
EasyExcel 带格式多线程导出百万数据(实测好用)
大家好,我是宝哥!
前言
以下为结合实际情况作的方案设计,导出阈值以及单sheet页条数都可以根据实际情况调整
大佬可直接跳过新手教程,直接查看文末代码
1. 背景说明
针对明细报表,用户会选择针对当前明细数据进行导出,便于本地或者线下进行处理或者计算等需求。不过一般在这种大数据量的导出任务下,会引发以下问题:
响应时间较慢; 内存资源占用过大,基本上一个大数据量的导出会消耗可视化服务的所有资源,引起内存回收,其它接口无响应;
考虑到单个excel文件过大,采用压缩文件流zip的方式,一个excel只有一个页签,一个页签最多十万条数据,所以少于十万条数据,会导出excel文件,而非zip压缩文件。
另外,这里导出功能的速率不能单以数据条数为量级进行衡量,平常一般一万条数据就是1M字节。较为准确的公式如下(借此就可以评估出很多数据导出的文件大小):
文件大小1M字节 = 字段列数15个 * 数据条数一万条
2. 方案概述
(1)大数据量导出问题主要是以下三个地方:
资源占用 内存(也是资源的一个,单独说明) 响应时间
针对以上三个问题,大方向考虑的是多线程结合数据流写入的方式。多线程:使用空间换时间,主要是加快接口响应时间,但是这里线程数不宜过多,一味加快响应时间提升线程数,资源占用会非常严重,故会考虑线程池,线程池的线程数为10;数据流:数据的IO-读取/写入等操作一般都是通过“数据包”的方式,即将结果数据作为一个整体,这样如果数据量多的话,会非常占用内存,所以采用数据流的方式,而且导出的时候会进行格式设置(单元格合并、背景色、字体样式等),一直使用的是Alibaba EasyExcel组件,并且Alibaba EasyExcel组件支持数据流的方式读取/写入数据。
(2)将写入导出Excel等功能单独分开成一个微服务:
注意:如果单个服务分配的资源足够的话,可以不用将导出功能与原应用服务拆开,这里可以省略
抢占资源 由于导出功能内存溢出,如果不做分离独立,整个应用服务也会宕机
(3)注意:
多线程下,同一页签的写入不可同步,即Alibaba EasyExcel组件的文件写入流SheetWriter是异步的; 多线程下,每个线程所用的文件写入SheetWriter是一个复制,依旧会占用大量内存; 微服务拆分时,数据读取和文件写入是在一个线程下的,所以新的微服务也要实现一套数据读取逻辑; 压缩文件使用压缩文件流,ZipOutputStream,不需要暂存本地;
(4)方案设计:
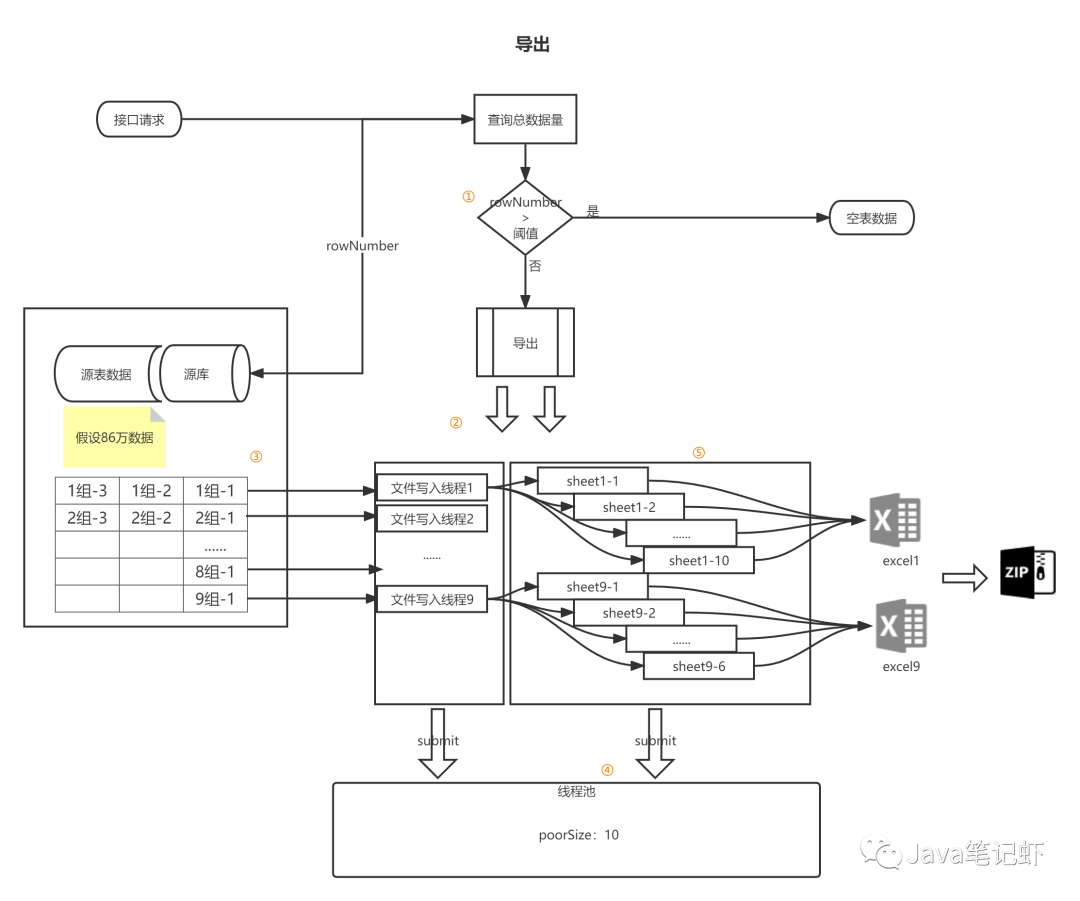
标注说明
1) 阈值可以进行设置,考虑到业务场景以及资源使用,这里阈值数据量为100w条,超过一百万会导出空表(而非导出一百万数据)
2) 导出进行多线程,启用最多十个多线程(默认最多一百万条数据,一个sheet页十万条数据),每个线程会进行两个动作,查询数据以及数据写入操作,(如果数据量较少,依旧是适用的)
3) 说明图,以86万数据为例,也就是说会启用九个文件写入线程,一个文件写入线程生成一个excel导出文件;
4) 线程池为队列线程,即后来的线程进入排队等待,队列长度(线程池大小)为10;
5) 每个文件写入线程会生成最多十个sheet(默认一个sheet页十万数据)写入线程(最后一个文件写入线程可能会少于十个)。
(5)maven依赖:
<!-- easyexcel -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>2.1.7</version>
</dependency>
3. 详细设计
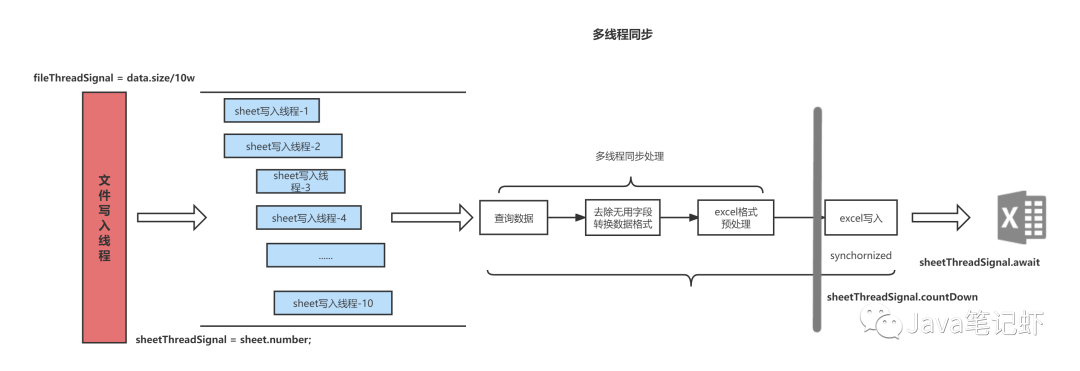
(1)文件写入多线程,按每个文件十万条数据进行导出,每个文件写入线程生成一个excel文件(单页签);
ROW_SIZE:一次查询的数据量,此处设置为10000条ROW_PAGE:一个页签多少次查询,此处设置为10次;
private static Interger ROW_SIZE = 10000;
private static interger ROW_PAGE = 10;
/**
* divide into sheets with 10W data per sheet
* */
int sheetCount = (rowCount/ (ROW_SIZE*ROW_PAGE))+1;
for(int i=0;i<sheetCount;i++){
threadExecutor.submit(()->{sheetWrite()});
}
(2)sheet写入多线程,最后一个文件写入线程的最后一个sheet写入线程可能不足1W条数据;
// 单sheet页写入数
int sheetThreadCount = rowCount - (i+1)*(ROW_SIZE*ROW_PAGE) > 0 ? ROW_PAGE : (rowCount - i*(ROW_SIZE*ROW_PAGE))/ROW_SIZE+1;
CountDownLatch threadSignal = new CountDownLatch(sheetThreadCount);
