
投稿人就是AI顶会最好的「审稿人」!中国学者提出同行评审新机制

极市导读
近年来,机器学习顶会论文数目井喷,审稿压力巨大,其同行评审制度备受质疑。宾大教授针对此挑战提出了由论文作者协助的新型同行评审机制。>>加入极市CV技术交流群,走在计算机视觉的最前沿
你是否已经受够了NeurIPS,ICLR,ICML等会议的审稿意见?
你是否有过最好的论文被拒稿,但是相对差的论文反而被接收的经历?
相信对众多机器学习、人工智能领域的从业者来说,这种现象已经见怪不怪了。

人工智能专家Ian Goodfellow在Twitter上抱怨同行评审(peer review)
机器学习的成功依赖于大型会议,这一领域发展非常迅速。而期刊审稿周期相对较长,因此大部分最新的工作都首先发表在会议上,像NeurIPS,ICLR,ICML等,这对机器学习的发展壮大起了很重要的作用。
一般来说,学术会议会邀请某一领域的专家审稿 - 即通过同行评审制度 - 决定论文是否值得发表。可以说,顶会现在的成功,很大程度上也要归功于同行评审制度。
反之,如果研究工作不经过可靠的同行评审就发表,可能会带来许多问题:大多数人,即非专家,无法分辨研究结果的好坏对错;也会对研究造成混乱,后人可能会引用错误的结果、结论,这无疑也会阻碍机器学习领域研究的进步。
因此,随着研究人员及论文的数量成倍增加,同行评审的可靠性在今天变得更加重要。对这一制度可靠性的分析和相关的改进方法,也渐渐成为一个热门话题,并引起学术界和业界的关注。
如何改进同行评审的机制,提高审稿流程的可靠性呢?
近日,宾夕法尼亚大学沃顿商学院和计算机系的苏炜杰教授在今年NeurIPS上发表的一篇文章为改进同行评审提供了新的思路,提出一个简单实用的方法,结合了统计和优化的思想。
该研究认为,既然增加审稿人数,或给每个审稿人分配更多的论文不现实,那我们可以要求投稿作者提供信息来协助我们决策,「人尽其才,物尽其用」。然而,又要保证投稿人不会为了自身利益提供不实信息。 那么, 应该如何设计这一机制呢?

