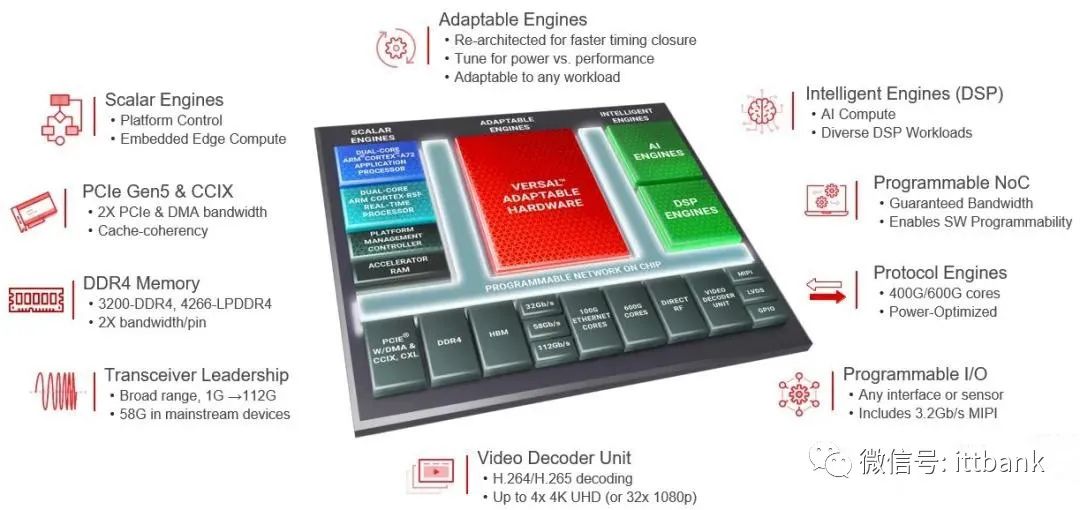
AMD将用FPGA干什么?新机器视觉关注共 5491字,需浏览 11分钟 ·2022-02-20 23:27 点击下方卡片,关注“新机器视觉”公众号视觉/图像重磅干货,第一时间送达近日,AMD 已经完成了对 Xilinx 的收购,由于过去一年半时间里 AMD 的股价上涨,最终成本接近 490 亿美元,而不是最初在 2020 年 10 月宣布该交易时预计的 350 亿美元。现在,随着 AMD 获得监管机构的批准并花光了所有“钱”——稀释后的市值与实际现金不同,但你可以用它买东西——很自然,收购完成后, CPU 和GPU 设计人员不仅可以使用作为 Xilinx 器件核心的 FPGA 可编程逻辑,还可以使用在所有 FPGA 混合中变得普遍的晶体管硬块,例如 DSP 引擎、AI 加速器、内存控制器、I /O 控制器和其他类型的互连 SerDes。AMD 需要很长时间才能建立一支工程师团队,这些工程师团队拥有赛灵思在可编程逻辑方面以及在其航空航天、国防、电信/通信、工业和广播/媒体业务领域所获得的专业知识,并且结合了凭借 Vitis 软件堆栈,Xilinx 的价值超过了收购一家在其他领域拥有收入和利润流且与 AMD 核心业务几乎没有重叠的公司的价值,这立即转化为 AMD 首席执行官Lisa Su所看中的, 更为广泛的,估值为 1350 亿美元的潜在市场。不断增加的 TAM 对于 AMD(实际上是任何半导体公司)实现增长至关重要,并将Xilinx 的收入和利润流(在过去 12 个月中分别为 36.8 亿美元和 9.29 亿美元)添加到AMD 的收入和利润流中,2021 年分别为 163.4 亿美元和 31.6 亿美元。但真正的价值,以及为什么 Lisa Su 和公司花了这么多钱来收购 Xilinx。皆因它需要做很多事情来最大限度地提高投资并推动其收入远高于仅仅通过合而取得的收入。AMD 以及数据中心的任何主要芯片公司都不清楚他们从第三方获得了多少 IP 块的许可。在我看来,这可能比我们许多人意识到的成本更高,并且假设赛灵思实际上创建了自己的内存控制器、I/O 控制器、网络控制器和更通用的 SerDes 以及片上互连,那么 AMD 可能随着时间的推移转移到赛灵思 IP 块,能够节省一些钱。如果赛灵思 IP 块比 AMD 替代品更好或完全从 AMD 堆栈中消失,那么这里有各种可能性来改进 AMD 在 CPU 和 GPU 插槽中的内容以及它如何从中创建自己的新 IP。例如,想象一下,基于 Xilinx SerDes 的数据中心规模 Infinity Fabric 交换结构以及由 AMD 和 Xilinx 融合团队共同创建的数据包处理引擎?想象一下类似于IBM 为其 Power10 处理器创建的内存区域网络,但跨机架和机架以及 Epyc CPU 和 Instinct CPU 加速器的行和行运行。. . . 想象一下,根本不关心以太网或 InfiniBand,除了作为集群的入口点。. . . 这会有多酷?看看 Versal 系列的“Everest”一代中的 Xilinx FPGA 混合器件:那些用于机器学习推理处理的 AI 矩阵引擎和用于各种信号处理的 DSP 引擎是过去在可编程逻辑中实现的硬块——赛灵思在其 Versal 系列中一直将其称为自适应引擎——但由于空间、热量和性能问题,将这些块实现为 ASIC 并使用芯片上的高速互连将所有这些块相互连接并连接到可编程逻辑要高效得多。