for(int j=0;j<sheetThreadCount;j++) {
threadExecutor.submit(()->{excelWriter()});
}
threadSignal.await();
(3)异步写入sheet文件,不同的文件写入线程写入不同的文件,所以只需要保证同一个文件写入线程下不同sheet写入线程的excelWriter异步即可;
// 获取数据
// todo
// 数据格式处理
Synchronized(excelWriter){
WriteSheet writeSheet = EasyExcel.writerSheet(sheetNo, "第" + (sheetNo+1) + "页数据");
excelWriter.write(lists, writeSheet);
}
(4)压缩文件,将多个excel压缩成一个zip,最后上传至fast dfs,返回前端下载地址,使用hutool封装的ZipUtil方法;
package cn.hutool.core.util;
String[] paths = new String[10];
FileInputStream[] ins = new FileInputStream[10];
ZipUtil.zip(OutputStream out, String[] paths, InputStream[] ins);
byte[] bytes = outputStream.toByteArray();
// 上传文件到FastDFS 返回上传路径
String path = fastWrapper.uploadFile(bytes, bytes.length, "zip");
return path + "?filename=" + fileName;
4. 缓存
每次请求是生成一个文件并上传至FastDFS服务器上,然后将下载路径返回给前端,有时多个用户频繁下载同一个文件(或者用户短时间内点击同一个下载任务)。针对以上情况,考虑采用缓存,将第一次的数据缓存下来。
① 请求参数较多,需要根据参数判断是否为同一个下载文件请求;
数据集ID 过滤器 数据量 数据集字段(先根据ID排序,再进行拼接)
② 设置过期时间(30分钟),不考虑数据一致性的问题(即数据源数据更改后,再更新缓存)。仅仅是做初步工作,即短时间内,只要符合条件①且时间未过期,就采用同一份数据;
③ 当请求下载的为同一份文件时,只是文件名不同时,依旧采用同一份缓存数据;
注:针对于数据一致性的问题,不对单个数据的内容变更进行考虑,原因是大数据量下,数据是否有变更的判断较为复杂,不现实。这里只判断在相同的请求条件下的总条数。
5. 可行性验证
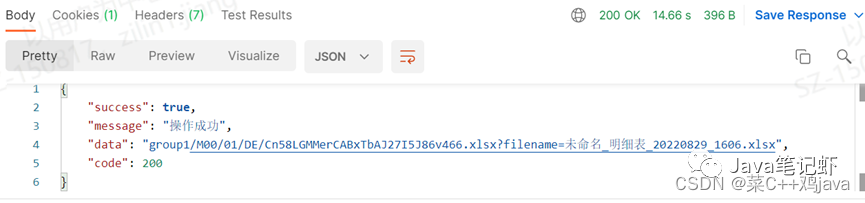
(1)单个文件写入下,176个字段,14140条数据,excel大小15M,响应时间为14.66s(未报错,未触发异常)
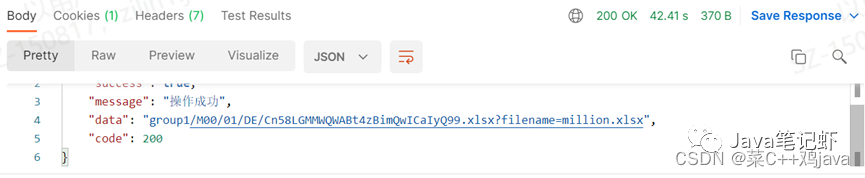
(2)单个文件写入下,14个字段,98万数据,excel大小为96M,响应时间为42.41s(未报错,未触发异常)
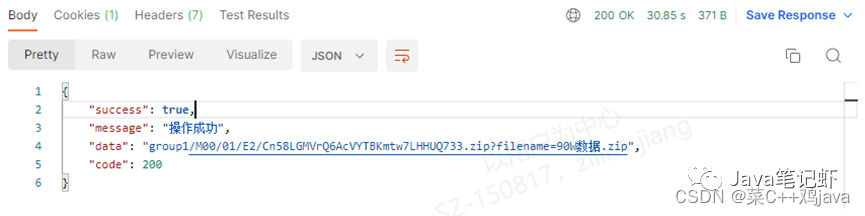
(3)拆分微服务下,14个字段,98万数据,zip大小为104M,平均响应时间为27.34s(未报错,未触发异常)
6. 代码
文件导出核心代码
TableExport.java
public String exportTable(ExportTable exportTable) throws Exception {
StringBuffer path = new StringBuffer();
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
StringBuffer sign = new StringBuffer ();
//redis key
sign.append(exportTable.getId());
try {
// 用来记录需要为 行 列设置样式
Map<String, Map<Integer, List<Map<Integer, ExportTable.ExportColumn.Font>>>> map = new HashMap<>();
sign.append("#").append(String.join(",", fields.stream().map(e-> e.isShow()?"true":"false").collect(Collectors.toList())));
setFontStyle(0, 0, exportTable.getFields(), map);
// 获取表头长度
int headRow = head.stream().max(Comparator.comparingInt(List::size)).get().size();
// 数据量超过十万 则不带样式
// 只处理表头:表头合并 表头隐藏 表头冻结
if(rowCount*fields.size() > ROW_SIZE*6.4){
