
Python实现电脑录音(含音频基础知识讲解)
咪哥杂谈

本篇阅读时间约为 6 分钟。
1
前言
但是有些细节点,和我想的不太一样。所以呢,我还是决定自己体验一波流程,顺便踩踩坑,毕竟是从兴趣出发。
而在上篇文章留言区中,有个小伙伴也提出,其实在去年,就已经用树莓派实现了这系列的功能,我觉得还是蛮有意思的一件事。
下面进入正题。
2
环境准备
这款第三方库,是一个跨平台音频库。
跨平台的性质,不用多说了吧!就是多面兼容你的系统,不论你是用的 windows 、mac、linux,它都是支持的。
安装命令如下:
pip install PyAudiomac的同志们,需要注意下,安装的时候可能会报错,安装如下即可。
brew install portaudio完备的第三方库都会有对应的文档,地址如下:
https://people.csail.mit.edu/hubert/pyaudio/docs/#pyaudio3
录音功能实现
PS: 音频方面的东西,我之前也没过多了解,近期写了 PyAudio 库的代码实现后才发现,要想明白代码的含义,还要有一些音频方面的知识作为前置储蓄,所以下面我会结合代码去通俗讲解,若有哪里不对的地方,欢迎评论区留言指出!
先来看代码。
设定参数:
CHUNK = 1024 # 每个缓冲区的帧数FORMAT = pyaudio.paInt16 # 采样位数CHANNELS = 1 # 单声道RATE = 44100 # 采样频率
设定具体实现的参数,分别有 缓冲区帧数、采样位数、声道模式、采样频率。
具体实现录音代码:
def record_audio(wave_out_path, record_second):""" 录音功能 """p = pyaudio.PyAudio() # 实例化对象stream = p.open(format=FORMAT,channels=CHANNELS,rate=RATE,input=True,frames_per_buffer=CHUNK) # 打开流,传入响应参数wf = wave.open(wave_out_path, 'wb') # 打开 wav 文件。wf.setnchannels(CHANNELS) # 声道设置wf.setsampwidth(p.get_sample_size(FORMAT)) # 采样位数设置wf.setframerate(RATE) # 采样频率设置for _ in range(0, int(RATE * record_second / CHUNK)):data = stream.read(CHUNK)wf.writeframes(data) # 写入数据stream.stop_stream() # 关闭流stream.close()p.terminate()wf.close()
首先对 pyaudio 库进行实例化。用其生成的实例化对象对数据流进行相应的打开,也就是 open 函数。在这块,分别传入了参数,采样位数、声道、采样频率,以及最后的缓冲区帧数。
调用 Python 自带的 wave 库,再次进行写入 wav 的相关设置。此处的操作类似 Python 写 txt ,只不过多了点音频设置而已。
用 采样频率 * 音频秒数/ 每个缓冲区帧数 ,得到的就是你要写入多少个块缓冲区的数量。最终,只需要每次循环写入固定的 1024,一共循环得出的多少个块缓冲区。即可得到最终的数据。
这里的公式计算,如果在不了解下述基础概念之前,是很难理解的。
4
音频基础知识普及
首先, wav 和 mp3 的后缀结尾,有什么不同?
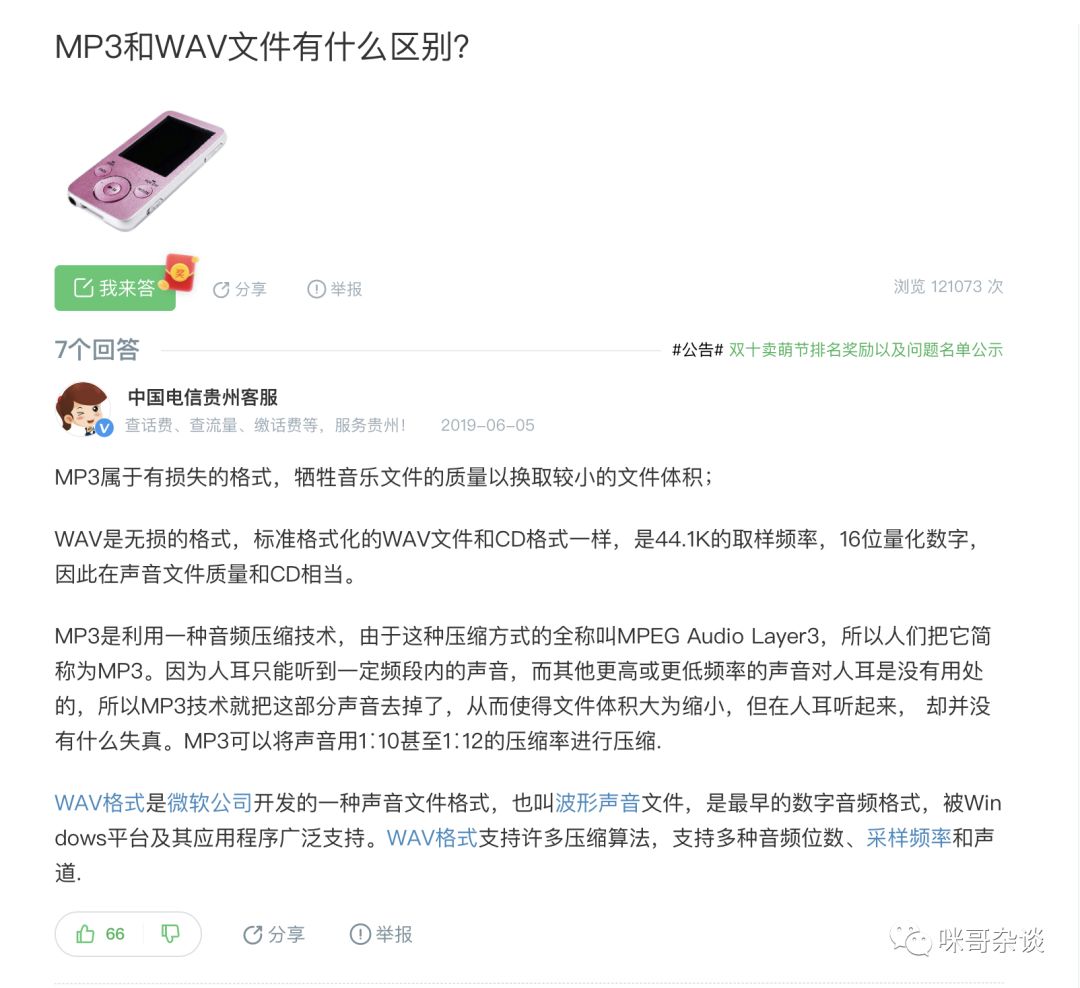
采样频率:就是对声音信息1秒钟采样多少次,以记录成数字信息。如CD音频是44.1KHz采样率,它对声音以每秒44100次的频率来记录信息。原则上采样率越高,声音的质量越好。

