
一年六篇顶会的清华大神提出Fastformer:史上最快、效果最好的Transformer
新智元报道
新智元报道
来源:arXiv
编辑:LRS
【新智元导读】Transformer模型好是好,可惜太慢了!最近一位清华大神在arxiv上传了一篇论文,提出新模型Fastformer,线性时间复杂度,训练和推理效率史上最快,还顺手在排行榜刷了个sota。
Transformer 的强大毋庸置疑,想要在CV和NLP的排行榜上取得一席之地,Transformer几乎是必不可少的骨架模型。
但它的效率相比传统的文本理解模型来说却不敢恭维,Transformer的核心是自注意力(self-attention)机制,对于输入长度为N的文本,它的时间复杂度达到二次O(N^2)。
虽然已经有很多方法来处理 Transformer 加速问题,但是对于长序列来说,这些方法要么效率仍然较低或是效果还不够好,例如BigBird使用稀疏注意力却丢失了全局上下文信息。
清华大学提出了一个新模型Fastformer,基于additive attention能够以线性复杂度来建立上下文信息。

论文地址:https://arxiv.org/abs/2108.09084
文章的第一作者武楚涵,是清华大学电子工程系的博士研究生。
目前的研究兴趣包括推荐系统、用户建模和社会媒体挖掘。在人工智能、自然语言处理和数据挖掘领域的会议和期刊上发表过多篇论文。

仅2021年就在顶会上发表了六篇论文,大神的世界只能仰望。

论文的通讯作者是黄永峰,清华大学电子系教授,博士,博导,信息认知和智能系统研究所副所长,首届全国十佳网络安全优秀教师。
主要从事网络及网络安全技术的研究和教学。现为IEEE Senior Member、中国电子学会信息隐藏与多媒体安全专家委员会委员。
已在IEEE Transaction IFS和中国科学等国内外著名期刊和AAAI和ACL等重要国际会议发表论文300多篇;出版专著4部、译著2部,教材2部。申请和授权发明专利10余项。