map.put("cellStyle", null);
}
sign.append("#").append(exportTable.getStyle());
// 数据量超过百万或者数据为空,只返回有表头得单元格
if(rowCount==0 || rowCount*fields.size() >= ROW_SIZE*1500){
EasyExcel.write(outputStream)
// 这里放入动态头
.head(head).sheet("数据")
// 传入表头样式
.registerWriteHandler(EasyExcelUtils.getStyleStrategy())
// 当然这里数据也可以用 List<List<String>> 去传入
.doWrite(new LinkedList<>());
byte[] bytes = outputStream.toByteArray();
// 上传文件到FastDFS 返回上传路径
return fastWrapper.uploadFile(bytes, bytes.length, "xlsx") + "?filename=" + fileName + ".xlsx";
}
sign.append("#").append(rowCount);
String fieldSign = fields.stream().sorted(Comparator.comparing(ExportTable.ExportColumn::getId))
.map(e->e.getId()).collect(Collectors.joining(","));
sign.append("#").append(fieldSign);
/**
* 相同的下载文件请求 直接返回
* the redis combines with datasetId - filter - size of data - fields
*/
if (redisClientImpl.hasKey(sign.toString())){
return redisClientImpl.get(sign.toString()).toString();
}
/**
* 分sheet页
* divide into sheets with 10M data per sheet
*/
int sheetCount = (rowCount/ (ROW_SIZE*ROW_PAGE))+1;
String[] paths = new String[sheetCount];
ByteArrayInputStream[] ins = new ByteArrayInputStream[sheetCount];
CountDownLatch threadSignal = new CountDownLatch(sheetCount);
for(int i=0;i<sheetCount;i++) {
int finalI = i;
String finalTable = table;
Datasource finalDs = ds;
String finalOrder = order;
int finalRowCount = rowCount;
threadExecutor.submit(()->{
// excel文件流
ByteArrayOutputStream singleOutputStream = new ByteArrayOutputStream();
ExcelWriter excelWriter = EasyExcel.write(singleOutputStream).build();
// 单sheet页写入数
int sheetThreadCount = finalI == (sheetCount-1) ? (finalRowCount - finalI *(ROW_SIZE*ROW_PAGE))/ROW_SIZE+1 : ROW_PAGE;
CountDownLatch sheetThreadSignal = new CountDownLatch(sheetThreadCount);
for(int j=0;j<sheetThreadCount;j++) {
int page = finalI *ROW_PAGE + j + 1;
// 最后一页数据
int pageSize = j==(sheetThreadCount-1)&& finalI ==(sheetCount-1) ? finalRowCount %ROW_SIZE : ROW_SIZE;
threadExecutor.submit(()->{
try {
writeExcel(dataSetTableRequest, datasetTable, finalTable, qp,
datasetTableFields, exportTable, page, pageSize, finalDs, datasourceProvider,
fieldArray, fields, head, map, headRow, excelWriter, mergeIndex, finalOrder);