AMD 的工程师在考虑如何构建计算引擎、系统和集群时,可以使用这些硬块中的每一个,包括 Arm 内核。AMD 设计的每个计算设备,无论是单片芯片还是封装中的小芯片集合,都可以在 AMD 认为合适的时候添加一些可编程逻辑。那么除了在很大程度上保持业务不变之外,AMD 将如何与 Xilinx 合作呢?它还没有说,除了说 AMD 在交易失败之前已经授权了一些 Xilinx IP,并且无论该 IP 是什么——不要假设它是可编程逻辑——都将在明年年底的某个时候出现在 AMD 芯片中。让我们看看他们合并后的一些潜在可能性,如果您有自己的想法,请提出来。首先,我们认为整个 CPU 和整个 FPGA 的单芯片混合实现是不太可能的,但有可能会发生共同封装的 CPU-FPGA 混合。这是英特尔早在 2014 年就与 FPGA 制造商 Altera 合作的东西,这甚至发生在它收购该公司之前——在 2018 年,宣布将“Skylake”至强 SP 处理器与 Arria 10 FPGA 混合在一个封装中的产品。我们认为这些产品不会在数据中心起飞,原因与为什么我们在数据中心的单个封装中看不到 CPU-GPU 混合体的原因相同,除非是非常特殊的情况,例如带有集成显卡的 PC 芯片被重新用作媒体处理服务器引擎,就像 AMD 和英特尔过去在其嵌入式产品线中所做的那样。在其 frankensocket CPU-GPU 复合体中,英特尔将 125 瓦的成熟 20 核 Xeon SP-6138P 与额定 70 瓦的成熟Arria 10 GX FPGA 1150放在同一封装中。它们通过 UltraPath 互连 (UPI) 链接进行连接,这些链接用于与 CPU 进行共享内存 NUMA 配置,这意味着英特尔将 UPI 控制器移植到 Arria 10 上。(这个 UPI 控制器似乎不太可能在可编程控制器中实现逻辑,但 UPI 协议可能是在硬编码 SerDes 之上实现的,该 SerDes 适合 UPI 的时序,可编程逻辑填补了空白。)Arria 10 GX 没有在 FPGA 复合体上激活 Arm 内核(他们可能一直在那里,英特尔从未明确表示过)。这个 frankensocket 的 FPGA 部分的目标应用程序是在可编程逻辑上运行 Open vSwitch 虚拟切换,使其运行速度提高 3 倍以上,并允许 Xeon CPU 托管 2 倍的虚拟机,因为 Open vSwitch没有在至强核心的软件上运行。我们估计组合设备的成本为 6,500 美元,当时 Xeon 部分的成本约为 2,600 美元。据我们所知,这个想法并没有席卷市场,后续也转向卸载虚拟存储、虚拟网络和交换以及加密/解密到 DPU(一种美化的 SmartNIC,取决于你想要什么定义使用)。AMD 十多年来一直在考虑这种混合 CPU-GPU 计算方法及其异构系统架构,甚至在一些服务器部件中实现了它们,并且显然已经为 PC 和大批量定制游戏机芯片做到了这一点。在一定程度上,Infinity Fabric 互连是 HSA 的一种实现。AMD 可以将整个 CPU 和整个 FPGA 集成在一起——由用于 CPU 计算的 frankensocket、用于 FPGA 可编程逻辑的小芯片以及它们两者的共享内存和 I/O 集线器组成——这很有趣,因为它可以提供连贯的共享插槽内跨 CPU 和 FPGA 容量的内存。