
史上首次,强化学习算法控制核聚变登上Nature:DeepMind让人造太阳向前一大步
过去三年,DeepMind 和瑞士洛桑联邦理工学院 EPFL 一直在进行一个神秘的项目:用强化学习控制核聚变反应堆内过热的等离子体,如今它已宣告成功。
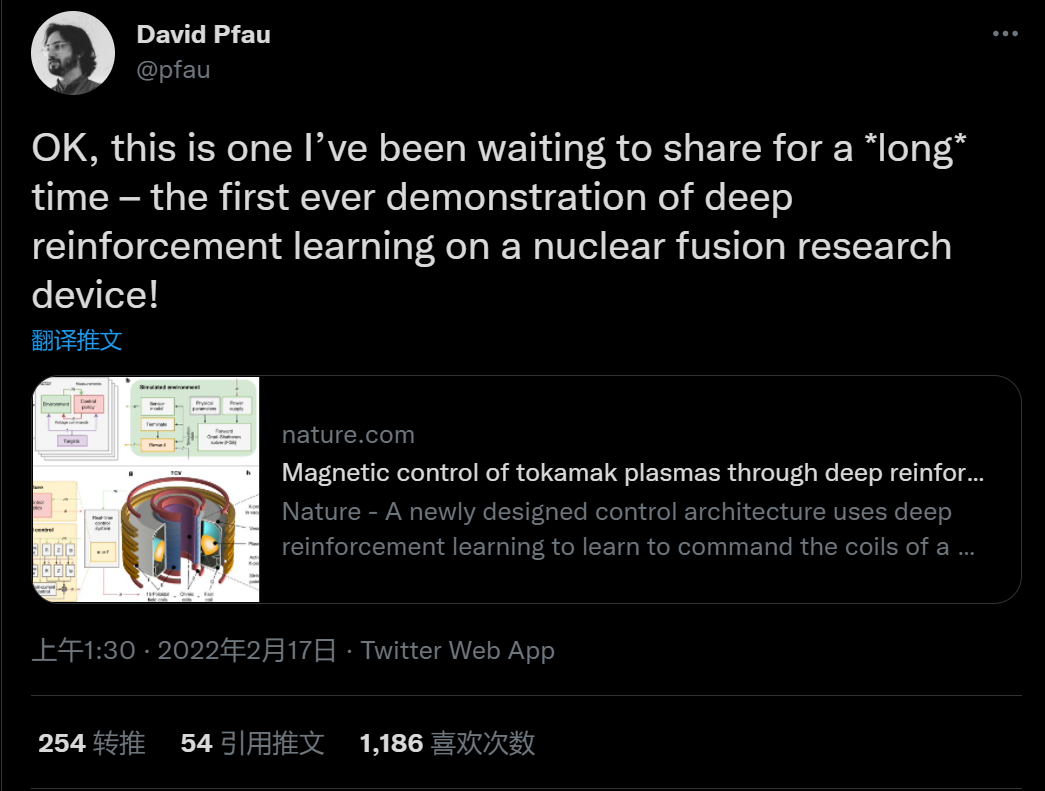