sheetThreadSignal.countDown();
} catch (Exception e) {
e.printStackTrace();
}
});
}
try {
sheetThreadSignal.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 关闭写入流
excelWriter.finish();
paths[finalI] = (finalI +1) + "-" + fileName + ".xlsx";
// 单文件
if (sheetCount == 1){
// xlsx
// 将sign存入redis并设置过期时间
}
threadSignal.countDown();
});
}
threadSignal.await();
if (sheetCount != 1){
ZipUtil.zip(outputStream, paths, ins);
byte[] bytes = outputStream.toByteArray();
// 上传文件到FastDFS 返回上传路径
path.append(fastWrapper.uploadFile(bytes, bytes.length, "zip"))
.append("?filename=").append(fileName).append(".zip");
// 将sign存入redis并设置过期时间
redisClientImpl.set(sign.toString(), path.toString(), SYS_REDIS_EXPIRE_TIME);
}
} catch (Exception e) {
e.printStackTrace();
}
return path.toString();
}
private void writeExcel(ExcelWriter excelWriter){
//数据查询
// todo
synchronized (excelWriter) {
WriteSheet writeSheet = EasyExcel.writerSheet(0, "第" + 1 + "页数据")
// 这里放入动态头
.head(head)
//传入样式
.registerWriteHandler(EasyExcelUtils.getStyleStrategy())
.registerWriteHandler(new CellColorSheetWriteHandler(map, headRow))
.registerWriteHandler(new MergeStrategy(lists.size(), mergeIndex))
// 当然这里数据也可以用 List<List<String>> 去传入
.build();
excelWriter.write(lists, writeSheet);
}
}
Excel导出的文件流样式处理类。
CellColorSheetWriteHandler.java
import com.alibaba.excel.metadata.CellData;
import com.alibaba.excel.metadata.Head;
import com.alibaba.excel.util.StyleUtil;
import com.alibaba.excel.write.handler.CellWriteHandler;
import com.alibaba.excel.write.metadata.holder.WriteSheetHolder;
import com.alibaba.excel.write.metadata.holder.WriteTableHolder;
import com.alibaba.excel.write.metadata.style.WriteCellStyle;
import org.apache.commons.lang3.StringUtils;
import org.apache.poi.ss.usermodel.*;
import org.apache.poi.xssf.usermodel.XSSFCellStyle;
import org.apache.poi.xssf.usermodel.XSSFColor;
import org.apache.poi.xssf.usermodel.XSSFFont;
import java.awt.Color;
import java.util.List;
import java.util.Map;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @Author 菜鸟
* @description 拦截处理单元格创建
*/
public class CellColorSheetWriteHandler implements CellWriteHandler
{
/**
* 多行表头行号
*/
private int headRow;
/**
* 字体
*/