使用 Infinity Fabric 链接,它也可以跨socket完成。正如我们所建议的,使用 Infinity Fabric 交换,它可以跨机架甚至跨行完成。这是一个强大的想法。其中任何一个问题都是锁定任何socket中的配置。CPU 与 FPGA 可编程逻辑的比例会因应用、行业和客户用例而异。而且,如果您将 GPU 加入其中,您就会有许多不同的变量可供选择,实际上,每个芯片都会及时成为特定客户的定制部件。你可以为超大规模和云建设者这样做,因为数量值得,但如果 AMD 想把它卖给其他服务提供商和大型企业,它必须选择一些 SKU,而且它所做的任何事情都可能不是最理想的。Nvidia 并没有用到任何 FPGA ,除了可能用于模拟自己的芯片(如果它在其“Selene”超级计算机上进行所有模拟和验证,可能甚至没有),该公司的联合创始人兼首席执行官 Jensen Huang对此并不伪言。 但英特尔收购了 Altera 而现在 AMD 又收购了 Xilinx 的事实至少表明,FPGA 在现成 CPU 上运行的编程语言和用于实现某些功能或软件堆栈的定制 ASIC 之间的边界仍然具有吸引力。我们一直认为,一个平衡的系统将包括所有三个计算引擎,例如现代交换机。您需要用于快速串行处理和大内存占用的 CPU,用于快速并行处理和高内存带宽的 GPU,以及用于加速硬编码算法的 FPGA,这些算法在 X86 或 Arm 处理器上的软件实现中可用,但在由于这些算法变化太大,或者因为您无法支付热量或成本溢价,因此无法保证定制 ASIC 的数量。我们认为将 FPGA 可编程逻辑嵌入到每个 CPU 插槽甚至每个 GPU 插槽中作为这些设备的一种暂存器,这样它们就可以拥有散列算法、加密算法、安全协议或虚拟开关的元素,这在 FPGA 中绝对是一件有趣的事情(或部分完成),而不是在 CPU 或 GPU 芯片上的逻辑块中,在添加到 CPU 或 GPU 插槽的单独小芯片中,或在 CPU 上运行的更高级别的软件中。多年来,IBM 已经在其 System z 和 Power 处理器中添加了此类暂存器(请注意,不是用 FPGA 逻辑实现的),允许它们实现新指令或创建复合指令,这些指令在芯片流片了。这不会是芯片/插座空间的很大一部分。我们绝对认为很快就会有 Versal FPGA 混合使用 Xen X86 内核交付,我们认为 Vitis 堆栈将进行调整,以便能够将代码编译到这些内核以及 Versal 计算的其他元素复杂的。我们认为 AMD 不太可能将 X86 或 Arm 内核引入其 GPU,但我们确实认为该公司可以创建一系列混合了 FPGA 和 X86 内核的 SmartNIC 和 DPU——如果它的话,甚至可能是婴儿 GPU具有架构意义。AMD 是 SmartNIC 的新手,但 Xilinx 不是,尤其是在 2019 年 4 月收购 Solarflare 之后。这让我们在这个探索中有了更多的想法,这是我们自混合旅程开始以来一直鼓励计算引擎制造商做的事情。似乎很清楚的是,我们将在插槽内或跨插槽拥有小芯片组件,并在它们之间进行某种互连。对于 AMD 和 Xilinx,它将是 Infinity Fabric,并且可能在其之上支持 CCIX 或 CXL 协议,如果 Infinity Fabric 确实是 PCI-Express 的超集,其中融入了 AMD HyperTransport 功能,这应该是可能的。