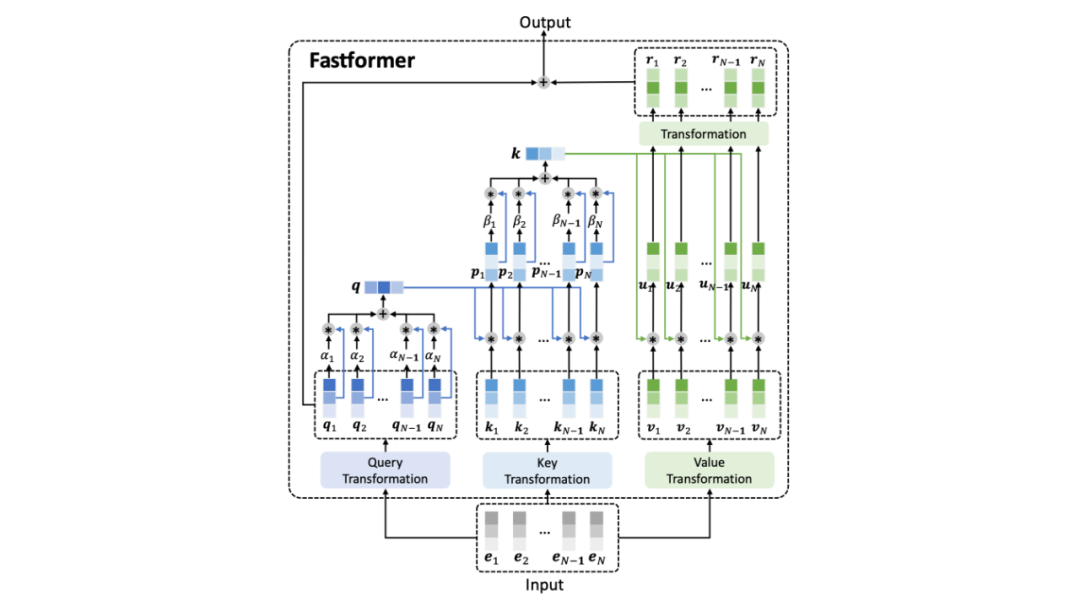
Fastformer首先对输入的attention query矩阵合并为一个全局query向量,然后对attention的key和全局query向量采用element-wise的乘法学习到全局上下文相关key矩阵,再通过additive attention合并为全局key向量。
通过元素乘积对全局key和attention之间的交互进行建模,并使用线性变换学习全局上下文感知的注意力,最后将它们与attention query查询一起添加以形成最终输出。
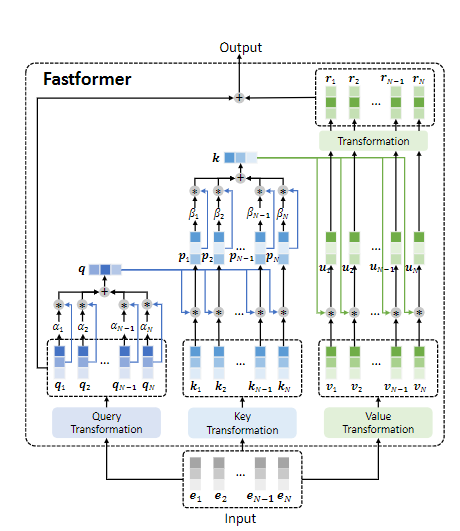
由此,计算复杂度可以降低到线性,并且可以有效地捕获输入序列中的上下文信息。
对于学习全局query和key向量的additive attention网络,其时间和内存开销均为O(N·d),参数总数为2hd(h为注意头数)。此外,元素乘积的时间代价和内存代价也是O(N·d),总复杂度是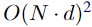 ,比标准的Transformer复杂度
,比标准的Transformer复杂度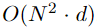 要更有效率。
要更有效率。
如果采用权重共享(weight sharing)方法,每层Fastformer的总参数量为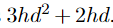 ,也有更少的参数。
,也有更少的参数。
模型验证
论文在五个不同任务的数据集上进行实验来验证Fastformer的效率:
IMDB,电影评论星级预测数据;
MIND,一个大规模的新闻推荐数据集。在这个数据上进行两个任务:新闻主题分类和个性化推荐;
CNN/DailyMail数据集,一个广泛使用的文本摘要数据集;
PubMed数据集,包含更长文本的文本摘要数据集;
Amazon 电子产品领域评论星级预测数据。

