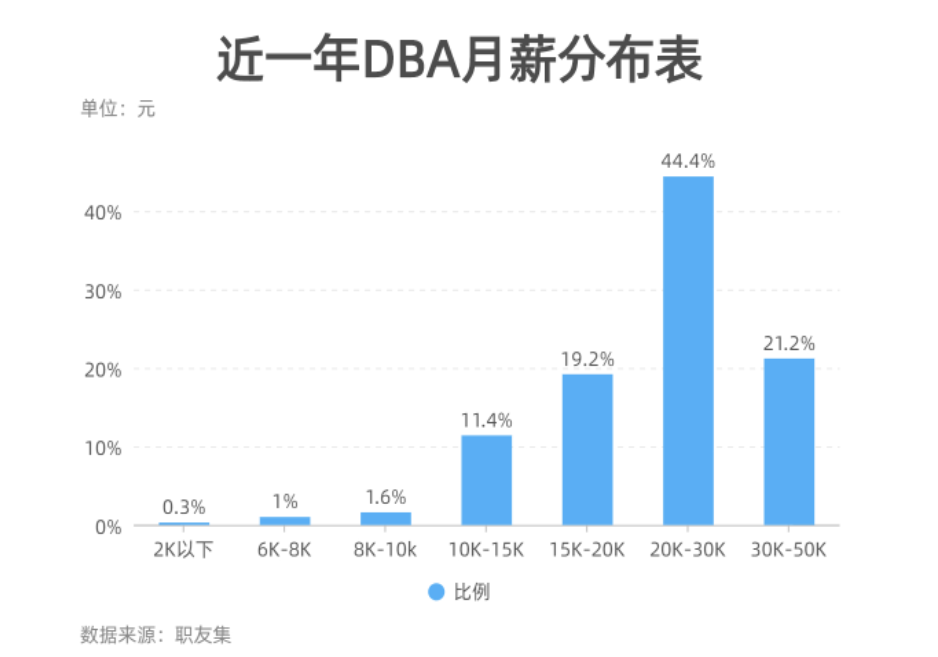
以 20K 为分水岭,DBA 薪资往 20K 以上倾斜,这个范围的占比为 44.4%+ 21.2% = 65.6%.
同样以 1000人为调查基数,意味着以 50K 去招人,面试者可能会超过 656 人,面试时间成本太高。而 6K 去招人,则只需面试 30人,快则 2 天,人就到位。
此时,我们可以得到一个经验:数据发生倾斜是必然,极端的数据非常好找,但落到正态分布的中间位置,找起来就复杂了,所以得同时配备其他属性,才能更好定位到相关数据。
既然 20K-50K 的 DBA 人数那么多,怎样才能更快地招到人呢。有一个办法是,从低价格的地方挖人。
比如:
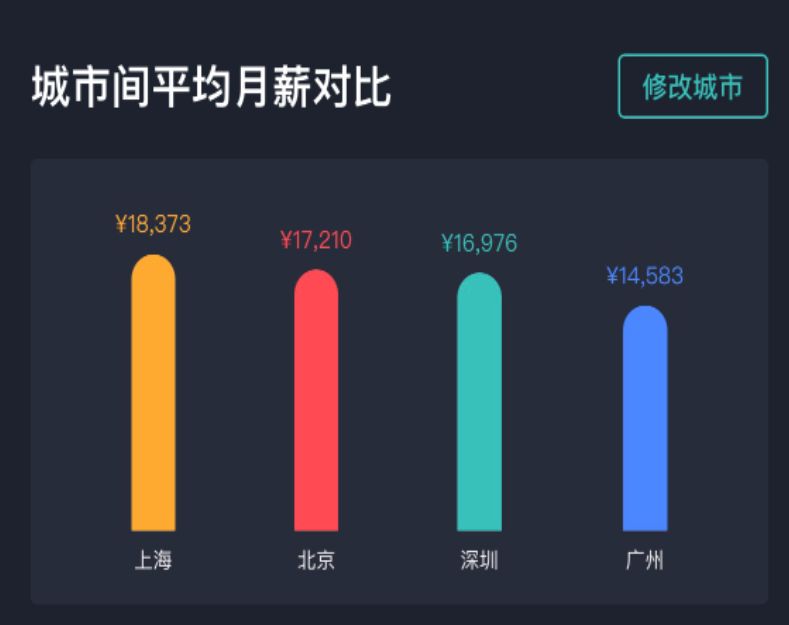
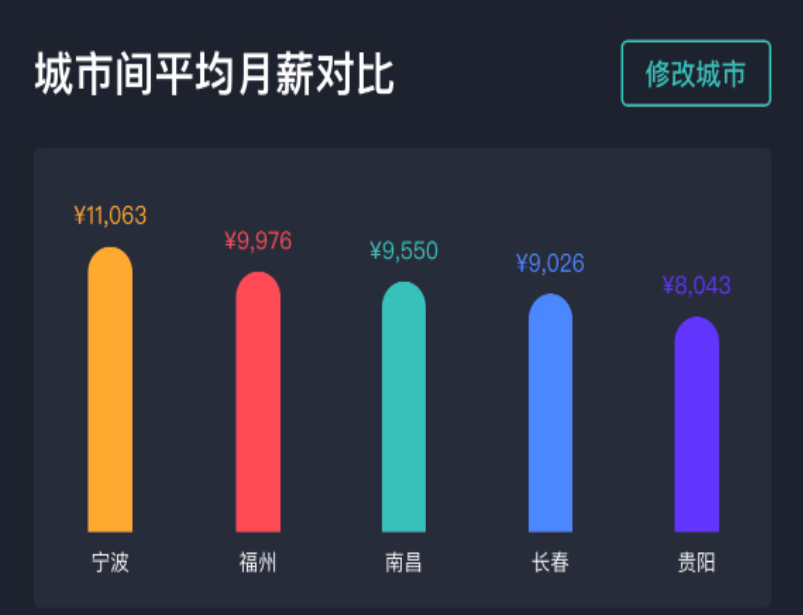
对比发现,贵阳地区以 8K 为平均数,那么直接以 20K 的价格,则可以很快招到人。
你看,加一维数据量就变小了。这就是处理数据倾斜的一个有效方法,以薪酬水平加地区,极大地减少样本数量,提高了筛选效率。
细看数据倾斜的解决方法,本质是判断怎么建索引更有效。最为关键的一步,是计算列组合的数据量占总数的比例,越低越有效。
那么,怎么计算列组合产生的基数高低呢,总不能每次全表扫描,做一遍排列组合计算吧?
接下来说两个常用的事前策略:
第一,是直觉。作为设计者,对业务数据的分布,一定会有意识。比如做零售,按照日期和门店做索引,肯定订单量分散更低;