想要将许多东西打包到混合计算引擎中并制作一个大socket有很好的延迟原因。但也许在后摩尔定律时代,要有最好的答案。所以,我们希望看到 AMD 这样做。创建一个高性能的 Zen4 内核,去掉所有矢量引擎,并在芯片上放置更多内核或在芯片上放置更多更快的内核。我们选择后者是因为在这个 CPU 上,我们想要惊人的串行性能。我们想要这个东西上的 HBM3 内存,我们想要至少 256 GB 的容量,这应该是可能的。大量的 Infinity Fabric 链接从单个插槽中脱落。最高500瓦,我们不在乎。现在,在系统板左侧的旁边,我们想要一个杀手级“Aldebaran” Instinct GPU,而 MI200 的一半可能就足够了——Instinct MI200 在一个封装中具有两个逻辑 GPU– 或者可能需要配备四台毕宿五发动机的完整 MI300。这将取决于客户。在 GPU 周围也放置大量 HBM3 内存。在 CPU 的右侧,我们想要一个 Versal FPGA 混合,其中包含更多的 Infinity Fabric 链接,去掉了 Arm 内核,保留了 DSP 引擎和 AI 引擎,以及所有硬块互连的东西。这是一个集成的可编程逻辑引擎,在需要时可以像 DPU 一样工作。Infinity Fabric 通道可以从这里断开以创建集群,或者直接断开 GPU 和 CPU,但我们喜欢在 DPU 上实现 Infinity Fabric 交换机的想法。现在,利用这些计算引擎模块,允许客户在系统板上、机架内和跨行配置他们需要的比率。也许有一个客户需要为每个 CPU 配备四个 GPU,为每个具有单个 Infinity Fabric 交换机的复杂系统配备两个 DPU。在另一种情况下,可能由于延迟原因,GPU 更靠近 DPU(想想现代超级计算机),而 CPU 挂在 GPU 的一侧。或者 CPU 和 GPU 都从 DPU 集线器发出。或者 CPU 处于环形拓扑结构中,而 GPU 处于机架内的胖树中。将其全部设为 Infinity Fabric,并使拓扑在 Infinity Fabric 交换机上可更改。(不同的工作负载需要不同的拓扑结构。)每个组件都经过高度调整、精简,完全没有冗余,硬件与软件绝对协同设计。在AMD未来的系统中,除了集群中的头节点以外,没有 InfiniBand 或以太网,它们只是 Epyc CPU-only 服务器。如果我们是 AMD,我们会这样做。来源:半导体行业观察,编译自nextplatform本文仅做学术分享,如有侵权,请联系删文。—THE END— 浏览 46点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 FPGA云服务器云计算服务平台什么是FPGA?嵌入式Linux0FPGA云服务器配备现场可编程门阵列(Field Programmable Gate Array)的高性能云计算服务。同时具备开发、模拟、调试和编译硬件代码所需的各种资源,您可以基于FPGA云服务器为您的应用程序创建自定义的硬件加速能力。固件工程师到底是干什么?嵌入式Linux0博士生们都在干什么?小白学视觉0固件工程师到底是干什么?李肖遥0英特尔FPGA人才“遭抢”雷锋网0GPU、FPGA和ASIC架构师技术联盟0GPU、FPGA和ASIC智能计算芯世界0去音乐节的人都在干什么?互联网那些事0点赞 评论 收藏 分享 手机扫一扫分享分享 举报
 下载APP
下载APP