private ExportTable.ExportColumn.Font columnFont = new ExportTable.ExportColumn.Font();
private static volatile XSSFCellStyle cellStyle = null;
public static XSSFCellStyle getCellStyle(Workbook workbook, WriteCellStyle contentWriteCellStyle) {
if(cellStyle == null) {
synchronized (XSSFCellStyle.class) {
if(cellStyle == null) {
cellStyle =(XSSFCellStyle) StyleUtil.buildHeadCellStyle(workbook, contentWriteCellStyle);
}
}
}
return cellStyle;
}
/**
* 字体
* Map<Integer, ExportTable.ExportColumn.Font> 当前列的字段样式
* Map<Integer, List<Map<...>>> 当前行包含那几列需要设置样式
* String head:表头;
* String cell:内容;
*/
private Map<String, Map<Integer, List<Map<Integer, ExportTable.ExportColumn.Font>>>> map;
/**
* 有参构造
*/
public CellColorSheetWriteHandler(Map<String, Map<Integer, List<Map<Integer, ExportTable.ExportColumn.Font>>>> map, int headRow) {
this.map = map;
this.headRow = headRow;
}
/**
* 在单元上的所有操作完成后调用
*/
@Override
public void afterCellDispose(WriteSheetHolder writeSheetHolder, WriteTableHolder writeTableHolder, List<CellData> cellDataList, Cell cell, Head head, Integer relativeRowIndex, Boolean isHead) {
// 当前行的第column列
int column = cell.getColumnIndex();
// 当前第row行
int row = cell.getRowIndex();
AtomicInteger fixNum = new AtomicInteger();
// 处理行,表头
if (headRow > row && map.containsKey("head")){
Map<Integer, List<Map<Integer, ExportTable.ExportColumn.Font>>> fonts = map.get("head");
fonts.get(row).forEach(e->{
e.entrySet().forEach(ele -> {
// 获取冻结字段
if (null != ele.getValue().getFixed() && !StringUtils.isEmpty(ele.getValue().getFixed())) {
fixNum.getAndIncrement();
}
// 字段隐藏
if(!ele.getValue().isShow()){
writeSheetHolder.getSheet().setColumnHidden(ele.getKey(), true);
}
});
});
if (fixNum.get() > 0 && row == 0) {
writeSheetHolder.getSheet().createFreezePane(fixNum.get(), headRow, fixNum.get(), headRow);
}else{
writeSheetHolder.getSheet().createFreezePane(0, headRow, 0, headRow);
}
setStyle(fonts, row, column, cell, writeSheetHolder, head);
}
// 处理内容
if (headRow <= row && map.containsKey("cell") && !map.containsKey("cellStyle")) {
Map<Integer, List<Map<Integer, ExportTable.ExportColumn.Font>>> fonts = map.get("cell");
setStyle(fonts, -1, column, cell, writeSheetHolder, head);
}
}