每个缓冲区帧数:通俗的举个例子,你手里有 102400 块钱,现在要上交给女朋友。但是,你心想一口气全给她,怕撑爆了她的钱包。于是你定了一个值,每次只给她 1024 元。
这里的 1024 元即每个缓存区的帧数。你想全部上交,需要几次才能完成呢?是不是得重复上交这个动作 100 次!此时,这里的 100 次,便对应了上述代码的循环次数,即公式算出来的有多少个块缓存区。
5
播放功能实现
有了以上知识点,对于读文件来说,就相当 easy 了!直接放上核心代码:
def play_audio(wave_input_path):p = pyaudio.PyAudio() # 实例化wf = wave.open(wave_input_path, 'rb') # 读 wav 文件stream = p.open(format=p.get_format_from_width(wf.getsampwidth()),channels=wf.getnchannels(),rate=wf.getframerate(),output=True)data = wf.readframes(CHUNK) # 读数据while len(data) > 0:stream.write(data)data = wf.readframes(CHUNK)# 关闭资源stream.close()p.terminate()
读文件的话,没有什么可讲的,我是直接从官方文档的例子中 copy 的,修改了一下相应的参数,即可实现。
6
总结
放上一段,我用 Python 录制的 wav 音频文件。短暂的 3 s。
老规矩,有想要本章全部源码的同学,后台回复 音频 ,即可获得地址。
文中关于音频的解释,哪里有错误,欢迎评论区留言指出!

Python减少代码量的两个内置函数 Python打造自己的语音机器人设计思路
 你点的每个在看,我都认真当成了喜欢
你点的每个在看,我都认真当成了喜欢评论