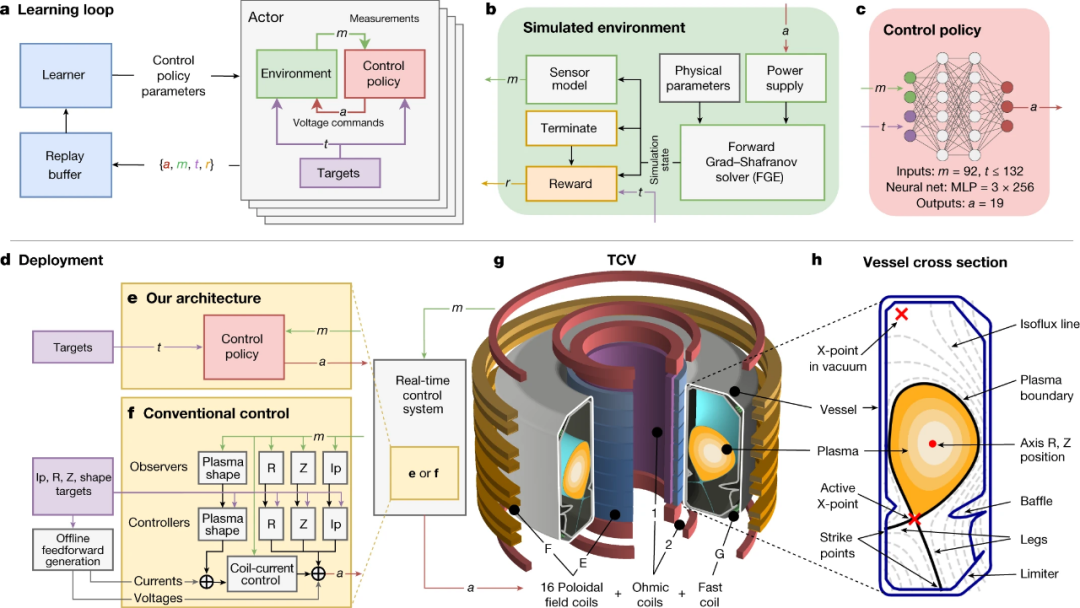
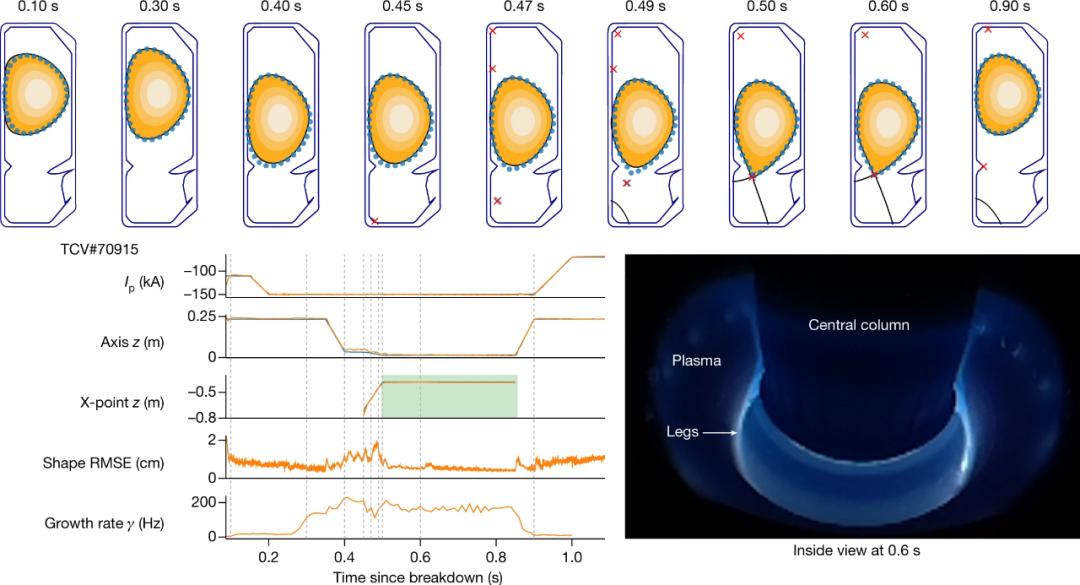
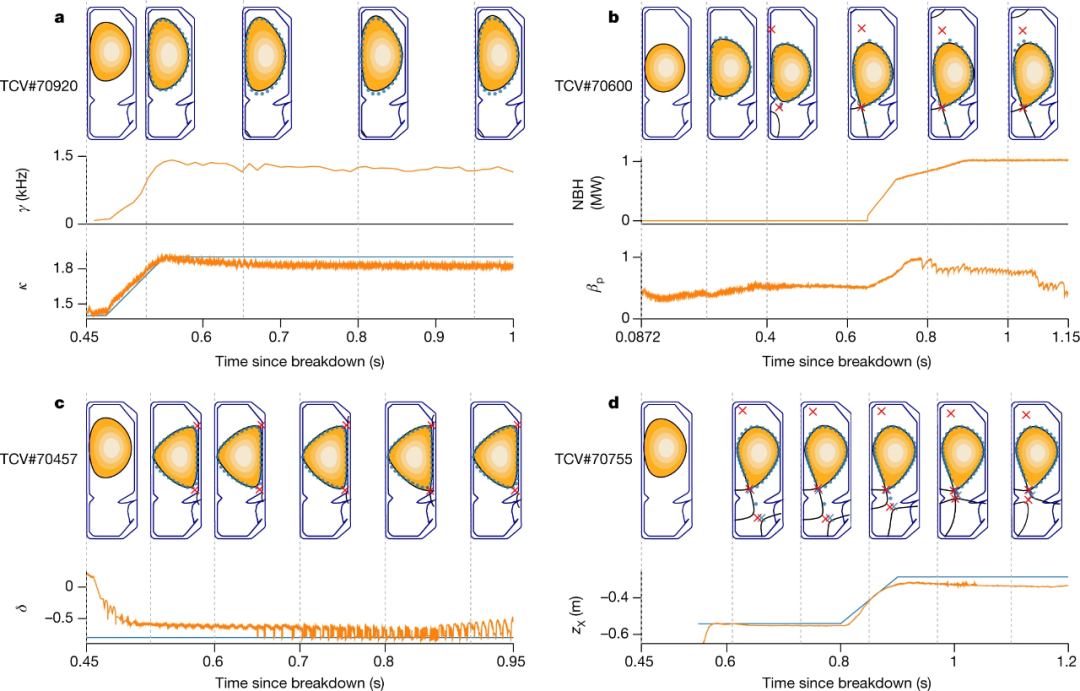
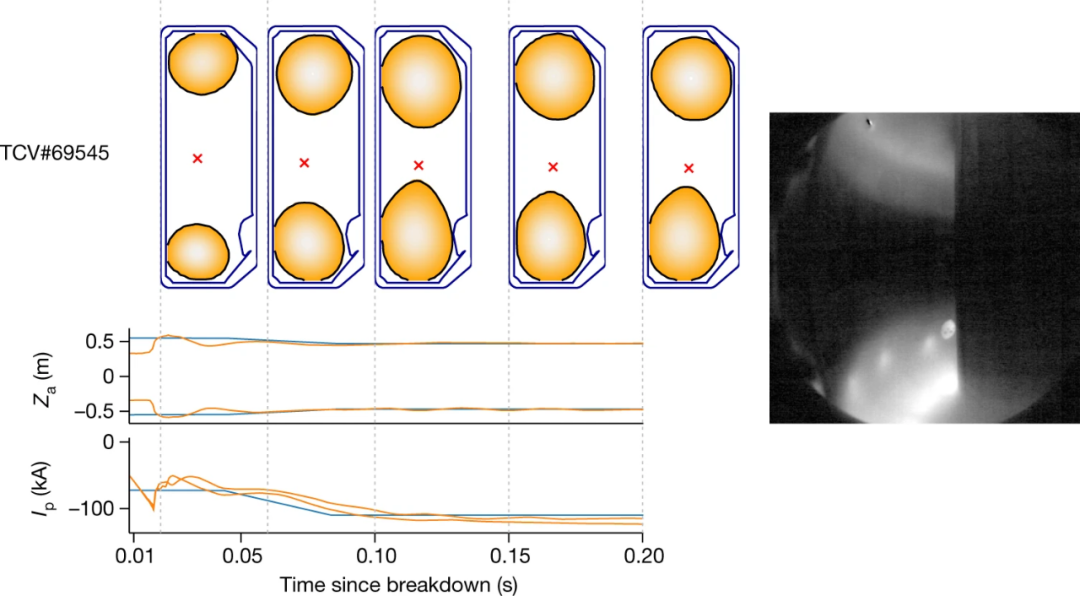
第一阶段:设计者为实验指定目标,可能伴随着随时间变化的控制目标;
第二阶段:深度 RL 算法与托卡马克模拟器交互,以找到接近最优的控制策略来满足指定目标;
第三阶段:以神经网络表示的控制策略直接在托卡马克硬件上实时运行(零样本)。
推荐阅读
写的书太受欢迎怎么办?北大《深度强化学习》作者:那就开放下载吧

评论