private void setStyle(Map<Integer, List<Map<Integer, ExportTable.ExportColumn.Font>>> fonts, int row, int column, Cell cell, WriteSheetHolder writeSheetHolder, Head head){
fonts.get(row).forEach(e->{
if (e.containsKey(column)){
// 根据单元格获取workbook
Workbook workbook = cell.getSheet().getWorkbook();
//设置列宽
if(null != e.get(column).getWidth() && !e.get(column).getWidth().isEmpty()) {
writeSheetHolder.getSheet().setColumnWidth(head.getColumnIndex(), Integer.parseInt(e.get(column).getWidth()) * 20);
}else{
writeSheetHolder.getSheet().setColumnWidth(head.getColumnIndex(),2000);
}
// 单元格策略
WriteCellStyle contentWriteCellStyle = new WriteCellStyle();
// 设置垂直居中为居中对齐
contentWriteCellStyle.setVerticalAlignment(VerticalAlignment.CENTER);
// 设置左右对齐方式
if(null != e.get(column).getAlign() && !e.get(column).getAlign().isEmpty()) {
contentWriteCellStyle.setHorizontalAlignment(getHorizontalAlignment(e.get(column).getAlign()));
}else{
contentWriteCellStyle.setHorizontalAlignment(HorizontalAlignment.LEFT);
}
if (!e.get(column).equal(columnFont) || column == 0){
/**
* Prevent the creation of a large number of objects
* Defects of the EasyExcel tool(巨坑,简直脱发神器)
*/
cellStyle = (XSSFCellStyle) StyleUtil.buildHeadCellStyle(workbook, contentWriteCellStyle);
// 设置单元格背景颜色
if(null != e.get(column).getBackground() && !e.get(column).getBackground().isEmpty()) {
cellStyle.setFillForegroundColor(new XSSFColor(hex2Color(e.get(column).getBackground())));
}else{
if(cell.getRowIndex() >= headRow)
cellStyle.setFillForegroundColor(IndexedColors.WHITE.getIndex());
}
// 创建字体实例
Font font = workbook.createFont();
// 设置字体是否加粗
if(null != e.get(column).getFontWeight() && !e.get(column).getFontWeight().isEmpty())
font.setBold(getBold(e.get(column).getFontWeight()));
// 设置字体和大小
if(null != e.get(column).getFontFamily() && !e.get(column).getFontFamily().isEmpty())
font.setFontName(e.get(column).getFontFamily());
if(0 != e.get(column).getFontSize())
font.setFontHeightInPoints((short) e.get(column).getFontSize());
XSSFFont xssfFont = (XSSFFont)font;
//设置字体颜色
if(null != e.get(column).getColor() && !e.get(column).getColor().isEmpty())
xssfFont.setColor(new XSSFColor(hex2Color(e.get(column).getColor())));
cellStyle.setFont(xssfFont);
// 记录上一个样式
columnFont = e.get(column);
}
// 设置当前行第column列的样式
cell.getRow().getCell(column).setCellStyle(cellStyle);
// 设置行高
cell.getRow().setHeight((short) 400);
}
});
}
}
Excel导出的默认样式设置类。
EasyExcelUtils.java
public static HorizontalCellStyleStrategy getStyleStrategy(){
// 头的策略
WriteCellStyle headWriteCellStyle = new WriteCellStyle();
// 背景设置为灰色
headWriteCellStyle.setFillForegroundColor(IndexedColors.GREY_25_PERCENT.getIndex());
WriteFont headWriteFont = new WriteFont();
headWriteFont.setFontHeightInPoints((short)12);
// 字体样式
headWriteFont.setFontName("Frozen");
// 字体颜色
headWriteFont.setColor(IndexedColors.BLACK1.getIndex());
headWriteCellStyle.setWriteFont(headWriteFont);
// 自动换行
headWriteCellStyle.setWrapped(false);
// 水平对齐方式(修改默认对齐方式——4.14 版本1.3.2)
headWriteCellStyle.setHorizontalAlignment(HorizontalAlignment.LEFT);
// 垂直对齐方式
headWriteCellStyle.setVerticalAlignment(VerticalAlignment.CENTER);
// 内容的策略
WriteCellStyle contentWriteCellStyle = new WriteCellStyle();
// 这里需要指定 FillPatternType 为FillPatternType.SOLID_FOREGROUND 不然无法显示背景颜色.头默认了 FillPatternType所以可以不指定
// contentWriteCellStyle.setFillPatternType(FillPatternType.SQUARES);
// 背景白色
contentWriteCellStyle.setFillForegroundColor(IndexedColors.WHITE.getIndex());
// 水平对齐方式(修改默认对齐方式——4.14 版本1.3.2)
contentWriteCellStyle.setHorizontalAlignment(HorizontalAlignment.LEFT);
WriteFont contentWriteFont = new WriteFont();
// 字体大小
contentWriteFont.setFontHeightInPoints((short)12);
// 字体样式
contentWriteFont.setFontName("Calibri");
contentWriteCellStyle.setWriteFont(contentWriteFont);
// 这个策略是 头是头的样式 内容是内容的样式 其他的策略可以自己实现
return new HorizontalCellStyleStrategy(headWriteCellStyle, contentWriteCellStyle);
}
Excel导出合并单元格处理类。
MergeStrategy.class
import com.alibaba.excel.metadata.Head;
import com.alibaba.excel.write.merge.AbstractMergeStrategy;
import org.apache.commons.collections.map.HashedMap;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.util.CellRangeAddress;
import java.util.*;
/**
* @Author 菜鸡
* @description 合并单元格策略
*/
public class MergeStrategy extends AbstractMergeStrategy
{
/**
* 合并的列编号,从0开始
* 指定的index或自己按字段顺序数
*/
private Set<Integer> mergeCellIndex = new HashSet<>();
/**
* 数据集大小,用于区别结束行位置
*/
private Integer maxRow = 0;
// 禁止无参声明
private MergeStrategy() {
}
public MergeStrategy(Integer maxRow, Set<Integer> mergeCellIndex) {
this.mergeCellIndex = mergeCellIndex;
this.maxRow = maxRow;
}
private Map<Integer, MergeRange> lastRow = new HashedMap();
@Override
protected void merge(Sheet sheet, Cell cell, Head head, Integer relativeRowIndex) {
int currentCellIndex = cell.getColumnIndex();
// 判断该行是否需要合并
if (mergeCellIndex.contains(currentCellIndex)) {
String currentCellValue = cell.getStringCellValue();
int currentRowIndex = cell.getRowIndex();
if (!lastRow.containsKey(currentCellIndex)) {
// 记录首行起始位置
lastRow.put(currentCellIndex, new MergeRange(currentCellValue, currentRowIndex, currentRowIndex, currentCellIndex, currentCellIndex));
return;
}
//有上行这列的值了,拿来对比.
MergeRange mergeRange = lastRow.get(currentCellIndex);
if (!(mergeRange.lastValue != null && mergeRange.lastValue.equals(currentCellValue))) {
// 结束的位置触发下合并.
// 同行同列不能合并,会抛异常
if (mergeRange.startRow != mergeRange.endRow || mergeRange.startCell != mergeRange.endCell) {
sheet.addMergedRegionUnsafe(new CellRangeAddress(mergeRange.startRow, mergeRange.endRow, mergeRange.startCell, mergeRange.endCell));
}
// 更新当前列起始位置
lastRow.put(currentCellIndex, new MergeRange(currentCellValue, currentRowIndex, currentRowIndex, currentCellIndex, currentCellIndex));
}
// 合并行 + 1
mergeRange.endRow += 1;
// 结束的位置触发下最后一次没完成的合并
if (relativeRowIndex.equals(maxRow - 1)) {
MergeRange lastMergeRange = lastRow.get(currentCellIndex);
// 同行同列不能合并,会抛异常
if (lastMergeRange.startRow != lastMergeRange.endRow || lastMergeRange.startCell != lastMergeRange.endCell) {
sheet.addMergedRegionUnsafe(new CellRangeAddress(lastMergeRange.startRow, lastMergeRange.endRow, lastMergeRange.startCell, lastMergeRange.endCell));
}
}
}
}
}
class MergeRange {
public int startRow;
public int endRow;
public int startCell;
public int endCell;
public String lastValue;
public MergeRange(String lastValue, int startRow, int endRow, int startCell, int endCell) {
this.startRow = startRow;
this.endRow = endRow;
this.startCell = startCell;
this.endCell = endCell;
this.lastValue = lastValue;
}
}
来源:blog.csdn.net/qq_40921561/article/details/126764038
往期推荐:
6个顶级SpringCloud微服务开源项目,企业开发必备!
Spring Boot 使用 ChatGPT API 开发一个聊天机器人
SpringBoot + Sharding JDBC,一文搞定分库分表、读写分离