实验过程中使用Glove词向量初始化,在32GB的V100 GPU上进行5次实验取性能的平均值。
对比模型包括:
标准的Transformer;
Longformer,基于稀疏注意力的Transformer,结合了滑动窗口注意力和全局注意力来建模局部和全局上下文;
BigBird,Longformer的扩展,包括稀疏随机注意力机制;
Linformer,一个线性复杂度的Transformer,使用低维key和value矩阵来计算近似self-attention;
Linear Transformer,也是线性复杂度的Transformer,使用核函数来估计self-attention机制;
Poolingformer,一种层次结构,首先使用滑动窗口自注意力来捕捉短距离的内容,然后使用pooling self-attention来捕捉长距离的上下文。
在分类任务上,可以看到FastFormer要比标准的Transformer要更好。
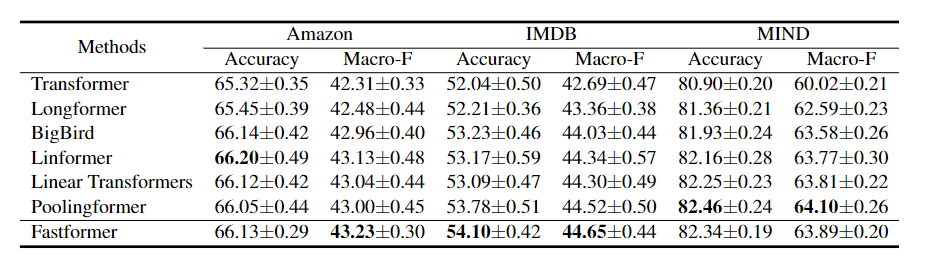
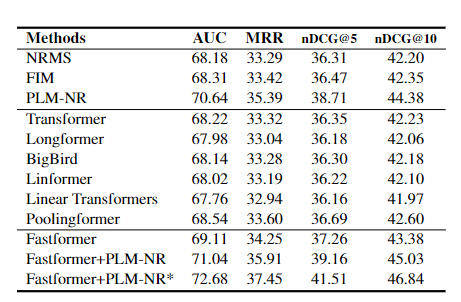
比较不同方法在新闻推荐任务中的性能时,又增加了三个模型:
NRMS,它使用多头自注意力网络学习新闻和用户表征;
FIM,一种用于个性化新闻推荐的细粒度兴趣匹配方法;
PLM-NR,使用预训练的语言模型为新闻推荐提供基础。
在不同的Transformer结构中,Fastformer达到了最好的性能,并且它也优于基本NRMS模型。此外,Fastformer可以进一步提高PLM-NR的性能,并且集成模型在MIND排行榜上获得最佳结果。
结果分析
结果表明,Fastformer不仅在文本建模方面是有效的,而且在理解用户兴趣方面也是有效的。
既然提到快,在效率的对比上也要进行实验。将输入序列的长度从128调整为65535,并将batch size的大小与序列长度成反比。使用随机生成token作为伪样本,并固定token embedding以更好地测量不同方法的计算成本。
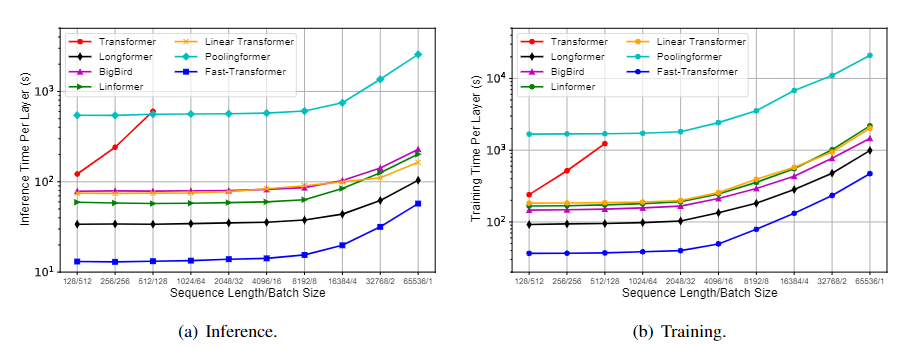
当序列长度相对较长时(例如512),Transformer效率较低。此外还发现,虽然Poolingformer在理论上具有线性复杂性,但在实践中效率低下。这是因为它使用的窗口大小(例如256)以类似卷积的方式计算池权重,这导致计算成本的非常大的常数项。
在训练和推理时间方面,Fastformer比其他线性复杂度Transformer更有效,这些结果验证了Fastformer的有效性。
不同的参数共享技术对Fastformer的技术也有影响,通过共享query和value转换矩阵,在不同的注意头之间共享参数,可以发现,与没有任何参数共享技术的Fastformer模型相比,使用query-value参数共享可以获得类似或略好的性能。因此可以通过共享query和value转换矩阵来减少参数大小。
此外,头部参数共享将导致显著的性能下降。这是因为不同的注意头需要捕捉不同的上下文模式,而共享它们的参数对上下文建模是不利的,采用分层共享方法可以进一步提高模型的性能,因为不同层之间的参数共享可以缓解过拟合的风险。
参考资料:
https://arxiv.org/abs/2108.09084