第二,是做 Hash 索引。假设你在日期上装了索引,但查询里面,基本不按日期搜索,索引白建。于是,找两个或多个常用判断字段,做 Hash 索引。这样,就碎化了组合查询的密度,提高了效率
以上的策略,主要考量命中率。怎么分析命中率,这属于优化界的秘密武器,每个数据库厂商都有自己的数据字典,需要有好奇心的读者,慢慢摸索。原理都相通!
举个例子, SQL Server 中,有一种叫做 Statistics 的东西。它就是用来统计基数以及命中率的对象。
它通过统计每列或列组合的单值总数,计算在表总数据量上的占比。由此计算出这列的命中率,继而判断是否适合做索引。
使用以下命令即可查询每列或列组合的单值总数:
DBCC SHOW_STATISTICS('Sales.SalesOrderDetail', IX_SalesOrderDetail_ProductID)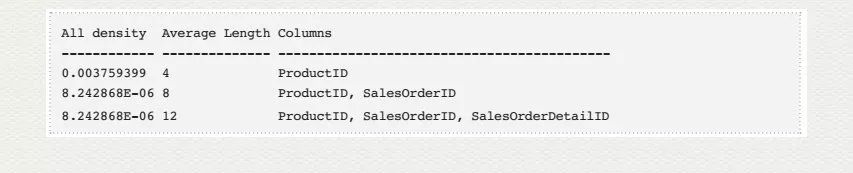
这就是索引 IX_SalesOrderDetail_ProductID 的密度(Density). 密度越低,查询的命中率就越高,效率就越高
当然,用密度来预判命中率,也有一定的缺陷,需要注意很多地方,比如和柱状图的连用等等。详细的技术实战参考这篇文章:
点击上方链接直达,为你详细解释 statistics 的查询,创建和效率优势,包括:
Statistics 分别有哪些查询方法
Statistics 分别有哪些创建方法
Statistics 在查询中的效率优势
好了,分享就到这里。最近魔都发生了些事,大家都知道了。作息,情绪都有些影响,所以更新频率有些慢,各位多担待。
往期精彩: