Oceanus的实时流式计算实践与优化
点击可观看精彩演讲视频
一、腾讯云流计算服务
今天的内容主要分两大部分:第一部分向大家快速介绍现在腾讯云上流式计算服务的基本情况,后一个较大的重点分为三个部分——我们在实时的业务过程中针对Flink SQL所遇到的技术上的痛点、在改造这些痛点的过程中所遇到的技术挑战,以及在整个实践过程中所做的技术方案和内容。
这是现在腾讯云实时计算服务的运营情况,目前在客户方面我们既有内部客户,也有外部客户。在外部客户方面,像B站、叮咚买菜等互联网公司都使用了我们的实时计算服务。内部业务像比较重要的微信、QQ、QQ音乐、腾讯视频等都已经使用了我们的实时计算服务。目前整个实时计算的计算规模已经超过了3万核,每天的数据接入量超过5PB,日实时计算量超过50万/次,而且这个规模还在不断地增长。

我们整个服务的研发方向也分为四块:首先是想降低用户在使用我们的计算服务以及开发他自己的Flink实时计算任务时的接入和学习成本,所以我们提供了一站式的开发平台。同时用户开发完自己的Flink job之后,可以直接在这个平台上进行线上测试,保证实时部署前的数据正确性。其次我们提供了一站式的部署功能,能够让实时的计算任务直接部署到腾讯云的TKE容器上。最后是运维工具,任务部署到TKE之后,需要实时掌握实际运营情况,包括它的失败告警以及实际的运营指标等,我们提供了一系列的运维工具,帮助用户快速解决线上的问题。
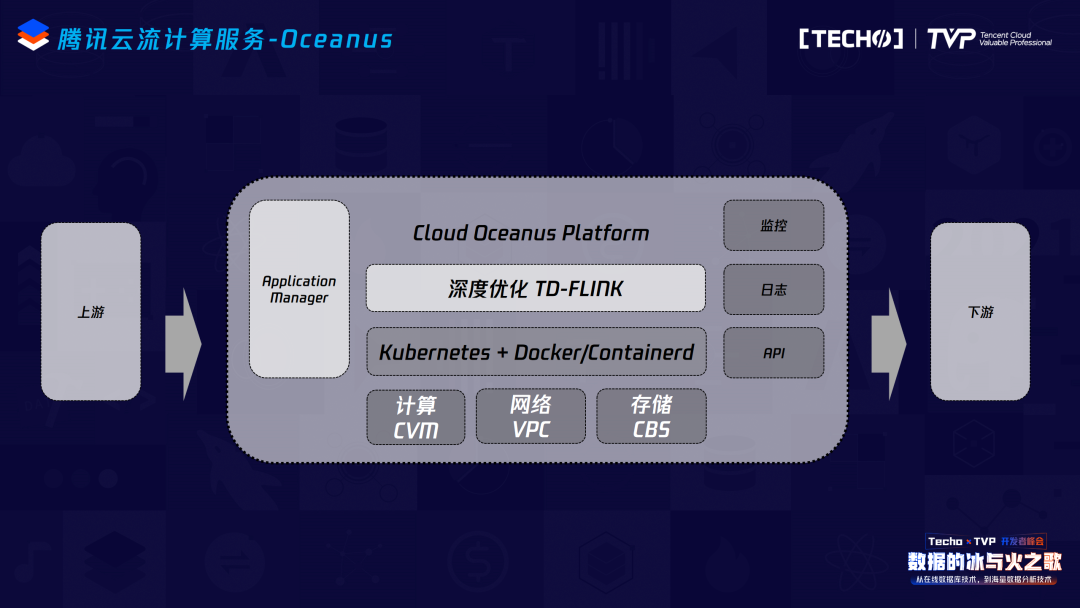
整个云上生态中,实时计算更多担当的是一个通道的角色,我们在上下游的生态和数据打通上花费了非常多的精力,包括修复了社区connector相关的一些bug、基本能支持大数据生态和腾讯云上所有基本组件的数据打通,目前我们也已经在内部测试的CDC Source、ClickHouse 等connector,最近应该会上线跟大家见面。
接下来的内容是今天的重点——我们在Flink SQL上所做的工作,在展开之前,我带大家快速回顾Flink SQL的基本概念和情况。
二、Flink SQL概况
首先看Flink的编程模型,Flink本身提供了三层编程模型供大家使用,最底层的是Data Stream和Data Set API,是一个java API,往上Table这一层是它基于类似于DSL的领域建模语言,再往上是它的Flink SQL,越往上它的抽象层次会越高,也就意味着用户在使用不同的编程接口的时候,越往上所需要花费的学习成本和接入成本会更低。所以在实际接入过程中还是希望用户能够使用我们的Flink SQL,因为本身SQL的特点也是非常明显的,首先它是标准化的语言,不同背景的人员来使用SQL都能够快速阅读当前这一段SQL所表达的业务逻辑,同时它底层跟计算引擎和版本可能都是解耦的,所以后续的版本升级、平台迁移都是比较轻量级的。但是它也有它的不足之处,越往上抽象,它可能会流失一些基本的功能,即Flink SQL并没有涵盖到所有的DataStream或者说Flink原语的语义,所以我们也希望大家和社区一起共建这部分的能力。

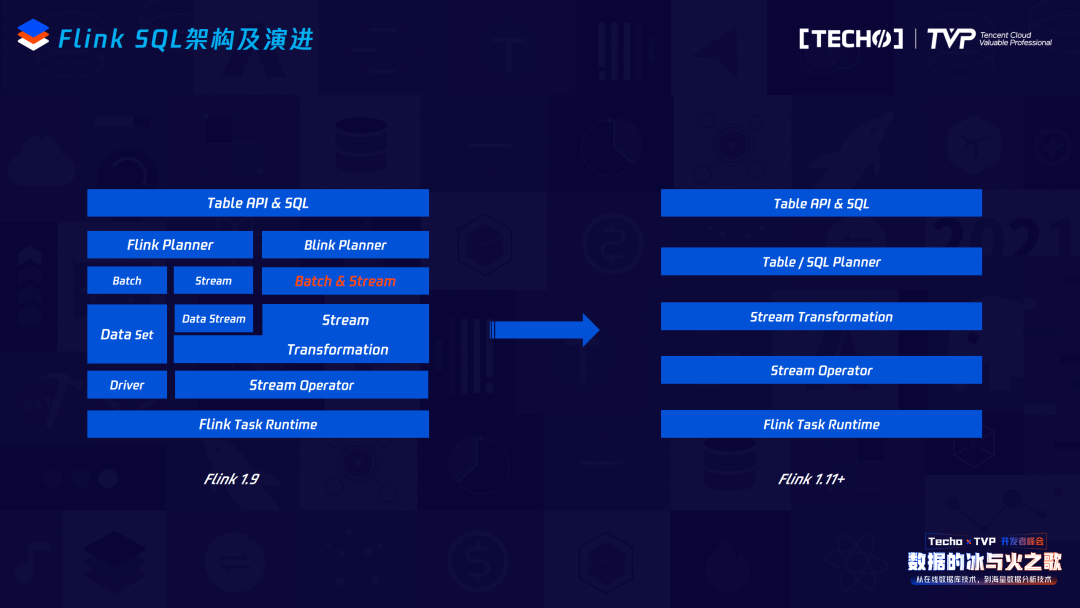
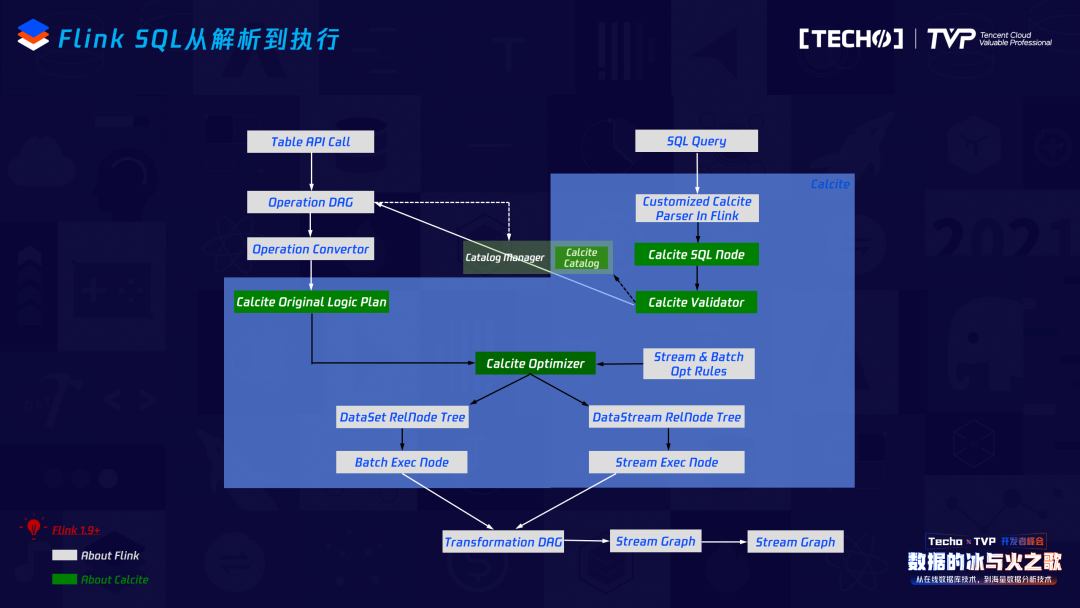
再看当前Flink SQL的架构及演进,这其实是Flink1.9和Flink1.9之后的变化,最主要的变化是在Flink1.9之前它经过了Data Set或者Data Stream的一层转换,也就是说转成最终的Stream Graph时,它会调用Data Stream或者Data Set的API;但是在Flink1.9之后,它其实把这一层拿掉了,即在SQL Node变成Stream Graph时,用Stream Transformation就可以达到直接转化Stream Graph。它的优点显而易见,抽掉了中间这一层,可以保证在做SQL优化代码和逻辑正确化优化的规则上都可以共享,不再区分它的流与批。
这是一条SQL从SQL文本转成最终Flink Job的过程,主要分五步:第一步调Flink依赖里的JavaCC,将这个文本转成AST语法树,也就是它的SQL Node,SQL Node后会调一个Validate接口,这里Validate的内容就是SQL的一些元数据,经过这两步之后就完成了一条SQL的语法分析和语义分析。再往后SQL Node会转成Rel Node,最终会转成Flink的Native Code,中间会做一些优化,包括:逻辑执行计划优化和物理执行计划优化。最终的执行计划变成Native Code,中间我们有两种方式去生成最终的Flink代码,一种是通过一些规则的方式静态地编码,另外一种是如果逻辑比较灵活的话,可能需要通过动态代码生成技术,将代码生成架构文件之后在内存里进行编译,直接部署到Flink集群上。
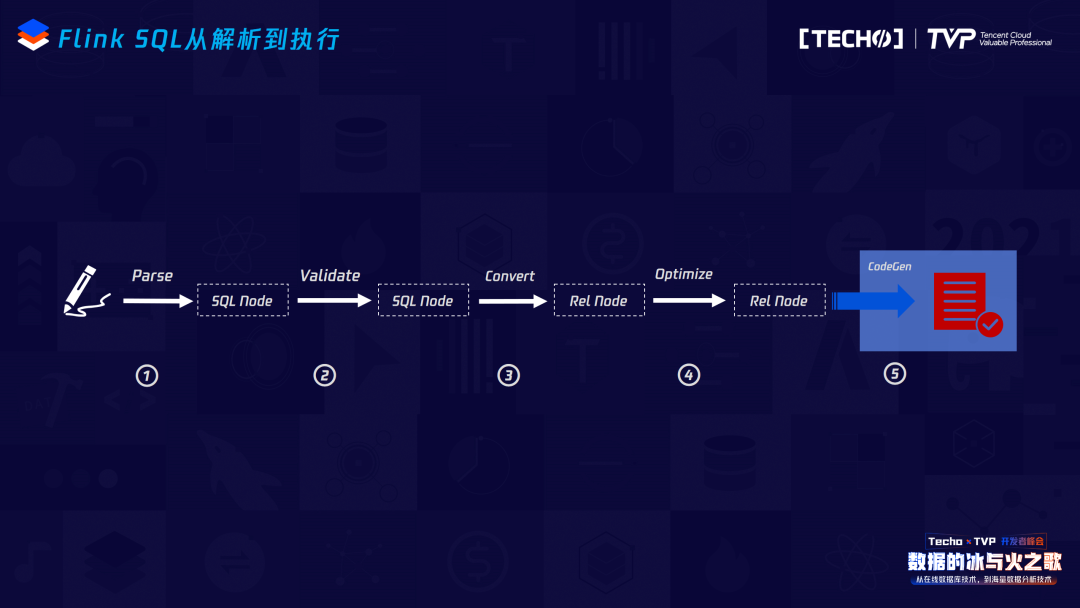
从这个图,可以更详细的看出Flink SQL从解析到执行,跟不同模块之间的互动关系。同时,跟Flink1.7不同的是,它从calcite交互出来之后不会再转成SQL Node,而是直接变成Operation DAG,通过Operation Convertor会再转成最开始的Logical plan,往后的优化部分是一样的,再往下它就不会再去调Data Stream或者Data Set API,而直接会变成Transformation DAG,最终转成Stream Graph,这是整个的流程。
三、Flink SQL的痛点与挑战
接下来是我们在整个接入过程中所遇到的一些痛点与技术挑战,总结起来痛点主要分为三个部分。
第一部分是SQL语法支持,因为标准SQL已经发展了很多年,但是Flink的项目快速发展也就这几年的时间,所以Flink SQL的功能并没有完全覆盖到所有的标准SQL,比如你在MySQL写一条SQL,想直接运行在Flink上,可能有些语法是不能够完全支持的,所以这一块也需要跟社区一起不断地去补齐和完善。另外一方面是它的语法不统一。因为流上的语义本就非常复杂,不同的平台语法也不同,包括Flink也有自己的“方言”,不同的版本之间Flink其实在快速的演进过程中,做得也不是很好,所以在同一个功能上它的语法写法也不一样,这都带来一些学习上的成本。
第二是功能覆盖,对SQL来说,无法完全覆盖Data Stream或者Data Set API的功能,还是要持续补齐Data Stream和Data Set的能力。Flink任务其实是一个DAG的组织图,通过DAG的方式来表示不同算子之间的执行顺序,但是SQL语言从最开始发展到现在其实并不是很擅长描述DAG,如果DAG非常复杂,想通过一个SQL去表达是非常困难,或者说基本上不可能的,当前有一些方案,比如可以把一个复杂的DAG切分成多个SQL,通过视图的方式把整个DAG组装起来,但即使这样做,如果SQL非常复杂,它的阅读性和后续的扩展性都是比较差的,所以这部分相对于Data Stream有比较多短板。
第三是运维支撑,SQL的执行性能包括三部分,第一部分是它的业务逻辑本身,第二部分是它的执行计划优化,第三部分是执行计划转换成Flink Native Code,后面这两部分主要是平台来担当优化的角色,所以各家平台技术上的实现都有各自的长处,用户能够把控的优化性能方向可能就是业务逻辑本身,如果想像Data Stream做一些精细化优化,那SQL这一块也是非常不足。即使现在我们提供一些参数的方式调优,也是基于平台自己提供的一些能力才能做优化,这是一个难点,在平台侧和社区以后都要持续补齐。在问题定位方面,SQL翻译成Flink job之后,它的运行是一个整体,如果SQL非常复杂,其中的某一步或者是某一部分的逻辑不符合预期,复现这个问题就非常困难,因为本身在流上复现问题都很困难,如果想分段去复现,更是难上加难,所以后续也是需要不断补齐能力,仅在内核侧做起来并不容易。
在难点方面,Stream SQL发展比较晚,针对它的标准比较少。扩展一个SQL时,其实我们不想去扩展很多跟平台或版本相关的SQL方言,因为这样会带来版本升级或平台迁移的负担,所以在扩展当前的Flink SQL时,我们还是希望遵循一些标准,如果是SQL的标准,那是最好的。另外是在语义方面,因为Stream上的语义相对于Batch复杂很多,而且它有自己的一些特殊语义,比如窗口或排序,在流上和在批上实现这个能力,复杂程度完全不一样,在流上会复杂特别多。
在性能优化方面,要注意流上一些特有的特性。比如Retract机制,比如Flink自己也是一个带State的操作,所以在优化的时候都要结合State进行,包括State交互和设计方案都要考虑。另外是在性能优化的时候,现在整个执行计划转变都是通过RBO的方式,如果要更准确,其实通过CBO的方式会更贴切,但是在流上的统计信息收集和在批上完全不一样,而且即使收集到了最新的统计信息,如果想去优化当前这一条SQL,有可能改变了当前DAG的拓扑图,有可能就没办法从原来的状态恢复,这些问题都是我们后续要解决的。
四、Flink SQL的优化与扩展
接下来展开我们在Flink SQL上做的扩展与优化工作,其实优化工作的方向是和前面业务的痛点一一对应。
首先在扩展语法方面,再强调一下,我们在扩展语法的时候并不希望开发一些跟平台或版本相关的方言,这样会为后续的维护带来非常大的负担,所以扩展语法时还是会找一些和现有的SQL标准相符的SQL语法,比如现在的Windowing Table-valued Function,另一个是流与维表Join,也是遵循了标准SQL的写法。在功能方面也是补齐我们的SQL和Data Stream之间的差距,目前包括我们的增量窗口、增强的Tumble窗口,还有可以指定任意字段作为时间属性字段被窗口使用等功能。在性能方面我们也做了较多的工作,接下来要讲的是Retraction优化还有UDX函数内联优化,比如一个UDX被调用多次,Flink会被执行多次,如果我们做一个简单的优化,可以拿第一次的执行结果直接代入后面的UDX调用链里,减少性能的损耗。我们做了一个Bucket Join,对于流与维表Join有较大的优化,它不需要把维表的数据全部加载到内存,这也是非常有用的。还有一个是Local Key By,也是借鉴了MapReduce,减少在这个阶段的数据流动。
1. 新增Table-Valued Function语法
接下来是Table-Valued Function。原始需求是这样的:如果想在两个流做一个Join,同时这个Join是在相同窗口内的数据完成Join的,应该怎么做?按照社区当前的写法,可能需要先做一个Join,再做Group by。可以看到它有两个问题,首先它的语义模糊不清,因为如果先做Join再做Group by,无法保证在做Join的时候数据在同一个窗口内;另外一个是在Flink上进行SQL翻译时,不管是Join还是Window Group by,都要涉及到状态的操作,所以我们先做Join,再做Window,涉及到两次的状态操作,同时Join状态的清理没办法随着Window的销毁而销毁,也就是Join状态必须通过Flink TTL的方式来清理,对于当前这个需求,如果只需要对相同窗口内的数据做Join,那应该是这个窗口销毁了,所有的状态都要被销毁,所以如果用社区的SQL去写也有问题。
经过一些调研,我们发现在SQL2016里面有一个叫Table-Valued Function的语法,我们和calcite社区一起把Table-Valued Function进行了落地,目前1.23版本之上已经支持这个语法,而且我们内部也把它实现到了Flink里。差异显而易见,原来比如要写一个Window,它会把这个Window信息放到Group字段里,但是通过这个语法我们把Window信息放到了From Source这一层,从这个SQL来看,它更贴近于标准SQL或者说批的这种写法更适合具有数据分析背景的人员来理解。

再看下面的Logic Plan,它在下面进行TableScan的时候,往上有一个TableFunctionScan,在转变之后它加了两个字段:Window start和Window Node,经过这个Rel Node转换后它的原始数据会被加上两列,来表示这个数据是属于哪个窗口。有了这个标记后,我们要在流上再做这种Join就比较简单了——先描述两个流属于哪个窗口,直接再做Join,因为本身它是在内部实现的,不需要去写累赘的语法,所以如果想实现这个需求,就是非常简洁的一个语法,先构造两个具有Window窗口的Source,直接做Join就好。同时在多流上我们不仅仅实现了Join,而且在状态操作中把Join和Window算子两个的状态操作合在一起,提升了执行性能,我们还在流上支持交并差的操作。

针对这个语法我们还扩展了很多其他非常有用的功能。第一是改写了当前Flink Group Window的写法,改写后更贴切标准SQL针对Group Window的写法,原来的Group Window是要把Window信息放到Group字段里,但现在我们直接把Window信息放到Table里,意味着Table的Source已经分了窗口,理解起来更直接。同时因为Table-Valued Function已经把数据划分了窗口,所以直接在当前语法上实现窗口内排序或者Top N输出,这个语法也就显得更加自然和容易。

我们最近也做了一个扩展:自定义的Table-Valued Function,这个功能被非常多用户提及,可以实现对于Source表M列转N列的操作,意味着如果Source阶段若只有两列,下面计算的时候需要三列,那直接自定义一个Table-Valued Function就可以完成这个操作,而用现在的Flink SQL是完全做不到的。

2. 新增窗口类型
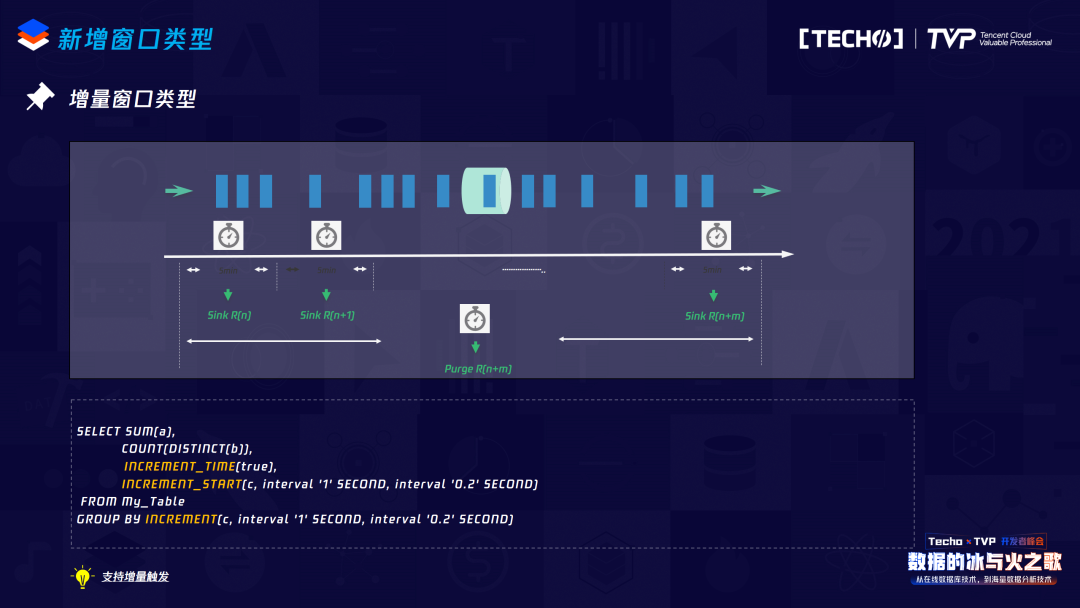
接下来是新增的两个窗口类型,在实际生产过程中非常有用。一个叫增量窗口,它的需求背景非常直观,比如要统计当前某一个网页一天内的PV曲线,对于普通的Table Window,数据要发送到下游来描绘这个曲线,而必须等到整个窗口触发之后才能收到数据,因此曲线无法被描绘。其实它的实现机制也比较简单,我们可以自定义一个trigger,如果这个trigger到达了在SQL里定义的interval限制,就直接可以把当前的Window State直接发送到下游,下游会接收到多次的数据来描绘当前的PV曲线。在实际的生产过程中,我们又遇到了用户提到的一个比较有用的功能:增量触发。因为在很多情况下,有些Group Key很长一段时间内当前这个窗口和上一个窗口的触发值是不变的,如果每一次都把这个数据触发到下游,对下游的压力也比较大,所以我们增加了Lazy trigger,即当前窗口的值如果不变,不需要往下游发送这个数据,以减少下游的数据接收压力。
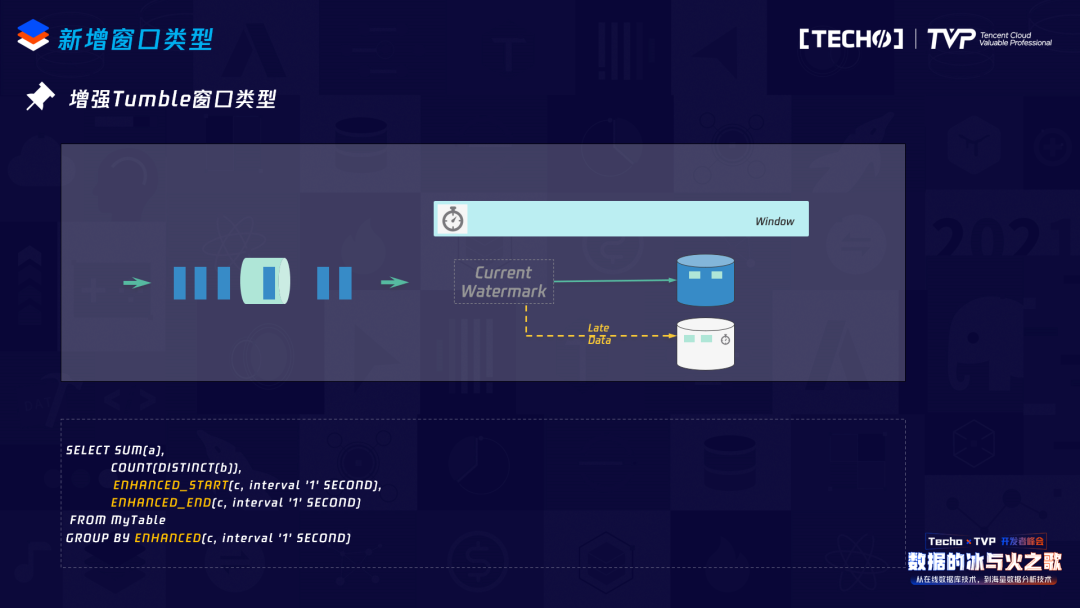
另外是增强Tumble窗口类型。用Data Stream写过Flink job的同学应该都知道,如果需要处理迟到数据,我们可能要定义一个Side output,如果在SQL上想用Tumble Window去处理这个迟到数据,目前的Tumble Window无法指定这个数据的输出,所以我们增加了一个新的窗口类型,实现的机制不复杂,比如来的迟到数据会被放到另外一个State里面,我们会定义一个trigger,trigger的长度就是当前Tumble Window的长度,即并不是来一条数据就往下游发送一条,而是经过一段时间的汇聚,之后将这个汇聚的结果再发送到下游,这样不仅能够接收迟到的数据,而且还能够减少下游接收数据的压力。这里有一点需要指出的:使用这个Window,对于下游来讲如果是类似于K/V的HBase,要注意后面的迟到数据可能覆盖前面的数据,对于迟到数据一定是累加的,一旦覆盖,整个结果就错了。
3. 回撤流性能优化
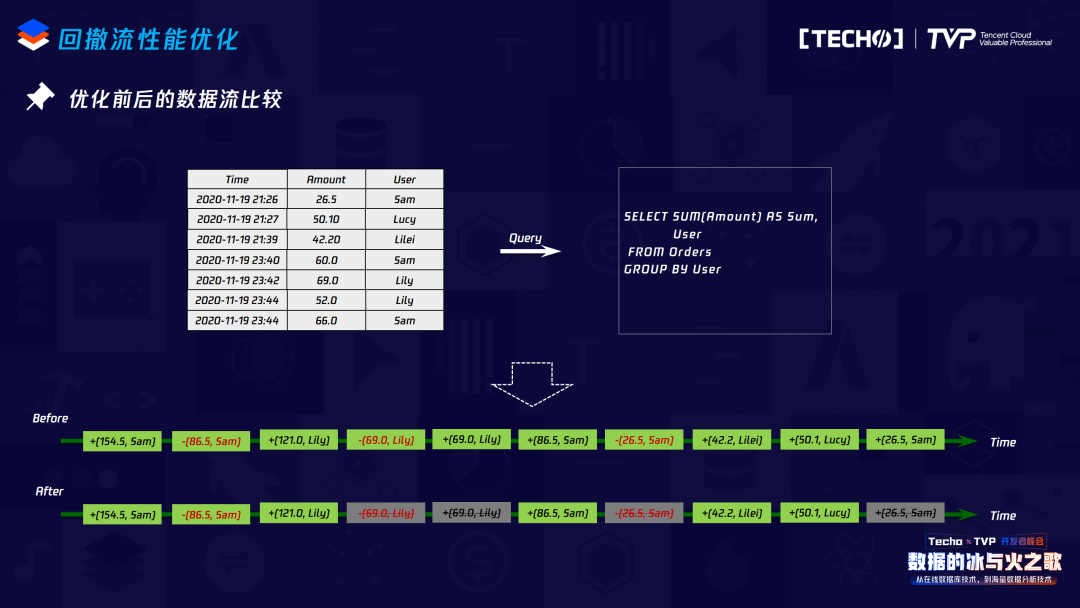
接下来是回撤流的机制,在Flink里如果写一个SQL要保证整个逻辑的正确性,那回撤流是非常有用的。比如这个例子,它有两层Group by,如果没有回撤流机制,结果是错的。这个回撤流的作用是什么?在流上来一条数据都要向下游发送它的更新结果数据,如果上游不停地来相同的Group key并向下游发送,更新结果覆盖了之前的结果,那到了下游拿这个结果去更新就会出错,所以像两层Group by场景,应该是要先把原来发送到下游的数据回撤,同时发送新的计算结果,具体的做法是在原始数据里加一个标志,比如一个减号,这个减号就告诉下游:“删掉这个数据,接下来我会送给你一个新的数据,那才是当前对Group key更新的结果。”
目前Flink的实现过程中,可以看到最坏的情况,是整个下游接收的数据应该是原始数据的两倍,在我们的优化过程中发现完全没有必要每来一条数据就向下游发送一条,因为这都要涉及State操作,而且如果Group by key较多,用Rocks DB作为state backend,Rocks DB会涉及IO的操作,性能得不到很好的保证,所以我们把它进行CACHE或者说整个逻辑正确化的改写。如果在Sink,其实也不需要每来一条数据就向下游发送一条,而且针对KV组件特别有用,KV组件本身是幂等的,不需要向下游发送Retract,直接支持Upsert,所以我们直接把新的Update信息发送给下游即可。
针对回撤流优化的几个实现方案,我列举了比较有代表性的:
第一个是刚才SQL两层Group by的场景,我们在第一层Group by向下游发送AGG结果时,在上面进行改写:在中间加一个operator,做一个CACHE,这个CACHE也不是CACHE原始数据,它会把数据进行上面Window的操作,之后再发送给下游,这对于下游接收的数据量就会减少很多。
第二种场景是Sink场景,在Sink之前也可以做一个CACHE,这个CACHE保证之前的数据做累计,向下游发送的时候并不是每来一条就发送一条,只有达到了这个CACHE的触发条件,才会向下游发送数据。
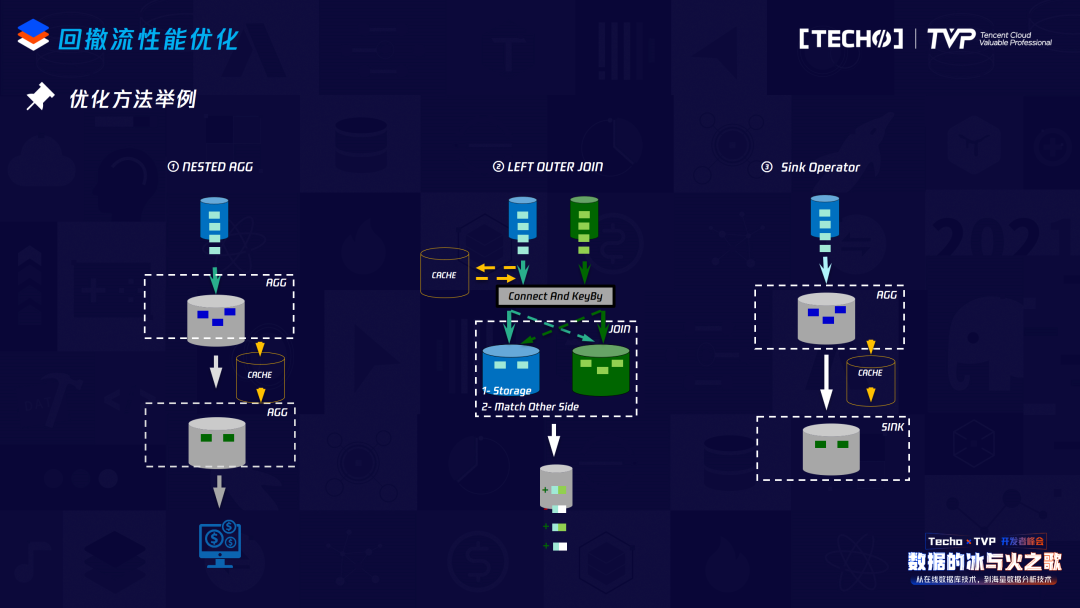
对于Outer Join的场景,会相对复杂一点。讲Outer Join优化之前,简单说明为什么这种Outer Join会产生回撤:因为在流上做两个流Join,如果是一个LEFT Join,左边的数据先来,右边的数据如果没有匹配上,其实对于没有匹配上的语义是有歧义的,到底是因为没有右边的数据,还是它迟到了?这些都需要做区分,所以为了保证Outer Join完整的语义,对于在Flink原始的实现方案,就需要首先向下游发送左边的数据以左边的流填充、右边的数据以填充的那一条数据发送给下游,但此时如果又有右边的数据,Outer Join变成了Inner Join的逻辑,后面的数据又过来,首先要把前面发送给下游的这条数据回撤,同时向下游发送一条跟Inner Join一样逻辑的数据。
经过上面的分析,优化思路也较直接。首先我们可以在左边进行一个CACHE,这个CACHE并不是无条件的,在CACHE之前先向右边去做匹配的查询,如果能匹配上,说明当前对这条Join key是Inner Join的逻辑,它其实是不需要CACHE的,没有必要牺牲实时处理的实时性来完成这个功能,直接向下游发送Inner Join的逻辑即可。如果右边没有数据,就可以做一个有技术点设计的CACHE,比如在做相同key数据CACHE时,不需要存储所有的原始数据,而是加一个字段表示当前key相同的数据,如果到达了触发条件,就向下游发送跟这个相同的数据。同时如果左边的数据跟右边的数据匹配上了,对于相同的key,往后所有的数据没有必要再做缓存,因为毕竟做这个CACHE是牺牲了一定的时效性而换来的。
来看优化前后的结果对比,做完CACHE或Upset,向下游发送的数据量相对于没有优化之前减少很多,因为做了一个合并。在内部我们做了测试,如果CACHE的时间大小是两分钟,对于两边是100万条的数据,同时下游是幂等组件,经过优化向下游接收的数据量有30倍的减少。如果是Inner Join,两边的数据量是完全随机的,我们做了一个两分钟的CACHE,100万的数据有近20%的提升。