论文地址:https://arxiv.org/abs/2110.14802
苏炜杰教授针对性地提出了一种新机制:保序机制(Isotonic Mechanism),并从理论上保证了该机制既能激励投稿人提供真实的信息,又能增加审稿结果的可靠性。
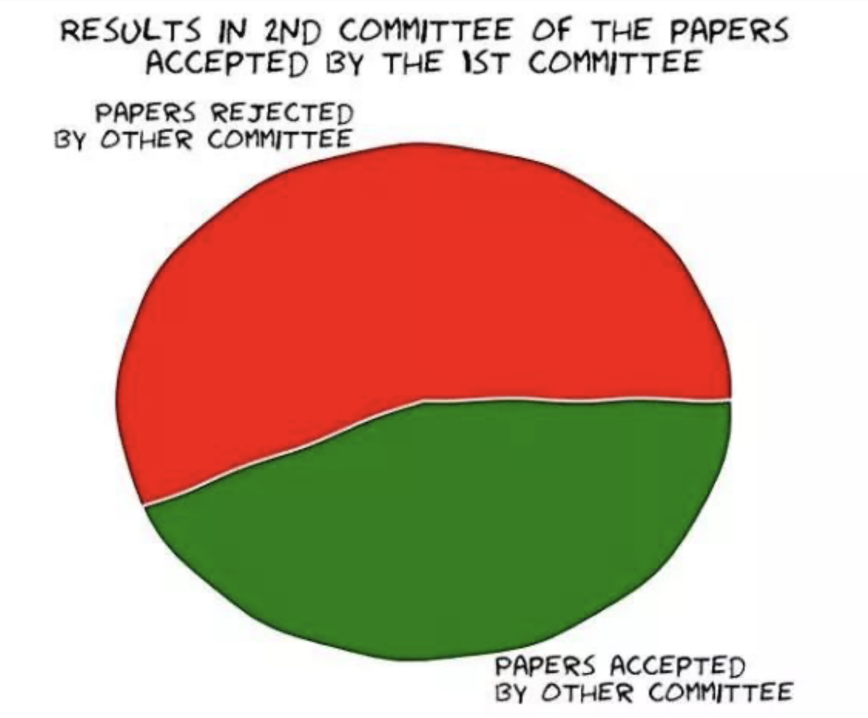
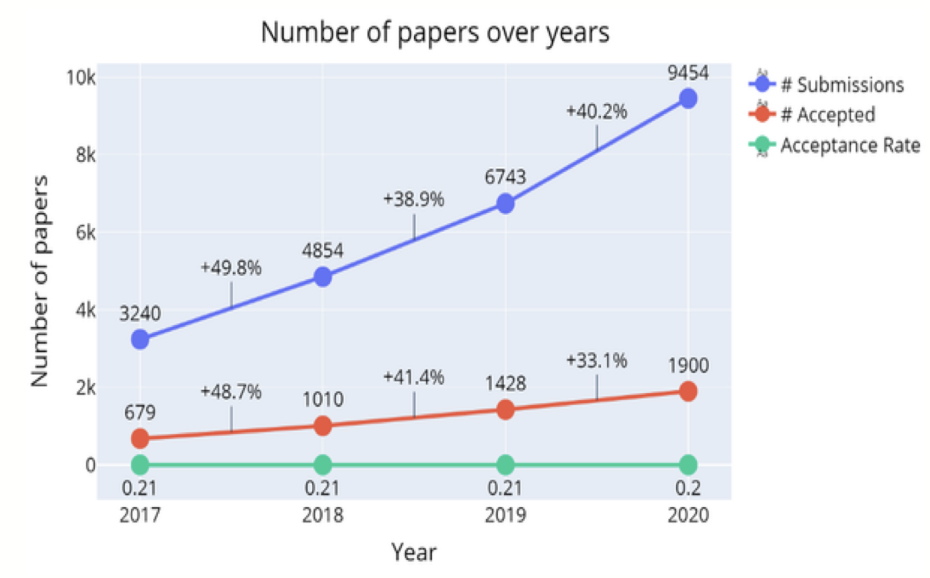
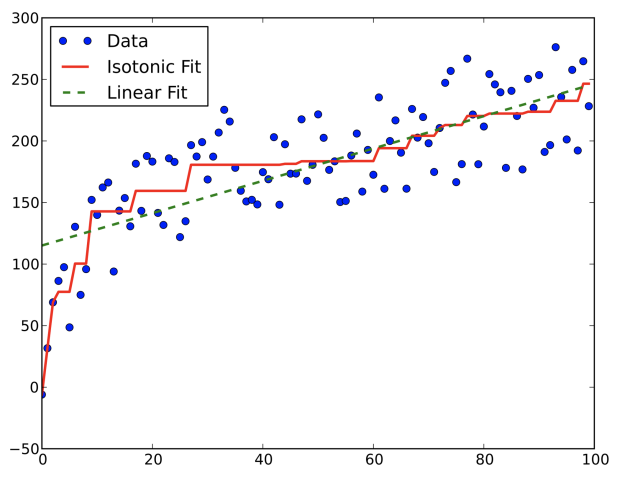
保序机制(Isotonic Mechanism)简介
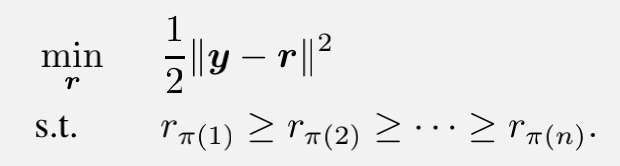
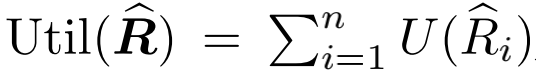
保序机制的理论保证


保序机制的提出背景
文章与NeurIPS 2021会议的巧合
总结与展望
虽然效用函数为凸一定程度上符合研究者的偏好,但是对于一些追求中稿数量的研究者,效用函数可能是一些特殊的非凸函数(例如阶梯状的函数)。如何改进技巧应用到这种问题上?
当前改进同行评审已经有一些初见成效的工作,如何将他们结合进来?
保序机制的准确性是使用L2误差来衡量的。有没有更符合实际情况的误差函数?
如何应对投稿人策略性地利用保序机制,例如故意提交低质量论文变相抬高分数?
在跨学科评审和多个审稿人多个作者的情况下,如何保证噪声的可交换性,如何对应修改保序机制?
保序机制要求提供论文质量的排序是否有附带好处?比如要求作者对自身论文质量有更清楚的认识,或许会减少会议论文常见的「guest authorship」。
作者简介
参考资料:
https://arxiv.org/pdf/2110.14802.pdf
https://www.toutiao.com/i7039916197835506209/?timestamp=1639147753&app=news_article&group_id=7039916197835506209&use_new_style=1&req_id=202112102249130101310380762754C599&wid=1639647590857
https://arxiv.org/pdf/2109.09774.pdf
https://www.reddit.com/r/MachineLearning/comments/r24rp7/d_peer_review_is_still_broken_the_neurips_2021/
https://hub.baai.ac.cn/view/10481
https://zhuanlan.zhihu.com/p/90666675
https://cloud.tencent.com/developer/article/1172713
http://eprints.rclis.org/39332/
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
